-
Data-Efficient Backdoor 论文笔记
#论文笔记#
1. 论文信息
概要:本文是 backdoor attack 中的数据加毒。不同于以往随机在干净数据中选择样本加毒的方法,本文考虑了不同样本加毒会产生不同的攻击效率。主要的贡献是,研究了样本遗忘效应对加毒数据学习的影响,提出了一种过滤和更新的策略(FUS),筛选出容易遗忘的加毒样本,构建加毒数据集。与随机选择相比,只需要47% ~ 75%的中毒样本量就能获得相同的攻击成功率。并且还有更好的迁移性。
2. introduction
2.1 背景与问题
-
数据加毒
- 数据加毒是 backdoor attack 中的一个分支,大致的做法是给数据集中加入 trigger 然后发布。被攻击者使用加毒的数据集进行训练模型,就会给自己的模型中留下后门。
- 大部分数据加毒的研究方向主要集中在如何生成更好的 trigger 去提升攻击的准确率以及降低数据中的加毒比例。数据中的加毒比例越低,检测算法就越难检测到数据中存在的问题。
- 之前的方法都遵循一个共同的过程:随机从干净的数据集中选择一些数据,然后加入 trigger 构建加毒数据。这种随机选择的策略默认任何加毒样本对攻击的贡献是相等的,这不符合实际情况。因此本文提出了一个选择加毒的策略。
-
forgettable samples
-
容易被遗忘的样本
-
本文方法的核心是找到对后门注入贡献比较大的加毒样本,分类任务中对于决策边界影响比较大的样本有两种,hard or forgettable samples。本文重点讨论 forgettable samples。
-
关于 forgettable samples 的定义可以参考知乎博客。这里做一个简述
-
样本遗忘主要是受到灾难性遗忘现象启发而提出的,灾难性遗忘:描述的是在一个任务上训练出来的模型,如果在一个新任务上进行训练,就会大大降低原任务上的泛化性能,即之前的知识被严重遗忘了。
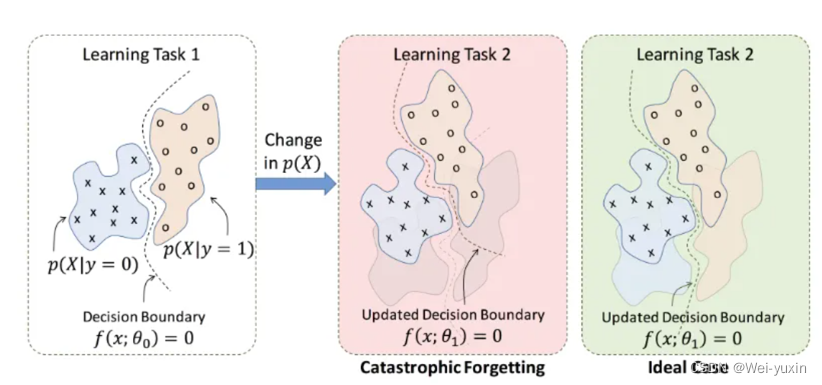
-
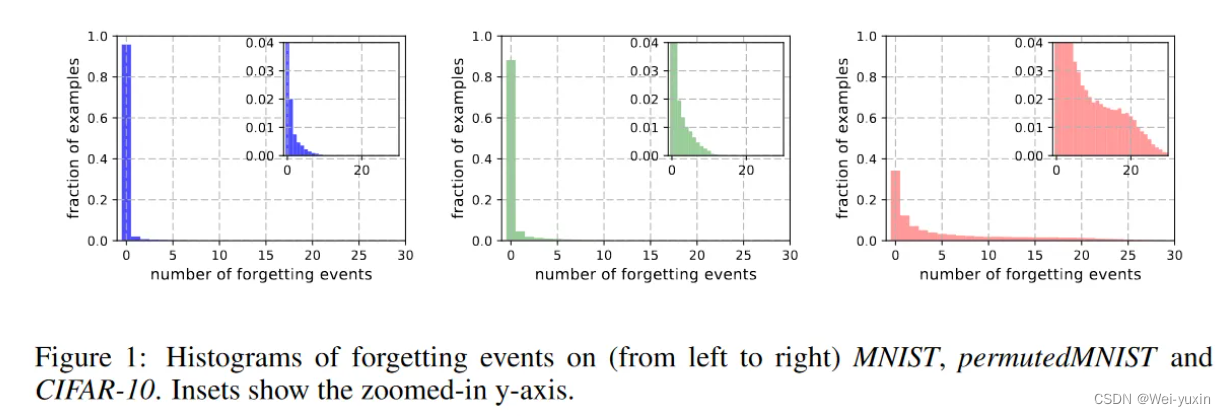
下图统计了数据集中样本的被遗忘次数,纵坐标表示样本的比例,横坐标表示 forgetting events。forgetting events:当一个样本本次预测正确,下次预测错误,就记一次 forgetting event。说明了越复杂的数据集中,forgettable samples 的数目就越多。
-
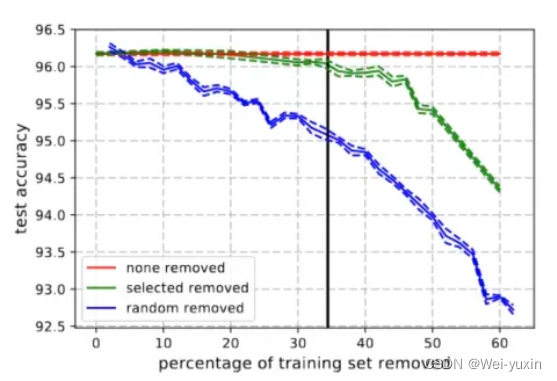
forgettable samples 和分类任务的关系。样本在训练中被遗忘的次数越多,它对分类任务的作用可能越大。可以从下图中看出,红色线为不移除样本中的数据,绿色线为移除样本中不容易被遗忘的数据,蓝色线为随机移除样本中的数据。由三条曲线的变化趋势可以看出 forgettable samples 可以促进模型的学习
-
-
-
forgettable poisoned samples
-
许多论文已经证实了 forgettable samples 的存在,并且 forgettable samples 的存在对分类任务具有促进作用。本论文通过实验探讨了在加入了 trigger 的 poisoned samples 中是否存在容易被遗忘的现象。
-
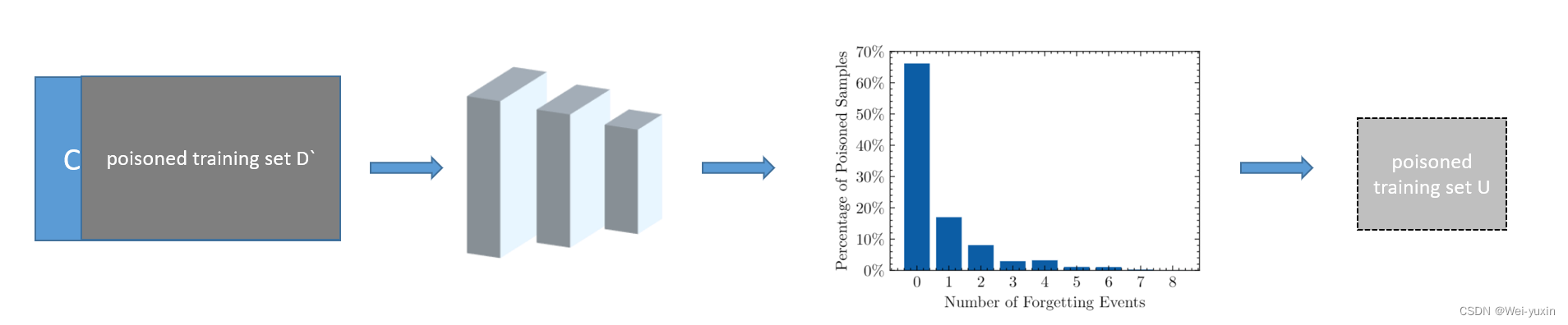
作者在 cifar10 上统计了 poisoned samples 的 forgetting events,结果如下图所示,发现在 poisoned samples 中也存在着forgettable poisoned samples。并且也通过移除加毒数据中 poisoned samples 的方法,去证明 forgettable poisoned samples 对于攻击具有积极的作用。
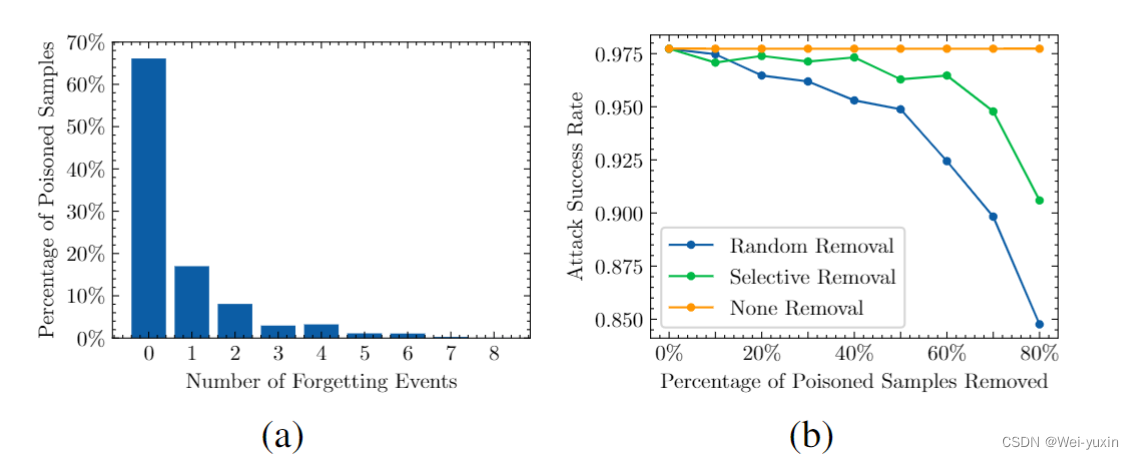
poisoned forgetting events:if x ′ x^{\prime} x′ is correctly classified at the time step s s s, i.e., I ( f θ s ( x ′ ) = t ) = 1 \mathbb{I}\left(f_{\theta^s}\left(x^{\prime}\right)=t\right)=1 I(fθs(x′)=t)=1, but is misclassified at s + 1 s+1 s+1, i.e., I ( f θ s + 1 ( x ′ ) = t ) = 0 \mathbb{I}\left(f_{\theta^{s+1}}\left(x^{\prime}\right)=t\right)=0 I(fθs+1(x′)=t)=0, then we record this as a forgetting event for that sample.
-
2.3 文章的贡献
- 将 poisoned samples 的选择问题视为优化问题
- 提出了 Filtering-and-Updating Strategy (FUS) 策略去选择加毒的数据
3. method
通过文章对于 forgettable poisoned samples 的讨论,我们已经得知 forgettable poisoned samples 对攻击效果具有促进作用。所以本文的方法就是将 forgettable poisoned samples 选择出来。
直接选择:
一种最直观的方法就是将数据集中的绝大部数据都变成 poison data,然后通过 forgetting event 计数的方法将 forgettable poisoned samples 选择出来。但是作者通过实验证明这种想法是错误的。
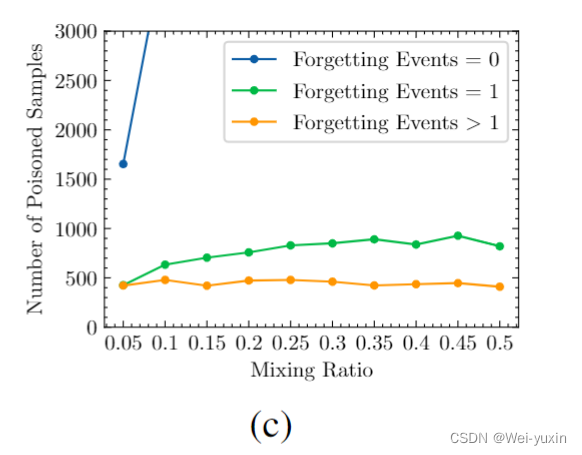
由下表可以看出,随着加毒数据比例的增大,筛选出的 forgettable poisoned samples 并没有增多(可以看到黄色线条,forgetting event > 2 的样本数目并没有增多。)所以这种直接筛选的方法是不合理的。文中对这种现象的解释是 trigger 更加容易学习。
We think this phenomenon happens because the features of the trigger are too easy to learn. Namely, the increase in the number of adversaries results in the differences between samples failing to emerge, as the model learns the backdoor more easily and more quickly.
举个不恰当的例子就是,如果我们在一堆狗的图片中混入一个噪声并且告诉模型这噪声也是狗,模型会比较容易忘记这个噪声。如果我们在狗这种数据集中加入大量相同的噪声,并且告诉模型这个噪声是狗,模型就很容易记住了。
FUS:
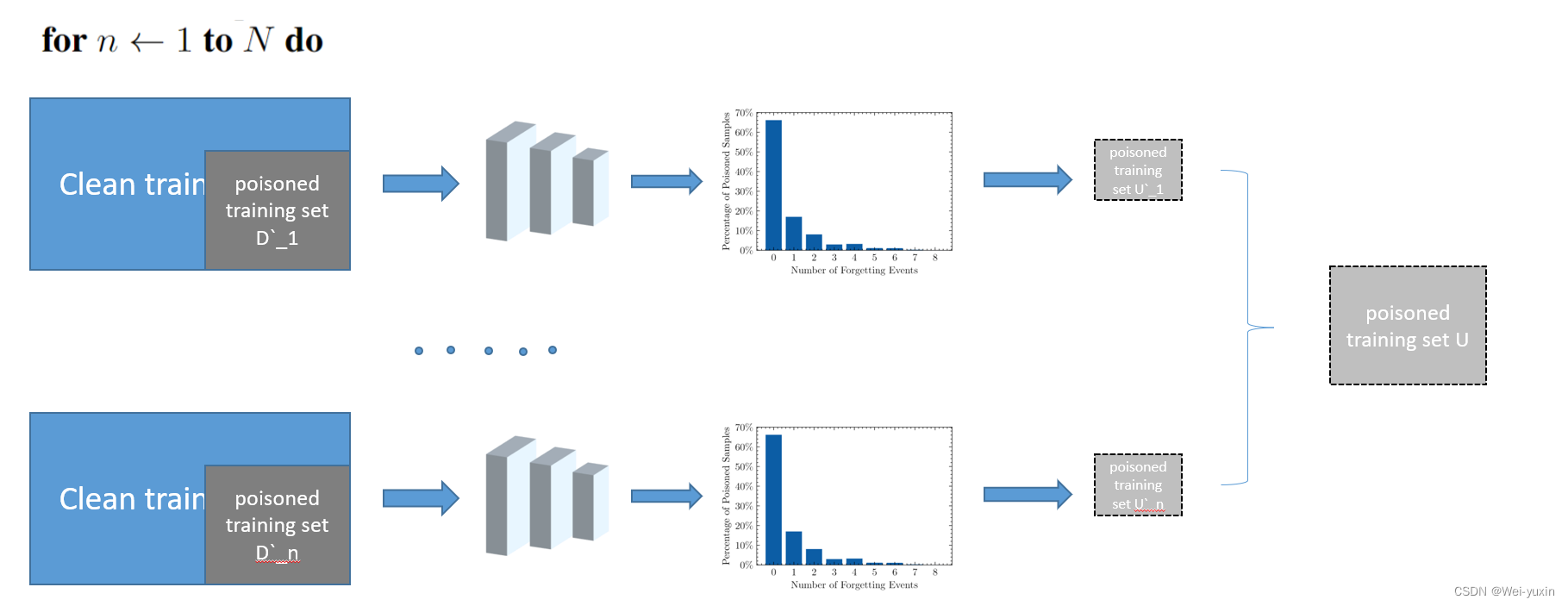
为了解决上述的问题,本文设计了 FUS 算法。算法图如下:

简单来说就是 poisoned training data 分成了 n 份,然后在这其中筛选出 forgettable poisoned samples 最后构成 forgettable poisoned data
4. experiments
4.1 数据集以及评价指标
🟠数据集一
CIFAR-10🟠数据集二
ImageNet-10:从 ImageNet-1k 中选择了 10 类实验
本文 trigger 的选择以及攻击的方式参照论文:Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning 2017 这是一个比较简单的攻击方法,如下图所示

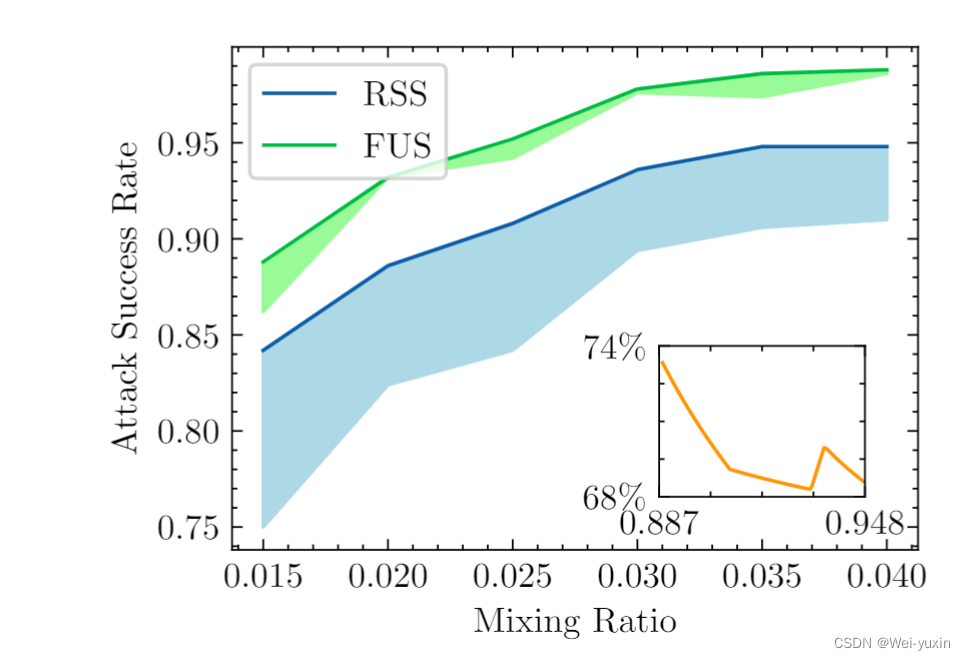
可以看到在白盒模型中,RSS(随机筛选)的策略不如本文提出的 FUS 策略。证明了该方法的优越性。
-
-
相关阅读:
JDK17新特性
Android学习笔记 15. ConstraintLayout 约束布局
前端八股文142-186
day17正则表达式作业
如何才能让UI自动化收益更大?
mac 安装hbuilderx
git版本回退
CocosCreator使用 ProtoBuf WebSocket与服务器对接方法
select函数出现No such file or directory错误
[R]第二节 对象介绍与赋值运算
- 原文地址:https://blog.csdn.net/weiyuxin107/article/details/127982941