-
Java Class11
Java Class11
集合
概念
集合是用于存储对象的工具类容器,实现了常用的数据结构,提供了一系列公开的方法用于删除、修改、查找和遍历数据,降低了日常开发成本。
三种集合
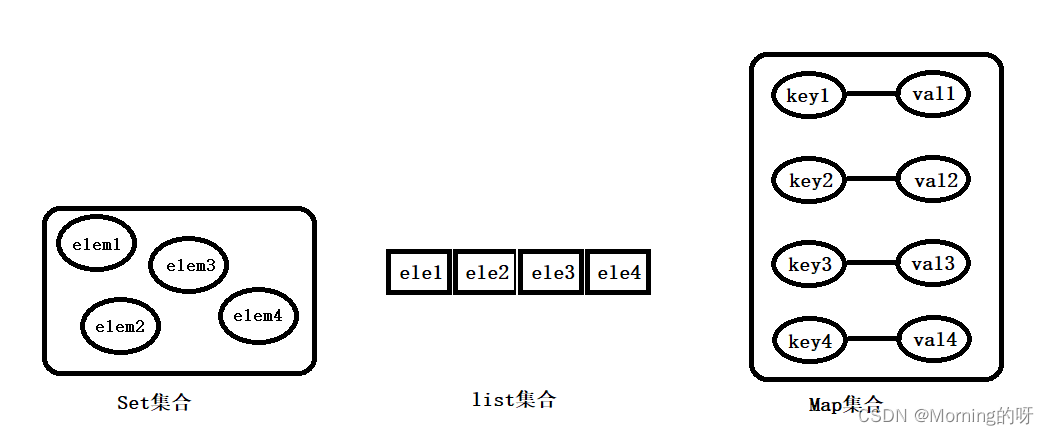
Set
set集合中元素是无序、不可重复的List
list集合中元素是从前到后遍历的
List分为ArrayList和LinkedListMap
map集合采用键值对存储,一个键对应一个值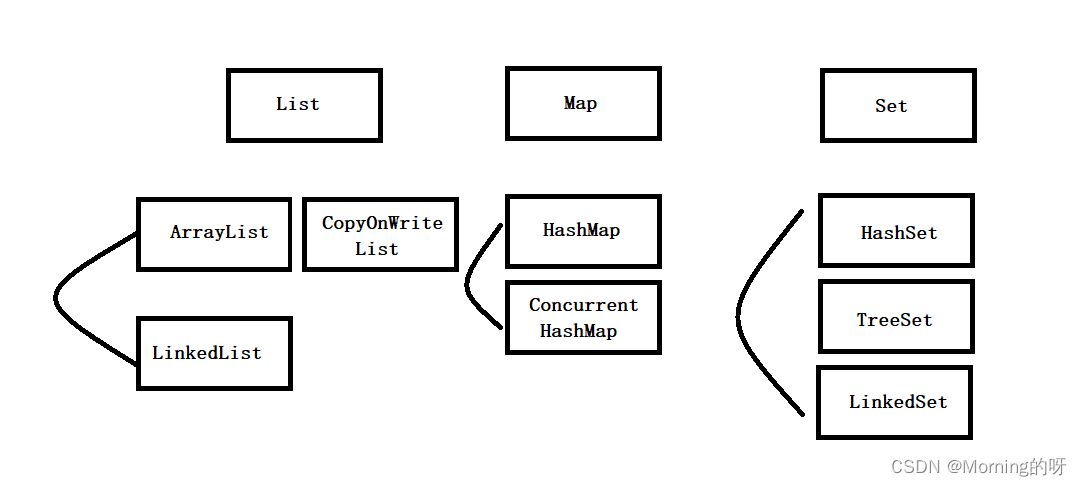
ArrayList
基本操作
public class Demo { public static void main(String[] args) { List<Integer> list=new ArrayList<>();//定义ArrayList集合 //add增 list.add(1); list.add(2); list.add(3); //remove删 list.remove(2); //set改 list.set(0,3); //get取 list.get(0); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
三种遍历方式
public class A { public static void main(String[] args) { //定义ArrayList集合 List<Integer> list=new ArrayList<>(1000);//开辟空间为1000,类型为Integer //进行add操作 添加元素 list.add(1); list.add(2); list.add(3); for(int i=0;i<list.size();i++){//循环遍历集合的值 System.out.println(list.get(i));//依次遍历输出元素的值 } Iterator <Integer>it=list.iterator();//初始化迭代器 while (it.hasNext()){//判断下一元素值是否存在 Integer i=it.next();//遍历下一元素的值 System.out.println(i);//打印当前元素的值 } for(int i:list){//利用foreach循环遍历元素的值 System.out.println(i); } //定义ArrayList集合并赋初值 List<Integer> list2= Arrays.asList(1,2,3,4,5); //已经定义初值的集合不能对元素的个数进行修改 // list2.add(6); // list2.remove(2); // list2.clear(); list2.set(1,30);//set操作是修改元素的值,并没有改动元素个数 } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
可变形参
public class Demo { private int age; private String name; public void method1(int age1,String name1){ age=age1; name=name1; } public void method2(int age1,int age2,String name1){ age1=age2; age=age1; name=name1; } public void method3(String name,int...age){ } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
可变形参可以帮助解决重载问题,避免同一类型参数重复调用造成冗余
fail-safe
fail-fast
fail-fast存在多线程环境下,当线程1对集合进行遍历时,线程2在期间进行修改,造成线程1读取的结果发生变化public class B { public static void main(String[] args) { List list=new ArrayList();//定义集合 list.add(1); list.add(2); list.add(3); List list1=list.subList(0,2); list.remove(0); list.add(6); // 输出子集合会报错,输出原集合不会报错 // System.out.println(list1); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
上述代码中,两个list同时对其进行读写操作,控制台会报异常,启动sail-safe机制保证读写一致。
addAll可以看做是add操作的加强版,可以一次性将多个值一次存储到集合,避免了每次add都会进行的开堆操作。
public class C { public static void main(String[] args) { List<String> list=new ArrayList<>();//定义list集合 Collection c=new ArrayList();//定义集合 //向集合添加元素 c.add("A"); c.add("B"); c.add("C"); list.addAll(c);//addAll一次加入元素 Iterator<String> it=list.iterator();//定义迭代器 while (it.hasNext()){//判断是否还有下个元素 System.out.println(it.next());//打印下个元素 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
CopyOnWriteArrayList
CopyOnWriteArrayList是基于ArrayList在多线程处理中出现异常而出现的。
CopyOnWriteArrayList在内部会进行加锁操作,在多线程时会复制一个新的集合,在原来的集合中进行读操作,而在复制集合中进行修改操作,修改操作完毕后将原集合指针指向复制集合,原集合做删除操作。
public class C1 { public static void main(String[] args) { List<String> list=new ArrayList<>();//定义list集合 //向集合依次添加元素 list.add("A"); list.add("B"); list.add("C"); List<String> list2=new CopyOnWriteArrayList<>();//定义COW集合 list.add("D"); Iterator<String> it=list.iterator();//定义迭代器 while (it.hasNext()){//判断是否由下一个元素 System.out.println(it.next());//进行打印 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
CopyOnWriteArrayList的内存占用很大,所以不适合进行多次修改操作
原来集合内存占用:100M
复制集合占用:100M
插入大小占用:10M总共:100+100+10=210M
LinkedList
LinkedList是双向链表,LinkedList插入和删除快,但查找慢。
public class D { public static void main(String[] args) { Queue<String> q=new LinkedList<>();//定义Linked集合 //依次输入元素的值 q.offer("北京"); q.offer("上海"); q.offer("广州"); String str="";//定义字符串 while ((str=q.poll())!=null){//判断是否为空 System.out.println(str);//打印元素的值 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
ArrayList与LinkedList比较
ArrayList底层采用顺序表进行存储,所以查找容易,增删改操作效率较低
LinkedList底层采用双向链表进行存储,所以增删改操作容易,但查找不如ArrayList
HashMap
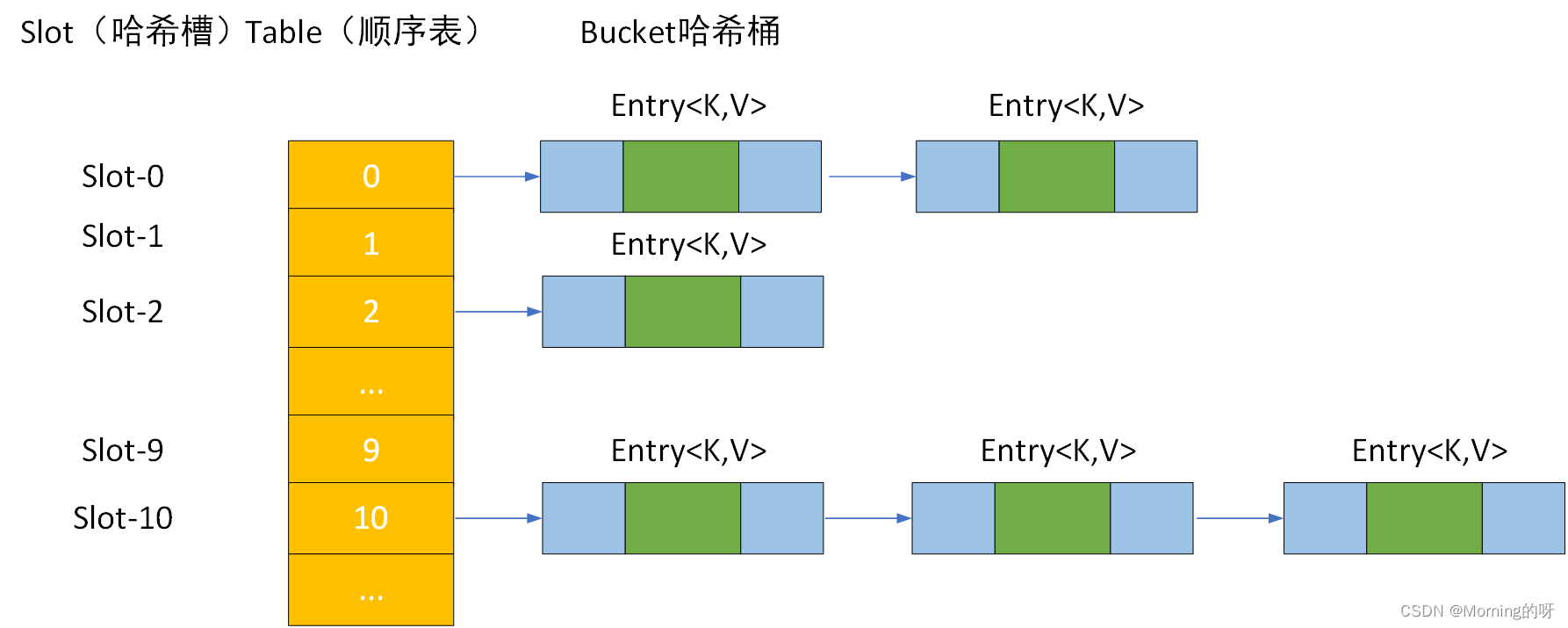
HashMap在JDK8.0前是是顺序表+链表
JDK8.0后是顺序表+链表+红黑树slot哈希槽:位置标识,类似指针对应数组的下标
table顺序表:是一个数组,做bucket的表头
bucket哈希桶:用链表存储对应的元素的值public class E { public static void main(String[] args) { Map<String,Object> map=new HashMap(100);//定义HashMap map.put("北京",100); map.put("上海",200); map.put("天津",300); map.put(null,null); List list=new ArrayList();//定义list集合 list.add("张"); list.add("王"); list.add("李"); Iterator it=map.keySet().iterator();//定义迭代器 //输出键 while (it.hasNext()){ System.out.println(it.next()); } System.out.println(); Iterator it2=map.values().iterator();//定义迭代器 //输出值 while (it2.hasNext()){ System.out.println(it2.next()); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
HashMap存在的问题
1.数据丢失
两个线程同时进行修改操作时,后一个操作会覆盖前一个,造成对象丢失2.已遍历区间新增元素会丢失
使用迁移方法时,新增的元素会落在已遍历过的哈希槽上,在遍历完成后,table数组引用指向了newTable,这时新增元素会被当做垃圾回收3.新表会被覆盖
4.迁移丢失
ConcurrentHashMap
ConcurrentHashMap采用volatile关键字而不使用加锁方法,牺牲部分效率,但性能较好
ConcurrentHashMap利用锁分段技术加强锁的数量,使争夺同一把锁的线程数目得到控制。
使用锁分段技术,在面对大量数据的时候,想要处理部分数据不需要对整体加锁(这样频繁操作会大大降低效率),而是采用锁分段技术对每段数据进行加锁,这样只需要对该部分进行解锁,而不改变其他数据段,从而提高效率
但在面对size(判断大小)containsValue(查找值)等操作需要遍历整体才能得出结果时,还是需要对整体进行加锁
ConurrentHashMap由Segment和HashEntry组成。
Segment是一种可重入锁
HashEntry用来存储键值对数据Segment结构和HashMap类似,一个Segment包含一个HashEntry数组
Set
Set中不允许出现重复元素
常用HashSet、TreeSet、LinkedSet等 -
相关阅读:
Linux操作系统使用及C高级编程
CSDN的md编辑器如何输入上下标?公式和非公式的输入方式不一样
webGL编程指南 第三章 平移三角形 TranslatedTriangle.js
编译着色器并在屏幕上绘图
【统计任意一组字符中大小写字母的个数】
Dockerfile文件详细教程
地理标志农产品质量安全风险评估及预警研究
cpu温度监测 Turbo Boost Switcher Pro for mac最新
[PostgreSQL的 SPI_接口函数]
JavaScript事件流:深入理解事件处理和传播机制
- 原文地址:https://blog.csdn.net/qq_45325217/article/details/127877876
