1.背景
分类神经网络模型:Mobilenetv3。
深度学习框架:PyTorch。
Mobilenetv3简单的手写数字识别:
- 任务输入:一系列手写数字图片,其中每张图片都是28x28的像素矩阵。
- 任务输出:经过了大小归一化和居中处理,输出对应的0~9数字标签。
项目参考代码:https://github.com/wuya11/easy-classification
1.1 说明
本文基于Mobilenetv3神经网络,识别数字分类。将分类模型的训练,验证等流程分解,逐一详细说明并做适当扩展讨论。本文适合有一定深度学习理论知识的读者,旨在基于理论结合代码,阐述分类神经网络的一般流程。背景资料参考如下:
- 深度学习理论知识:参考黄海广博士组织翻译的吴恩达深度学习课程笔记,链接:《深度学习笔记》
- Pytorch常用函数,nn.Module,加载数据等功能,参考链接:《Pytorch中文文档》
- Mobilenetv3分类,了解卷积网络构建参数,开始输入和最终网络模型输出size,不做过多底层的了解。参考链接:《Mobilenetv3解析》
1.2 数据集来源
下载开源的训练图片库:http://yann.lecun.com/exdb/mnist/。
在项目根目录下新建data目录用于放置训练集,测试集,验证集数据。执行项目中make_fashionmnist.py脚本,解压文件,最终得到神经网络的训练数据,参考如图:

说明:
- 标签生成为目录,每个目录里面为具体的数字图片。比如0目录的图片均是手写数字为0的图片。
- 每个图像解析后,size为28*28。(若后续模型的入参需求为224*224,可以在此处调整图像大小。但不建议在一开始就修改,在图像转为张量处调整更合理,不同的模型入参不一定相同)
- 训练集、验证集和测试集各自的作用,参考说明:《数据集说明》
1.3 构建神经网络模型
构建神经网络模型基本流程如下:
参考教程:《深度学习入门必看-手写数字识别》
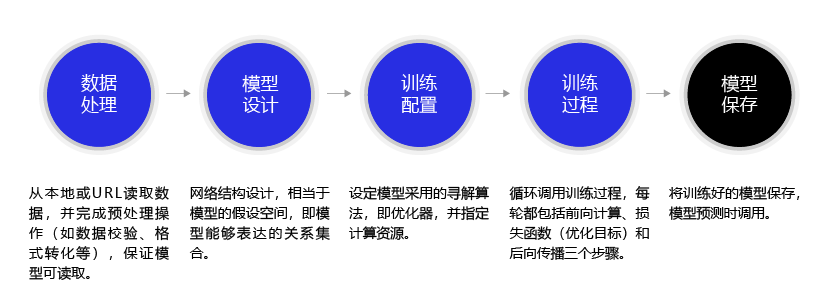

2.数据处理
2.1 加载配置文件
定义项目中的配置信息,方便统一设置参数,便于修改和维护。举例config.py部分配置如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | cfg = { ### Global Set "model_name": "mobilenetv3", #shufflenetv2 adv-efficientnet-b2 se_resnext50_32x4d xception "class_number": 10, "random_seed":42, "cfg_verbose":True, "num_workers":4, ### Train Setting 'train_path':"./data/train", 'val_path':"./data/val", ### Test 'model_path':'output/mobilenetv3_e50_0.77000.pth',#test model 'eval_path':"./data/test",#test with label,get test acc 'test_path':"./data/test",#test without label, just show img result ### 更多参考项目中的config.py文件 } |
调用配置信息
from config import cfg path=cfg["train_path"] #获取config文件中的train_path变量
2.2 加载训练集图片信息

2.2.1 获取原始图像
从图像目录下加载图像信息,部分代码参考如下:

train_data = getFileNames(self.cfg['train_path']) val_data = getFileNames(self.cfg['val_path']) def getFileNames(file_dir, tail_list=['.png','.jpg','.JPG','.PNG']): L=[] for root, dirs, files in os.walk(file_dir): for file in files: if os.path.splitext(file)[1] in tail_list: L.append(os.path.join(root, file)) return L
2.2.2 原始图像调整
针对训练集数据,需随机打乱处理。若训练数据较大,一次只想获取部分数据训练,可做一个配置参数设置训练数目,基于参数动态调整。图像调整部分代码参考如下:
# 随机处理训练集 train_data.sort(key = lambda x:os.path.basename(x)) train_data = np.array(train_data) random.shuffle(train_data) # 调整训练时的数据量 if self.cfg['try_to_train_items'] > 0: train_data = train_data[:self.cfg['try_to_train_items']] val_data = val_data[:self.cfg['try_to_train_items']]
2.2.3 图像调整
本例基于Mobilenetv3神经网络处理分类,入参图像大小为224*224(每个模型的入参图像大小不一定相同,可基于配置文件设置,如"img_size": [224, 224])。由于基础训练图像大小为28*28。需做训练图像调整,部分代码参考如下:
class TrainDataAug: def __init__(self, img_size): self.h = img_size[0] self.w = img_size[1] def __call__(self, img): # opencv img, BGR img = cv2.resize(img, (self.h,self.w)) img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) img = Image.fromarray(img) return img
2.2.4 图像生成张量
图像生成张量,主要使用transforms.Compose()函数,做图像处理。相关知识点参考:
图像生成张量信息,部分代码参考如下:
my_normalize = getNormorlize(cfg['model_name']) data_aug_train = TrainDataAug(cfg['img_size']) transforms.Compose([ # 调整图像大小 data_aug_train, # 图像转换为张量 transforms.ToTensor(), # 归一化处理 my_normalize, ])
归一化参数配置,不同模型的值不一样,参考如下(归一化参数值可参考网络,论文等获取):
def getNormorlize(model_name): if model_name in ['mobilenetv2','mobilenetv3']: my_normalize = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) elif model_name == 'xception': my_normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) elif "adv-eff" in model_name: my_normalize = transforms.Lambda(lambda img: img * 2.0 - 1.0) elif "resnex" in model_name or 'eff' in model_name or 'RegNet' in model_name: my_normalize = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) #my_normalize = transforms.Normalize([0.4783, 0.4559, 0.4570], [0.2566, 0.2544, 0.2522]) elif "EN-B" in model_name: my_normalize = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) else: print("[Info] Not set normalize type! Use defalut imagenet normalization.") my_normalize = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) return my_normalize
自定义一个Dataset对象,重写__getitem__方法:
class TensorDatasetTestClassify(Dataset): def __init__(self, train_jpg, transform=None): self.train_jpg = train_jpg if transform is not None: self.transform = transform else: self.transform = None def __getitem__(self, index): img = cv2.imread(self.train_jpg[index]) if self.transform is not None: img = self.transform(img) return img, self.train_jpg[index] def __len__(self): return len(self.train_jpg)
图像生成为张量,基于DataLoade数据加载器。DataLoade组合数据集和采样器,并在数据集上提供单进程或多进程迭代器。参考链接:《DataLoader 使用说明》。部分代码参考:
分组说明:比如存在1000条数据,每64条数据为一组,可分为1000/64=15.625 组,不能整除时,最后一组会drop_last 参数做剔除或是允许该组数据不完整。迭代器为16组,在一次训练时,会循环16次跑完训练的数据。
my_dataloader = TensorDatasetTestClassify train_data = getFileNames(self.cfg['train_path']) train_loader = torch.utils.data.DataLoader( my_dataloader(train_data, transforms.Compose([ data_aug_train, transforms.ToTensor(), my_normalize, ])), batch_size=cfg['batch_size'], shuffle=True, num_workers=cfg['num_workers'], pin_memory=True)
2.2.5 小节总结
- 获取到原始图像信息时,需要随机打乱图像,避免训练集精度问题。
- 基于Pytorch 框架,自定义DataSet时,需定义item返回的对象信息(返回图片信息,图片张量信息,标签信息等可自定义)。
- 图像转换为张量时,引入归一化,对生成的张量信息做处理。
- DataLoade数据加载器,分组跑数据,提升效率,也可以自行编写for实现,但框架已有,调用框架的方便。
2.3 加载其他图片信息
加载验证集图片信息,加载测试集图片信息,流程同加载训练图片信息一致,根据实际需求可做部分逻辑调整。
3.模型设计
3.1 Pytorch 构建网络
- 经典的网络模型,目前均可在网上找到开源的网络模型构建代码。Pytorch也封装了部分网络模型的代码,详情参考:《torchvision.models》
- 自定义网络模型,主要是构建网络骨干,基于卷积层,激活函数等组合使用。最后根据任务分类,构建对应的全连接层。详情参考:《PyTorch-OpCounter》,《构建神经网络常用实现函数》
- 构建Mobilenetv3网络,可直接调用torchvision.models中已经封装好的模型。自定义实现也可参考《Pytorch:图像分类经典网络_MobileNet(V1、V2、V3)》
3.2 预训练模型
预训练模型是在大型基准数据集上训练的模型,用于解决相似的问题。由于训练这种模型的计算成本较高,因此,导入已发布的成果并使用相应的模型是比较常见的做法。
加载预训练权重时,需注意是不同硬件资源之间的差异(GPU模型权重加载到CPU或其他转换),加载预训练常规异常及处理方案参考:《PyTorch加载模型不匹配处理》。
预训练模型加载参考代码:
self.pretrain_model = MobileNetV3() # 预训练模型权重路径 if self.cfg['pretrained']: state_dict = torch.load(self.cfg['pretrained']) # 模型与预训练不一致时,逻辑处理 state_dict = {k.replace('pretrain_', ''):v for k, v in state_dict.items()} state_dict = {k.replace('model.', ''): v for k, v in state_dict.items()} # 跳过不一致的地方 self.pretrain_model.load_state_dict(state_dict,False)
3.3 构建全连接层
全连接层是2维张量与2维张量的转换,主要是骨干层输出特征信息后,比如维度为1028,实际任务分类只需要10类,此刻需要建立全连接层做转换。构建全连接层相关知识参考如下:
构建一个网络模型时,需定义模型的输出函数,在此处接入全连接层,参考代码如下:
def forward(self, x): x = self.features(x) x = x.mean(3).mean(2) #张量维度换 4转2 last_channel=1280 # mobilenetv3 large最终输出为1280 # 构建一个全连接层 self.classifier = nn.Sequential( nn.Dropout(p=dropout), # refer to paper section 6 nn.Linear(last_channel, 10), #数字0-9共10个分类 x = self.classifier(x) return x

3.4 小节总结
- 经典网络的实现,可当作黑盒对待。不做过多深入的研究。参考网络模型实现代码时,注意开始的输入张量和最终骨干网络的输出张量信息。
- 网上部分博客,关于Mobilenetv3-small,最终输出有写 1280,也有写1024的,参考论文应该是1024,最终层这种也可自定义,但建议还是以论文为准。
- 选用一个经典的网络模型,主要是使用其骨干层训练的结果,在根据自身任务的分类特性,做全连接层处理。
- 训练一个新任务时,根据使用的分类模型,一般不建议从零开始训练,可基于已经存在的模型权重,做预训练微调处理。
4.训练配置
训练配置需定义训练过程中使用的硬件资源信息,优化器,损失函数,学习率调整策略等。部分代码参考如下:
class ModelRunner(): def __init__(self, cfg, model): # 定义加载配置文件 self.cfg = cfg # 定义设备信息 if self.cfg['GPU_ID'] != '' : self.device = torch.device("cuda") else: self.device = torch.device("cpu") self.model = model.to(self.device) # gpu加速,cpu模式无效 self.scaler = torch.cuda.amp.GradScaler() # loss 定义损失函数 self.loss_func = getLossFunc(self.device, cfg) # 定义优化器 self.optimizer = getOptimizer(self.cfg['optimizer'], self.model, self.cfg['learning_rate'], self.cfg['weight_decay']) # 定义调整学习率的策略 self.scheduler = getSchedu(self.cfg['scheduler'], self.optimizer)
4.1 设备硬件资源
判断服务器是否支持GPU,可查看《torch.cuda》。特别注意硬件的特性,如预训练加载时,保存的模型权重是基于GPU的,若加载时采用CPU模式,会报错。
4.2 损失函数
损失函数相关知识参考链接:
定义一个多分类CrossEntropyLoss:
class CrossEntropyLoss(nn.Module): def __init__(self, label_smooth=0, weight=None): super().__init__() self.weight = weight self.label_smooth = label_smooth self.epsilon = 1e-7 def forward(self, x, y, sample_weights=0, sample_weight_img_names=None): one_hot_label = F.one_hot(y, x.shape[1]) if self.label_smooth: one_hot_label = labelSmooth(one_hot_label, self.label_smooth) #y_pred = F.log_softmax(x, dim=1) # equal below two lines y_softmax = F.softmax(x, 1) #print(y_softmax) y_softmax = torch.clamp(y_softmax, self.epsilon, 1.0-self.epsilon)# avoid nan y_softmaxlog = torch.log(y_softmax) # original CE loss loss = -one_hot_label * y_softmaxlog loss = torch.mean(torch.sum(loss, -1)) return loss
4.3 优化器
训练过程采用二层循环嵌套方式,训练完成后需要保存模型参数,以便后续使用。
- 内层循环:负责整个数据集的一次遍历,遍历数据集采用分批次(batch)方式。
- 外层循环:定义遍历数据集的次数,如训练中外层循环100次,训练次数可通过配置参数设置。
优化器应用于内层循环,优化器相关知识参考链接:《torch.optim》,《优化算法Optimizer比较和总结》,常用优化器代码参考:
def getOptimizer(optims, model, learning_rate, weight_decay): if optims=='Adam': optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay) elif optims=='AdamW': optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) elif optims=='SGD': optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, weight_decay=weight_decay) elif optims=='AdaBelief': optimizer = AdaBelief(model.parameters(), lr=learning_rate, eps=1e-12, betas=(0.9,0.999)) elif optims=='Ranger': optimizer = Ranger(model.parameters(), lr=learning_rate, weight_decay=weight_decay) else: raise Exception("Unkown getSchedu: ", optims) return optimizer
4.4 学习率调整
scheduler 相关知识参考:《PyTorch中的optimizer和scheduler》,《训练时的学习率调整知识》。scheduler.step()按照Pytorch的定义是用来更新优化器的学习率的,一般是按照epoch为单位进行更换,即多少个epoch后更换一次学习率,因而scheduler.step()一般放在epoch这个大循环下。学习率调整相关代码参考:
def getSchedu(schedu, optimizer): if 'default' in schedu: factor = float(schedu.strip().split('-')[1]) patience = int(schedu.strip().split('-')[2]) scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=factor, patience=patience,min_lr=0.000001) elif 'step' in schedu: step_size = int(schedu.strip().split('-')[1]) gamma = int(schedu.strip().split('-')[2]) scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma, last_epoch=-1) elif 'SGDR' in schedu: T_0 = int(schedu.strip().split('-')[1]) T_mult = int(schedu.strip().split('-')[2]) scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=T_0, T_mult=T_mult) elif 'multi' in schedu: milestones = [int(x) for x in schedu.strip().split('-')[1].split(',')] gamma = float(schedu.strip().split('-')[2]) scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=gamma, last_epoch=-1) else: raise Exception("Unkown getSchedu: ", schedu) return scheduler
4.5 小节总结
- 在训练之前,首先确定硬件环境,cpu跑的慢,能用GPU的,优先使用GPU。Pytorch版本安装时,也需根据硬件配置选择,安装地址:《Pytorch Get Start》。
- 损失函数可用Pytorch封装了常用损失函数,或参考数学公式自定义编写。损失函数实现逻辑可不过分深究,当作黑盒模式对待。正确传入损失函数入参的参数,在不同任务场景下,测试或参考论文,选择或编写合适的损失函数。
- 优化器,学习率调整均可当作黑盒模式对待。会传参和调用即可。优化器,学习率存在多种解决方案,在不同任务场景下,测试或参考论文,选择合适该任务的方案。
5.训练过程
5.1 训练流程概述
一个完整的训练过程,包括多次对准备的全量训练集数据,验证集数据做迭代处理。执行过程参考代码如下:
def train(self, train_loader, val_loader): # step 1:定义训练开始时一些全局的变量,如是否过早停止表示,执行时间等 self.onTrainStart() # step 2: 外层大轮询次数,每次轮询 全量 train_loader,val_loader for epoch in range(self.cfg['epochs']): # step 3: 非必须,过滤处理部分次数,做冻结训练处理 self.freezeBeforeLinear(epoch, self.cfg['freeze_nonlinear_epoch']) # step 4: 训练集数据处理 self.onTrainStep(train_loader, epoch) # step 5: 验证集数据处理,最好训练模型权重保存,过早结束逻辑处理 self.onValidation(val_loader, epoch) # step 6: 满足过早结束条件时,退出循环,结束训练 if self.earlystop: break # step 7:训练过程结束,释放资源 self.onTrainEnd()
5.2 冻结训练
冻结训练其实也是迁移学习的思想,在目标检测任务中用得十分广泛。因为目标检测模型里,主干特征提取部分所提取到的特征是通用的,把backbone冻结起来训练可以加快训练效率,也可以防止权值被破坏。在冻结阶段,模型的主干被冻结了,特征提取网络不发生改变,占用的显存较小,仅对网络进行微调。在解冻阶段,模型的主干不被冻结了,特征提取网络会发生改变,占用的显存较大,网络所有的参数都会发生改变。精确冻结指定网络层参考链接:《精确冻结模型中某一层参数》
冻结整个网络层参考代码:
# freeze_epochs :设置冻结的标识,小于该值时冻结 # epoch: 轮询次数值,从0开始 def freezeBeforeLinear(self, epoch, freeze_epochs=2): if epoch < freeze_epochs: for child in list(self.model.children())[:-1]: for param in child.parameters(): param.requires_grad = False # 等于标识值后,解冻 elif epoch == freeze_epochs: for child in list(self.model.children())[:-1]: for param in child.parameters(): param.requires_grad = True
5.3 训练数据
训练数据按批次处理,如总训练集1000条,64条数据为一批。内部循环1000/64次,批次轮询时,更新优化器信息,重新计算梯度(如从山顶向谷底走,逐步下降)。训练过程优化处理,参考链接:《Torch优化训练的17种方法》,《训练过程梯度调整》,训练参考代码:
# 定义模型为训练 self.model.train() # 轮询处理批次数据 for batch_idx, (data, target, img_names) in enumerate(train_loader): one_batch_time_start = time.time() # 来源于dataset对象,item中定义的对象 target = target.to(self.device) # 张量复制到硬件资源上 data = data.to(self.device) # gpu模式下,加快训练,混合精度 with torch.cuda.amp.autocast(): # 模型训练输出张量,参考模型定义的forward返回方法 output = self.model(data).double() # 计算损失函数,可自定义或调用PyTorch常用的 loss = self.loss_func(output, target, self.cfg['sample_weights'], sample_weight_img_names=img_names) # 一个batchSize 求和 total_loss += loss.item() # 把梯度置零 self.optimizer.zero_grad() # loss.backward() #计算梯度 # self.optimizer.step() #更新参数 # 基于GPU scaler 加速 self.scaler.scale(loss).backward() self.scaler.step(self.optimizer) self.scaler.update() ### 返回 batchSize个最大张量值对应的数组下标值 pred = output.max(1, keepdim=True)[1] # 训练图像对应的 分类标签 if len(target.shape) > 1: target = target.max(1, keepdim=True)[1] # 统计一组数据batchSize 中训练出来的分类值与 实际图像分类标签一样的数据条数 correct += pred.eq(target.view_as(pred)).sum().item() # 统计总训练数据条数 count += len(data) # 计算准确率 train_acc = correct / count train_loss = total_loss / count
5.4 验证数据
验证数据流程同训练数据流程类似,但不需要求导,更新梯度等流程,参考代码如下:
# 定义模型为验证 self.model.eval() # 重点,验证流程定义不求导 with torch.no_grad(): pres = [] labels = [] # 基于批次迭代验证数据 for (data, target, img_names) in val_loader: data, target = data.to(self.device), target.to(self.device) # GPU下加速处理 with torch.cuda.amp.autocast(): # 模型输出张量,参考模型定义的forward返回方法 output = self.model(data).double() # 定义交叉损失函数 self.val_loss += self.loss_func(output, target).item() # sum up batch loss pred_score = nn.Softmax(dim=1)(output) # print(pred_score.shape) pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability if self.cfg['use_distill']: target = target.max(1, keepdim=True)[1] # 真实值与验证值一致求和数量 self.correct += pred.eq(target.view_as(pred)).sum().item() batch_pred_score = pred_score.data.cpu().numpy().tolist() batch_label_score = target.data.cpu().numpy().tolist() pres.extend(batch_pred_score) labels.extend(batch_label_score) # print('\n',output[0],img_names[0]) pres = np.array(pres) labels = np.array(labels) # print(pres.shape, labels.shape) self.val_loss /= len(val_loader.dataset) # 计算准确率 self.val_acc = self.correct / len(val_loader.dataset) # 当次值记录为最优,后续应用和历史最优值做比较 self.best_score = self.val_acc
5.5 保存最优的模型权重
单次模型验证结束后,会通过如acc,F1 score等维度评估模型的效果,记录该次验证的评分。外部循环多次时,最终记录最优的一次验证结果,保存为模型的最优权重。
保存模型权重参考代码如下:
def checkpoint(self, epoch): # 当前值小于历史记录的值时 if self.val_acc <= self.early_stop_value: if self.best_score <= self.early_stop_value: if self.cfg['save_best_only']: pass else: save_name = '%s_e%d_%.5f.pth' % (self.cfg['model_name'], epoch + 1, self.best_score) self.last_save_path = os.path.join(self.cfg['save_dir'], save_name) self.modelSave(self.last_save_path) else: # 保存最优权重信息 if self.cfg['save_one_only']: if self.last_save_path is not None and os.path.exists(self.last_save_path): os.remove(self.last_save_path) save_name = '%s_e%d_%.5f.pth' % (self.cfg['model_name'], epoch + 1, self.best_score) self.last_save_path = os.path.join(self.cfg['save_dir'], save_name) torch.save(self.model.state_dict(), save_name)
5.6 提前终止
模型在验证集上的误差在一开始是随着训练集的误差的下降而下降的。当超过一定训练步数后,模型在训练集上的误差虽然还在下降,但是在验证集上的误差却不在下降了。此时模型继续训练就会出现过拟合情况。因此可以观察训练模型在验证集上的误差,一旦当验证集的误差不再下降时,就可以提前终止训练的模型。相关知识参考:《深度学习技巧之Early Stopping》
提前终止参考代码如下:
def earlyStop(self, epoch): ### earlystop 配置下降次数,如当前值小于历史值出现7次,就提前终止 if self.val_acc > self.early_stop_value: self.early_stop_value = self.val_acc if self.best_score > self.early_stop_value: self.early_stop_value = self.best_score self.early_stop_dist = 0 self.early_stop_dist += 1 if self.early_stop_dist > self.cfg['early_stop_patient']: self.best_epoch = epoch - self.cfg['early_stop_patient'] + 1 print("[INFO] Early Stop with patient %d , best is Epoch - %d :%f" % ( self.cfg['early_stop_patient'], self.best_epoch, self.early_stop_value)) self.earlystop = True if epoch + 1 == self.cfg['epochs']: self.best_epoch = epoch - self.early_stop_dist + 2 print("[INFO] Finish trainging , best is Epoch - %d :%f" % (self.best_epoch, self.early_stop_value)) self.earlystop = True
5.7 释放资源
训练验证结束后,及时清空缓存,垃圾回收处理释放内存。
def onTrainEnd(self): # 删除模型实例 del self.model # 垃圾回收 gc.collect() # 清空gpu上面的缓存 torch.cuda.empty_cache()
5.8 小节总结
- 训练过程综合使用了损失函数,优化器,学习率,梯度下降等知识,一般基于内外两个大循环训练数据,最终产生模型的权重参数,并保存下来。
- 保存的模型权重可用于评估和实际使用。也可以当作其他任务的预加载模型权重。
- 训练过程是训练集数据,验证集数据交替进行的,单独的只进行训练集数据的处理无明细意义。
- 训练集数据需要求导(冻结训练层除外),做前向计算和反向传播处理。验证集不需要,在训练之后,只做验证结果的评分处理。
6.评估与应用
6.1 评估与应用
模型训练结束后,保存模型权重信息。在评估和预测图像分类时,加载模型权重信息。加载评估数据模型和加载训练集数据的模式一样。(若评估的图像与模型入参不一致,需转换调整),模型评估参考如下代码:
# 加载训练的模型权重 runner.modelLoad(cfg['model_path']) # 评估跑数据 runner.evaluate(train_loader) # 评估函数 def evaluate(self, data_loader): self.model.eval() correct = 0 # 验证不求导 with torch.no_grad(): pres = [] labels = [] for (data, target, img_names) in data_loader: data, target = data.to(self.device), target.to(self.device) with torch.cuda.amp.autocast(): output = self.model(data).double() pred_score = nn.Softmax(dim=1)(output) pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability if self.cfg['use_distill']: target = target.max(1, keepdim=True)[1] correct += pred.eq(target.view_as(pred)).sum().item() batch_pred_score = pred_score.data.cpu().numpy().tolist() batch_label_score = target.data.cpu().numpy().tolist() pres.extend(batch_pred_score) labels.extend(batch_label_score) pres = np.array(pres) labels = np.array(labels) # acc评分 acc = correct / len(data_loader.dataset) print('[Info] acc: {:.3f}% \n'.format(100. * acc)) # f1评分 if 'F1' in self.cfg['metrics']: precision, recall, f1_score = getF1(pres, labels) print(' precision: {:.5f}, recall: {:.5f}, f1_score: {:.5f}\n'.format( precision, recall, f1_score))
模型预测参考如下代码:
# 加载权重 runner.modelLoad(cfg['model_path']) # 开始预测 res_dict = runner.predict(test_loader) # 预测函数 def predict(self, data_loader): self.model.eval() correct = 0 res_dict = {} with torch.no_grad(): pres = [] labels = [] for (data, img_names) in data_loader: data = data.to(self.device) output = self.model(data).double() pred_score = nn.Softmax(dim=1)(output) pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability batch_pred_score = pred_score.data.cpu().numpy().tolist() for i in range(len(batch_pred_score)): res_dict[os.path.basename(img_names[i])] = pred[i].item() # 保存图像与预测结果 res_df = pd.DataFrame.from_dict(res_dict, orient='index', columns=['label']) res_df = res_df.reset_index().rename(columns={'index':'image_id'}) res_df.to_csv(os.path.join(cfg['save_dir'], 'pre.csv'), index=False,header=True)
6.2 分类结果展示
随机抽参与预测的四个图像信息如下:

最终输出预测结果如下:编号为10,1015图片预测分类与实际情况一样。编号为1084,1121的图片预测结果与实际结果不一样。
