-
spark3.0.2搭建教程
spark3.0.2搭建教程
spark3.0.2安装教程
一、前期准备
需要提前按照好hadoop集群
资源下载:
补充:
二、spark搭建
主机名 hadoop1 hadoop2 hadoop3 Master
workerworker worker 分别有三台主机,主机名为hadoop1、hadoop2、hadoop3
(一)搭建
1、将spark上传到虚拟机上
在CRT中可以输入命令
rz将spark-3.0.2-bin-hadoop3.2.tgz上传到/opt/software中cd /opt/software rz- 1
- 2
/opt/software我用来存放安装包相关文件的2、解压安装包
将文件解压到
/opt/module/tar -zxvf spark-3.0.2-bin-hadoop3.2.gz -C /opt/module/- 1
并将文件名字改为spark
mv /opt/module/spark-3.0.2-bin-hadoop3.2 spark- 1
(二)、standalone(独立部署)模型
standalone模式是spark的master-salve的模型,安装规划如下:
主机名 hadoop1 hadoop2 hadoop3 Master
workerworker worker 1、修改配置文件
-
进入到解压文件路径下
conf中- 修改
slaves.template为slaves - 修改
spark-env.sh.template为spark-env.sh - 修改
spark-defaults.conf.template为spark-defaults.conf
mv slaves.template slaves mv spark-env.sh.template spark-env.sh mv spark-defaults.conf.template spark-defaults.conf- 1
- 2
- 3
上面都是模板文件,因此需要修改
- 修改
-
在
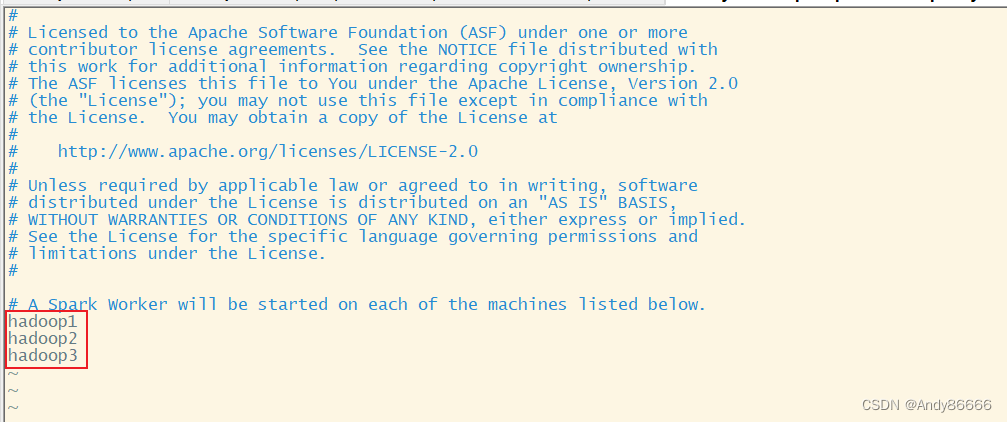
slaves中,中添加worker节点hadoop1 hadoop2 hadoop3- 1
- 2
- 3
-
在
spark-env.sh中,添加JAVA_HOME的路径,Master节点export JAVA_HOME=/opt/module/jdk1.8.0_212 SPARK_MASTER_HOST=hadoop1 SPARK_MASTER_PORT=7077- 1
- 2
- 3
注意:JAVA_HOME是自己安装jdk的路径;7077端口相当于hadoop3版本内部通信的
8020、9000、9820端口 -
配置历史服务器来记录任务运行情况
-
在
spark-defaults.conf中添加或者修改spark.eventLog.enabled true spark.eventLog.dir hdfs://hadoop1:8020/directory spark.yarn.historyServer.address=hadoop1:18080 spark.history.ui.port=18080- 1
- 2
- 3
- 4
spark.eventLog.dir是指存储日志数据的位置 ,将数据存到hadoop2上注意:需要在hdfs上创建一个
directory文件夹来存储,可以使用下面命令hadoop fs -mkdir /directory -
还需要在spark-env.sh添加历史服务器相关的配置信息
export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://hadoop1:8020/directory -Dspark.history.retainedApplications=30"- 1
- 2
- 3
- 4
-
(三)、yarn模型
yarn模型是利用yarn来进行资源调度
1、修改配置文件
和standalone模型的配置有相似的地方
-
在slaves中添加worker的文件,和上面内容一样
-
在
spark-env.sh中,添加JAVA_HOME的路径和hadoop集群的配置文件路径export JAVA_HOME=/opt/module/jdk1.8.0_212 YARN_CONF_DIR=/opt/hadoop-3.1.3/etc/hadoop- 1
- 2
注意:JAVA_HOME是自己安装jdk的路径,
YARN_CONF_DIR是hadoop配置文件的路径 -
配置历史服务器来记录任务运行情况,和standalone模型的配置一样
-
需要去在hadoop的
yarn-site.xml中添加Whether physical memory limits will be enforced for containers. yarn.nodemanager.pmem-check-enabled false yarn.nodemanager.vmem-check-enabled false - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意:修改后,将修改的文件分发到其他的hadoop中,并重启启动hadoop集群
因此可以得知,yarn模型基于standalone模型下,只需要在spark-env.sh 只需要添加
YARN_CONF_DIR即可(四)、将spark文件分发到hadoop2、hadoop3中
rsync -av /opt/module/spark 用户名@ip地址:/opt/module/- 1
三、开启spark
进入的spark安装目录中,执行下面命令开
spark集群和hadoop集群sbin/start-all.sh- 1
需要自己另外开启hadoop集群
可以通过jps命令查看spark是否启动,分别会在
hadoop1、hadoop2、hadoop3中显示以下进程hadoop1 hadoop2 hadoop3 Master
workerworker worker (一)、测试
需要进入到spark的安装目录中,使用spark的官方案例:计算π的值
第一种:standalone模式
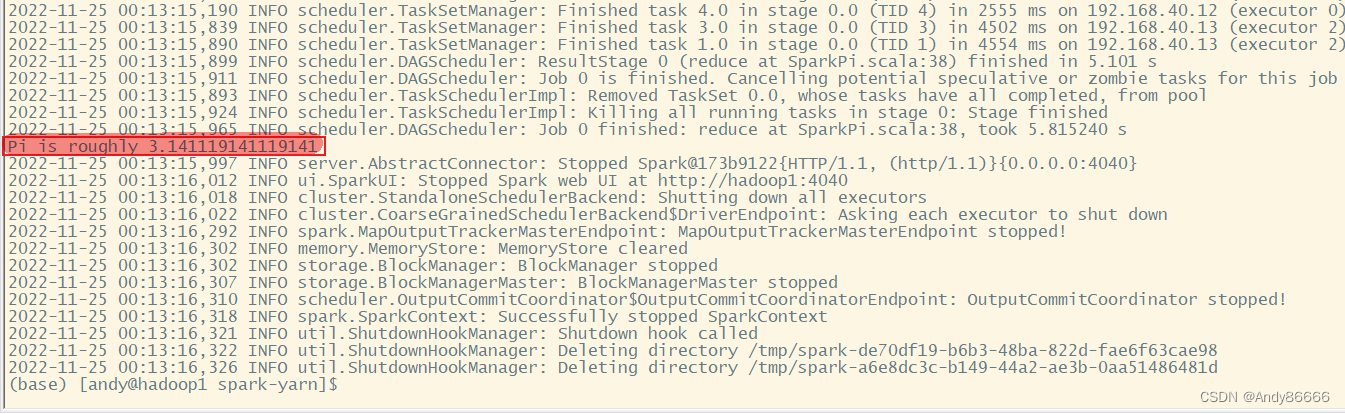
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://hadoop1:7077 \ ./examples/jars/spark-examples_2.12-3.0.2.jar \ 10- 1
- 2
- 3
- 4
- 5
第二种:yarn模式
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn ./examples/jars/spark-examples_2.12-3.0.2.jar \ 10- 1
- 2
- 3
- 4
- 5
补充知识:
- 为了便于对spark和scala的学习,在jupyter添加内核来编写。
jupyter中安装scala和spark内核详细教程
-
相关阅读:
初步搭建一个自己的对象存储服务---Minio
行业洞察 | AI贩卖的焦虑,我们该买单吗?
海藻酸钠-聚乙二醇-四嗪 TZ-PEG-alginate 四嗪修饰海藻酸钠 海藻酸钠-PEG-四嗪
Educational Codeforces Round 136 (Rated for Div. 2)(A~D)
【Java】面向对象的特性之一:多态性
java使用多线程并行处理逻辑后合并处理结果(Async注解方式)
Linux 使用 atop 监控工具
springboot验证码的生成与验证
【图像去噪】基于非线性扩散PM算法实现图像去噪附matlab代码
HBase2.x(四)HBase API 创建连接
- 原文地址:https://blog.csdn.net/Andy86666/article/details/128010302