-
C++模板基础和STL之string
泛型编程之模板
使用实际调用的函数不是同一个,因为不同类型参数,函数栈帧中开辟的空间不一样。参数不一样,所以调用的函数也不一样。使用模板速度必重载速度更快,因为是编译器直接生成。而STL就叫标准模板库。
template<class T> void Swap(T& x1, T& x2) // 本意是用引用& { T x = x1; x1 = x2; x2 = x; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
特别场景:当函数像求和一样,两个都用模板的T类型,那么T不可以同时为doble和int,如何解决这种问题?
答:显示实例化。这种方式是指定模板参数T的具体类型。 -
对于模板参数T:
可以做参数、也可能做返回值。
typedef中可以使用参数T使得某个类或某类数据结构支持尽可能多的参数类型,而只是用typedef int datatype不能同时满足两种或以上的数据结构存储的数据类型。实际上,面对不同参数,编译器会自动生成不一样的代码,不必自己写出来重复度极高的相似类或结构体的代码,工作都交给了编译器。如下写法:stack<int> st1; stack<double>st2; stack<int*>st4;- 1
- 2
- 3
以上,编译器实例化出几份代码分别是存int、double的等几个存不同元素类型的栈。
- 注意点:
- 如果在类外使用类模板写函数,还要重声明使用了类模板T。不然如下第二行的T识别不出来。

- 使用类模板后,类型变成了class_name,class_name只是类名。
- 模板实例化:
隐式实例化和显示实例化:
答:隐式是直接传参,让编译器自己判断,显示是函数名后:<>显示实例化。模板函数和非模板函数(平时常用的)可以同时存在,调用时候,如果显示给类型,会优先调用非模板函数。隐式调用,优先调用模板函数。此外,如果模板可以产生更匹配的函数,就选择模板函数。模板不允许自动类型转换,但是普通函数可以自动类型转换。 - 类模板:
比如一个项目中,我们如果定义栈的类,内部类型使用了class T。那么在同一项目中,可以给stack存各种类型数值,而不用类模板,就肯定不行,只能存单一类型数值。
关于模板的疑问点:
- 下面有关C++中为什么用模板类的原因,描述错误的是? ( )
A.可用来创建动态增长和减小的数据结构
B.它是类型无关的,因此具有很高的可复用性
C.它运行时检查数据类型,保证了类型安全
D.它是平台无关的,可移植性
- 问题:D对吗?C对吗?
模板运行时不检查数据类型,也不保证类型安全,相当于类型的宏替换。
只要支持模板语法,模板的代码就是可移植的,总之它不安全,且如果支持模板语法,就可移植。
- 在下列对fun的调用中,错误的是( )
template
T fun(T x,T y){
return xx+yy;
}
A.fun(1, 2)
B.fun(1.0, 2)
C.fun(2.0, 1.0)
D.fun(1, 2.0)- B、D哪个错了?
显示实例化,改变的是传入的参数类型, 而不是说确定了模板中T类型,所以D会都变float,D正确了。
- 下列关于模板的说法正确的是( )
A.模板的实参在任何时候都可以省略
B.类模板与模板类所指的是同一概念
C.类模板的参数必须是虚拟类型的
D.类模板中的成员函数全是模板函数
- 我全不懂
A 不一定有时候需要指定
B 模板类是通过类模板实例化的具体类,不一样。也就是说:模板类更小,是个具体的。类模板是说你在使用类模板
C 错误,不是虚拟,也可以直接传,如2题的D
D 对,因为数据成员是模板类型,所以函数都是模板函数。
- 下列的模板声明中,其中几个是正确的( )
1)template
2)template
3)template
4)template
5)template<typename T1,T2>
6)template
7)template
8)
- 2、4、6 7
class可以用typename代替。
- 下列描述错误的是( )
A.编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础
B.函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具
C.模板分为函数模板和类模板
D. 模板类跟普通类以一样的,编译器对它的处理时一样的
D错误,肯定不一样。
STL
STL是C++标准模板库(standard template libaray)。此外STL版本一般一致,常见有PJ、SGI版本等。
核心:容器、算法string
- 基本知识点:
必须导入包,因为<<、>>对string类型操作需要重载。
构造函数7、成员函数上百,只需要掌握常用即可。
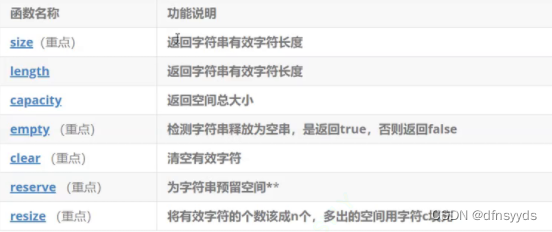
- 常见函数:
- size()和length()结果一样,但是推荐size。它俩的计算都不包含\0。此外由于其它STL容器中习惯用size,因为只有字符串习惯说length长度,多用size()为了保持统一,方便记忆用size。
- 对capacity()的了解:查看string容量的函数
答:利用s += ‘char’ 或其它函数会使得字符串增容,字符串变量长度发生改变后会自动增容。大小包括**\0**。 - 当字符串长度变化后如何增容的?
答:如果字符串变量长度改变后,开始会再malloc()一个32的空间,此后如果长度再变化,会成1.5倍地做扩容。 - 访问之operator[]
- std::string::operator[]
使得string能直接通过s[i]得到下标为i的字符值。返回类型是引用,出了范围还存在,所以可以直接返回私有这个成员。
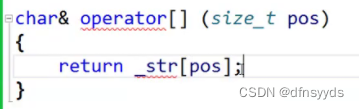
原理:重载[],通过【pos】直接返回字符指针_str[pos]。以底层的私有指针变量为一维数组返回下标为pos的_str。即使是私有成员变量也可以返回,可以返回它的地址,也可以返回它的拷贝值。 - 此外,at()功能也类似[],但是它抛出异常,而不是断言。
- 字符串拼接:
声明string s而不做初始化也可以任意拼接字符串,但是建议像做leetcode,结果字符串还是以""初始化吧。
遍历string之迭代器
- 理解:
暂时认为是指针。 - 使用代码:
需要写++it。
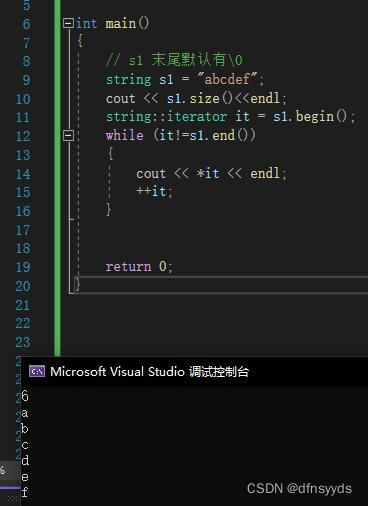
- 迭代器变量的操作:通过it可以访问string某个位置的值,也可以通过it改字符串中字符。*it += 1;
- 反向迭代器:rbegin()、rend()
与之前正向迭代器操作一样,需要加上r。结果方向相反。
它的rbegin()指向’\0’的前一个。rend()指向第一个字符。

-
既然有了下标搭配[]的用法,为什么还要迭代器呢?
因为其它STL也需要遍历,不能通过[]方式,为了保持统一。 -
这里发现:创建正、反迭代器类型it、rit都很费劲,右值是.begin()或.end(),用auto可以自动识别右值类型做转换。
-
当迭代器遇上const常字符串的引用:不能修改,只能*it读。
遍历string之范围for
- 范围for运行效果如上述迭代器。
for(auto e: s1) cout<<e<<endl;- 1
- 2
- 使用:
- 可以读写:
- auto e只是对s1中的值做拷贝。如果要修改字符串,应该使用引用。
- 规定&必须放在e前面。
- 如下的auto可换char,但是不如auto好用。
- 代码:
for(auto& e: s1) cout<<e<<endl;- 1
- 2
reserve():专门的字符串扩容函数,以’\0’填充
- 作用:
- 开空间: 申请1000个空间,一次多开,会让string减少增容次数,提高效率。
s.reserve(1000); - 开空间加初始化:reserve(100, ‘x’);
开100个空间,每个位置填’x’。
此外,reserve扩容并不会影响原来的string长度。
常使用reserve()而不是resize()。
resize()
可以扩容,也可以缩容。缩容可能让字符串丢失。
c_str()
- 解释:
获取C形式的string,以’\0’结束。
通过字符串变量可以直接调到。 - 用法:
可以使用在字符串读文件上:
如下第一种不可编译,因为fopen()第一个参数是const char*,而这里的file是string。使用file_str()是const char*。
string file("test.txt"); FILE* fout = fopen(file, "W"); -------------下面可以的----------------- string file2(test.txt); FILE* fout = fopen(file_str, "W");- 1
- 2
- 3
- 4
- 5
substr()
截取字符串,返回的结果是深拷贝。
find()
- 功能:
默认从参数size_t pos=0开始找。如果找不到,给整型最大值。 string::npos,npos是string中的静态变量。 - 使用技巧:
用find(‘str’)求字符位置,再搭配substr()截取子串。substr(0, pos-0),技巧就是用find()结果减某个位置。
rfind()
- 情景:文件名是:.txt.zip,我们找.zip,如果寻找策略是从第一个".“到文件末尾寻找”.zip",那么只能得到".txt.zip",只需要".zip"这需要从右往左找。用rfind(“.”)得到靠后的"."位置,然后用substr(pos)得到从这个位置到最末尾的子串。

url.substr():寻找从某个位置起往后的n个。
s.substr(x, n):从下标为x起找n个。
erase():删除
param1:起始位置
param2:删个数。如果不给,就删完。- 删头:
uri.erase(0, 1); - 删尾:如果删除位置是末尾,则倒着删
uri.erase(uri.size() - 1, 1); - 使用erase()对字符串去头尾:
搭配find_first_not_of()、find_last_not_of(" “),后面这个意思是最后一个不是空格,所以还应该+1,才是末尾空格位置。以下” "或’ '都可以用
// 不空才去做 // find_first_not_of void trimSpace(string& s) { if (!s.empty()) { s.erase(0, s.find_first_not_of(" ")); s.erase(s.find_last_not_of(" ") + 1); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
sto()系列和to_string()
数字变字符串、字符串变数字:
stoi()转为int类型,stold转为double类型。

demo:
- 解析url:
int main() { // s1 末尾默认有\0 string url = "https://www.baidu.com/?tn=62095104_31_oem_dg/"; size_t pos1 = url.find(":"); string protocol = url.substr(0, pos1 - 0); cout << "协议:"<<protocol<< endl; // 找第二个'/',find()和rfind()直接用都拿不到。 // 这就可以用find的其它用法:从某个位置开始找,我们根据url的规律,可以从w开始,pos1+3 size_t pos2 = url.find('/', pos1+3); // cout <<"第二个/位置" << pos2 << endl; pos2 = 21 string domain = url.substr(pos1+3, pos2 - (pos1+3)); cout << "域名:"<<domain<<endl; string uri = url.substr(pos2 + 1); cout << "区分段:" << uri << endl; // 删头 uri.erase(0, 1); cout << "区分段:" << uri << endl; // 删尾:从位置起删,如果是最后位置,则反着删 uri.erase(uri.size() - 1, 1); cout << "区分段:" << uri << endl; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 读空格后单词长度
#include#include #include using namespace std; int main() { string s; //char ch = getchar(); // 单个字符接收 以'\n'为结尾 会忽视空格 /*while (ch != '\n') { s += ch; ch = getchar(); }*/ getline(cin, s); int pos = s.rfind(' '); string res = s.substr(pos + 1); cout << res.size() << endl; return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
字符串的接收:
cin>>s,
cin和scanf字符串默认以空格和换行结束。
当要输入字符串以空格间隔,只接收第一个。- 两种接收带空格字符串的方式:
- 循环getchar()方式
string s; char ch = getchar(); // 单个字符接收 以'\n'为结尾 会忽视空格 while (ch != '\n') { s += ch; ch = getchar(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- getline()
getline(cin, s);- 1
练习
- leetcode344. 反转字符串
-
思路:
利用左右变量begin、end,双重循环,依次交换头尾。外圈要符合begin -
注意:
- C++不用写swap,库中提供了。
- 像这种都是正数的变量如下标begin、end且也较小,用size_t无符号整形即可。
bool isLetter(char ch) { if ((ch >= 'A' && ch <= 'Z') || (ch >= 'a' && ch <= 'z')) return true; else return false; } class Solution { public: string reverseOnlyLetters(string s) { size_t begin = 0; size_t end = s.size() - 1; // 左到右判断一遍 遇到字母就停下 都是字母才交换。 // 注意换完还得往后走 while (begin < end) { while (begin < end && !isLetter(s[begin])) { begin++; } while (begin < end && !isLetter(s[end])) { end--; }1 swap(s[begin], s[end]); begin++; end--; } return s; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- leetcode 387. 字符串中的第一个唯一字符
-
思路:
利用计数排序思想,字母范围比较集中,st[i] - ‘a’ 结果为0~27,最后遍历寻找为1的值。 -
报错:

一直报错无返回值,仔细看因为左边提示:会有-1的结果。所以没有认真看题,不是所有都符合规范。 -
代码
class Solution { public: int firstUniqChar(string s) { int countArr[26] = { 0 }; // 统计次数 for (size_t i = 0; i < s.size(); ++i) countArr[s[i] - 'a']++; for (int j = 0;j < s.size(); j++) if (countArr[s[j] - 'a'] == 1) return j; return -1; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 巧妙点和习惯:
- 要返回原始字符串中的位置, s[j] - ‘a’ 得到字母表中第几个值。其中j,就是该字母在原始string中位置的记录。
- 会使用 size_t:当数字范围较小且都是正数,尽管使用。
- string习惯使用size()求长度。
- 回文串
这个题让看字母类和数字类是否相同,不考虑其他特殊字符。
- 思路:
- 双指针法:begin、end同时挪动,是
为什么是两层:移动过程可能会停下做操作,做完操作后,因为外层循环使得继续去移动。所以两层循环搭配双指针非常合适。
2. 巧妙用法:大小写转换:对数字做tolower()和对字母做tolower()效果一样,不会影响数字,且比较字母更加方便。 - 注意事项:当前都是字母后,比较完应该挪动指针。
class Solution { public: bool isLetterOrNum(char ch) { if (ch >= '0' && ch <= '9') return true; if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z')) return true; return false; } bool isPalindrome(string s) { int begin = 0, end = s.size() - 1; /* */ while (begin < end) { while (begin < end && !isLetterOrNum(s[begin])) { begin++; } while (begin < end && !isLetterOrNum(s[end])) { end--; } if (tolower(s[begin])!=tolower(s[end])) { cout << "这里不对" << endl; return false; } else { end--; begin++; } } return true; } };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- leetcode415. 字符串相加
主要是长测试用例的相加:
- 对于leetcode类测试:
如下代码:
上面的可以,为什么下面不可以?
Solution s1 = Solution(); -----------上面的可以,为什么下面不可以---------------- Solution s1 = new Solution(); -----------下面的又可以---------------- Solution* s1 = new Solution();- 1
- 2
- 3
- 4
- 5
因为new在申请空间,返回地址,所以用类指针类型接收。
习惯上,操纵类喜欢用指针。 -
相关阅读:
在Centos上配置bgp路由
C++中的is_same_v和conditional_t
寻找AI时代的关键拼图,从美国橡树岭国家实验室读懂AI存力信标
React-hooks【三】useCallback与useMemo详解,搭配Memo使用
渗透测试——通过SQL注入拿到webshell
猿创征文| 指针,这还拿不下你?
Python数据分析实战-表连接-merge四种连接方式用法(附源码和实现效果)
宝宝有这些表现正不正常?我来告诉你
关于.model.meta,.model.index,.model.data-00000-of-00001--学习笔记
Java 如何经行异常处理?常见的运行异常的编译时异常
- 原文地址:https://blog.csdn.net/myscratch/article/details/127266658
