-
关于vagrant up的一个终结之谜(Markdown版本)
背景
使用vagrant管理的机器,在使用vagrant命令的过程中总有一些问题. vagrant up 有时候会拉不起机器。 虽然公司的很多闲置机器没有充分利用,但是鉴于对目前的这个问题应该还是要很谨慎的上线核心项目。对虚拟化的技术还需要加强。
此外,对于开源的使用有必要时常关心release log, 看看你的问题是否被修复,可以选择升级来解决。
综述,开源需谨慎,PLAN B 一定要。 辨证的来看,流行的开源软件一般都有人维护,大家齐心协力修bug,一般不会有太fatal的bug, 但是不排除所以核心业务一定要有背书,否则你力荐推广,背锅的一定是你. 这时又得辩证的看待这个问题,成功与失败就在一瞬间,如果你力荐推广一个开源技术,然后投入大量经历去研究,当有一定深度(看懂源代码、可以修改源代码、可以开发新feature …) 就可以cover掉开源的劣势。那你就成为大牛啦.vagrant up 无法连接机器
根据提示,vagrant 好像无法管理这个机器了,无法ssh也ping不通。但是statu 却显示running,感觉好像是vagrant的bug. 这里有个同样的问题
下面是详细的log
/gpmaster/gpseg-1_down/k8s/k8s-node2]#vagrant reload ==> node: Attempting graceful shutdown of VM... node: Guest communication could not be established! This is usually because node: SSH is not running, the authentication information was changed, node: or some other networking issue. Vagrant will force halt, if node: capable. ==> node: Forcing shutdown of VM... ==> node: Clearing any previously set forwarded ports... ==> node: Fixed port collision for 22 => 2222. Now on port 2209. ==> node: Clearing any previously set network interfaces... ==> node: Preparing network interfaces based on configuration... node: Adapter 1: nat ==> node: Forwarding ports... node: 22 (guest) => 2209 (host) (adapter 1) ==> node: Running 'pre-boot' VM customizations... ==> node: Booting VM... ==> node: Waiting for machine to boot. This may take a few minutes... node: SSH address: 127.0.0.1:2209 node: SSH username: vagrant node: SSH auth method: private key Timed out while waiting for the machine to boot. This means that Vagrant was unable to communicate with the guest machine within the configured ("config.vm.boot_timeout" value) time period. If you look above, you should be able to see the error(s) that Vagrant had when attempting to connect to the machine. These errors are usually good hints as to what may be wrong. If you're using a custom box, make sure that networking is properly working and you're able to connect to the machine. It is a common problem that networking isn't setup properly in these boxes. Verify that authentication configurations are also setup properly, as well. If the box appears to be booting properly, you may want to increase the timeout ("config.vm.boot_timeout") value.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
vagrant status查看状态
/gpmaster/gpseg-1_down/k8s/k8s-node2]#vagrant status Current machine states: node running (virtualbox) The VM is running. To stop this VM, you can run `vagrant halt` to shut it down forcefully, or you can run `vagrant suspend` to simply suspend the virtual machine. In either case, to restart it again, simply run `vagrant up`. [root@P1WQMSMDW02 /gpmaster/gpseg-1_down/k8s/k8s-node2]#vagrant halt ==> node: Attempting graceful shutdown of VM... node: Guest communication could not be established! This is usually because node: SSH is not running, the authentication information was changed, node: or some other networking issue. Vagrant will force halt, if node: capable. ==> node: Forcing shutdown of VM...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
再次重现vagrant up无法拉起机器
2022年11月20日22:04:16
这次的情况是这样的,升级了OS 的内核,然后直接在虚拟机里面执行reboot
执行的操作如下:#默认启动的顺序是从0开始,新内核是从头插入(目前位置在0,而4.4.4的是在1),所以需要选择0。 grub2-set-default 0 #重启并检查 reboot- 1
- 2
- 3
- 4
然后就起不来了…

尝试用virtualbox的命令行工具启停虚拟机
0、ping主机
无法ping通.
1、VBoxManage list runningvms l 列出正在运行的vm
[root@p1edaspk03 /nfs/k8s-node]#ps -ef | grep -i virtu root 50698 132091 1 21:51 ? 00:00:14 /usr/lib/virtualbox/VBoxHeadless --comment master1-186 --startvm e480abec-465f-4826-8cc6-a2270a4f3878 --vrde config root 66072 44455 0 22:09 pts/2 00:00:00 grep --color=auto -i virtu root 132084 1 0 Nov10 ? 00:00:07 /usr/lib/virtualbox/VBoxXPCOMIPCD root 132091 1 0 Nov10 ? 00:01:44 /usr/lib/virtualbox/VBoxSVC --auto-shutdown You have mail in /var/spool/mail/root [root@p1edaspk03 /nfs/k8s-node]# You have mail in /var/spool/mail/root [root@p1edaspk03 /nfs/k8s-node]# [root@p1edaspk03 /nfs/k8s-node]#VBoxManage list runningvms "master1-186" {e480abec-465f-4826-8cc6-a2270a4f3878} [root@p1edaspk03 /nfs/k8s-node]#- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2、VBoxManage controlvm 【第一步获取的uuid】 poweroff
[root@p1edaspk03 /nfs/k8s-node]#VBoxManage controlvm e480abec-465f-4826-8cc6-a2270a4f3878 poweroff 0%...10%...20%...30%...40%...50%...60%...70%...80%...90%...100% [root@p1edaspk03 /nfs/k8s-node]# [root@p1edaspk03 /nfs/k8s-node]#VBoxManage list runningvms^C [root@p1edaspk03 /nfs/k8s-node]#- 1
- 2
- 3
- 4
- 5
3、查看vm是否存在
[root@p1edaspk03 /nfs/k8s-node]#ps -ef | grep -i virtu root 67239 44455 0 22:11 pts/2 00:00:00 grep --color=auto -i virtu [root@p1edaspk03 /nfs/k8s-node]# [root@p1edaspk03 /nfs/k8s-node]#vagrant global-status id name provider state directory -------------------------------------------------------------------------- 8162a08 node1-186 virtualbox running /nfs/k8s-node- 1
- 2
- 3
- 4
- 5
- 6
- 7
4、vagrant查看vm状态
出现了一个矛盾的情况, 两个命令结果不一样,不过人家也解释了可能存在cache.
使用如下命令清除cachevagrant global-status --prune- 1
详细的日志.
[root@p1edaspk03 /nfs/k8s-node]#vagrant global-status id name provider state directory -------------------------------------------------------------------------- 8162a08 node1-186 virtualbox running /nfs/k8s-node The above shows information about all known Vagrant environments on this machine. This data is cached and may not be completely up-to-date (use "vagrant global-status --prune" to prune invalid entries). To interact with any of the machines, you can go to that directory and run Vagrant, or you can use the ID directly with Vagrant commands from any directory. For example: "vagrant destroy 1a2b3c4d" [root@p1edaspk03 /nfs/k8s-node]# [root@p1edaspk03 /nfs/k8s-node]# [root@p1edaspk03 /nfs/k8s-node]# [root@p1edaspk03 /nfs/k8s-node]# [root@p1edaspk03 /nfs/k8s-node]# [root@p1edaspk03 /nfs/k8s-node]# [root@p1edaspk03 /nfs/k8s-node]#vagrant status Current machine states: node1-186 poweroff (virtualbox)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21

vagrant halt 停vm
]#vagrant halt ==> node1-186: Attempting graceful shutdown of VM... node1-186: Guest communication could not be established! This is usually because node1-186: SSH is not running, the authentication information was changed, node1-186: or some other networking issue. Vagrant will force halt, if node1-186: capable. ==> node1-186: Forcing shutdown of VM... You have mail in /var/spool/mail/root- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
vagrant up 启动vm
e]#vagrant ssh ssh_exchange_identification: read: Connection reset by peer- 1
- 2
目前的解决方案
删掉重新拉起一个,所以重要的vm要做好备份,
vagrant destroy -f- 1
正常的vagrant up日志
]#time bash startk8s.sh ==> node1-186: Attempting graceful shutdown of VM... ==> node1-186: Clearing any previously set forwarded ports... ==> node1-186: Clearing any previously set network interfaces... ==> node1-186: Preparing network interfaces based on configuration... node1-186: Adapter 1: nat node1-186: Adapter 2: bridged ==> node1-186: Forwarding ports... node1-186: 22 (guest) => 2222 (host) (adapter 1) ==> node1-186: Running 'pre-boot' VM customizations... ==> node1-186: Booting VM... ==> node1-186: Waiting for machine to boot. This may take a few minutes... node1-186: SSH address: 127.0.0.1:2222 node1-186: SSH username: vagrant node1-186: SSH auth method: private key ==> node1-186: Machine booted and ready! ==> node1-186: Checking for guest additions in VM... node1-186: No guest additions were detected on the base box for this VM! Guest node1-186: additions are required for forwarded ports, shared folders, host only node1-186: networking, and more. If SSH fails on this machine, please install node1-186: the guest additions and repackage the box to continue. node1-186: node1-186: This is not an error message; everything may continue to work properly, node1-186: in which case you may ignore this message. ==> node1-186: Setting hostname... ==> node1-186: Configuring and enabling network interfaces... ==> node1-186: Rsyncing folder: /nfs/k8s-node/k8s-master/ => /vagrant ==> node1-186: Machine already provisioned. Run `vagrant provision` or use the `--provision` ==> node1-186: flag to force provisioning. Provisioners marked to run always will still run.- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Machine booted and ready 代表机器起来了.

重现
在vagrant设置磁盘大小中竟然重写了此问题。
我的操作:
step 1 fdisk 分区
step 2 挂载分区
step 3 设置开启自动挂载重启失败。关键的问题在于重新做一遍就可以启动,这才是最S的操作.
继续重现
–update 2022年12月26日10:14:44
这次又重现了这个问题。这一次想趁机搞懂这个问题到底什么导致的

开debug模式vagrant up --debug &> timeout.debug- 1
网上对这个问题的讨论也有,一般认为是virtualbox的bug,建议升级virtualbox。我也照做。升级到6.1 目前最高版本。并没有解决
查看virtualbox的日志

查看官方forum
lscpu查看是开启的状态.
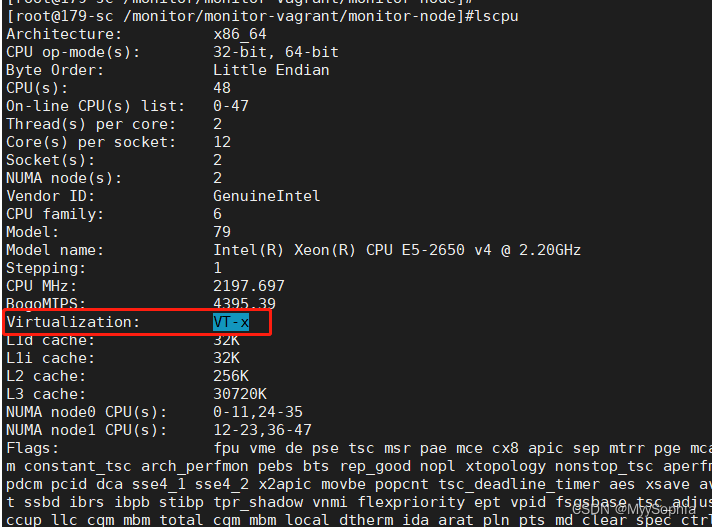
什么是VT-x?
VT-x(虚拟化扩展)是一项硬件功能,可以在计算机的中央处理器(CPU)上提供虚拟化支持。它允许在一台计算机上运行多个独立的操作系统,每个操作系统在虚拟机中运行,而不是在物理机上运行。这使得可以在同一台计算机上并行运行多个操作系统,而无需使用多台计算机。
VT-x 最初由 Intel 开发,现在已被广泛采用。它是虚拟化技术中常用的一种,其他虚拟化技术包括 AMD 的 AMD-V 和 ARM 的 Virtualization Extension(VE)。
使用 VT-x 需要满足以下条件:
-
计算机的 CPU 支持 VT-x。
-
计算机的 BIOS 或 UEFI 已启用 VT-x。
-
计算机的操作系统支持 VT-x。
如果上述条件都满足,就可以使用 VT-x 来安装和运行虚拟机。
这篇forum说是kvm可能会影响
事实上,我确实这么做了,在宿主机上安装了kvm。
问题应该就是出在这里。因为之前使用virtualbox启动虚拟机都是没有问题的。解决
1、卸载kvm相关组件
yum remove qemu-kvm qemu-img virt-manager libvirt libvirt-python virt-manager libvirt-client virt-install virt-viewer -y- 1
- 2
2、重新拉起virtualbox
vagrant up启动成功

参考
【1】vagrant up问题

【2】 vagrant up的issue官方的解释说这是第三方插件的bug.他不管这个。
-
相关阅读:
GAMES101-ASSIGNMENT7(作业7)
网络流应用(一)
如何在没有苹果电脑将 IPA 文件上传到苹果开发者中心
图像分类相关优质开源数据集汇总(附下载链接)
YAML 学习笔记
开利网络到访东家集团,沟通招商加盟数字化机制落地事项
[每日一题] 2731. 移动机器人 (思维 + 前面元素所有差值求和)
权限想要细化到按钮,怎么做?
app自动化(二)python代码操控手机终端
【老生谈算法】matlab实现Kmeans聚类算法源码——Kmeans聚类算法
- 原文地址:https://blog.csdn.net/MyySophia/article/details/127955142

