-
编码命名方式知多少
0.前言
大咖好呀,我是恋喵大鲤鱼。
软件开发中,命名无处不在。
比如我们需要对项目命名、目录命名、文件命名、类命名、变量命名,还有其他类型的资源等等。那么取名时,业界有哪些命名方法呢?
本文将列举常见的命名方法,没有孰优孰劣,每种都有其各自的使用场景。至于项目中采取哪种命名方式,不同的公司团队,不同的编程语言,不同的技术领域均不尽相同。我们需要坚持的一点就是统一至上。
统一的命名风格可以提高源码的可读性和可维护性,每一个开发团队都应该践行。
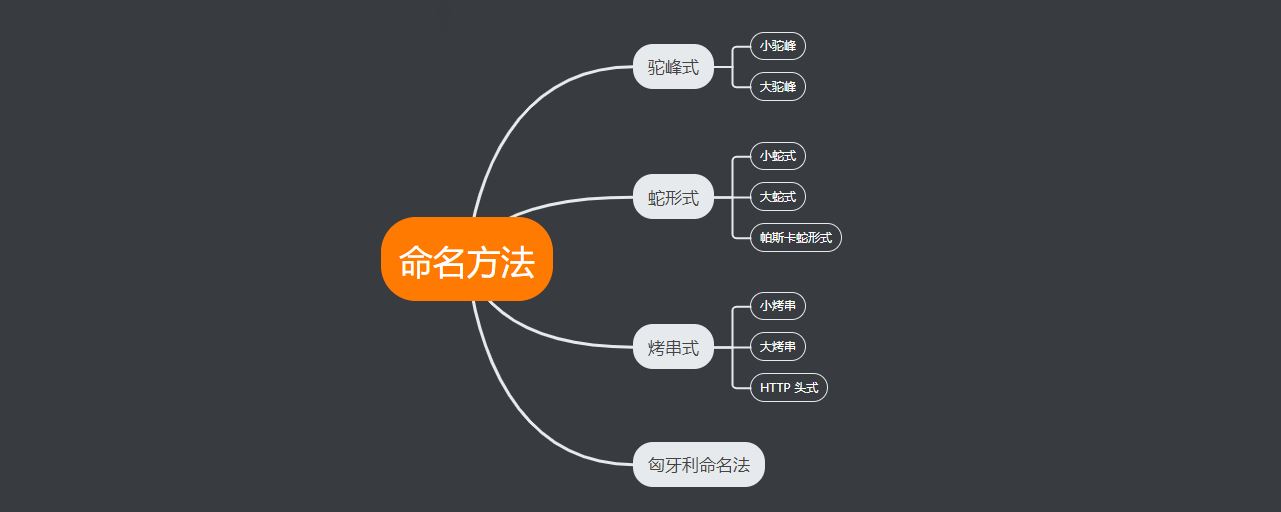
1.驼峰式
驼峰命名法(Camel Case)不同单词之间没有分隔符,采用大小写混合的方式区分不同单词。
小驼峰
如果第一个单词首字母小写,称为小驼峰(camelCase)。

大驼峰
如果第一个单词首字母大写,称为大驼峰(CamelCase)。

注意: 大驼峰命名法还有一个名字,叫 Pascal 命名法。这是因为该命名规范最早由 Niklaus Wirth 在 1970 年代提出,以纪念法国数学家和物理学家 Blaise Pascal(1623-1662年)。Pascal 是一位重要的数学家和自然科学家,对于概率论、流体力学和计算器的发明有重要贡献。
驼峰式是一种非常流行的将单词组合成单个概念的方式。在许多语言中(如 Java、JavaScript、C#),小驼峰常被用来命名局部变量和函数,大驼峰常用来命名全局变量和类。
2.蛇形式
蛇形命名法(Snake Case)使用下划线分隔不同单词。

小蛇式
如果所有单词都小写,称为小蛇式(snake_case)。
小蛇式通常用于声明数据库字段名。此外,URL 参数一般也使用 snake_case。在某些 API 设计中,如果查询参数的键与值直接放在 URL 中,可以使用 snake_case。例如 https://api.example.com/users?user_name=john_doe。
大蛇式
如果所有单词都大写,称为大蛇式(SCREAMING_SNAKE_CASE)。
之所以加个 screaming,因为在英文中,如果一个单词全部大写,表示大声喊叫,引起他人的注意。
大蛇式通常用于宏定义和被许多语言用来命名常量。
帕斯卡蛇形式
如果所有单词首字母都大写,称为帕斯卡蛇形式(Pascal_Snake_Case)。
Pascal_Snake_Case 是将两种命名方式组合而成的一种命名风格。它是由 Pascal Case(帕斯卡命名法)和 Snake Case(蛇形命名法)组合而成。
这种命名方式在实际开发中较少使用,因为它将两种不同的命名风格结合在一起,可能会导致命名混乱,降低代码的可读性和一致性。
3.烤串式
烤串命名法(Kebab Case)使用中划线分隔不同单词。
烤串命名法使用中划线连接多个单词,从而形成一个字符串。由于这种连接方式形象地类似于烤肉串,因此取名为烤串命名法。

小烤串式
如果所有单词都小写,称之为小烤串式(kebab-case)。
小烤串式在 Lisp 编程语言中经常被用到,所以有时也叫做 lisp-case。
URL 路径中经常使用小烤串式。例如 www.blog.com/cool-article-1。这是一种很好的、干净的、可读的单词组合方式。
我们在 K8S 的资源配置文件中也会看到 kebab-case。
此外,在 CSS 中,所有属性名称和大多数关键字值也主要采用 kebab-case 格式。
大烤串式
如果所有单词都大写,称之为大烤串式(SCREAMING-KEBAB-CASE)。
大烤串式主要用于突出强调被命名的对象,古老的 Cobol 编程语言中经常使用,所以有时也被称为 COBOL-CASE。
HTTP 头式
如果所有单词首字母都大写,称之为 HTTP 头式(HTTP-Header-Case)。
因为 HTTP 头部字段的命名使用这种方式,所以称之为 HTTP 头式,如 Content-Type、User-Agent 等。
4.匈牙利命名法
匈牙利命名法(Hungarian notation)是早期的规范,由微软程序员查尔斯-西蒙尼(Charles Simonyi)发明,因其为匈牙利人,故被称为匈牙利命名法。

匈牙利命名法要求标识符使用一个小写前缀来表示变量的类型或用途。按照在微软中的使用场景,分为匈牙利应用命名法和匈牙利系统命名法。
匈牙利应用命名法指在微软软件产品中使用的匈牙利命名法,比如 Word、Excel 和其他应用程序。
匈牙利系统命名法是指在 Windows 操作系统中使用的匈牙利命名法,因 Windows API 而被大家熟知。
匈牙利系统命名法在匈牙利应用命名法之后出现,二者的区别主要在于前缀的目的不同。
系统匈牙利命名法的前缀主要用于表示变量的物理类型。
lAccountNum // 变量是 long int 类型 arru8NumberList // arr 表示数组,u8 表示 uint8,所以整个变量表示 uint8 数组 bBusy // 布尔类型- 1
- 2
- 3
一些常见的前缀类型有:
arr 数组(Array) b 布尔值(Boolean) by 字节(Byte) ch 字符(Char) f 浮点型(Float) fn 函数(Function) h 句柄(Handle) i 整型(Int) l 长整型(Long Int) u 无符号整型(Unsigned Int) u8 无符号 8 位整型(Unsigned Int8) u16 无符号 16 位整型(Unsigned Int16) u32 无符号 32 位整型(Unsigned Int32) p 指针(Pointer) lp 长指针(Long Pointer) s 字符串(String) w 字(Word) dw 双字(Double Word)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
还有其他更多的前缀是根据微软自己的 MFC/句柄/控件/结构等东西定义的,就不过多描述了。
匈牙利应用命名法的前缀主要目的是力求对逻辑数据类型而非物理数据类型进行编码,也就是提示变量的目的是什么,或者它代表什么。
rwPosition // 表示一个行(Row)的位置 usName // 表示不安全字符串(unsafe string) szName // 表示以 Null 做结尾的字符串(zero-terminated string)- 1
- 2
- 3
Simonyi 提出的大多数(但不是全部)前缀本质上是语义的,现在来看,一些前缀也表示物理数据类型,例如以 Null 做结尾的字符串使用 sz 前缀。然而,这些前缀仍然是语义上的,因为 Simonyi 的想法是使用语义化的前缀来表示变成语言的类型系统无法表达的逻辑上数据类型。
Simonyi 建议的大多数前缀都是自然语义的,但不是所有。下面几个是来自微软官方文档。
- pX 指向另一个X类型的指针,这包含非常少的语义信息。
- d 是一个前缀表示两个值的区别,例如,dY可能代表一个图形沿Y轴的距离,而一个仅仅叫做y的变量可能是一个绝对坐标。这完全是自然语义的。
- sz 是一个无结束或零结束的字符串。在 C 中,这包含一些语义信息,因为C语言的char*类型的变量不确定是一个指向单个字符的指针,还是一个字符数组,或是一个零结束字符串。
- w 标记一个变量是一个字。这基本上没有包含什么语义信息,因此可以被看作一种匈牙利系统命名法。
- b 表示一个字节,和w对比可能有一些语义信息,因为C语言中,只有char型(以及signed/unsigned char)是一个字节长的,这些类型有时候被用来保存数值而非字符。这个前缀可以明确某个变量保存的是字符还是数值。
在使用匈牙利应用命名法的代码中有时候也可能包含匈牙利系统命名法,即在描述被单独以类型方式定义的变量时使用。
匈牙利命名法在 C++ 中被扩展而包含变量的作用域,由一个下划线隔开:
g_nWheels // 全局命名空间的成员,整型 m_nWheels // 结构体/类成员,整型- 1
- 2
匈牙利命名法是一个十分复杂繁琐的命名规范,它诞生在 IDE 还不够发达的年代。在那个年代,当代码量很多的时候,想要确定一个变量的类型很麻烦,不像现在 IDE 都会给提示,所以才产生了匈牙利命名法,现在已经很少使用了。
5.小结
除了文中介绍的常见命名方法,如果要连接的单词简短且数量不多的情况下(比如2个),直接全小写拼接或全大写拼接也未尝不可,比如 filepath 和 FILEPATH。
面对众多的命名方法,我们要知道没有最好的命名方法,就像没有最好的编程语言一样。
如果一个团队在命名方法上保持一致,那么选择使用哪个命名方法并非那么重要,当然最好要和业界做法保持一致。
如果您喜欢这篇文章,欢迎关注微信公众号“恋喵大鲤鱼”了解最新精彩内容。
参考文献
Camel case - Wikipedia
Snake case - Wikipedia
Hungarian notation - Wikipedia
Naming convention (programming) - Wikipedia
Case Styles: Camel, Pascal, Snake, and Kebab Case
COBOL - Wikipedia -
相关阅读:
Flutter 中的单元测试:从工作流基础到复杂场景
C语言之判断与循环语句知识点总结
【计算机网络笔记九】I/O 多路复用
如何创建集成 LSP 支持多语言的 Web 代码编辑器
[EFI]华硕 Asus VivoBook S510UA 电脑 Hackintosh 黑苹果efi引导文件
mysql 1030 Got error 28 from storage engine
[架构之路-240]:目标系统 - 纵向分层 - 应用层 - 应用层协议与业务应用程序的多样化,与大自然生物的丰富多彩,异曲同工
SpringMVC(六、声明式事务控制)
Excel文件带有密码的只读模式,如何设置?
代码管理工具:Git
- 原文地址:https://blog.csdn.net/K346K346/article/details/127953825
