-
Pytorch的入门操作(二)
2、Pytorch
2.1 Pytorch的介绍和安装
目标:
知道如何安装Pytorch
2.1.1 Pytorch的介绍
Pytorch是Facebook发布的深度学习框架,由其易用性,友好性,深受广大用户青睐
2.1.2 Pytorch的版本

2.1.3 Pytorch的安装
安装地址介绍:安装地址
带GPU安装步骤conda instal1 pytorch torchvision cudatoolkit=9.0 -c pytorch
不带GPU安装步骤
conda insta11 pytorch-cpu torchvision-cpu -c pytorch
安装之后打开ipython
输入:In [l]:import torch In [2]: torch.__version Out[2]:'1.0.1'- 1
- 2
- 3
注意:安装模块的时候安装的是pytorch,但是在代码中都是使用torch
2.2 Pytorch的入门使用
目标
- 知道张量和pytorch中的张量
- 知道pytorch中如何创建张量
- 知道pytorch中tensor的常见方法
- 知道pytorch中tensor的数据类型
- 知道pytorch中如何实现tensor在cpu和cuda中转化
2.2.1 张量Tensor
张量是一个统称,其中包含很多类型:
- 0阶张量:标量、常数,0-D Tensor
- 1阶张量:向量,1-D Tensor
- 2阶张量:向量,2-D Tensor
- 3阶张量
- …
- N阶张量
a:各种数值数据称为张量
b:常数:scale:0阶张量
c:向量:vector:1阶张量
d:矩阵:matrix:2阶张量
e:3阶张量
阶指的是一个高维数组里的形状(sheet)的个数2.2.2 Pytorch中创建张量
- 使用python中的列表或者序列创建tensor
torch,tensor([[1.,-1.],[1., -1.]]) tensor([[ 1.0000,-1.0000],[ 1.0000,-1.0000]])- 1
- 2
- 使用numpy中的数组创建tensor
torch.tensor(np.array([[1,2,3],[4,5,6]])) tensor([[ 1,2,3], [ 4,5,6]])- 1
- 2
- 3
- 使用torch的api创建tensor
1)torch.empty(3,4)创建3行4列的空的tensor,会用无用数据进行填充
2)torch.ones([3,4])创建3行4列的全为1的tensor
3)torch.zeros([3,4])创建3行4列的全为0的tensor
4)torch.rand([3,4])创建3行4列的随机值的tensor,随机值的区间是[0,1)
>>> torch.rand(2,3) tensor([[ 0,8237, 0.5781, 0.6879],[ 0.3816, 0.7249, 0.0998]])- 1
- 2
- 3
5)torch.randint(1ow=0,high=10,size=[3,4])创建3行4列的随机整数的tensor,随机值的区间是[low,high)
>>> torch.randint(3,10,(2,2)) tensor([[4,5], [6,7]])- 1
- 2
- 3
6)torch.randn([3,4])创建3行4列的随机数的tensor,随机值的分布式均值为0,方差为1(randn中的n是null)
张量的创建方法
a:torch.Tensor(list)
b:torch.empty()/zeros()/ones()
c:torch.rand/randint()/randn()2.2.3 Pytorch中tensor的常用方法
- 获取tensor中的数据(当tensor中只有一个元素可用):tensor.item()
In [l0]: a = torch.tensor(np.arange(1)) In [11]: a Out[11]: tensor([0]) In [12]: a.item() Out[12]: 0- 1
- 2
- 3
- 4
- 5
- 转为numpy数组
In [55]: z.numpy() Out[55]: array([[-2.5871205], [ 7.3690367], [-2.4918075]],dtype=float32)- 1
- 2
- 3
- 4
- 5
- 获取形状:tensor.size()
In [72]:x Out[72]:tensor([[ 1, 2], [ 3, 4], [ 5, 10],dtype=torch.int32) In [73]: x.size() Out[73]: torch.size([3,2])- 1
- 2
- 3
- 4
- 5
- 6
- 形状改变: tensor.view((3,4))。类似numpy中的reshape,是一种浅拷贝,仅仅是形状发生改变
In [76]: x.view(2,3) Out[76]: tensor([[ 1, 2, 3], [ 4, 5, 10]],dtype=torch.int32)- 1
- 2
- 3
- 4
- 获取维数: tensor.dim()
In[77]:x.dim() Out[77]:2- 1
- 2
- 获取最大值:tensor.max()
In [78]: x.max() Out[78]: tensor(10,dtype=torch.int32)- 1
- 2
- 转置: tensor.t()
In [79]: x.t0)out[79]: tensor([[ 1, 3, 5], [ 2, 4, 10]],dtype=torch,int32)- 1
- 2
- 3
- tensor[1,3]获取tensor中第一行第一列的值
- tensor[1,3]=100 对tensor中第一行第三列的位置进行赋值100
- tensor的切片
张量的方法和属性
a. 数据中只有一个元素的时候,取值:
tensor.item()
b.转化为numpy数组的时候: tensornumpy()
c. 获取形状:
i. tensor.size()
ii. tensor.size(1)#获取第一个维度的形状
d.形状的变化:tensor.view([shape])
e. 获取阶数: tensor.dim()
f.常用计算方法:tensor.max()/min/std
g.转置:
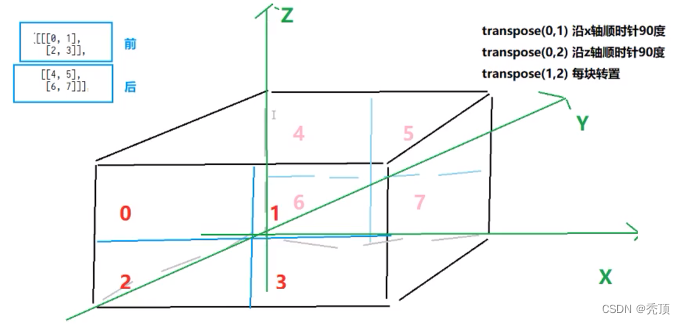
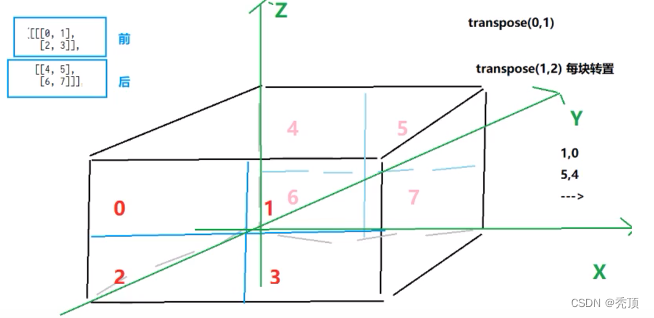
i.二维:tensor.t() tensor.transpose(0,1)
ii. 高维: tensor.transpose(1,2)/tesnor.permute(0,2,1)
h. 取值和切片
i. t[1,2,3)
ii. t[1,:,:]
iii. t[1,2,3] = 100
对三维数据而言,转置图示
2.2.4 tensor的数据类型
- 获取tensor时数据类型:tensor.dtype
In [80]: x.dtype Out[8o]: torch.int32- 1
- 2
- 创建数据的时候指定类型
In [88]: torch.ones([2,3],dtype=torch,float32) Out[88]: tensor([[9.1167e+18,0.0000e+00,7.8796e+15], [8.3097e-43,0.0000e+00,-0.0000e+00]])- 1
- 2
- 3
- 4
- 类型的修改
In [17]: a Out[17]: tensor([1,2],dtype=torch.int32) In [18]: a.type(torch.float) Out[18]: tensor([1.,2.]) In [19]: a.dduble() Out[19]: tensor([1.,2.],dtype=torch.float64)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
数型
a. 指定数据类型:
i.torch.tensor(array,dtype)
ii. torch.ones(array,dtype)
b. 获取数据类型
i. tensor.dtyep
c. 修改数型
i. tonsor.float/long()/int()
d.torch.Tensor和torch.tensor的区别
i.全局(默认的数据类型)是torch.float32
ii.torch.Tensor()传入数字表示形状和torch.FloatTensor相同
iii.Torch.Tensor传入可迭代对象表示数据,类型为横型的数据类型
iv.torch.tensor为创建tensor的方法2.2.5 tensor的其他操作
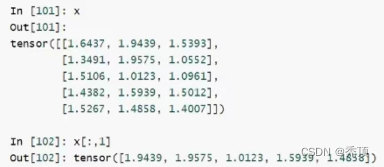
- tensor和tensor相加
In [94]: x = x.new_ones(5,3,dtype=torch.float) In [95]: y = torch.rand(5,3) In [96]: x+y Out[96]: tensor([[1.6437,1.9439,1.5393], [1.3491,1.9575,1.0552], [1.5106,1.0123,1.0961]. [1.4382,1.5939,1.5012], [1.5267,1.4858,1.4007]]) In [98]: torch.add(x,y) Out[98]: tensor([[1.6437,1.9439,1.5393], [1.3491,1.9575,1.0552], [1.5106,1.0123,1.0961], [1.4382,1.5939,1.5012], [1.5267,1.4858,1.4007]]) In [99]: x.add(y) Out[99]: tensor([[1.6437,1.9439,1.5393], [1.3491,1.9575,1.0552], [1.5106,1.0123,1.0961], [1.4382,1.5939,1.5012], [1.5267,1.4858,1.4007]]) In [100]: x.add_(y) #带下划线的方法会对x进行就地修改 Out[100]: tensor([[1.6437,1.9439,1.5393] [1.3491,1.9575,1.0552], [1.5106,1.0123,1.0961] [1.4382,1.5939,1.5012], [1.5267,1.4858,1.4007]]) In [101]: x #x发生改变 Out[101]: tensor([[1.6437,1.9439,115393], [1.3491,1.9575,1.0552], [1.5106,1.0123,1.0961], [1.4382,1.5939,1.5012] , [1.5267,1.4858,1.4007]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
注意:带下划线的方法(比如:add_)会对tensor进行就地修改
- tensor和数字操作
In [97]: x +10 Out[97]: tensor([[11.,11.,11.], [11.,11.,11.], [11.,11.,11.], [11.,11.,11.], [11.,11.,11.]])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- CUDA中的tensor
CUDA(Compute Unified Device Architecture) ,是NVIDIA推出的运算平台。CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
torch.cuda这个模块增加了对CUDA tensor的支持,能够在cpu和gpu上使用相同的方法操作 tensor
通过.to方法能够把一个tensor转移到另外一个设备(比如从CPU转到GPU)
#device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") if torch,cuda.is_available(): device = torch.device("cuda") # cuda device对象 y = torch.ones_like(x,device=device) # 创建一个在cuda上的tensor x = x.to(device) z=x+y # 使用方法把x转为cuda 的tensor print(z) print(z.to("cpu",torch.doub1e)) # .to方法也能够同时设置类型 >>tensor([1.9806], device='cuda:0') >>tensor([1.9806], dtype=torch.float64)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
通过前面的学习,可以发现torch的各种操作几乎和numpy一样
原地修改的方法:
a:x.add(y)直接会修改x的值
GPU中的tensor的使用
a.实例化device:torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”)
b.tensor.to(device) #把tensor转化为CUDA支持的tensor,或者cpu支持的tensor2.3 梯度下降和反向传播与原理
目标
- 知道什么是梯度下降
- 知道什么是反向传播
2.3.1 梯度是什么?
梯度:是一个向量,导数+变化最快的方向(学习的前进方向)
回顾机器学习

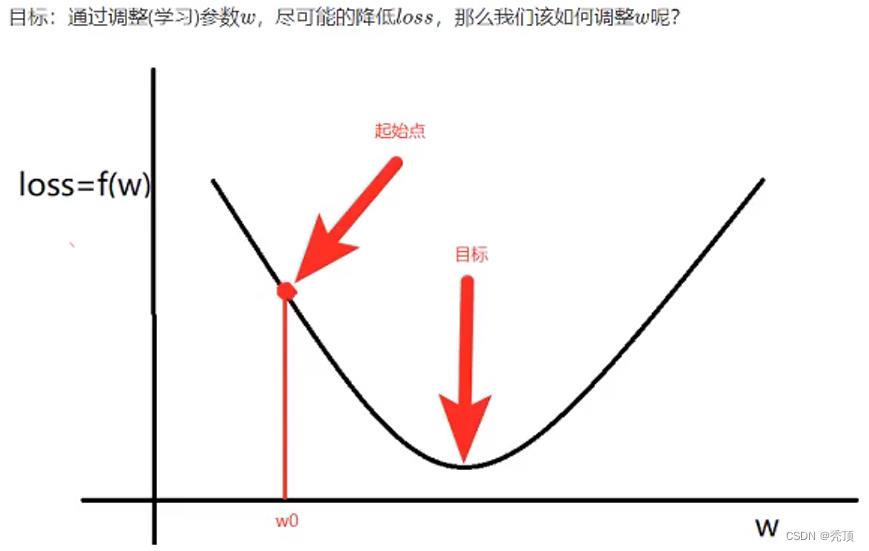


总结:梯度就是多元函数参数的变化趋势(参数学习的方向),只有一个自变量时称为导数2.3.2 偏导的计算
2.3.2.1 常见的导数计算

2.3.2.2 多元函数求偏导

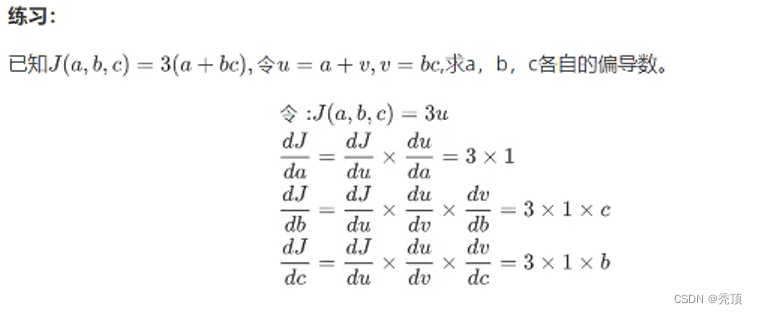
2.3.3 反向传播算法
2.3.3.1 计算图和反向传播
计算图: 通过图的方式来描述函数的图形
在上面的练习中,J(a,b,c)= 3(a + bc),令u = a+v,v = bc,把它绘制成计算图可以表示为:
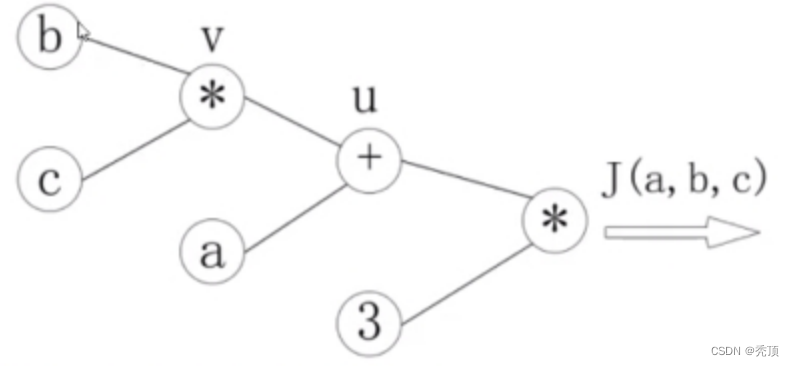
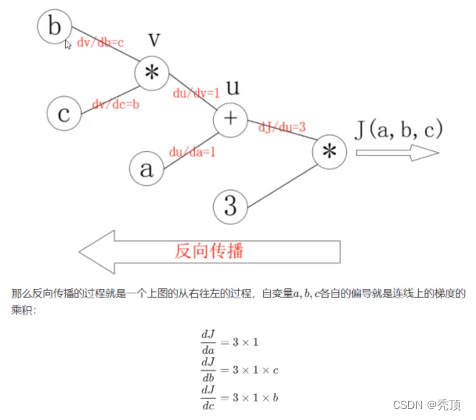
绘制成为计算图之后,可以清楚的看到向前计算的过程
之后,对每个节点求偏导可有:
2.3.3.2 神经网络中的反向传播
- 神经网络的示意图
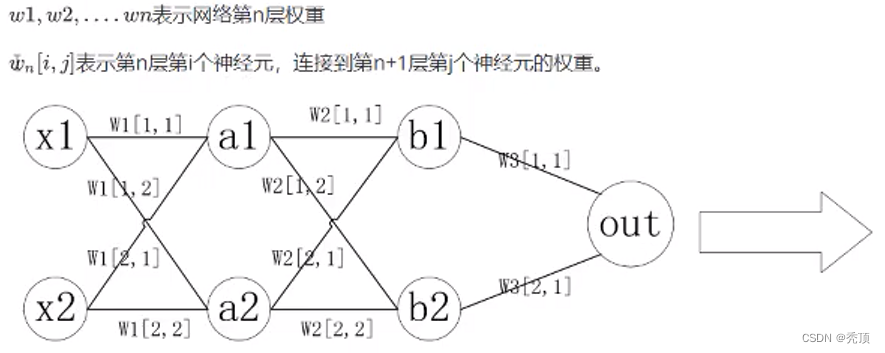
- 神经网络的计算图
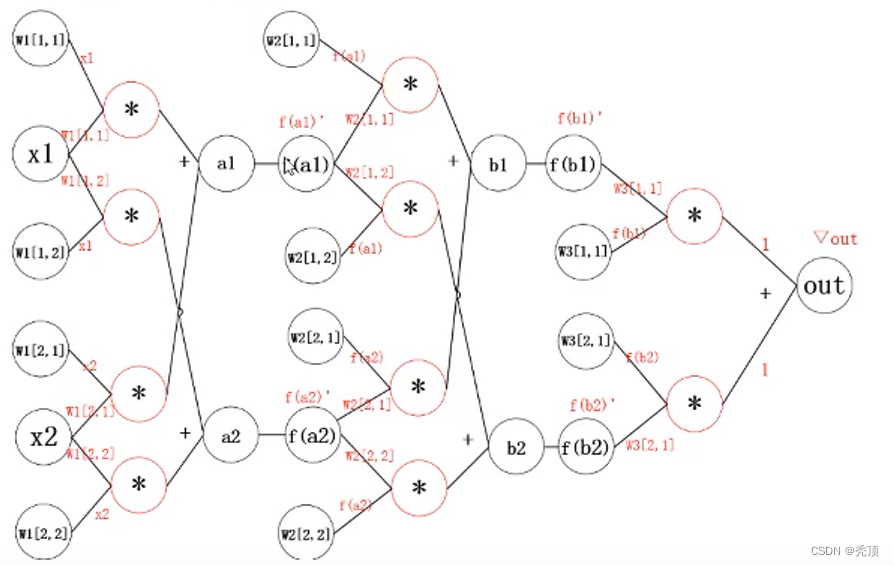
其中:


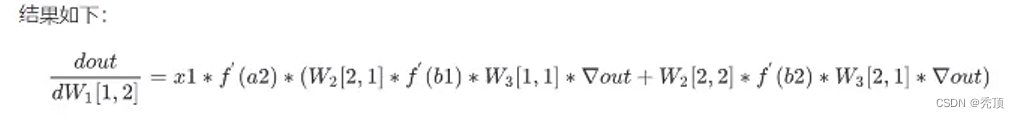
公式分为两部分: - 括号外: 左边红线部分
- 括号内
1)加号左边:右边红线部分
2)加号右边: 蓝线部分
但是这样做,当模型很大的时候,计算量非常大
所以反向传播的思想就是对其中的某一个参数单独求梯度,之后更新,如下图所示:

计算过程如下

更新参数之后,继续反向传播

继续反向传播

通用的描述如下
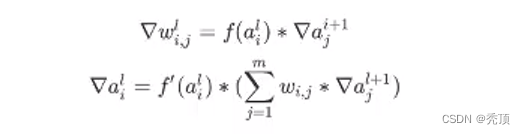
2.4 手动完成线性回归
目标
- 知道requires_grad的作用
- 知道如何使用backward
- 知道如何手动完成线性回归
2.4.1 向前计算
对于pytorch中的一个tensor,如果设置它的属性 requires_grad为True,那么它将会踪对于该张量的所有操作。或者可以理解为,这个tensor是一个参数,后续会被计算梯度,更新该参数。
2.4.1.1 计算过程

那么,在最开始随机设置x的值的过程中,需要设置他的requires_grad属性为True,其默认Noneimport torch x = torch.ones(2,2,requires_grad=True) #初始化参数x并设置requires_grad=True用来追踪其计算历史 print(x) #tensor([[1., 1.], # [1., 1.]], requires_grad=True) y = x+2 print(y) #tensor([[3.,3.], # [3.,3.]],grad_fn=) z=y*y*3 #平方x3 print(x) #tensor([[27.,27.], # [27.,27.]],grad_fn=) Out = z,mean() #求均值 print(out) #tensor(27.,grad_fn=) - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
从上述代码可以看出:
1.x的requires_grad属性为True
2.之后的每次计算都会修改其grad_fn 属性,用来记录做过的操作
1)通过这个函数和grad_fn能够组成一个和前一小节类似的计算图2.4.1.2 requires_grad和grad_fn
a = torch.randn(2,2) a=((a*3) / (a- 1)) print(a.requires_grad) #False a.requires_grad_(True) #就地修改 print(a.requires_grad) #True b = (a*a).sum() print(b.grad_fn) #with torch.no_gard() : c = (aa).sum() #tensor(151.6830),此时c没有gard_fn print(c.requires_grad) #False - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
注意:
为了防止跟踪历史记录(和使用内存),可以将代码块包装在with torch.no_grad():中。在评估模型时特别有用,因为模型可能具有requires_grad = True 的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。2.4.2 梯度计算

注意: 在输出为一个标量的情况下,我们可以调用输出tensor 的backword()方法,但是在数据是一个向量的时候,调用backward() 的时候还需要传入其他参数。很多时候我们的损失函数都是一个标量,所以这里就不再介绍损失为向量的情况
loss.backward()就是根据损失函数,对参数 (requires_grad=True) 的去计算他的梯度,并且把它累加保存到x.gard,此时还并未更新其梯度
注意点:
- tensor .data:
- 在tensor的require_grad=False,tensor.data和tensor等价
- require_grad=True时,tensor.data仅仅是获取tensor中的数据
- tensor .numpy() :
- require_grad=True不能够直接转换,需要使用tensor.detach().numpy()
2.4.3 线性回归实现
下面,我们使用一个自定义的数据,来使用torch实现一个简单的线性回归
假设我们的基础模型就是y = wx+b,其中w和b均为参数,我们使用y = 3x+0.8 来造数据x、y,所以最后通过模型应该能够得出w和b应该分别接近3和0.8- 准备数据
- 计算预测值
- 计算损失,把参数的梯度置为0,进行反向传播
- 更新参数
反向传播
a.计算图
把数据和操作通过图来表示
b. 反向传播
i. 从后往前,计算每一层的梯度pytorch完成线性回归
a. tensor(data,requird qrad=True)
i.该tensor后续会被计算梯度
ii. tensor所有的操作都会被记录在grad_fn
b. with torch.no qrad():
i. 其中的操作不会被追踪
c.反向传播: outputbackward()
d.获取梯度:x.grad,累加梯度
i. 所以: 每次反向传播之前需要先把梯度置为0之后tensor.data:获取tensor中的数据
required_grad=True的时候,获取数据内容,不带grad等属性
tensor.detach().numpy()能够实现对tensor中的数据的深拷贝,转化为ndarray类型2.5 调用Pytorch API完成线性回归
目标
- 知道pytorch中Module的使用方法
- 知道pytorch中优化器类的使用方法
- 知道pytorch中常见的损失函数的使用方法
- 知道如何在GPU上运行代码
- 能够说出常见的优化器及其原理
2.5.1 pytorch完成模型常用API
在前一部分,我们自己实现了通过torch的相关方法完成反向传播和参数更新,在pytorch中预设了一些更加灵活简单的对象,让我们来构造模型、定义损失,优化损失等
那么接下来,我们一起来了解一下其中常用的API2.5.1.1 nn.Moudle
nn.Modu1 是torch.nn 提供的一个类,是pytorch中我们自定义网路的一个基类,在这个类中定义了很多有用的方法,让我们在继承这个类定义网络的时候非带简单
当我们自定义网络的时候,有两个方法需要特别注意:
1._init___需要调用super 方法,继承父类的属性和方法
2.farward方法必须实现,用来定义我们的网络的向前计算的过程
用前面的y = wx+b 的模型举例如下:from torch import nn class Lr(nn.Module): def _init__(self): super(Lr,self).__init__() #继承父类init的参数 self.linear = nn.Linear(1,1) def forward(self,x): out = self.linear(x) return out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注意:
1.nn.Linear为torch预定义好的线性模型,也被称为全链接层,传入的参数为输入的数量,输出的数量(in_features,out_features)是不算(batch_size的列数)
2.nn.Module定义了_ca11_方法,实现的就是调用forward方法,即Lr的实例,能够直接被传入参数调用,实际上调用的是 forward方法并传入参数#实例化横配 mode1 = Lr() # 传入数据,计算结果 predict = mode1(x)- 1
- 2
- 3
- 4
2.5.1.2 优化器类
优化器(optimizer),可以理解为torch为我们封装的用来进行更新参数的方法,比如常见的随机梯变下降(stochastic gradient descent,SGD)
优化器类都是由torch.optim提供的,例如
1.torch,optim,SGD(移数,学习率)
2.torch.optim.Adam(参数,学习率)
注意:- 参数可以使用mode1.parameters()来获取,获取模型中所有requires_grad=True的参数
- 优化类的使用方法
1)实例化
2)所有参数的梯度,将其值置为0
3)反向传播计算梯度
4)更新参数值
示例如下:
optimizer m optim,SGD(mode1.parameters(),1rmle-3) #1.实例化 optimizer.zero_grad() #2.梯度值为0 loss.backward() #3.计算梯度 optimizer.step() #4.更新参数的值- 1
- 2
- 3
- 4
2.5.1.3 损失函数
前面的例子是一个回归问题,torch中也预测了很多损失函数
- 均方误差:nn.MSELoss()常用语分类问题
- 交叉饰损失: nn.CrossEntropyLoss(),常用语逻辑回归
2.5.1.4 把线性回归完整代码
使用方法:
model = Lr() #1.实例化横型 criterion = nn,MSELoss() #2.实例化损失函数 optimizer = optim.SGD(model.parameters(),1r=le-3) #3.实例化优化器类 for i in range(100): y_predict = model(x_true) #4.向前计算预测值 loss = criterion(y_true,y_predict) #5,调用损失的数传入真实值和预测值,得到损失结果 optimizer.zero_grad() #5.当前循环参数梯度置为0 loss.backward() #6.计算梯度 optimizer.step() #7.更新参数的值 class Lr(nn,Module): def __init__(self): super(Lr,self)._-init_() self,linear = nn.Linear(1,1) def forward(sef,x): out = self.linear(x) return out # 2.实例化模型,loss,和优化器 model = Lr() criterion = nn.MSELoss() optimizer = optim.SGD(model.parameters(),lr=1e-3) #3.训练模型 for i in range(30000): out = mode1(x) #3.1 获取预测值 loss = criterion(y,out) #3.2 计算损失 optimizer.zero_grad() #3.3 梯度归零 loss.backward() #3.4 计算梯度 optimizer.step() # 3.5 更新梯度 if (i+1) % 20 == 0: print('Epoch[{}/{}],loss:{:.6f}'.format(i,30000,loss.data)) #4.模型评估 model.eval() #设模型为评估模式,即预测模式 predict = model(x) predict = predict.data.numpy() plt.scatter(x.data.numpy(),y.data.numpy0),c="r") plt.plot(x.data.numpy(),predict) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
输出如下
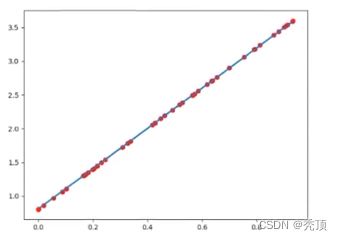
注意:
model.eval()表示设管模型为评估模式,即预测模式
model.train(mode=True) 表设置模型为训练模式
在当前的线性回归中,上述并无区别
但是在其他的一些模型中,训练的参数和预测的参数会不相同,到时候就需要具体告诉程序我们是在进行训练还是预测,比如模型中存在Dropout,BatchNorm的时候使用方法:model = Lr() #1.实例化横型 criterion = nn,MSELoss() #2.实例化损失函数 optimizer = optim.SGD(model.parameters(),1r=le-3) #3.实例化优化器类 for i in range(100): y_predict = model(x_true) #4.向前计算预测值 loss = criterion(y_true,y_predict) #5,调用损失的数传入真实值和预测值,得到损失结果 optimizer.zero_grad() #5.当前循环参数梯度置为0 loss.backward() #6.计算梯度 optimizer.step() #7.更新参数的值 class Lr(nn,Module): def __init__(self): super(Lr,self)._-init_() self,linear = nn.Linear(1,1) def forward(sef,x): out = self.linear(x) return out # 2.实例化模型,loss,和优化器 model = Lr() criterion = nn.MSELoss() optimizer = optim.SGD(model.parameters(),lr=1e-3) #3.训练模型 for i in range(30000): out = mode1(x) #3.1 获取预测值 loss = criterion(y,out) #3.2 计算损失 optimizer.zero_grad() #3.3 梯度归零 loss.backward() #3.4 计算梯度 optimizer.step() # 3.5 更新梯度 if (i+1) % 20 == 0: print('Epoch[{}/{}],loss:{:.6f}'.format(i,30000,loss.data)) #4.模型评估 model.eval() #设模型为评估模式,即预测模式 predict = model(x) predict = predict.data.numpy() plt.scatter(x.data.numpy(),y.data.numpy0),c="r") plt.plot(x.data.numpy(),predict) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
输出如下
注意:
model.eval()表示设管模型为评估模式,即预测模式
model.train(mode=True) 表设置模型为训练模式
在当前的线性回归中,上述并无区别
但是在其他的一些模型中,训练的参数和预测的参数会不相同,到时候就需要具体告诉程序我们是在进行训练还是预测,比如模型中存在Dropout,BatchNorm的时候2.5.2 在GPU上运行代码
当模型太大,或者着数太多的情况下,为了加快训练速度,经常会使用GPU来进行训练此时我们的代码需要稍作调整:
- 判斯GPU是否可用torch.cuda.is_available()
torch.device("cuda:0” if torch,cuda.is_available() else “cpu") >> device(type='cuda',index=0) #使用gpu >> device(type='cpu') #使用cpu- 1
- 2
- 3
- 把模型参数和input数据转化为cuda的支持类型
model.to(device) x_true.to(device)- 1
- 2
- 在GPU上计算结果也为cuda的数据类型,需要转化为numpy或者torch的cpu的tensor类型
predict = predict.cpu() .detach().numpy()- 1
detach( )的效果和data的相似,但是detach()是深拷贝,data是取值,是浅拷贝
修改之后的代码如下:import torch from torch import nn from torch import optim import numpy as np from matplotlib import pyplot as plt import time # 1.定义数据 x = torch.rand([50,1]) y=x*3+0.8 #2 .定义模型 class Lr(nn.Module): def _init_(self): super(Lr,self)._init_() self.linear = nn.Linear(1,1) def forward(self,x): out = self.linear(x) return out # 2.实例化模型,loss,和优化器 device = torch.device("cuda:0" if torch.cuda.is_available) else "cpu") x,y = x.to(device),y.to(device) model = Lr().to(device) criterion = nn.MSELoss() optimizer = optim.SGD(model.parameters(),1r=le-3) #3.训练,模型 for i in range(300): out = model(x) loss = criterion(y,out) optimizer.zero_grad() loss .backward() optimizer.step() if (i+1) % 20 == 0: print('Epoch[{}/{}],loss:{:.6f}'.format(i,30000,loss.data)) #4.模型评估 model.eval() predict = model(x) predict = predict,cpu().detach().numpy() #转化为numpy数组 plt.scatter(x.cpu().data.numpy(),y.cpu().data.numpy(),c="r") plt.plot(x.cpu().data.numpy()predict,) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43

2.5.3 常见的优化算法介绍
2.5.3.1 梯度下降算法
每次迭代都需要把所有样本都送入,这样的好处是每次迭代都顾及了全部的样本,做的是全局最优化。
2.5.3.2 随机梯度下降法
针对梯度下降算法训练速度过慢的缺点,提出了随机梯度下降算法,随机梯度下降算法算法是从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型了。
torch中的api为: torch.optim.SGD()2.5.3.3 小批量梯度下降
SGD相对来说要快很多,但是也有存在问题,由于单个样本的训练可能会带来很多噪声,使得SGD并不是每次迭代都向着整体最优化方向,因此在刚开始训练时可能收敛得很快,但是训练一段时间后就会变得很慢。在此基础上又提出了小批量梯度下降法,它是每次从样本中随机抽取一小批进行训练,而不是一组,这样即保证了效果又保证的速度。
2.5.3.4 动量法
mini-batch SGD算法虽然这种算法能够带来很好的训练速度,但是在到达最优点的时候并不能够总是真正到达最优点,而是在最优点附近徘徊。
另一个缺点就是mini-batch SGD需要我们挑选一个合适的学习率,当我们采用小的学习率的时候会导致网络在训练的时候收敛太慢,当我们采用大的学习率的时候,会导致在训练过程中优化的幅度跳过函数的范围,也就是可能跳过最优点。我们所希望的仅仅是网络在优化的时候网络的损失函数有一个很好的收敛速度同时又不至于摆动幅度太大。
所以Momentum优化器刚好可以解决我们所面临的问题,它主要是基于梯度的移动指数加权平均,对网络的参数进行平滑处理的,让梯度的摆动幅度变得更小。
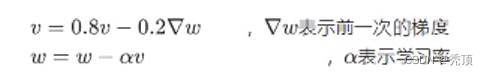
2.5.3.5 AdaGrad
AdaGrad算法就是将每一个参数的每一次迭代的梯度取平方累加后在开方,用全局学习率除以这个数,作为学习率的动态更新,从而达到自适应学习率的效果。
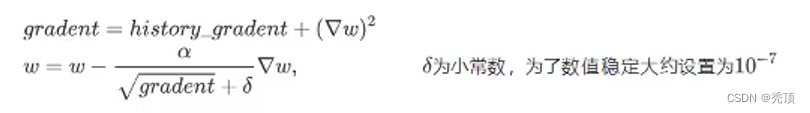
2.5.3.6 RMSProp
Momentum优化算法中,虽然初步解决了优化中摆动幅度大的问题,为了进一步优化损失函数在更新中存在摆动幅度过大的问题,并且进一步加快函数的收敛速度,RMSProp算法对参数的梯度使用了平方加权平均数。
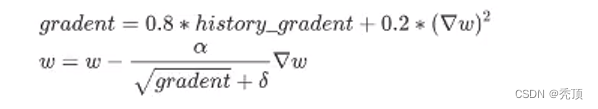
2.5.3.7 Adam

常见的优化算法:
1.梯度下降:全局最优
2. 随机梯度下降:随机的从样本中抽出一个样本进行梯度的更新
3.小批量梯度下降:找一波数据计算梯度,使用均值更新参数
4.动量法:对梯度进行平滑处理,防止振幅过大
5.adaGrad:自适应学习率
6.RMSProp:对学习率进行加权
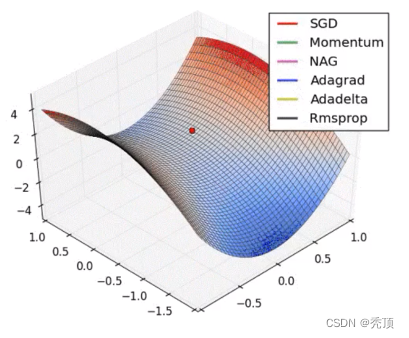
7.Adam:动量法+RMSprop,学习率能够自适应,梯度的振幅不会过大2.5.3.8 效果演示
2.6 Pytorch中的数据加载
目标
- 知道数据加载的目的
- 知道pytorch中Dataset的使用方法
- 知道pytorch中DataLoader的使用方法
- 知道pytorch中的自带数据集如何获取
2.6.1 模型中使用加载器的目的
在前面的线性回归模型中,我们使用的教据很少,所以直接把全部数据放到模型中去使用。但是在深度学习中,数据量通常是都非常多,非常大的,如此大量的数据,不可能一次性的在模型中进行向前的计算和反向传播,经带我们会对整个数据进行随机的打乱顺序,把数据处理成一个个的batch,同时还会对数据进行预处理。
所以,接下来我们来学习pytorch中的数据加载的方法。2.6.2 数据集类
2.6.2.1 Dataset基类介绍
在torch中提供了数据集的基类torch.utils.data.Dataset,继承这个基类,我们能够非常快速的实现对数据的加载。
torch.utils.data.Dataset的源码如下:
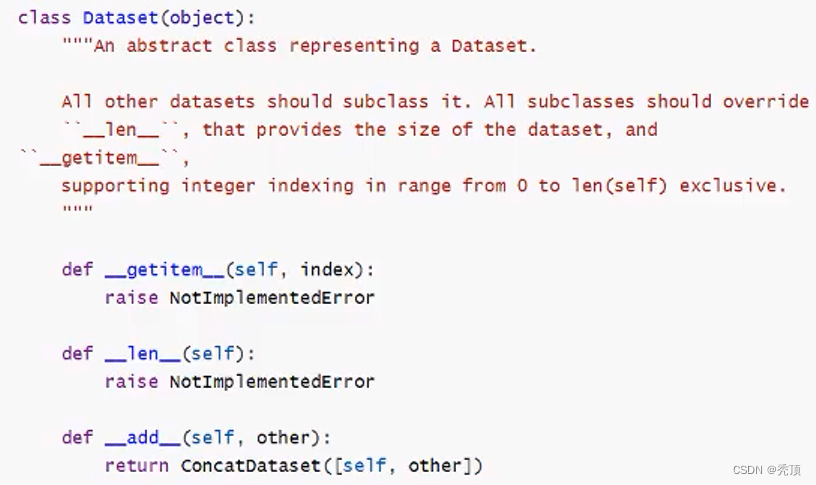
可知:我们需要在自定义的数据集类中继承Dataset类,同时还需要实现两个方法
1._len_方法,能够实现通过全局的len()方法获取其中的元素个数
2._getitem__方法,能够通过传入索引的方式获取数据,例如通过dataset[i]获取其中的第i条数据2.6.2.2 数据加载案例


2.6.2.3 迭代数据集
使用上述的方法能够进行数据的读取,但是其中还有很多内容没有实现:
- 批处理数据 (Batching the data)
- 打乱数据(Shuffling the data)
- 使用多线程multiprocessing 并行加载数据。
在pytorch中torch.utils.data.DataLoader提供了上述的所用方法
DataLoader的使用方法示例:

其中参数含义
- dataset: 提前定义的dataset的实例
- batch_size:传入数据的batch的大小,常用128,256等等
- shufle: bool类型,表示是否在每次获取数据的时候提前打乱数据
- num_workers:加载数据的线程数

注意 - len(dataset) =数据集的样本数
- len(dataloader) = math.ceil(样本数/batch_size) 即向上取整
2.6.2.4 pytorch自带的数据集
pytorch中自带的数据集由两个上层api提供,分别是torchvision和torchtext
其中:- torchvision 提供了对图片数据处理怕关的api和数据
- 数据位: torchvision.datasets,例如: torchvision.datasets.MNIST(手写数字图片数据)
- torchtext提供了对文本数据处理相关的API和数据
- 数据位置: torchtext.datasets ,例如: torchtext.datasets.IMDB (电影评论文本数据)
下面我们以Mnist手写数字为例,来看看pytorch如何加载其中自带的数据集使用方法和之前一样:
- 准备好Dataset实例
- 把dataset交给dataloder 打乱顺序,组成batch
2.6.2.4.1 torchversion.datasets

-
相关阅读:
好书分享:《optisystem案例解析》
【附源码】计算机毕业设计SSM网上人才招聘系统
20. 有效的括号
JavaWeb(文件上传 异步文件上传 文件下载)
【牛客网】排序子序列
前端小tips(持续更新)
MyBatis-Plus入门案例
YOLOv7独家原创改进:最新原创WIoU_NMS改进点,改进有效可以直接当做自己的原创改进点来写,提升网络模型性能精度
DeepinV20/Ubuntu安装postgresql方法
详解Linux的grep命令
- 原文地址:https://blog.csdn.net/weixin_45529272/article/details/127939827
