-
学习日记(XML 文件解析、检索、工厂设计模式、装饰设计模式)
学习日记(XML 文件解析、检索、工厂设计模式、装饰设计模式)
一、XML 概述
1. 概念
XML:可扩展标记语言
eXtensible Markup Language的缩写,是一种数据表示格式,可以描述非常复杂的数据结构,常用于传输和存储数据。如果把 XML 内容存为文件,那么该文件就是 XML 文件。特点:纯文本,默认使用
UTF-8编码;可嵌套。作用:用于进行存储数据和传输数据;作为配置文件用于存储系统的信息。
2. XML 的创建及语法规则
创建:创建一个 XML 类型的文件,文件的后缀名为
.xml,如:hello_world.xml。XML 的标签(元素)语法规则:
- 文档声明必须是第一行;
- 标签由一对尖括号和合法标识符组成,必须存在一个根标签,有且只能有一个;
- 标签必须成对出现,有开始,有结束,结束的标签有
/标记; - 特殊的标签可以不成对,但是必须有结束标记,如:
- 标签中可以定义属性,属性和标签名空格分开,属性值必须用引号引起来;
- 标签需要正确的嵌套;
- 定义注释信息可以用:
; - 可以存在 CDATA 区:
,其中可以写任何内容,快捷键:CD; - 如果存在特殊字符可以用以下替代。
替代 特殊字符 << 小于 >> 大于 && 和号 '‘ 单引号 "“ 引号 
右键点击文件选择
Open in Browser,用浏览器打开显示如下
3. XML 文档约束方式
文档约束:用来限定 XML 文件中的标签以及属性应该怎么写,程序员必须依照文档约束的规定来编写 XML 文件。
XML 文档约束方式分为:DTD 约束和 schema 约束。
依据文档约束来编写 XML 文档的步骤:
- 在需要编写的 XML 文件中导入 DTD 或 schema 约束文档;
- 按照约束的规定编写 XML 文件的内容。
注意:
-
DTD 约束文档后缀为
.dtd;schema 约束文档也是一个 XML 文件,后缀为.xsd。 -
DTD 不能约束具体的数据类型;schema 可以约束具体的数据类型。
二、XML 文件的解析技术
XML 文件解析:使用程序读取 XML 文件中的数据。
两种解析方式:SAX 解析和 DOM 解析(解析常用的技术框架:Dom4j)。
DOM 解析文档对象模型:
Document对象代表整个 XML 文档;Element对象代表标签(元素);Attribute对象代表属性;Text对象代表文本内容。
注意:
Element对象、Attribute对象以及Text对象都实现了Node接口,都是节点类型(最高类型)。
1. 使用 Dom4j 解析 XML 文件
首先需要在官网下载 Dom4j 框架,然后导入 jar 包。


解析的步骤:
- 导入 Dom4j 框架;
- 通过构造器创建一个 Dom4j 的解析器对象,代表整个 Dom4j 框架,如:
SAXReader saxReader = new SAXReader();; - 利用解析器对象调用
read方法把 XML 文件加载到内存中成为一个 Document 文档对象; - 通过 Document 文档对象调用
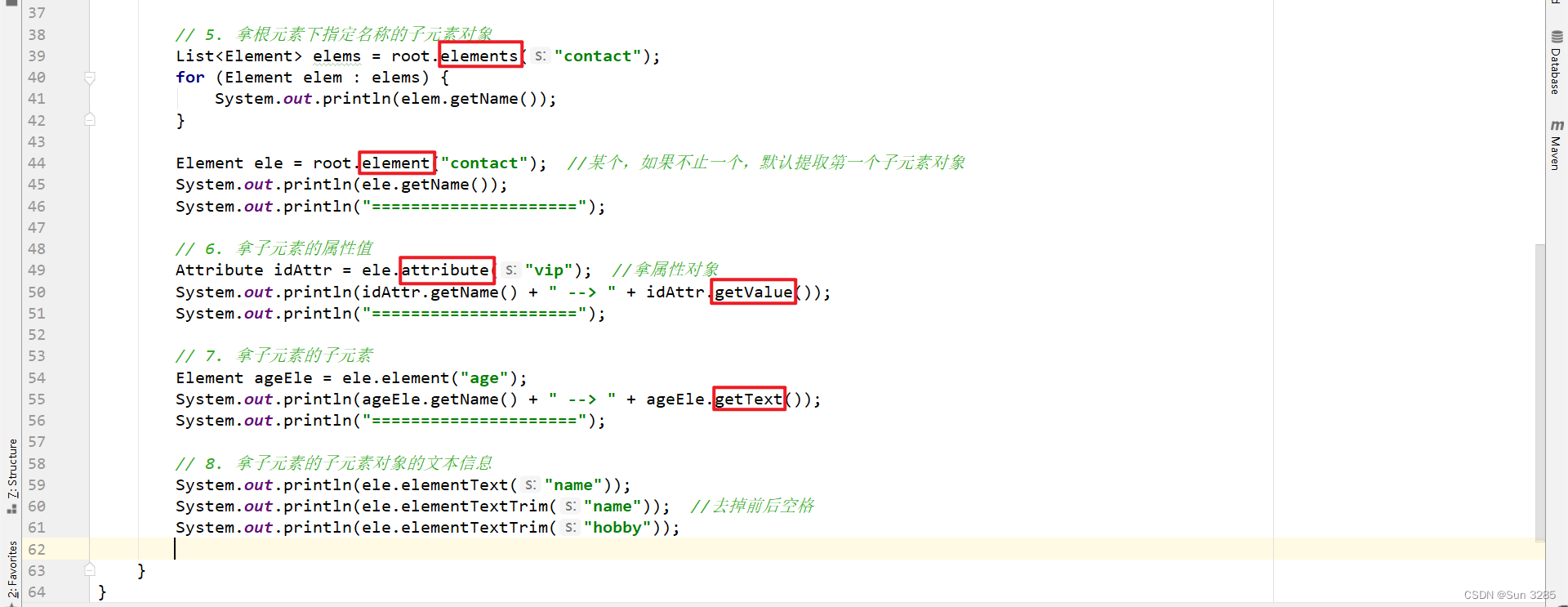
getRootElement方法来获取根元素对象; - 通过根元素对象调用以下各种方法获取子元素对象、属性对象、文本等。

方法名 说明 List elements() 得到当前元素下所有子元素对象 Element element(String var1) 得到当前元素下指定名字的子元素对象返回集合 List attributes() 得到当前元素下的所有属性对象 Attribute attribute(String var1) 得到当前元素下指定属性名的属性对象 String getText() 得到当前元素下的文本,返回值为 String 类型 String getTextTrim() 得到当前元素下的文本(去掉前后空格),返回值为 String 类型 注意:
- 在第二个方法中,若参数中指定的名字对应不止一个子元素对象,则默认提取第一个子元素对象。
- 获取到子元素对象后,可以继续调用
getName方法和getText方法获取元素的名字和文本。 - 获取到属性对象后,可以继续调用
getName方法和getValue方法获取属性的名称和对应的值。 - 获取子元素对象后可以继续调用
elements方法,进一步获取子元素的子元素对象。 - API 很灵活,用到时再去查。

解析结果

注意:
- 最好使用
Class对象调用getResourceAsStream来产生字节输入流,这样可以避免后续模块名发生改变而可能出现的错误。 getResourceAsStream方法中的/可以直接去src下寻找文件,而且必须是正斜杠。- 先获取元素对象或属性对象,然后再进行进一步操作。
2. XML 解析案例
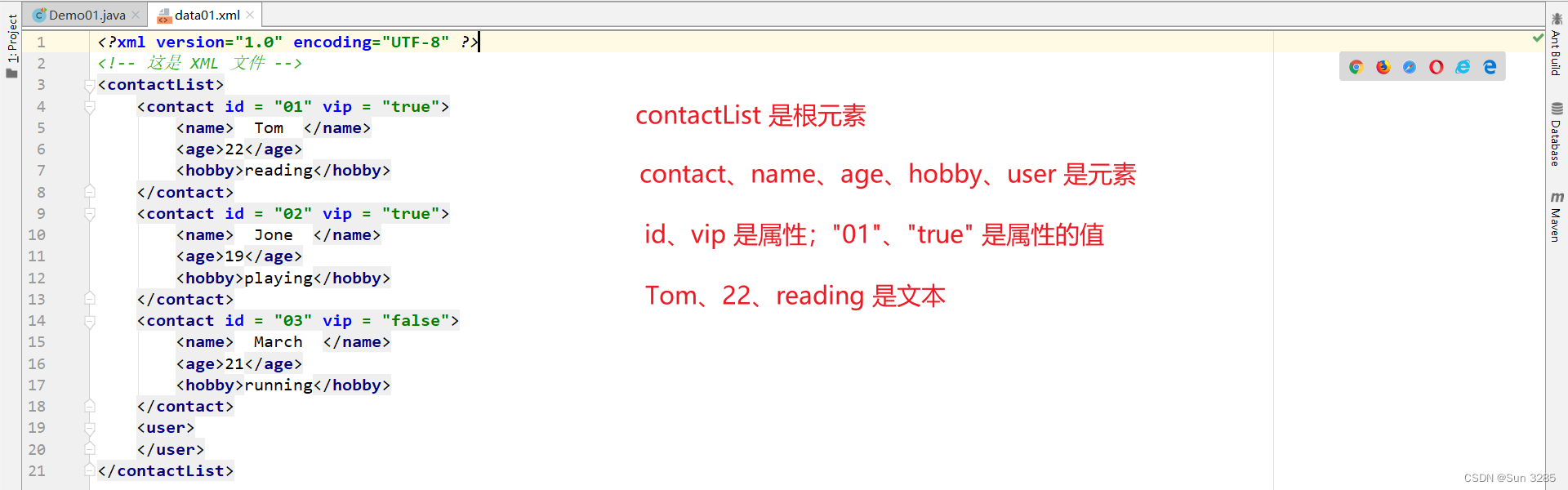
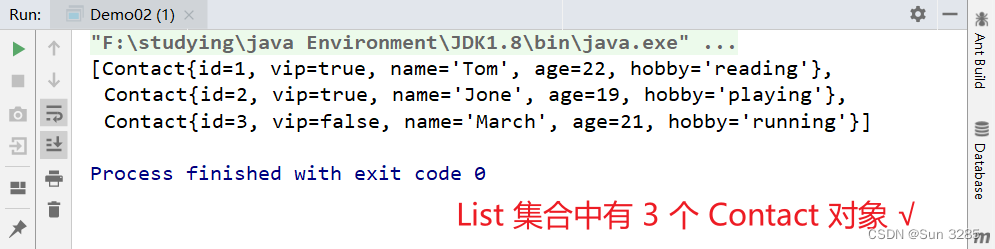
需求:将指定 XML 文件中的数据封装为 List 集合,其中每个元素是实体类
Contact。
实现


运行结果
注意:获取属性值或子元素对象文本有两种方法:先获取属性对象或子元素对象,然后调用方法;也可以直接调用以下方法获取。
方法名 说明 String attributeValue(String var1) 直接获取元素的属性值 String elementTextTrim(String var1) 直接获取该元素下子元素的文本(去掉前后空格) 
代码
package com.dom4j; import org.dom4j.Attribute; import org.dom4j.Document; import org.dom4j.Element; import org.dom4j.io.SAXReader; import java.io.InputStream; import java.util.ArrayList; import java.util.List; public class Demo02 { public static void main(String[] args) throws Exception { SAXReader saxReader = new SAXReader(); InputStream is = Demo02.class.getResourceAsStream("/XMLdata/data01.xml"); Document document = saxReader.read(is); List<Contact> list = Demo02.praseToList(document); System.out.println(list); } public static List<Contact> praseToList(Document document) { // 定义一个 list 集合用于存储 Contact 对象 List<Contact> list = new ArrayList<>(); Element root = document.getRootElement(); // 根元素的子元素 List<Element> elements = root.elements("contact"); // 遍历根元素的子元素 for (Element element : elements) { // 每有一个子元素,就创建一个 Contact 对象 Contact con = new Contact(); // 子元素的属性对象值 con.setId(Integer.valueOf(element.attributeValue("id"))); con.setVip(Boolean.valueOf(element.attributeValue("vip"))); con.setName(element.elementTextTrim("name")); con.setAge(Integer.valueOf(element.elementTextTrim("age"))); con.setHobby(element.elementTextTrim("hobby")); // // 取子元素的子元素对象 // Listelems = element.elements(); // for (Element elem : elems) { // switch (elem.getName()) { // case "name": // con.setName(elem.getTextTrim()); // break; // case "age": // con.setAge(Integer.valueOf(elem.getTextTrim())); // break; // case "hobby": // con.setHobby(elem.getTextTrim()); // break; // default: // break; // } // } list.add(con); } return list; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
三、XML 文件的数据检索技术:XPath
XPath 作用:检索 XML 文件中的信息。
XPath 使用路径表达式来定位 XML 文档中的元素节点或属性节点。
检索的步骤:
- 导入 Dom4j 框架和 XPath 的 jar 包(XPath 技术依赖于 Dom4j 技术);
- 通过构造器创建一个 Dom4j 的解析器对象,如:
SAXReader saxReader = new SAXReader();; - 利用解析器对象调用
read方法把 XML 文件加载到内存中成为一个 Document 文档对象; - 利用 XPath 提供的以下 API,结合路径表达式来完成检索 XML 文档中的元素节点或属性节点。
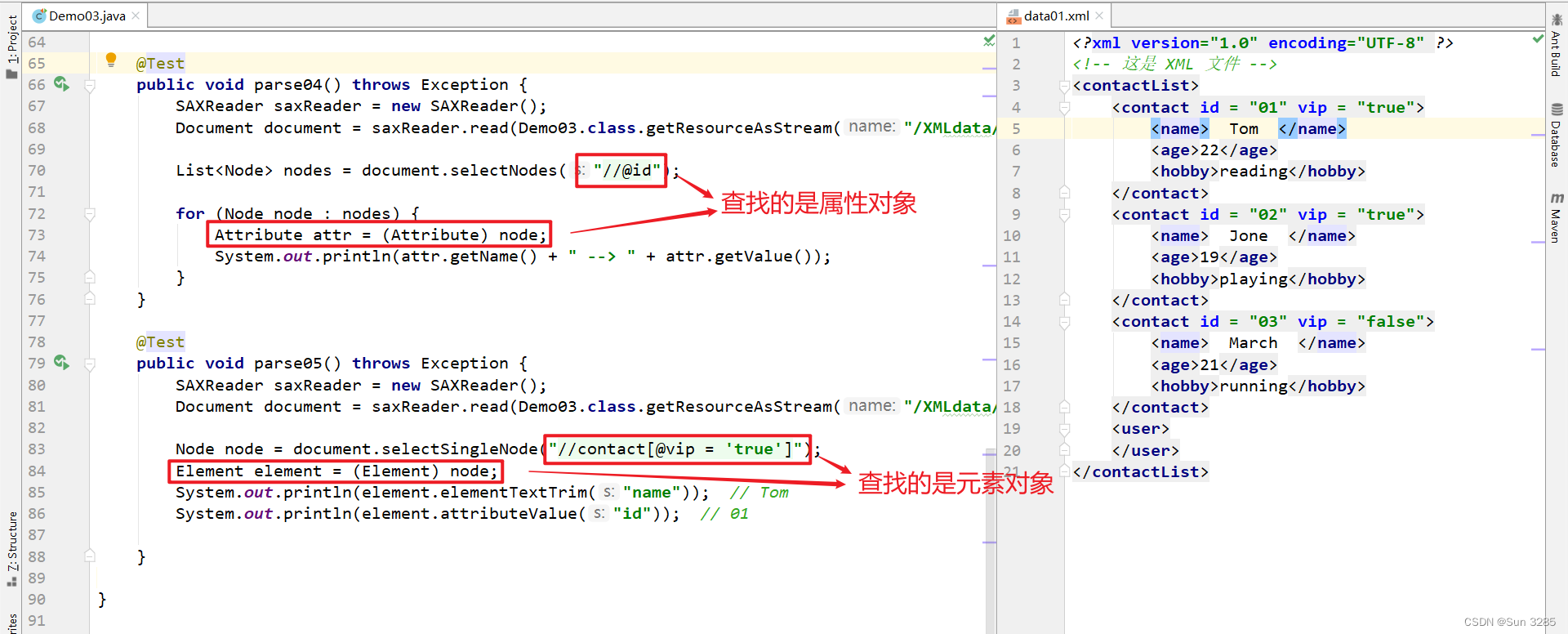
方法名 说明 Node selectSingleNode(String var1) 获取符合路径表达式的唯一元素 List selectNodes(String var1) 获取符合路径表达式的元素集合 元素查找的路径表达式 说明 /根元素/子元素/子元素绝对路径 ./子元素/子元素相对路径,其中 .表示当前元素//元素在全文搜索全部这个元素 //元素1/元素2在全文元素 1 下找一级元素 2 //元素1//元素2在全文元素 1 下找全部元素 2 注意:
/表示一级元素,//表示全部元素。根据属性查找属性对象或元素对象的路径表达式 说明 //@属性名查找所有属性对象 //元素[@属性名]查找带有指定属性名的元素对象 //元素//[@属性名 = '值']查找带有指定属性名,并且属性值相等的元素对象 注意:路径表达式都是正斜杠
/。元素查找



属性查找或元素查找

四、工厂设计模式
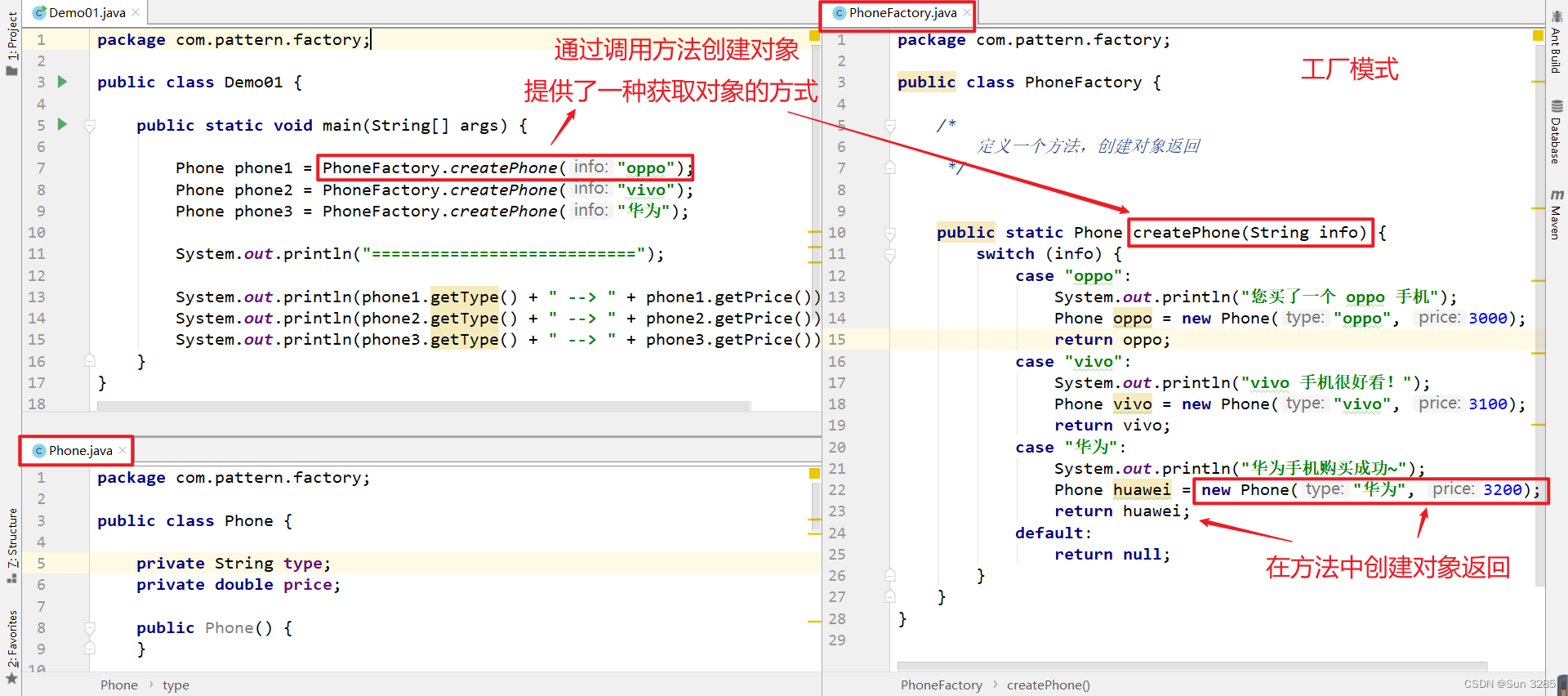
工厂设计模式:Factory Pattern 是 Java 中常用的设计模式之一,属于创建型模式,提供了一种获取对象的方式。
作用:
- 对象通过工厂的方法创建返回,工厂的方法可以为该对象进行加工和数据注入,封装了对象的创建细节。
- 可以实现类与类之间的解耦操作(核心思想)。

五、装饰设计模式
装饰设计模式:创建一个新类,包装原始类,从而在新类中提升原来类的功能。
步骤:
- 定义父类;
- 定义原始类,继承父类,定义功能;
- 定义装饰类,继承父类,包装原始类,增强功能。
作用:在不改变原类的基础上,动态地扩展一个类的功能。
如:
InputStream是抽象父类,FileInputStream是实现子类、BufferedInputStream是实现子类,是装饰类,读写性能提高。实践:模拟 IO 流。


注意:在 main 方法中,
is的实际类型为FileInputStream,所以在使用构造器创建bis对象时,传入的参数实际类型为FileInputStream,之后在装饰类调用read方法时,调用的是原始类(实现类)中的read方法(多态特点)。
注意:
- Dom4j 框架和 XPath 的 jar 包下载链接:点此下载,提取码:3285。
-
相关阅读:
『FPGA通信接口』LVDS接口(4)LVDS接收端设计
JAVA-GUI工具的编写-----事件篇
java计算机毕业设计积分权益商城MyBatis+系统+LW文档+源码+调试部署
java毕业设计选题二手车汽车车辆管理系统项目[包运行成功]
centos8 安装 时序数据库 TimescaleDB
[附源码]计算机毕业设计游戏商城平台论文Springboot程序
前端-(6)
docker命令大全
Android逆向工程【黑客帝国】
Redis服务器安装和配置远程访问
- 原文地址:https://blog.csdn.net/taiyang3285/article/details/127954159
