-
3-3、python中内置数据类型(集合和字典)
集合
集合是一个无序 的、不重复元素序列
集合的创建
使用 { } 或者 set() 函数来创建集合
- 注意:创建一个空集合必须使用 set()函数
- { } 用于创建一个空字典
- 集合的元素必须是不可变数据类型
s = {1, 2, 3, 1, 2, 3} print(s, type(s)) # {1, 2, 3}# s={1,2,3,[1,2,3]} 会报错,集合中的元素只能是不可变数据类型 s = {} print(s, type(s)) # {} s = set() print(s, type(s)) # 空集合set() - 1
- 2
- 3
- 4
- 5
- 6
- 7

集合的特性
集合是无序且不重复的,所以集合不支持连接、重复、索引、切片
集合支持成员操作符 in 和 not ins = {1, 2, 3} # print(s+s) #报错, 集合不支持连接操作符 # print(s*3) #报错, 集合不支持重复操作符 print(1 in s)- 1
- 2
- 3
- 4

集合的常用操作
增加
s={1,2,3} s.add(100) #添加单个元素 print(s) #{1, 2, 3, 100} s={1,2,3} s.update('456') #添加多个元素 print(s) s.update({7,8,9}) print(s)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

删除
- remove函数,如果删除的元素存在就删除,如果元素不存在就报错
- discard函数,如果删除的元素存在就删除,如果元素不存在就do nothing
- pop函数,随机删除一个元素,如果集合为空,就报错
s = {1, 2, 3} s.remove(3) print(s) s = {1, 2, 3} s.discard(100) # 删除一个集合中不存在的元素,则啥也不做 print(s) s = {1, 23, 4, 7, 8} s.pop() print(s)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
查看
- 差集:s1 - s2 (所有属于集合s1,但是不属于s2的元素)
- 交集:s1 & s2
- 对称差分:s1 ^ s2
- 并集:s1 | s2
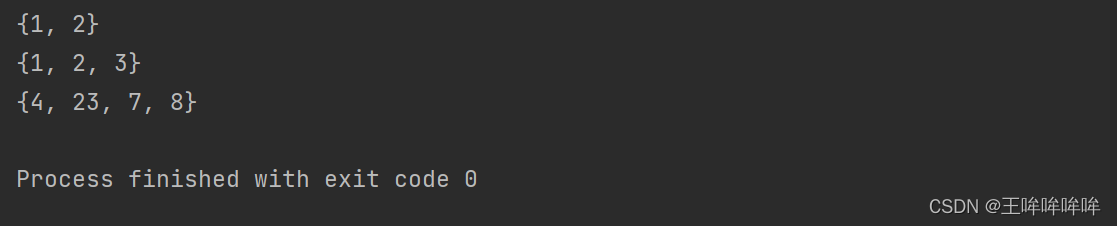
s1 = {1, 2, 3} s2 = {1, 2} print(s1 - s2) # 差集{3} print(s1 & s2) # 交集{1, 2} s1 = {1, 2, 3} s2 = {2, 3, 4} print(s1 | s2) # 并集 {1, 2, 3, 4} print(s1 ^ s2) # 对称差分 {1, 4},即{1, 2, 3, 4} - {2,3}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

- issubset函数,s1.issubset(s2),判断s2是不是s1的子集
- isdisjoint函数,s1.isdisjoint(s2),判断s1和s2是否没有交集
s1={1,2,3} s2={2,3,4} print(s1.issubset(s2)) # False s2是s1的子集吗? print(s1.isdisjoint(s2)) # False s2和s1没有交集吗?- 1
- 2
- 3
- 4

练习-对集合的排序
排序函数:
s={2,88,23,4}
sorted(s)函数能对集合s排序明明想在学校中请一些同学做一项调查问卷。为了实验的客观性,他先用计算机生成了N个1到1000之间的随机整数(N小于等于1000),对于其中重复的数字,只保留一个,把其余相同的数字去掉,不同的数字对应着不同学生的学号。然后再把这些数从大到小排序,按照排好的顺序去找同学做调查。请你协助明明完成“去重”与“排序”的工作。
import random s = set() # 定义一个空集合 n=int(input("请输入需要的N的个数(1-1000):")) for i in range(n): num = random.randint(1, 1000) s.add(num) print(sorted(s, reverse=True))- 1
- 2
- 3
- 4
- 5
- 6
- 7

frozenset 不可变的集合
s = frozenset({1, 2, 3}) print(s, type(s))- 1
- 2
frozenset是不能添加、删除、修改的集合
字典
字典是另一种可变容器模型,且可存储任意类型对象 【键不重复、无序】
键一般是唯一的,如果重复,最后一个键值会替换前面的,值不需要唯一
通过关键字,能快速找到关键字对应的值字典的创建
字典是key-value对或键值对存储的
d={"name":"lee","age":"18","city":"西安"} print(d,type(d)) d={} # 创建一个空字典 print(d,type(d))- 1
- 2
- 3
- 4

字典的特性
字典是不重复且无序的,和集合很像 【键不能重复,值可以重复】
字典不支持连接、重复、索引和切片特性
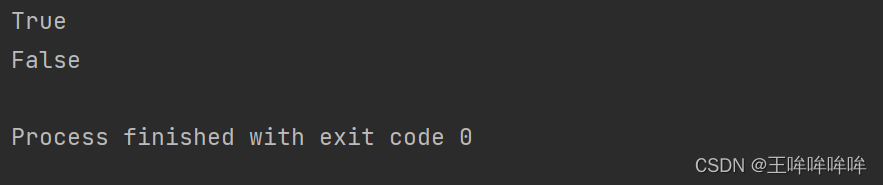
字典支持成员操作符 in 和 not in (判断是不是所有key值的成员)d = {"name": "lee", "age": "18", "city": "西安"} print("name" in d) # True print("wang" in d) # false- 1
- 2
- 3
字典的常用方法
查看
dir={"name":"lee","age":"18","city":"西安"} print(dir.keys()) #查看字典的所有key print(dir.values()) #查看字典的所有value print(dir.items()) #查看字典的所有key-value(item) print(dir['name']) #查看key为name对应的value值 #print(dir['province']) #查看key为province对应的value值,如果存在就返回,如果不存在就会报错 print(dir.get('province')) #查看key为province对应的value值,如果存在就返回,如果不存在就返回none print(dir.get('province',"陕西")) #查看key为province对应的value值,如果存在就返回,如果不存在就返回陕西- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

增加和修改
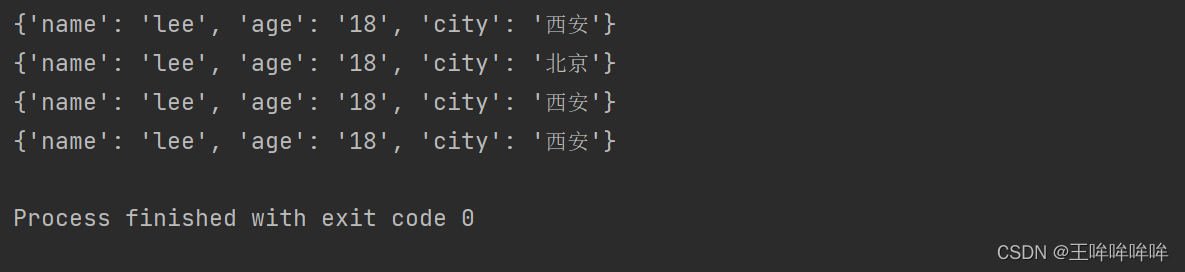
d={"name":"lee","age":"18"} d['city']='西安' #key值不存在就添加 print(d) d['city']='北京' #key值存在,则修改相应value值 print(d) d={"name":"lee","age":"18"} d.setdefault('city','西安') #key值不存在就添加 print(d) d.setdefault('city','北京') #key值存在,则do nothing print(d)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
删除
d = {"name": "lee", "age": 18} d.pop('age') print(d) d = {"name": "lee", "age": 18} del d['name'] print(d)- 1
- 2
- 3
- 4
- 5
- 6
- 7

遍历字典 (for)
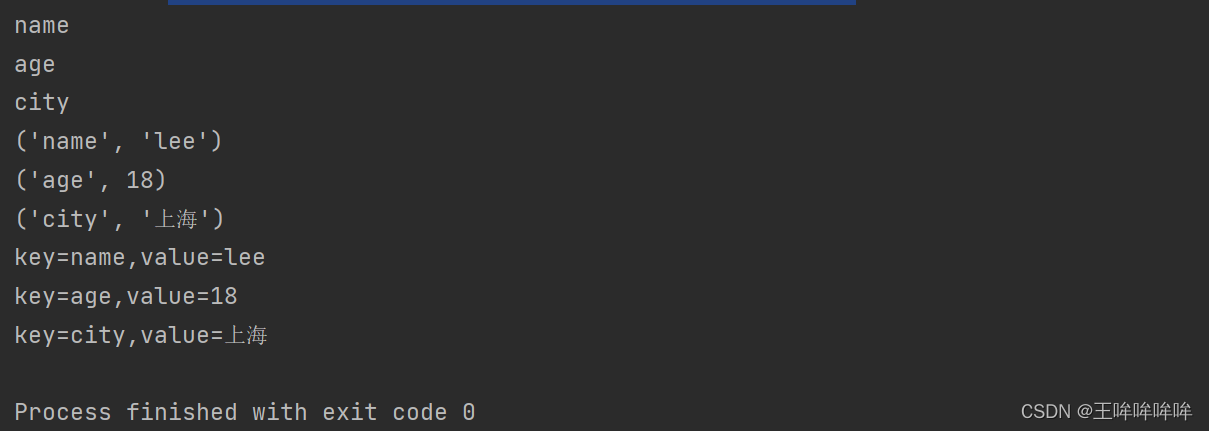
d = {"name": "lee", "age": 18, "city": "上海"} for i in d: print(i) # 这样只是遍历了字典中的key值 # 怎么样遍历字典中的key和value值呢? for item in d.items(): # item中返回的是个列表:[('name', 'lee'), ('age', '18'), ('city', '西安')] print(item) # 遍历字典中的key和value值 # 如何分别遍历字典中的key和value值呢? for key, value in d.items(): print(f"key={key},value={value}")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
defaultdict默认字典(给字典设置默认值)
collections.defaultdict类,本身提供了默认值的功能,默认值可以是整型、列表、集合等
from collections import defaultdict # 默认字典,设置字典默认的value值 d=defaultdict(int) #设置默认value为整型 print(d['views']) #默认value值为0 d['transfer'] +=1 #将key为transfer的值加1 print(d) #默认值为列表 d=defaultdict(list) d['allow_users'].append('lee') d['deny_users'].extend(['user1','user2']) print(d) #默认值为集合 d=defaultdict(set) d['love_movies'].add('肖申克的救赎') d['love_movies'].update({'我不是药神','黑客帝国'}) print(d)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

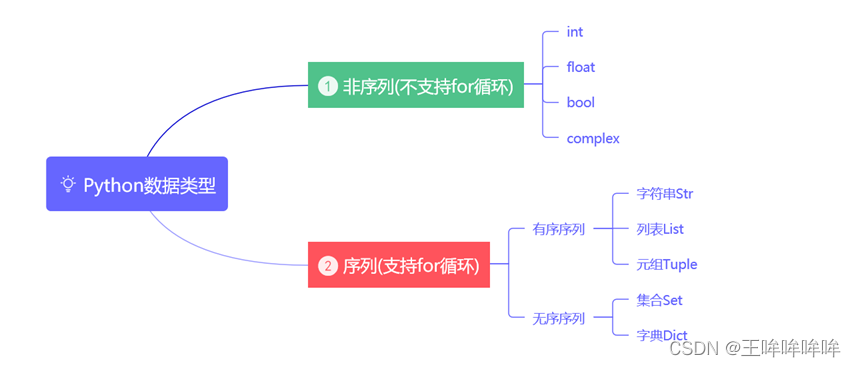
内置数据类型总结
-
可变数据类型和不可变熟虑类型
可变数据类型:列表、集合、字典
不可变数据类型:数值类型、元组、字符串 -
序列(支持for循环)和非序列(不支持for循环)
有序序列拥有的特征:索引、切片、连接操作符、重复操作符、成员操作符
什么是可变数据类型:
可以增删改。可变数据类型允许变量的值发生变化,即如果对变量进行append、+ - 等操作,只是改变了变量的值,而不会新建一个对象,变量引用的对象的地址也不会变化。不过对于相同的值的不用对象,再内存中则会存在不用的对象,即每个对象都有自己的地址,相当于内存中对同值的对象保存了多份,这里不存在引用计数,是实实在在的对象。
什么是不可变数据类型:
不能增删改。 python中的不可变数据类型,不允许变量的值发生变化,如果改变了变量的值,就相当于是新建了一个对象。 而对于相同值的对象,在内存中则只有一个对象,内部会有一个引用计数来记录有多少个变量引用这个对象。 -
相关阅读:
Acrobat Pro DC 2023 for Mac:PDF处理的终极解决方案
如何处理ChatGPT在文本生成中的语法错误和不合理性?
List集合
【Vue】修饰符、表单提交方式、自定义组件的关键步骤
【QT】Qt 5 的程序:打印文档
有关于MySQL的面试题
拷贝构造函数vs移动构造函数
Intel HAXM
2023年【四川省安全员A证】模拟试题及四川省安全员A证作业模拟考试
大数据开发之数据仓库
- 原文地址:https://blog.csdn.net/qq_43604376/article/details/127960546
