-
transformer论文及其变种
transformer的九种变种transformer
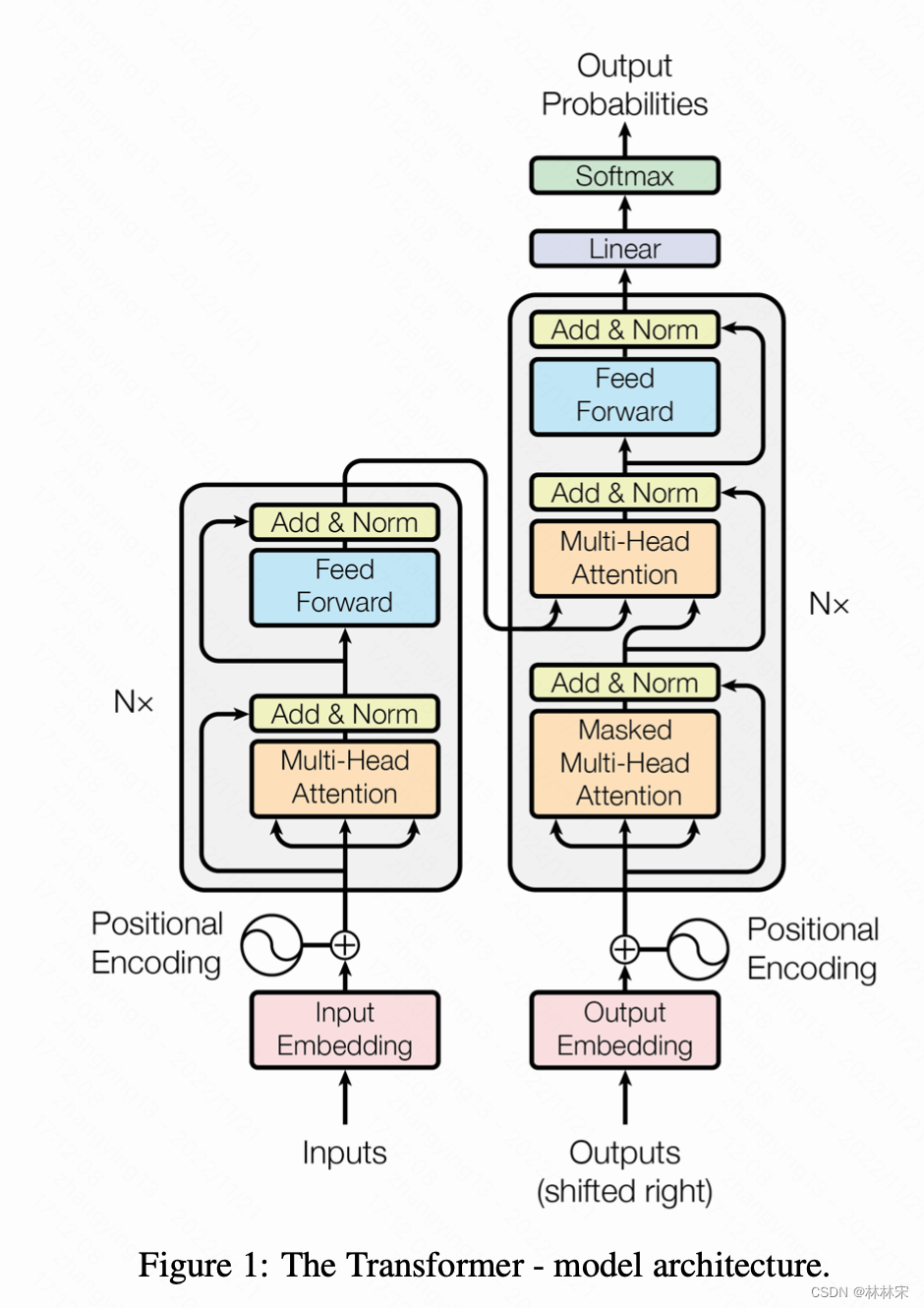
- motivation:序列映射的任务,常规是基于encoder-attention-decoder来完成的,基于CNN-RNN的结构。本文使用attention,用于机器翻译的任务。
模型细节
slf-attn & multi-head attn
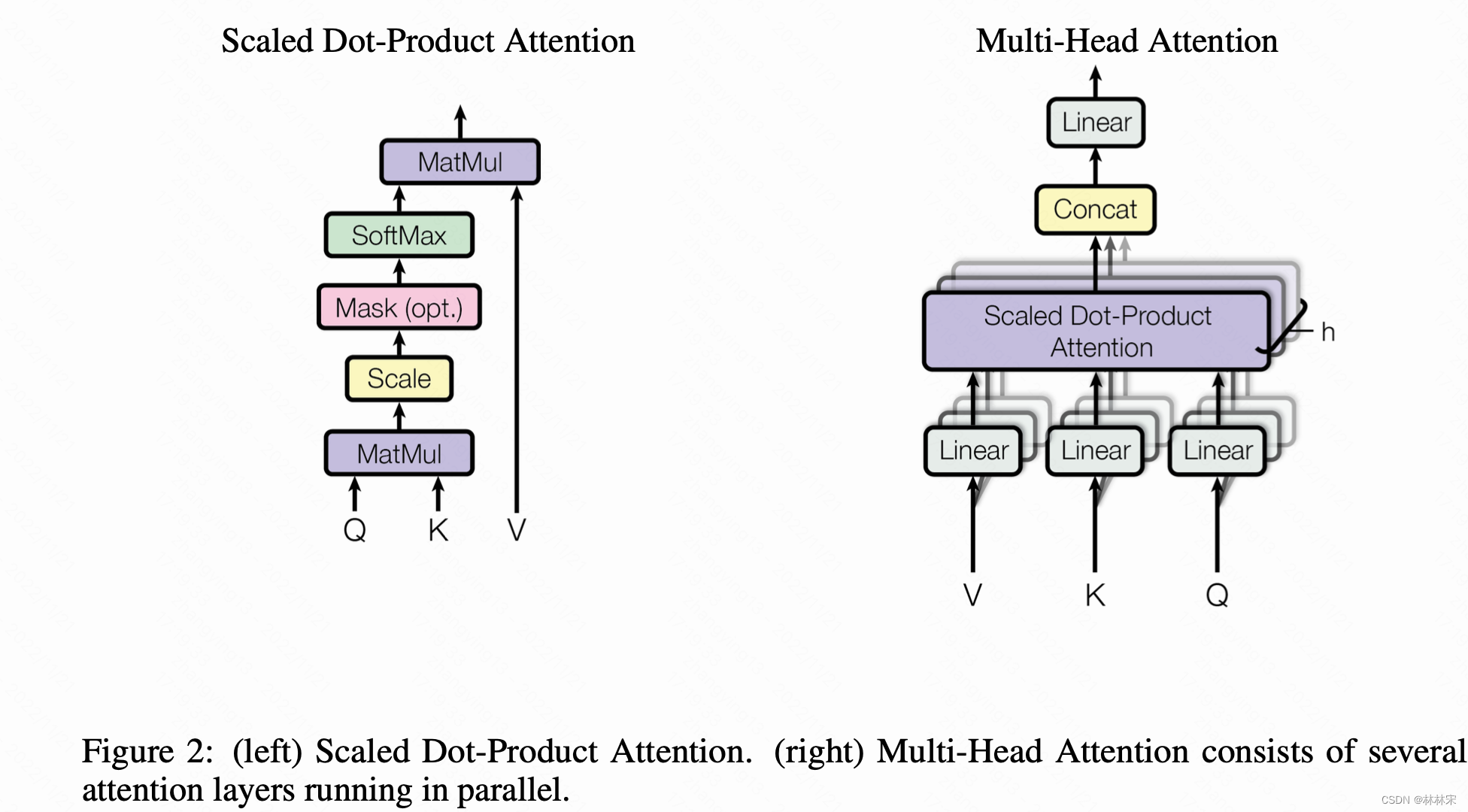
- encoder:对于所有K,Q和V是来自于同样的地方;因此可以attend到encoder输入的所有位置;
- decoder:Q来自于previous decoder layer,K和V来自于encoder output。为了保证自回归的有效性,需要在attention中mask掉无效的连接。
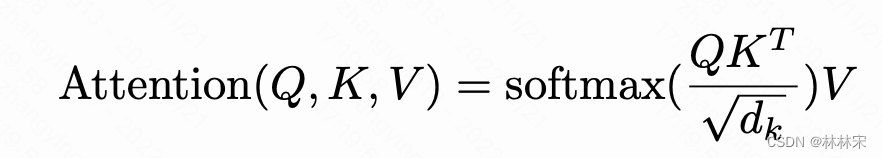
d k \sqrt[]{d_k} dk是为了防止梯度爆炸

- 不同的head关注不同的细节;同时,拆分维度,降低计算复杂度;
abs position
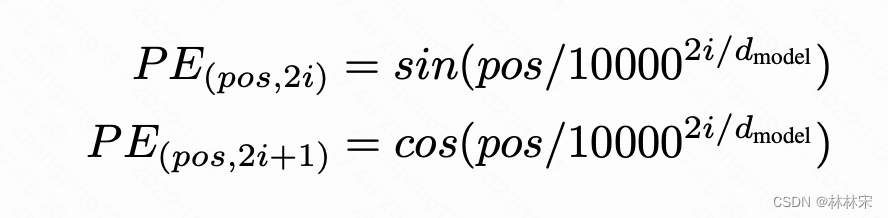
why slf-attn

- 常规来说,n<
- long-range dependence model
- 并行化
ASR相关工作
transducer
conformer
abstract
- interspeech2020, google
- motivation:在语音识别领域,将transformer global-model的能力和CNN location-model的能力结合。
- 常规CNN只能通过多层堆叠增大感知野;
model arch
transformer-XL
- motivation
- (1) tranformer中,将长句子切分成定长的序列输入,在切分的过程中,打破了句子的前后依赖关系;因此transformer-XL将上一句计算的隐状态保留下来,和下一句计算初始化状态拼接;---- 保留了前后依赖性;
- (2)abs-position修改为relative position

- 结果:比RNN的长时建模能力提升80%,比transformer的长时建模能力提升450%
Informer
- 2021AAAI best paper,论文讲解
- ProbSparse Self-Attention,可以在时间复杂度和内存使用方面达到,并具在序列的依赖对齐上有相当的性能。
- Self-Attention蒸馏将级联层的输入减半,突出了主要注意力,并可以有效处理超长输入序列。
- 生成型Decoder一次性预测一系列的序列,而不是一步一步预测,这彻底的提高了长序列推理速度。
细节

probSparse slf-attn

- 首先发现,只有少部分数据对attn的贡献比较大--------attn的长尾问题;
- attn的计算公式可知,Q*K是找到比较重要的(q,k)pair。-----处于attn的头部。
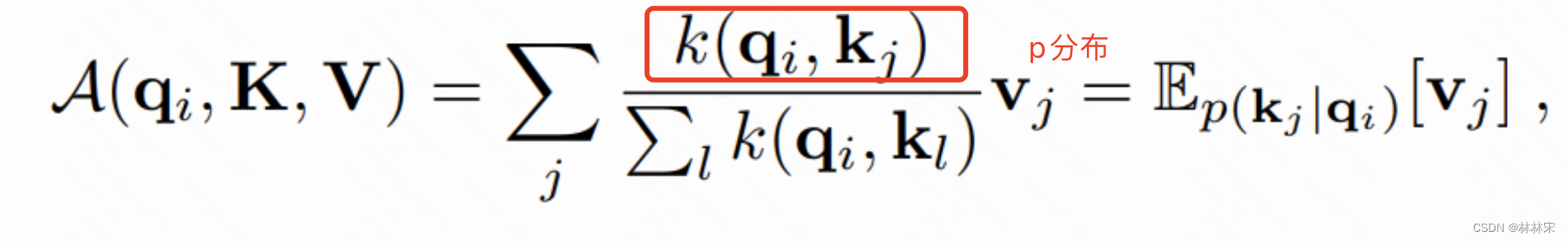
- 计算p分布和高斯分布的KL距离,距离越近,说明q越不重要。
- Q是稀疏矩阵,依赖对长尾问题的理解,简化了attention 计算的复杂度。
Longformer
- 解决slf-attn随着序列长度的增加,计算量爆炸的问题(限制了更长序列的建模)
- 论文解读
细节

(b) slide window attention:每个token的attention span=w,前后各看 1 / 2 w 1/2w 1/2w个token。一个拥有𝑚层的transformer,它在最上层的感受野尺寸为 m ∗ w m*w m∗w。
(c) dilated sliding window:在进行Self-Attention的两个相邻token之间会存在大小为𝑑的间隙,这样序列中的每个token的感受野范围可扩展到𝑑×𝑤。在第𝑚层,感受野的范围将是𝑚×𝑑×𝑤。
(d) global+sliding window:针对特定的任务进一步的完善。设定某些位置的token能够看见全部的token,同时其他的所有token也能看见这些位置的token,相当于是将这些位置的token”暴露”在最外面。例如对于分类任务,这个带有全局视角的token是”CLS”。Global+Sliding Window这里涉及到两种Attention,Longformer中分别将这两种Attention映射到了两个独立的空间。两组对应的Q/K/V计算。
GPT-generative pre-train
- motivation:充分利用大量未标注的原始文本数据,分为两个阶段:(1)pre-training阶段:使用无标签的数据,输入n个词,预测下一个词。因为是word-level的,因此GPT学习了一个语言模型;(2)fine-tuning阶段,针对具体的任务和少量的标注数据,对参数进行微调。
- 优点:模型更强大,普适性更强(针对所有任务微调相同的基本模型);
- 缺点:建立的语言模型是单向的
模型结构

- 去掉encoder,只有decoder的transformer,而且decoder中没有multi-head attn,只有masked multi-head attn。——在attention矩阵中,对预测词及之后的词进行mask。表现为一个上三角都是-inf的mask矩阵。
下游任务:fine-tuning

swin transformer
- 在图像领域,解决transformer计算量过大的问题
-
相关阅读:
java计算机毕业设计基于安卓Android的应急求救信息发布系统APP(源码+系统+mysql数据库+Lw文档)
Java 内存模型(JMM)
理解docker [一] - control group
传统纸业如何实现数字化,S2B2C系统网站赋能渠道提升供应链管理效率
五个人的五个成绩
STM32H7高性能MCU系列 STM32H7A3NGH6 32-bit RISC内核
SIP会话发起协议 - 先知道是什么(一)
Spring Boot Security 角色授权示例
Spring进阶(三):WEB
医院陪诊服务预约小程序的作用如何
- 原文地址:https://blog.csdn.net/qq_40168949/article/details/127968695