-
万字深剖进程地址空间(全程干货)
前言
在我们学习C语言和C++的时候经常会看到很多地址,这些地址通常都是被存放到对应的指针中的,那么这些地址到底指的是内存中的物理地址还是啥呢?显然今天这边文章就是来带大家解开这个谜底
一、程序地址空间
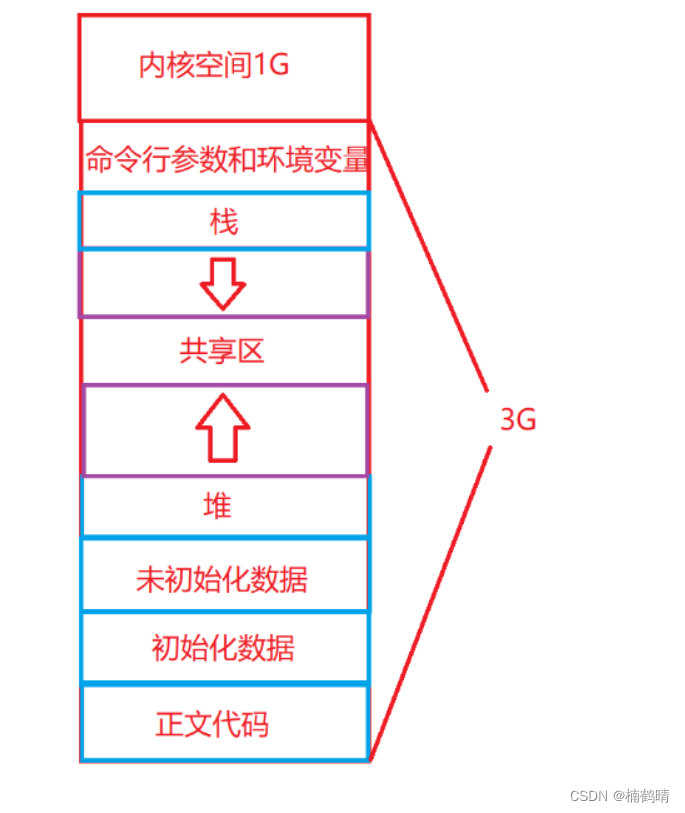
1.程序地址空间的简图
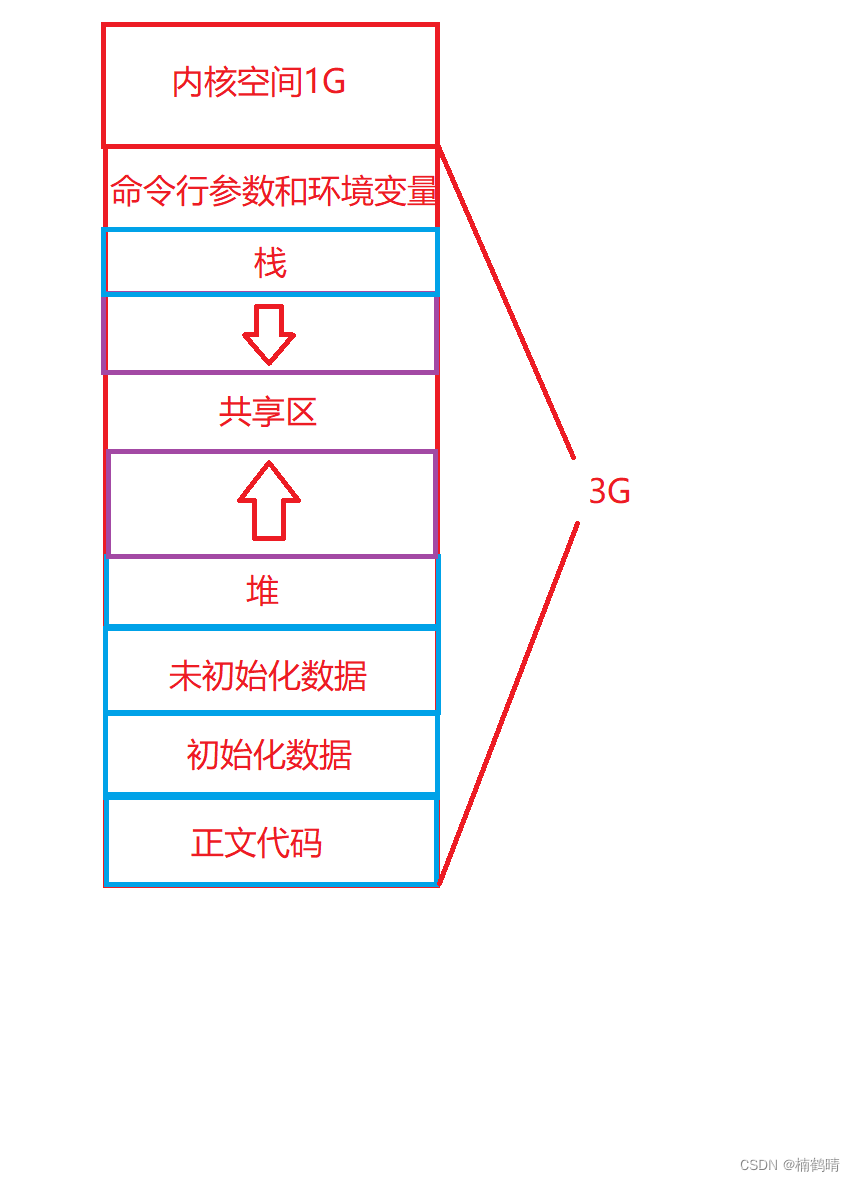
从上面的图我们可以看出,程序地址空间中存在一些相关的区域:正文代码,初始化数据,未初始化数据,堆,共享区,栈,命令行和环境变量,内核空间,除了内核空间,其他空间都属于用户空间,所占的空间大小是3G,我们今天主要研究用户空间的各个区域,内核空间今天暂不讨论。(1)正文代码
正文代码主要是指一些函数代码,比如常见的main函数就属于正文代码

(2)初始化数据
我们在写代码的时候通常需要声明一些变量,当我们对一个变量声明之后并给予赋初始值,那么该变量就属于初始化数据,初始化数据又可分为初始化全局数据和初始化局部数据,其实就是全局变量和局部变量的差别

(3)未初始化数据
我们在写代码的时候通常需要声明一些变量,当我们对一个变量声明之后未给予赋初始值,那么该变量就属于未初始化数据,未初始化数据又可分为未初始化全局数据和未初始化局部数据,其实就是全局变量和局部变量的差别

(4)堆区
在写代码的时候如果是通过动态内存开辟的空间一般都是存在于堆上的,常见的有C语言中的
malloc,calloc,realloc函数开辟的内存块和C++中new开辟的内存块都是属于堆区上的内存
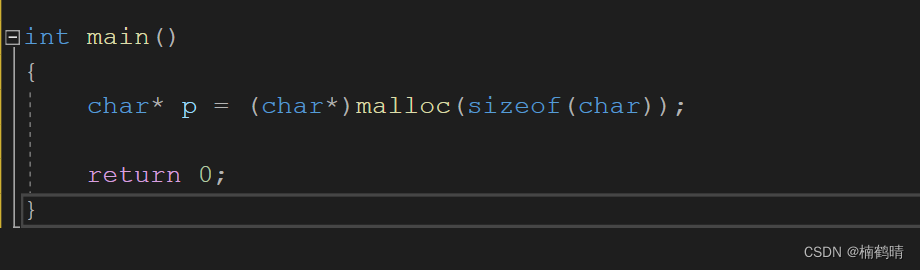
- 注意:开辟之后通常会返回一个指针,这个指针是指向堆区上开辟的内存块的,其中存放的是从堆区上开辟的空间,但是这个指针本身是在函数中定义的,因此属于一个局部变量,存在于栈上
(5)共享区
共享区这里暂不讨论,在后面进程间通信会展开说明
(6)栈区
我们通常会在函数栈帧中创建很多变量,这个变量只能在函数栈帧中存在,出了函数栈帧,这个变量就会被销毁,我们称这个变量具有临时性,这个变量即为局部变量,存在于栈上
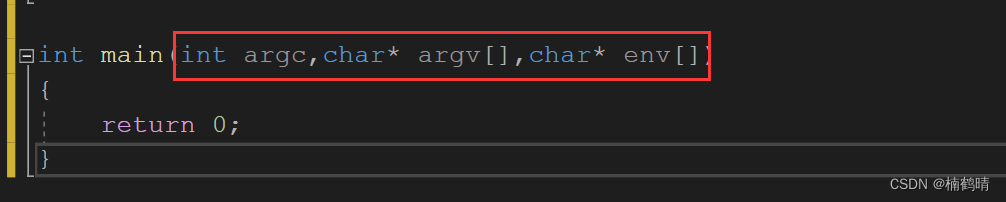
(7)命令行参数和环境变量
命令行参数指的是在命令行上敲入的一些参数,main函数的第二个参数就是负责获取命令行参数的,比如选项和命令等
环境变量:main函数的第三个函数就是负责接收环境变量的,在上篇文章(环境变量)中已经着重进行讲解
2.实验:验证程序地址空间中各个区域的存在
- 构建项目:创建源文件addr.c和自动化构建项目makefile文件
- 源文件addr.c
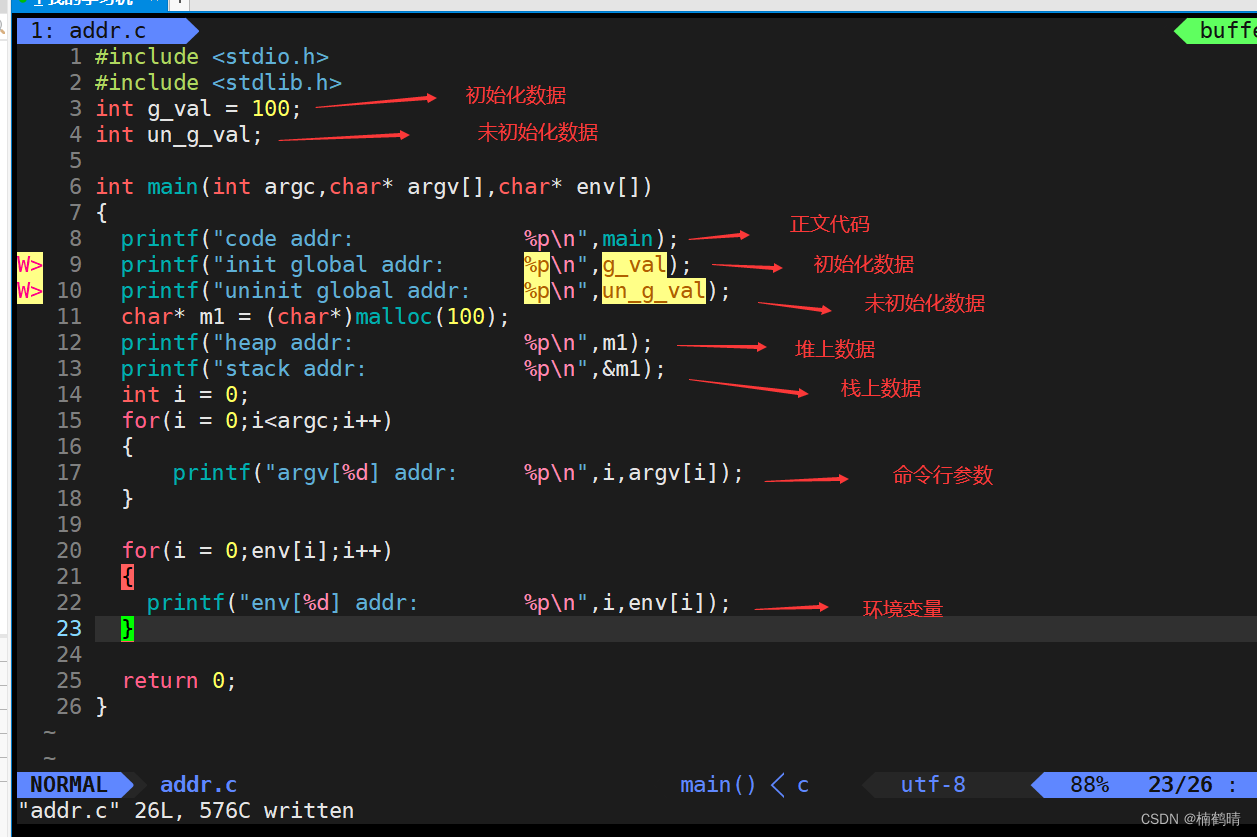
- 自动化构建项目makefile文件
- 实验结果
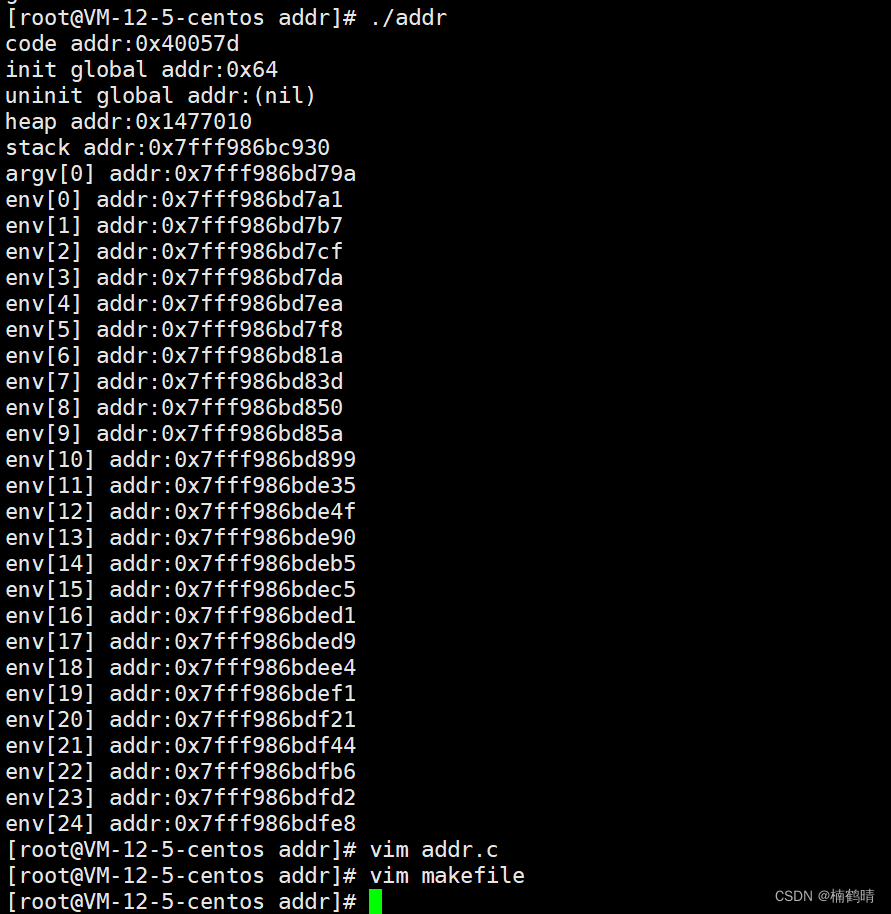
从实验结果我们可以看出,地址空间中确实存在正文代码,初始化数据和未初始化数据,堆,栈,命令行参数和环境变量,并且从正文代码到命令行参数和环境变量的地址是依次增大的
- 关于malloc函数
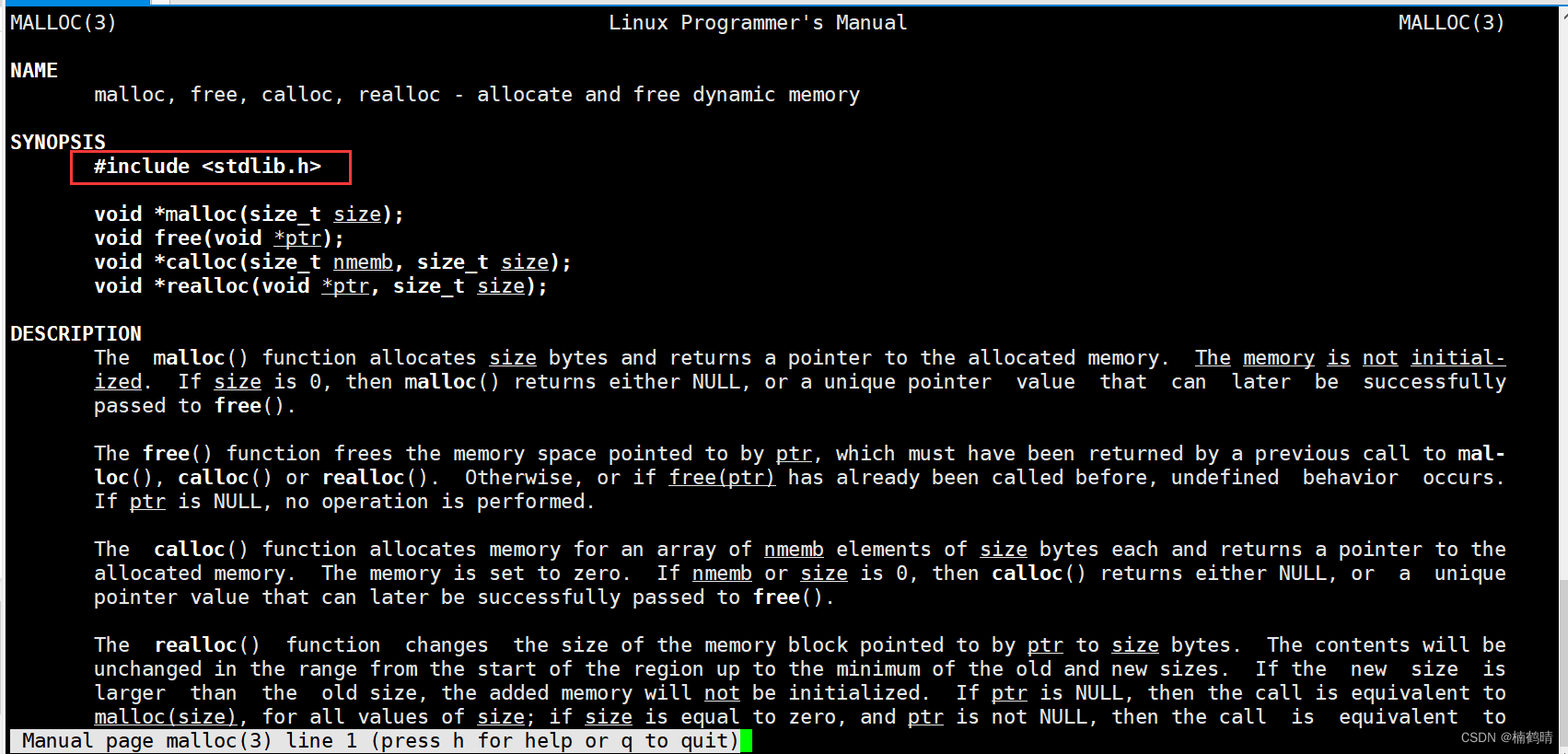
在使用malloc函数的时候一定要注意包含对应的头文件
3.实验:验证堆区和栈区中地址的增长方向
- 构建项目:创建源文件addr.c和自动化构建项目makefile文件
-
源文件addr.c
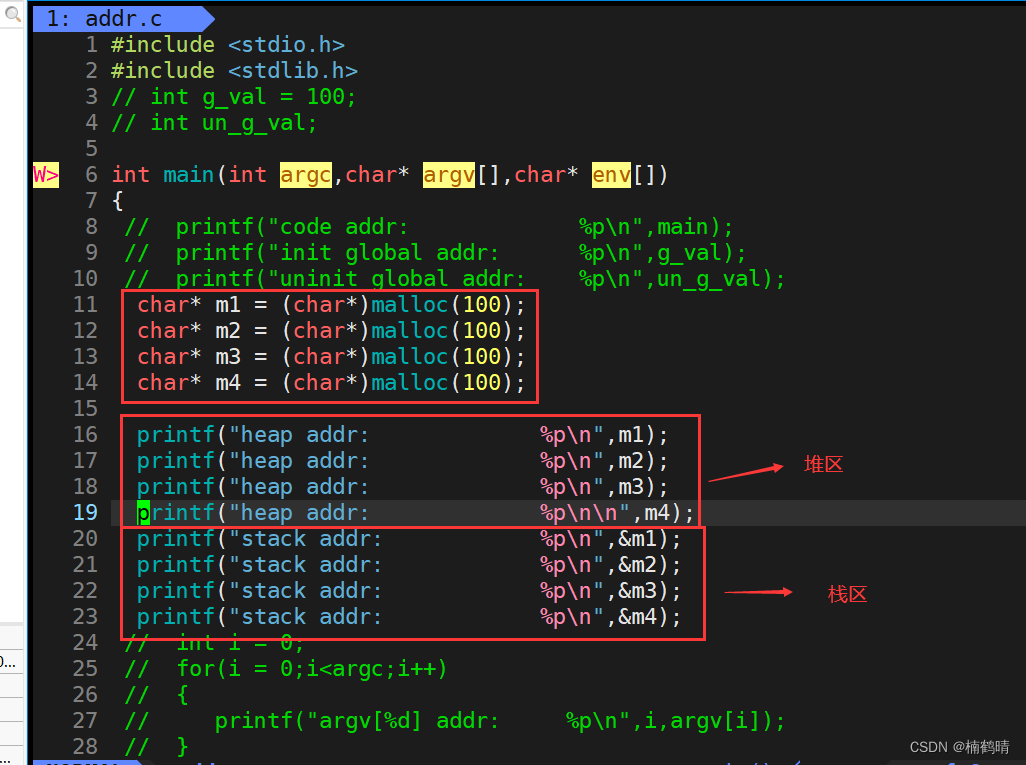
-
自动化构建项目makefile文件
- 实验结果
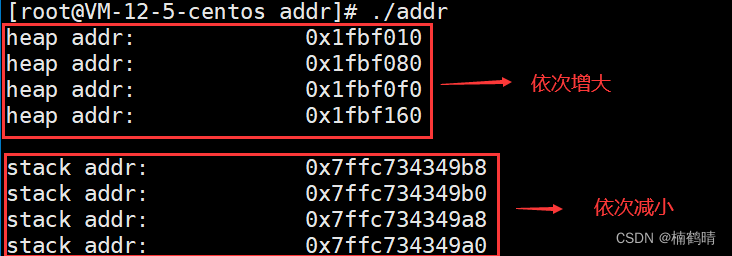
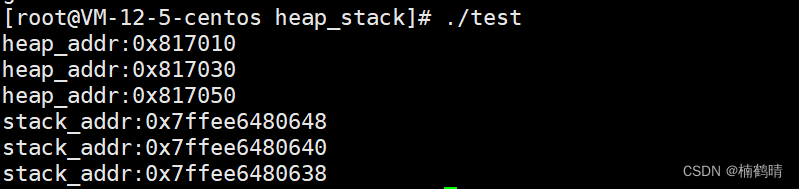
我们一般在C语言函数中定义的变量都是属于局部变量,保存在栈上的,先定义的变量的地址会更高
4.实验:如何理解static变量
- 构建项目:创建源文件addr.c和自动化构建项目makefile文件
-
源文件addr.c
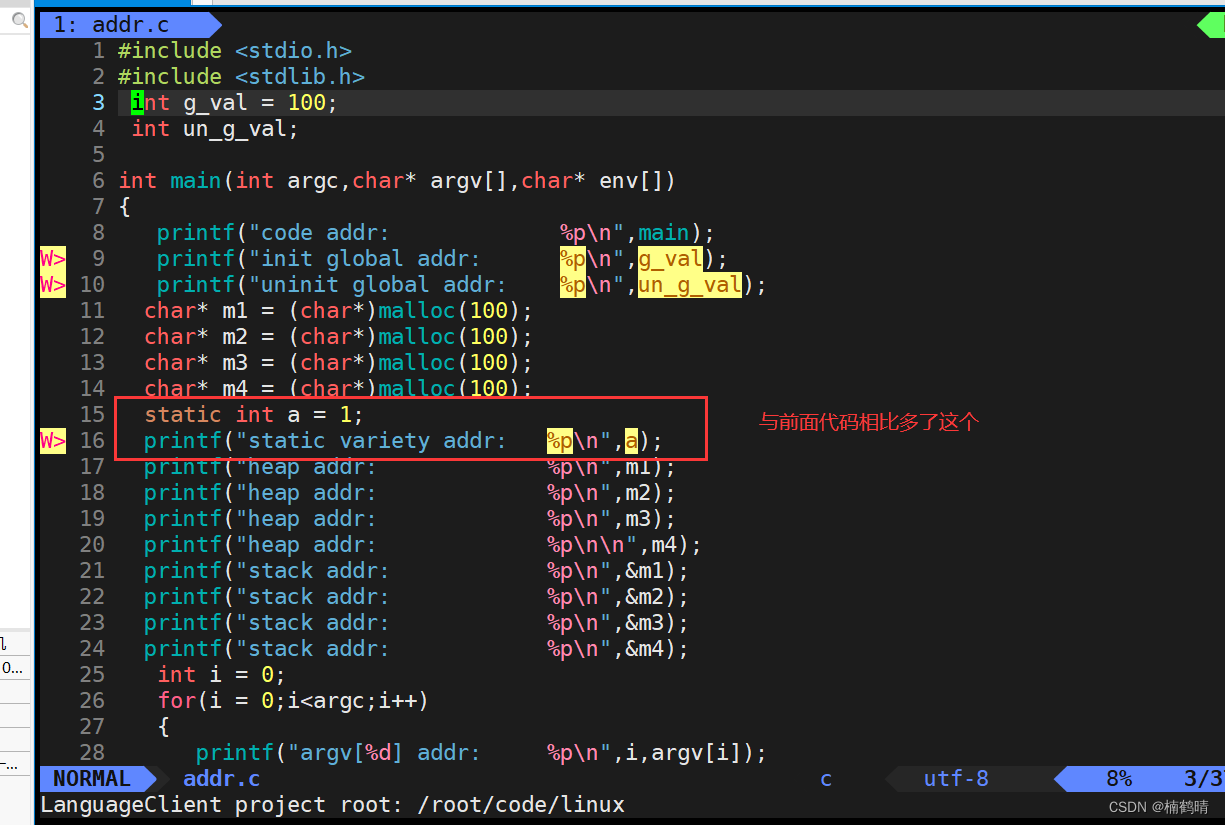
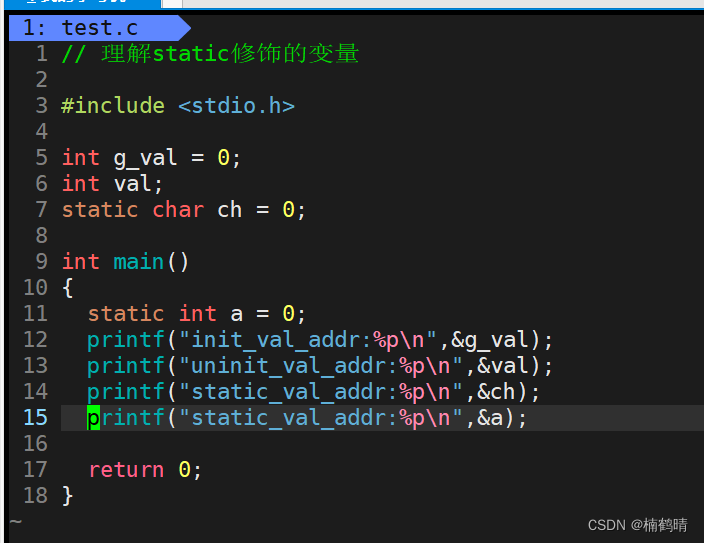
-
自动化构建项目makefile文件
- 实验结果
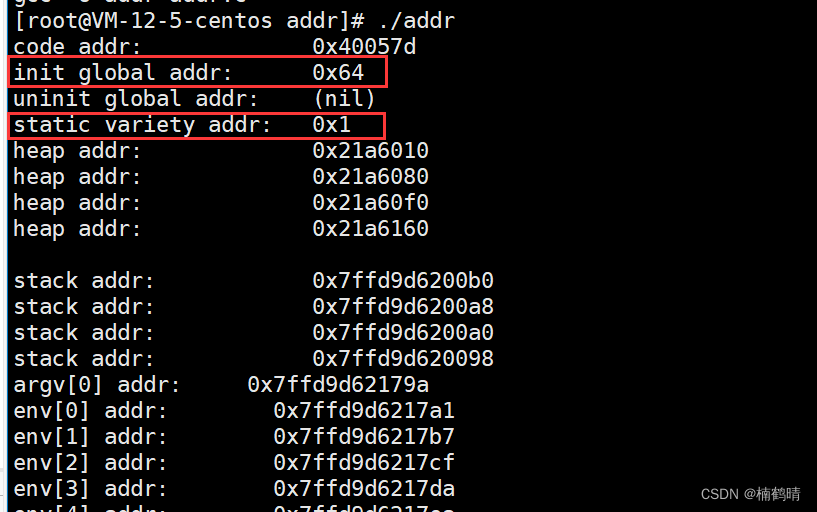
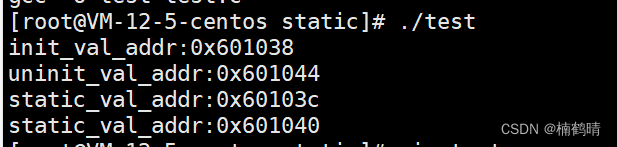
我们通过对比会发现,static修饰的静态局部变量存放的地址和全局变量存放的地址非常接近,其实static修饰局部变量时,该局部变量本质上已经变成了一个全局变量,当函数中的局部变量被
static修饰时,编译器会将其编译进全局区二、进程地址空间
1.物理地址VS虚拟地址
(1).物理地址:指在内存中实实在在存在的位置
(2).虚拟地址:并不是内存中存在的位置,而是通过一个叫页表的转换工具,将内存中的物理地址转化称虚拟地址
(3).物理地址和虚拟地址的关系
这里的虚拟地址就是在我们学习C语言中指针存放的地址,也就是说CPU拿到的是虚拟地址,然后可以通过页表转化成内存中的物理地址进而找到相关的代码2.感知虚拟地址的存在(Linux上验证)
实验思路:利用
fork()创建子进程,从而系统中会多出一个进程,也就是现在有两个进程(父子进程),让父子进程同时访问已经设置好的全局数据,通过修改和不修改两种情况观察实验结果的差异(1).利用全局数据和父子进程进行验证(全局数据不做修改)
- 构建项目:addr.c和makefile
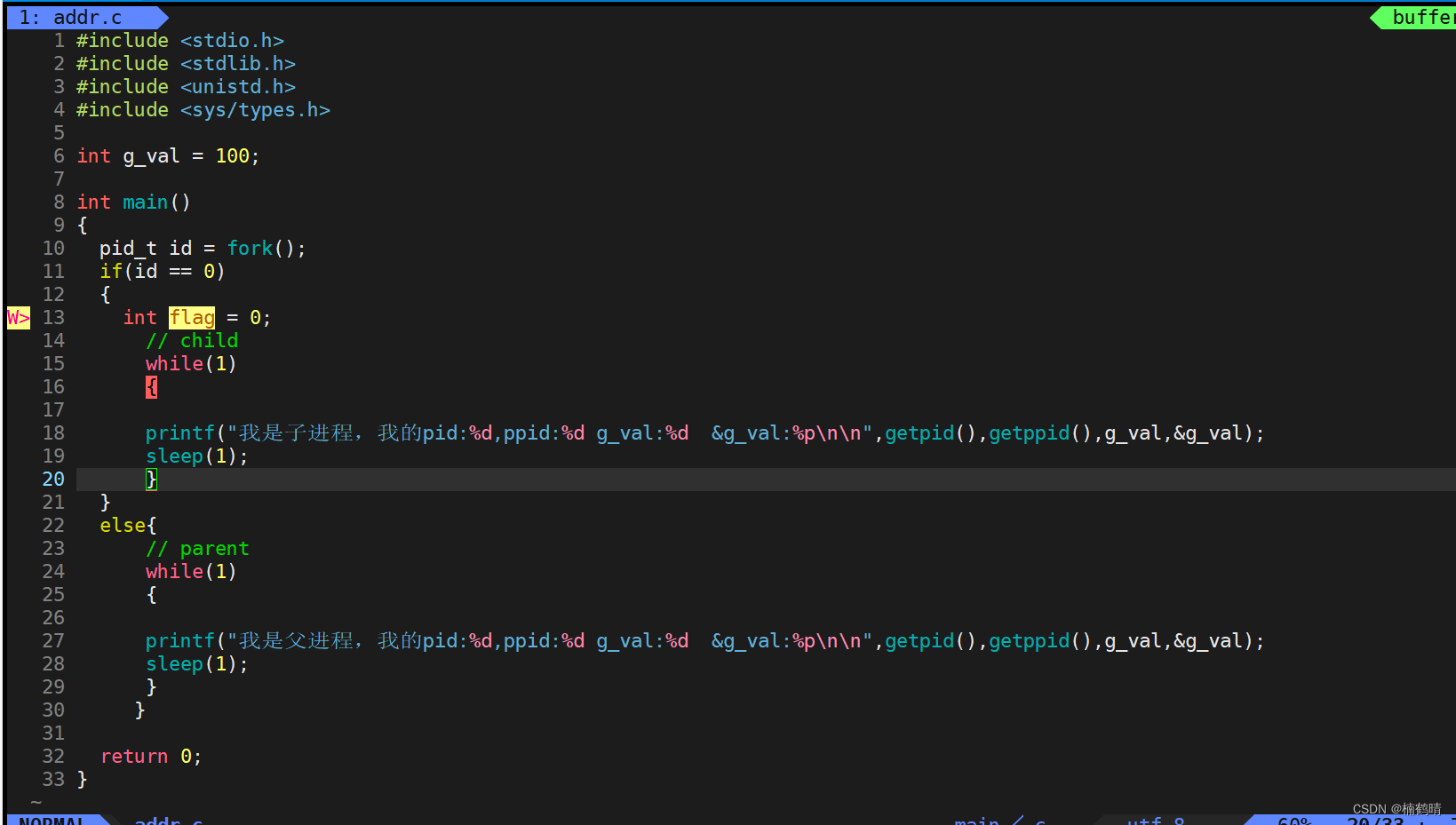
- 实验结果
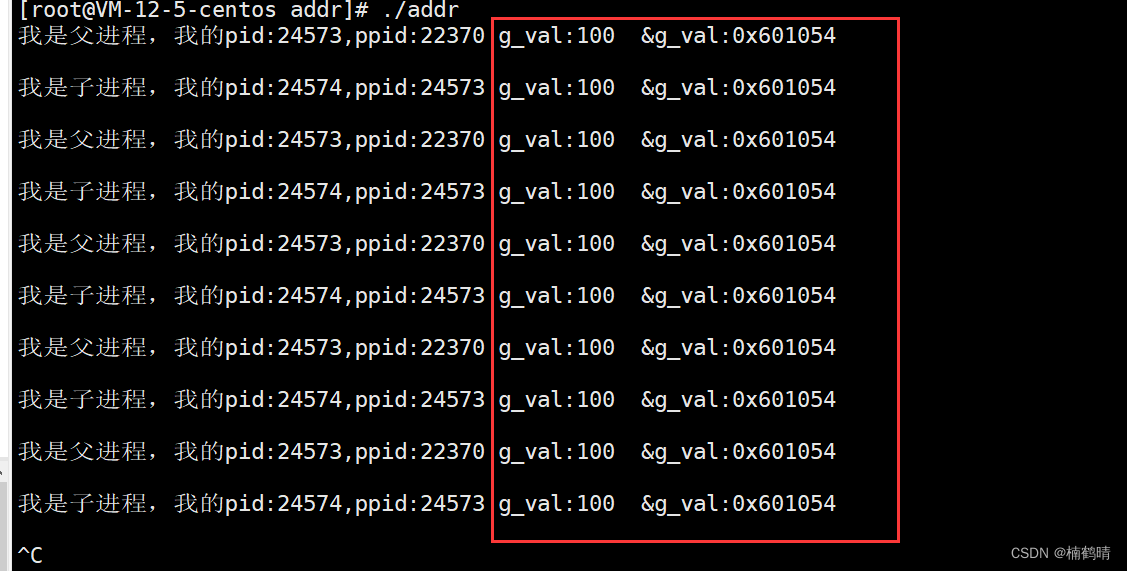
从实验结果我们可以看到,父子进程访问的全局数据g_val是同一个值,并且数据的地址也是同一个地址,因此父子进程共享同一个数据
(2).利用全局数据和父子进程进行验证(全局数据做修改)
- 构建项目:addr.c和makefile文件
- 实验结果
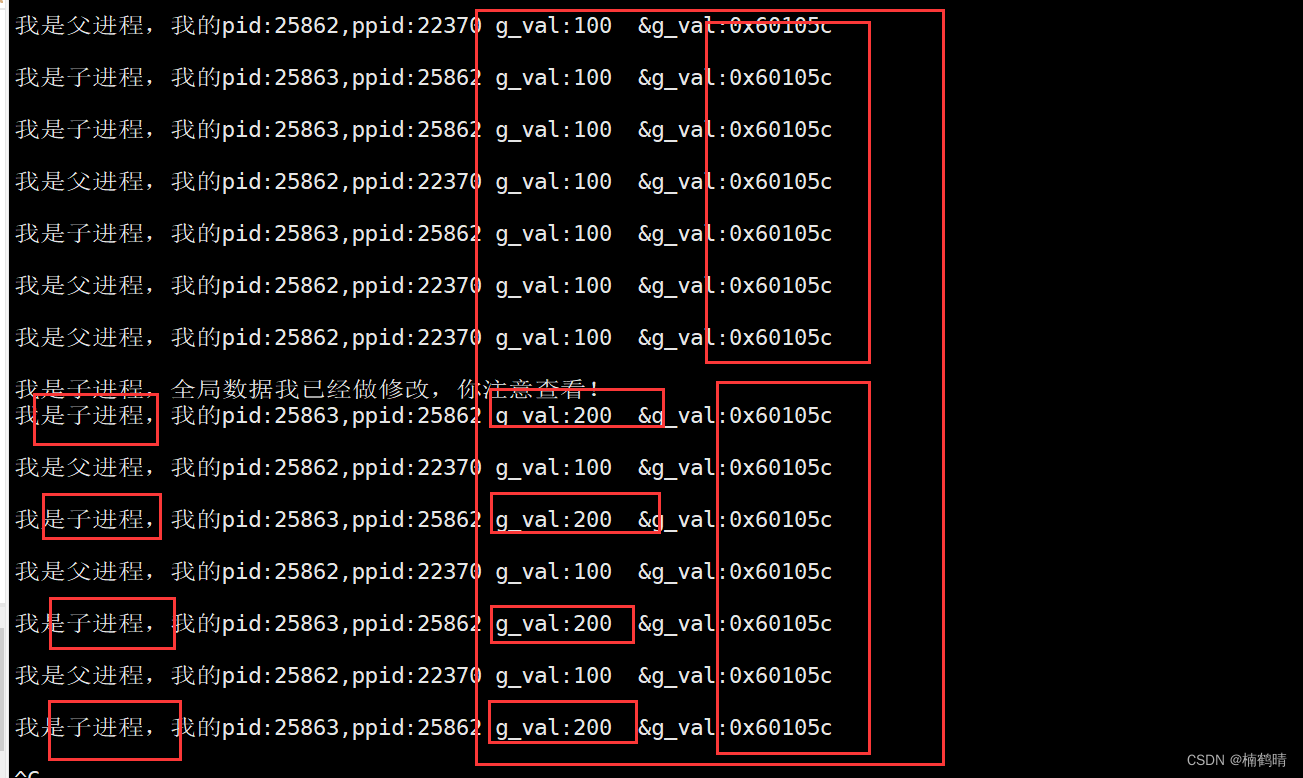
从上面的实验结果可以看出,在5秒之后,我们在子进程中修改了全局数据的内容会出现父子进程的结果是不一样的,我们通过结果可以看到,父子进程访问的全局数据的地址是一样的,但是结果是不一样的,因此,我们可以得出一个结论,这里所指的地址不可能是物理地址,因为同一个地址只能是同一个内容,不可能出现同一个地址存放两个不同的值,其实这里的地址是虚拟地址,不是真正的物理地址,那么具体为什么会出现同一个变量得出两个不同的结果呢?后面会详细讲解
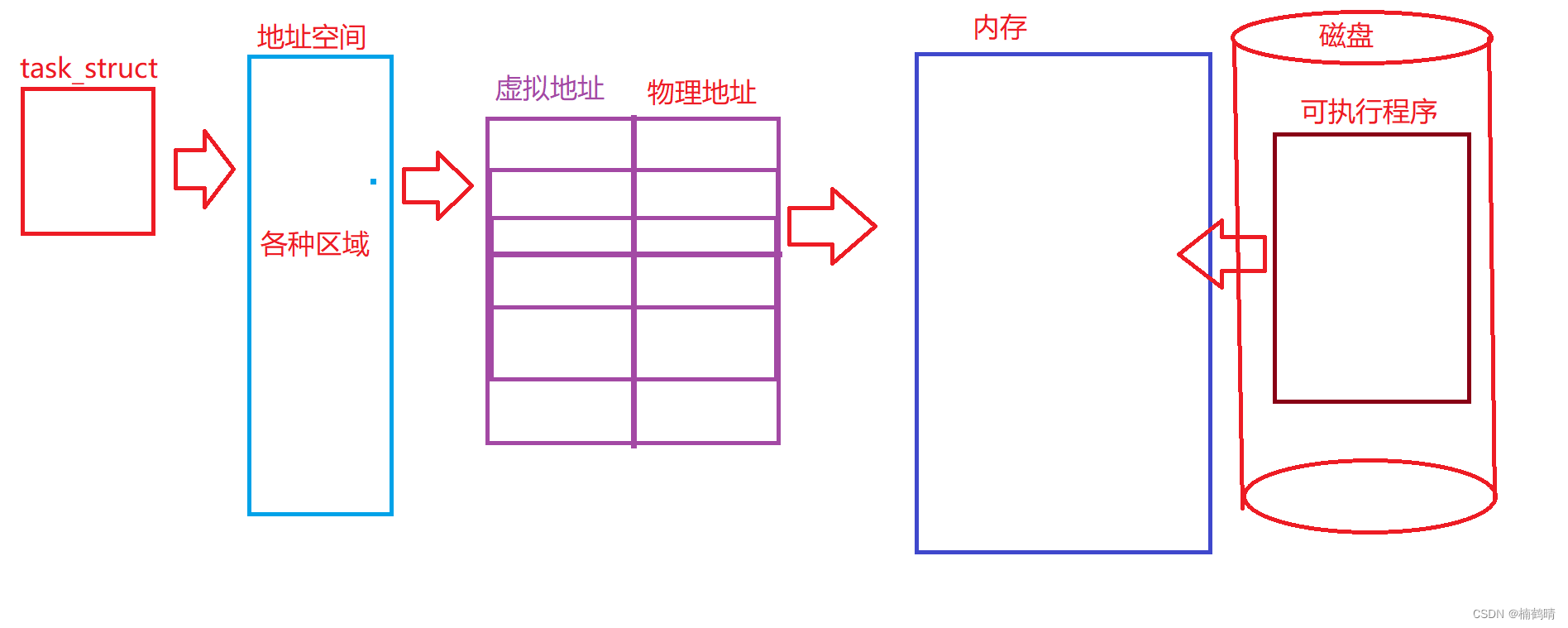
3. 进程地址空间
其实在每一个进程建立的时候,操作系统不仅会为进程创建一个PCB,同时还会为每一个进程创建一个进程地址空间,那么我们就可以知道,每一个进程都有自己独立的进程地址空间,那么这样系统中的进程地址空间就会非常多,操作系统就需要对这些进程地址空间进行管理和控制,而管理的本质就是先描述再组织,描述的意思就是为进程地址空间创建一个结构体,再Linux系统中,这个结构体叫做:
mm_struct,每一个进程都是相对独立,互不影响的,每一个进程中的PCB和mm_struct都是相互独立的,这就是进程的独立性- 进程地址空间的结构
进程地址空间中的结构和前面讲的程序地址空间的结构一样,其中都包含正文代码,初始化数据,未初始化数据,堆区,共享区和栈区,还有命令行参数和环境变量
- 进程地址空间中结构的代码表示
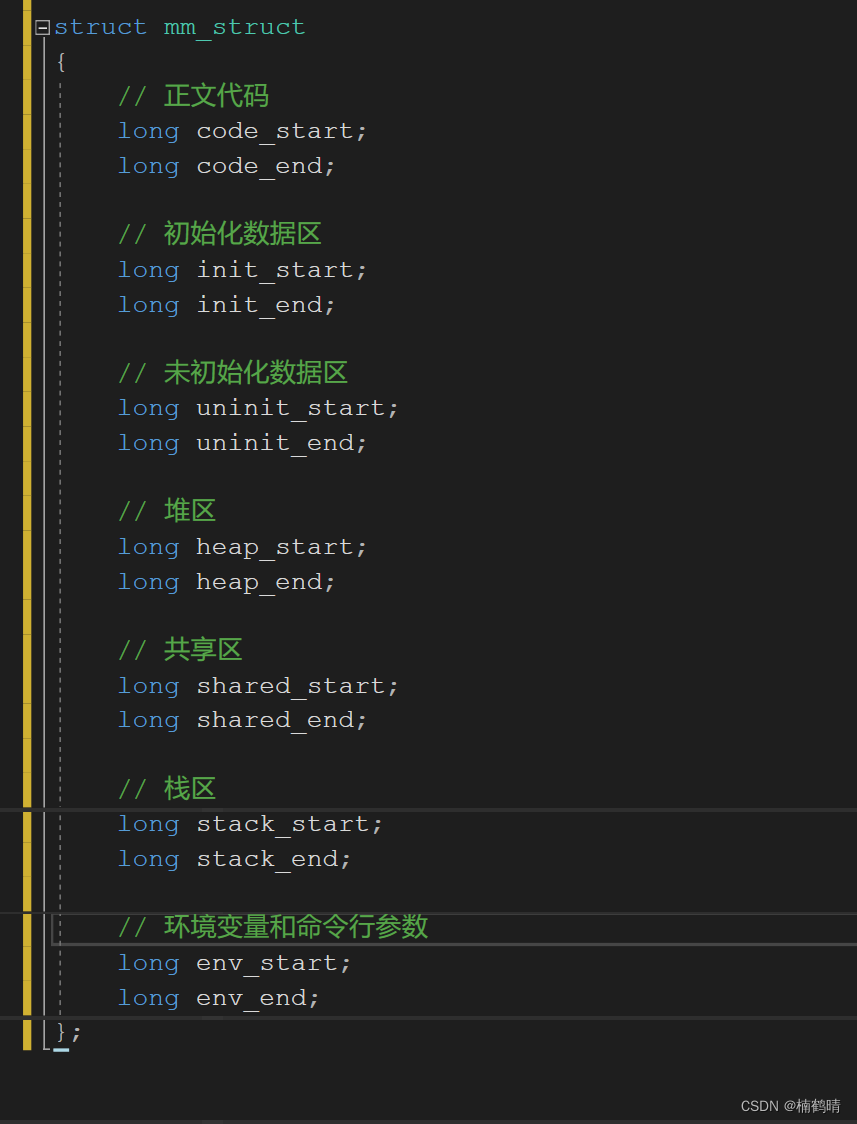
我们可以发现,每一个区域都是由对应的start和end来维护的,也就是说,如果我们向改变对应区域的大小,我们可以通过设置对应区域的start和end进行修改即可,在每一个区域的start和end中会包含很多的地址,这个地址就是所谓的虚拟地址,不是物理地址,物理地址是存在于内存中的,不是存在进程地址空间的
三、程序从磁盘加载到内存的过程(难点)
1.程序被编译但还没有被加载到内存时程序内部是否存在地址?
代码被编译形成可执行程序之后是存在对应的地址的,也就是说程序中的每一段代码在程序中的位置已经确定,这个地址是代码在程序中的地址,与内存中的虚拟地址是没有任何关系的
2.程序被编译但还没有被加载到内存时程序内部是否存在区域?
代码被编译成可执行程序之后,在可执行程序中是存在相关区域的,存在的区域有:正文代码,初始化数据区,未初始化数据区,命令行参数和环境变量,这时需要注意:并不存在栈区和堆区,栈区和堆区是要等程序加载到内存中才存在的
3.物理地址VS虚拟地址
物理地址是在代码在真正的内存中存在的地址(位置)
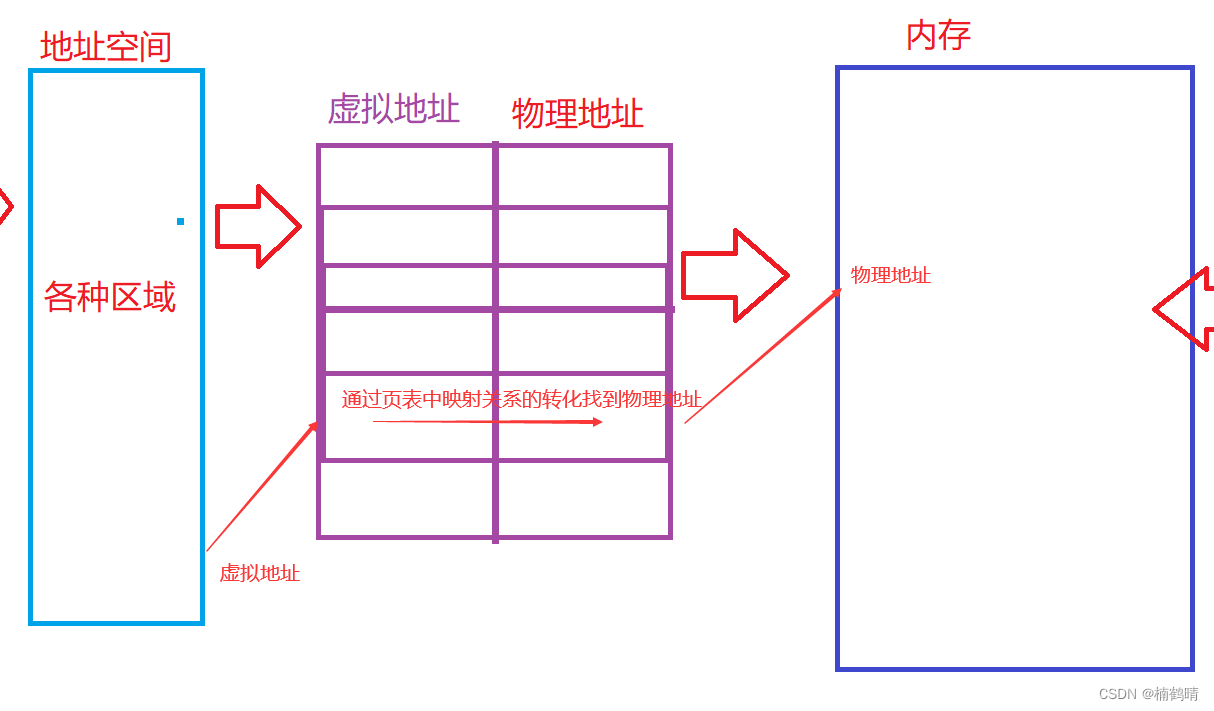
虚拟地址是指CPU直接能够访问到的地址,并不是相关代码在内存中的真实地址,这个虚拟地址的作用就是能够通过页表相关的映射关系转化成代码在内存中的物理地址
因此,我们可以知道,我们一旦有一个代码的虚拟地址还有页表的映射关系,其实就相当于我们有了代码在内存中的物理地址,虚拟地址和物理地址是通过页表建立联系的
4.进程地址空间
进程地址空间是一个内核数据结构
mm_struct,它其实是操作系统给系统中的每一个进程画的一个大饼,就是给系统中的每一个进程一种错觉,让自己觉得自己能够占有整个系统中的所有资源(内存),当程序加载到内存形成进程的时候,操作系统不仅会给进程创建一个PCB,而且还会给每一个进程创建一个进程地址空间,其对应的内核数据机构叫:mm_struct,每一个进程都独自拥有一个进程地址空间 ,每一个进程的进程地址空间中都包含有内存中的各个区域:正文代码,初始化数据,未初始化数据,堆区,共享区,栈区,命令行参数和环境变量,给对应的进程一种错觉就是拥有系统内存的所有资源,其实实际上并不是的,实际上每一个进程只能分到系统内存中的一部分,而不可能拥有系统内存的所有5.页表
页表是进程地址空间和物理内存之间存在的一个工具,其作用就是负责利用其中虚拟地址和物理地址的映射关系实现虚拟地址和物理地址之间的相互转化,也就是说有了虚拟地址和页表,我就可以找到对应的物理地址
6.磁盘
磁盘是代码被编译形成可执行程序之后未加载到内存存在的地方,属于外设
7.程序从磁盘加载到内存的过程(难点)
- 简图

- 载入内存前:代码被编译形成可执行程序之后存在于磁盘中,此时程序中的代码在程序中是存在地址的,这个地址采用相对编址的方式确定,因此,这个地址也成为逻辑地址
- 将程序载入内存:程序载入内存之后,对应的代码在内存中就会确定地址,程序中的代码之间的相对位置是保持不变的,所以载入内存之后,在内存中确定的地址都需要考虑偏移量的问题,这个偏移量与内存和代码在程序中的位置有关系,此时确定出的地址就是虚拟地址
- 构建页表:通过上述形成的虚拟地址映射出对应的物理地址之后就可以形成页表,页表的作用就是方便通过虚拟地址找到对应的物理地址
四、写时拷贝(重要)
写时拷贝是指当数据被修改的时候,系统会在内存中重新为该数据开辟一块新空间,将该数据原来的内存拷贝放到新空间,然后再在新空间对该数据进行修改
1.父子进程访问同一个数据出现两个结果
这个实验的思路很简单,就是利用fork()系统调用接口创建一个子进程,使原本只有一个进程变成了两个进程,然后让两个进程区访问程序中的同一个数据,当我们不对数据进行修改的时候,父子进程访问的数据的结果和数据的地址是一样的,当我们使用父子进程中的任何一个进程对该数据进行修改的话,那么后续继续让父子进程同时访问该数据就会出现不同的结果
- 修改前
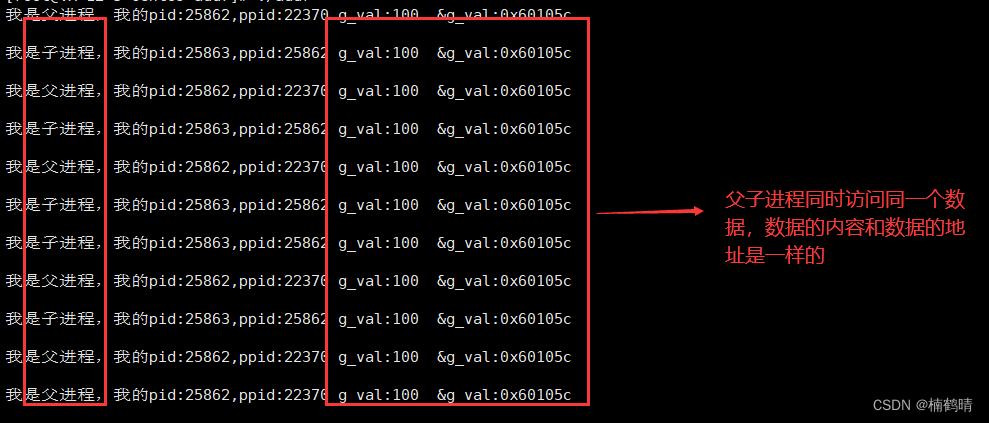
- 修改后
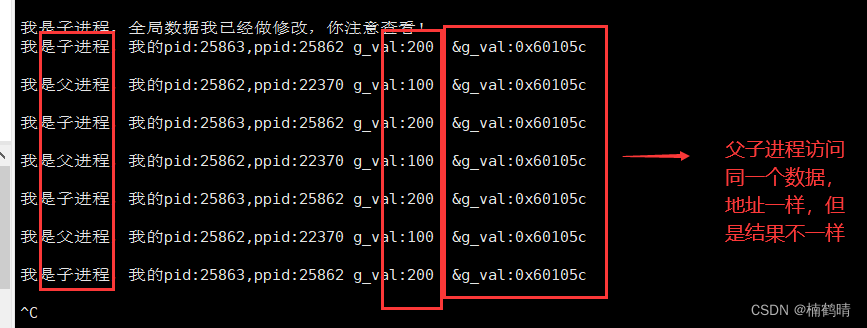
在前面已经说过,这里的地址指的是虚拟地址,而不是物理地址,如果是物理地址,那是不可能出现同一块地址空间出现两个或多个不同的结果的
实际上,在我们对数据进行修改的时候,此过程会发生写时拷贝
具体过程:
像上述的实验,我们是让子进程对数据进行修改,我们这里先以此为例:当系统识别到子进程想要修改该数据的时候,系统会为子进程在内存的另一个地方开辟一块新的空间,然后将该数据原来的值拷贝放到新空间,然后再在新空间对数据进行修改,这个新空间就是该变量在内存中实际存在的物理地址空间,此时操作系统会更新子进程中的页表映射关系,其中改变的是页表中原先映射关系的物理地址,让原先的物理地址更新为更改后的物理地址,因此,我们会发现,父子进程的页表中对该变量的虚拟地址是一样的,但是在子进程对该数据进行修改之后,子进程的页表被重新更新,更新之后映射出的物理地址就是不一样的,因此,此时父子进程访问的其实是两个不同的物理空间中的内容,所以结果就会出现父子进程访问同一个虚拟地址出现不同的结果
修改前
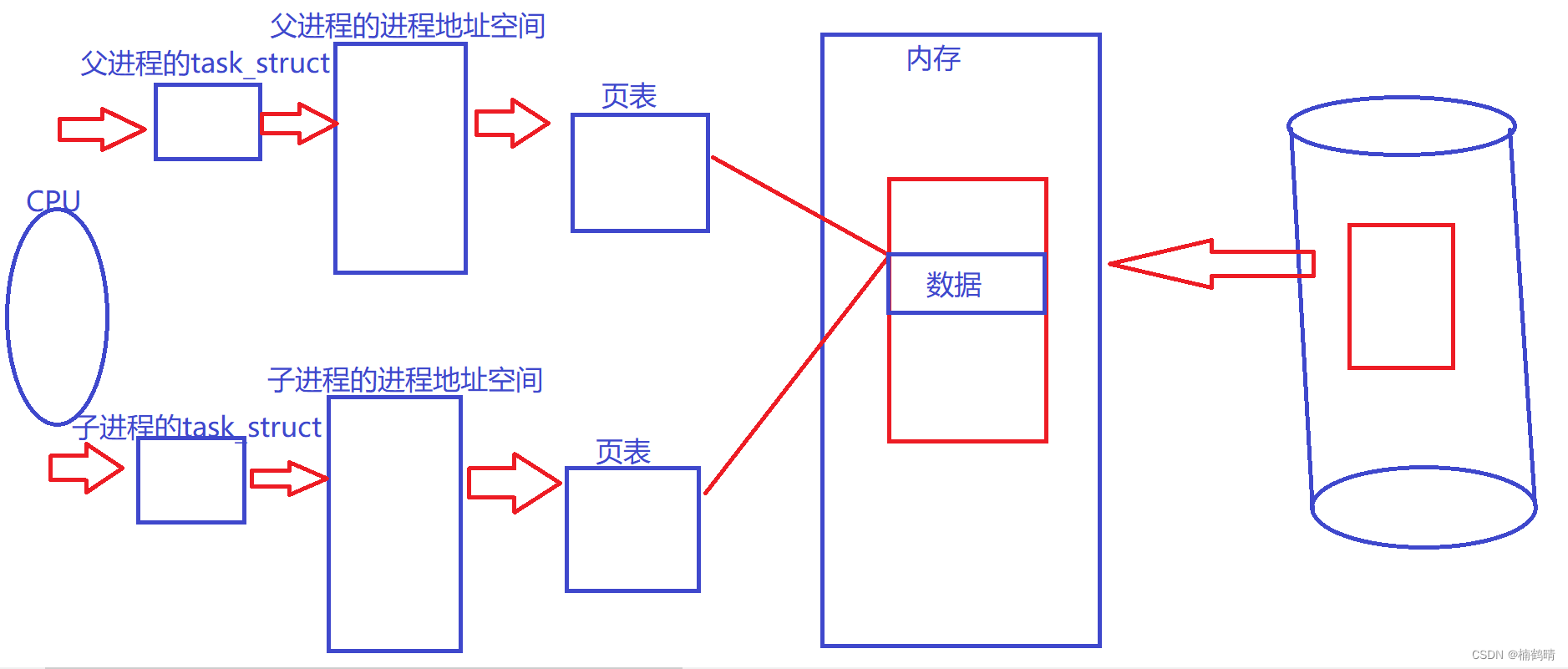
- 发生写时拷贝
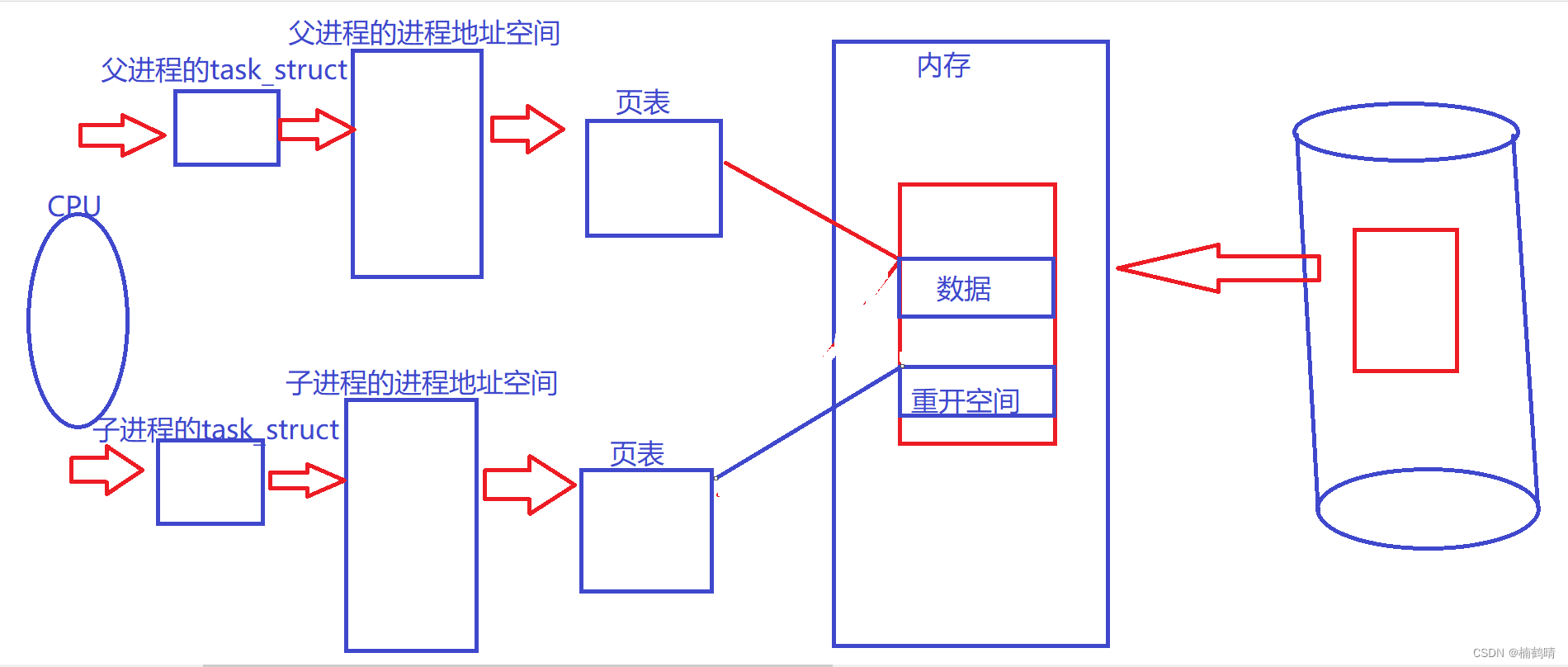
2.解释
fork()调用之后出现两个返回值的问题pid_d id是属于父进程栈空间的变量,fork()函数内部return会被执行两次,return的本质就是将保存在寄存器上的值写入到接收返回值的变量中,当id = fork();的时候,谁先返回,谁就要发生写时拷贝,所以,同一个变量,会有不同的内容,本质是因为这个变量的虚拟地址是一样的,但是会有不同的物理地址,过程和上面的例子差不多
五、进程地址空间存在的意义
1.保护内存
如果没有进程地址空间,那么就是task_struct直接对物理地址进行访问,那么如果有时出现代码写错,出现访问越界,或者野指针,或者指针指向操作系统的代码,那么当我们修改的时候,就会对其他代码造成影响,同时也会会导致物理内存的利用率低下,且访问控制薄弱
2.实现功能模块的解耦
当我们向系统申请一块空间,比如使用malloc函数来申请空间的时候,系统不会马上去实际的物理内存中申请,只会在进程地址空间中的堆区上将对应的区域放大,当系统检测到此时需要访问到那块内存的时候,系统才会马上向内存申请对应空间,这样就大大地增大了内存资源的利用率
3.简化进程的设计与实现
程序编译时确定的地址都是虚拟地址,但是访问的时候操作系统会将这个虚拟地址在页表中映射得到物理内存地址,进而访问物理内存区域,这样的话,每个进程都有自己独立的虚拟地址,跟其他进程互不影响,但是数据可以在物理内存任意位置存储,因为可以通过页表映射访问到实际物理存储的位置,实现了数据在物理内存上的离散存储,提高了内存利用率,并且可以在页表中对地址访问加以权限访问,提高了内存访问控制,程序运行时,其中中的数据和指令被打散在物理内存中存储,同时在页表中记录对应数据虚拟地址和物理地址的映射关系,以便于进程在虚拟地址访问的时候,操作系统能够通过映射找到物理地址进而访问物理内存
-
相关阅读:
Profile注解
[Mac软件]Adobe Illustrator 2024 28.3 intel/M1/M2/M3矢量图制作软件
字节跳动岗位薪酬体系曝光,看完感叹:不服不行
机器人过程自动化(RPA)入门 5. 处理应用程序中的控件
微信小程序反编译 2024 unveilr.exe
不同层设置不同学习率
腾讯云服务器CVM和轻量应用服务器区别全方位对比
一个Binder的前生今世 (一):Service的创建
西门子S7-1500作为智能设备共享功能
刷题记录(NC13822 Keep In Line,NC16663 合并果子,NC16430 蚯蚓)
- 原文地址:https://blog.csdn.net/m0_63019745/article/details/127991532