-
JUC并发编程第三篇,CompletableFuture场景练习,电商比价需求性能提升
JUC并发编程第三篇,CompletableFuture场景练习,电商比价需求性能提升
案例说明:电商比价需求
- 同一款产品,同时搜索出同款产品在各大电商的售价;
- 同一款产品,同时搜索出本产品在某一个电商平台下,各个入驻门店的售价是多少
- 出来结果希望是同款产品的在不同地方的价格清单列表,返回一个List
代码实现如下:
public class CompletableFutureNetMallDemo { static List<NetMall> mallList = Arrays.asList( new NetMall("jd"), new NetMall("tb"), new NetMall("tm"), new NetMall("dw"), new NetMall("pdd") ); //同步方式 public static List<String> getPriceByStep(List<NetMall> list,String productName) { return list.stream() .map(netMall -> String.format(productName + " in %s price is %.2f", netMall.getMallName(),netMall.calcPrice(productName))) .collect(Collectors.toList()); } //异步方式 public static List<String> getPriceByAsycn(List<NetMall> list,String productName) { return list.stream() .map(netMall -> CompletableFuture.supplyAsync(() -> String.format(productName + " in %s price is %.2f", netMall.getMallName(),netMall.calcPrice(productName)))) .collect(Collectors.toList()) .stream().map(CompletableFuture::join).collect(Collectors.toList()); } public static void main(String[] args) { System.out.println("-------------同步方式---------------"); long startTime = System.currentTimeMillis(); List<String> list = getPriceByStep(mallList, "java"); for (String element : list) { System.out.println(element); } long endTime = System.currentTimeMillis(); System.out.println("-----花费时间为:"+ (endTime - startTime)+"毫秒-----"); System.out.println("-------------异步方式---------------"); long startTime2 = System.currentTimeMillis(); List<String> list2 = getPriceByAsycn(mallList, "java"); for (String element : list2) { System.out.println(element); } long endTime2 = System.currentTimeMillis(); System.out.println("-----花费时间为:"+ (endTime2 - startTime2)+"毫秒-----"); } } class NetMall { private String mallName; public NetMall(String mallName){ this.mallName = mallName; } public double calcPrice(String productName){ //模拟检索时间1s try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } return ThreadLocalRandom.current().nextDouble() * 2 + productName.charAt(0); } public String getMallName() { return mallName; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
结果测试
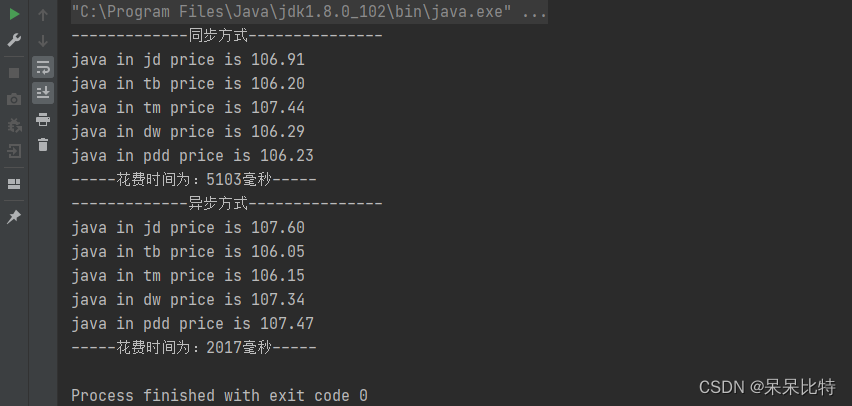
总结
如果现在有一些网站物品价格初始数据串,我们想要进行比价,可以将这些数据保存到Redis的Zset里边,保证数据没有重复,然后进行比较,第一种笨办法就是一条数据一条数据的过,但是这样性能不高;第二种,在JUC里边,有一个 CompletableFuture,用他做多线程异步并发是不阻塞的,而且可以自定义线程池,线程池根据数据量的大小伸缩,在数据量变大时仍能保证效率,大大提升程序性能。
-
相关阅读:
软件工程理论与实践 (吕云翔) 第五章 面向对象方法与UML课后习题及其答案解析
GCC 参数详解
钉钉对接打通金蝶云星空获取审批实例详情接口与采购订单新增接口
怎样把网页上的音频转换成mp3格式?试试这几个转换方法
DDoS攻击--防护本质
【c++提高1】拓扑排序
一个用Python将视频变为表情包的工具
黑马点评-02使用Redis代替session,Redis + token机制实现
1.5 HDFS分布式文件系统-hadoop-最全最完整的保姆级的java大数据学习资料
设置Domino服务器上的Web文件保护
- 原文地址:https://blog.csdn.net/NICK_53/article/details/127981967