-
C语言常用基础知识总结
1.sizeof
sizeof 返回参数所占用的字节数
- int arr[10];
- sizeof(arr)/sizeof(*arr)表示数组的大小。
数组名arr就是一个常量指针,指向第一个元素
*arr 指向第一个元素
sizeof(arr) 返回arr数组占用的总的字节数
sizeof(*arr)返回第一个元素所占用的字节数
总字节数/每个元素占用的字节数 = 元素个数一般情况下sizeof是在编译的时候求值,所以sizeof(i++)并不会引起什么坏的后果。
根据上面的表述,那么定义一个int * p;sizeof(p)=?,实际是等于4,上面的arr难道不是一个指针吗?为什么大小是arr数组占用的总的字节数.
sizeof(数组名):返回数组所有元素占有的内存空间字节数。
sizeof(指针) :返回计算机系统的地址字节数,如果是32位系统,返回4,16位系统返回2。
很多人认为数组名就是指向数组首地址的一个指针,但其实这个说法是错误的!
首先我们要知道,单纯的数组名,不是指针
数组名是一个标识符,它标识出我们之前申请的一连串内存空间,而且这个空间内的元素类型是相同的——即数组名代表的是一个内存块及这个内存块中的元素类型 。
只是在大多数情况下数组名会“退化”(C标准使用的decay和converted这两个词)为指向第一个元素的指针。
2.int *p=NULL 和int *p ;p=NULL 和*p = NULL 这三个的区别
第一种是定义一个int型指针,并给它初始化为NULL,也就是个空指针,没有指向任何地方,就是个空的。
第二种是定义一个int型指针,然后给指针赋值为NULL,指针指向NULL地址。
第三种是给指针的值赋值为NULL,也就是给指针指向的内容赋值为0(也就是为空)。int* p=NULL,
定义一个指针,其指向的内存保存的是int型的数据,同时p的值为0X00000000(即完成一次初始化);
其中,p是一个指针变量,p中内存地址处的内存是p指向的内存。
3.sizeof(),length(),strlen()
strlen()函数:strlen()用来计算指定的字符串s 的长度,不包括结束字符"\0"。
strlen不计算 \0之后的数据。
4.生成随机数
- #include<stdlib.h>
- #include<time.h>
- srand((unsigned int)time(NULL));
- int ret4 = rand() % (n - m + 1) + m;//生成m~n的随机数
5.uint8_t uint16_t
Uint8 Uint16等的区别_偏安一隅,占山为王的博客-CSDN博客_uint8和uint16的区别
6.两个8位转16
2个8位数据high、low合成一个16位数据s:
s = (short) (high << 8) | low; //java short是两个字节一个16位数据s拆分成2个8位数据high、low:
- high = (s >> 8) & 0xff; //高8位
- low = s & 0xff; //低8位
7.什么是指针
内存的编号叫做地址,这个地址我们就称为指针。对于32位的机器,假设有32根地址线,那么假设每根地址线在寻址的时候产生高电平(高电压)和低电平,也就是有2^32 编号,说明可以管理2的32次方个单元。每个地址标识一个字节,那我们就可以给
(2^32Byte == 2^32/1024KB == 2^32 /1024/1024MB==2^32/1024/1024/1024GB == 4GB) 4G的空闲进行编址。1、在32位的机器上,地址是32个0或者1组成二进制序列,那地址就得用4个字节的空间来存储,所 以一个指针变量的大小就应该是4个字节。
2、在64位机器上,如果有64个地址线,那一个指针变量的大小是8个字节,才能存放一个地址指针的大小在32位平台是4个字节,在64位平台是8个字节。
指针类型的作用:
指针类型决定了指针解引用操作的时候,一次访问几个字节(访问内存的大小)
指针类型决定了,指针±整数的时候的步长(指针±整数的时候,跳过几个字节)
野指针的产生及避免:
指针没有初始化,里面放的是随机值。
指针越界造成野指针问题
当一个指针指向的空间释放了,这个指针就变成野指针了
- 指针初始化
- 小心指针越界
- 指针指向空间释放即使置NULL
- 避免返回局部变量的地址
- 指针使用之前检查有效性
8. 函数指针和指针函数,指针数组和数组指针的区别
指针函数:简单的来说,就是一个返回指针的函数,其本质是一个函数,而该函数的返回值是一个指针。
int *fun(int x,int y);函数指针:其本质是一个指针变量,该指针指向这个函数。总结来说,函数指针就是指向函数的指针。
函数指针是需要把一个函数的地址赋值给它,有两种写法:
- fun = &Function;
- fun = Function;
取地址运算符&不是必需的,因为一个函数标识符就表示了它的地址,如果是函数调用,还必须包含一个圆括号括起来的参数表。
调用函数指针的方式也有两种:
- x = (*fun)();
- x = fun();
- int add(int x,int y){
- return x+y;
- }
- //函数指针
- int (*fun)(int x,int y);
- fun = add;
- fun(1,2)
指针数组:指针数组可以说成是”指针的数组”,首先这个变量是一个数组,其次,”指针”修饰这个数组,意思是说这个数组的所有元素都是指针类型,在32位系统中,指针占四个字节。
- char *arr[4] = {"hello", "world", "shannxi", "xian"};
- //arr就是我定义的一个指针数组,它有四个元素,每个元素是一个char *类型的指针,这些指针存放着其对应字符串的首地址。
数组指针:数组指针可以说成是”数组的指针”,首先这个变量是一个指针,其次,”数组”修饰这个指针,意思是说这个指针存放着一个数组的首地址,或者说这个指针指向一个数组的首地址。
根据上面的解释,可以了解到指针数组和数组指针的区别,因为二者根本就是种类型的变量。
char (*pa)[4];如果指针数组和数组指针这俩个变量名称一样就会是这样:char *pa[4]和char (*pa)[4],原来指针数组和数组指针的形成的根本原因就是运算符的优先级问题,所以定义变量是一定要注意这个问题,否则定义变量会有根本性差别!
pa是一个指针指向一个char [4]的数组,每个数组元素是一个char类型的变量,所以我们不妨可以写成:char[4] (*pa);这样就可以直观的看出pa的指向的类型,不过在编辑器中不要这么写,因为编译器根本不认识,这样写只是帮助我们理解。
既然pa是一个指针,存放一个数组的地址,那么在我们定义一个数组时,数组名称就是这个数组的首地址
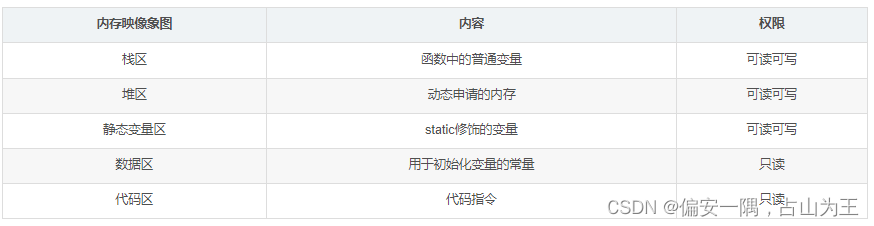
一般情况下,从栈区到代码区,是从高地址到低地址。栈向下增长,堆向上增长
9. 0 nullptr NULL的区别
10. static extern
11.函数参数传递
形参是一个副本传递,若要修改形参的值那么请用一级指针,若要修改形参一级指针的值那么用二级指针,以此类推。
- void GetChipModelInfo(uint32_t **chip_info)
- {
- *chip_info = (uint32_t*)0x40002028;
- }
- void GetUuid_Info(uint32_t **uuid_info)
- {
- *uuid_info = (uint32_t*)0x4000202C;
- }
- uint32_t *p;
- GetChipModelInfo(&p);
- printf("%08x\n",*p);
- uint32_t *uuid_info;
- GetUuid_Info(&uuid_info);
- //uint32_t *uuid_info = (uint32_t*)0x4000202C;
- printf("%08x %08x %08x %08x\n",*uuid_info,*(uuid_info+1),*(uuid_info+2),*(uuid_info+3));
//uint32_t read_buffer[1];
//read_buffer[0] = 0x12345678;
//0x12放在高地址
//printf("%08x",read_buffer); -
相关阅读:
码蹄集 - MT3203 - 填坑:骗数据过的~_~
Few-shot Learning for Trajectory-based Mobile Game Cheating Detection
如何开发物联网 APP?
MySQL数据库——日志管理、备份与恢复
juc
传递datetime数据类型至前端 时分秒消失
中国芯片金字塔成形,商业化拐点将至
Shell脚本简明教程
React 如何添加路由懒加载
Hive CLI和Beeline命令行的基本使用
- 原文地址:https://blog.csdn.net/qq_42475191/article/details/127948974
