-
数学杂谈:限制条件下的均匀分布考察
1. 问题描述
假设 x 1 , . . . , x n x_1, ..., x_n x1,...,xn均为 0 ∼ 1 0 \sim 1 0∼1上的均匀分布,且满足限制条件:
x 1 + x 2 + . . . + x n = 1 x_1 + x_2 + ... + x_n = 1 x1+x2+...+xn=1
求此时 x i x_i xi的真实分布表达式。
2. 问题解答
1. 答案
限制条件下 x x x的密度函数表达式如下:
f n ( x ) = ( n − 1 ) ⋅ ( 1 − x ) n − 2 f_n(x) = (n-1) \cdot (1-x)^{n-2} fn(x)=(n−1)⋅(1−x)n−2
2. 解析
我们可以快速地给出推导公式为:
f n ( x ) = ∫ 0 1 − x d t 1 ∫ 0 1 − x − t 1 d t 2 . . . ∫ 0 1 − x − t 1 − . . . − t n − 3 d t n − 2 ∫ 0 1 d t 1 ∫ 0 1 − t 1 d t 2 . . . ∫ 0 1 − t 1 − . . . − t n − 2 d t n − 1 f_n(x) = \frac{\int_{0}^{1-x}dt_1 \int_{0}^{1-x-t_1}dt_2 ... \int_{0}^{1-x-t_1-...-t_{n-3}}dt_{n-2}}{\int_{0}^{1}dt_1 \int_{0}^{1-t_1}dt_2 ... \int_{0}^{1-t_1-...-t_{n-2}}dt_{n-1}} fn(x)=∫01dt1∫01−t1dt2...∫01−t1−...−tn−2dtn−1∫01−xdt1∫01−x−t1dt2...∫01−x−t1−...−tn−3dtn−2
令
g n ( x ) = ∫ 0 1 − x d t 1 ∫ 0 1 − x − t 1 d t 2 . . . ∫ 0 1 − x − t 1 − . . . − t n − 1 d t n g_n(x) = \int_{0}^{1-x}dt_1 \int_{0}^{1-x-t_1}dt_2 ... \int_{0}^{1-x-t_1-...-t_{n-1}}dt_{n} gn(x)=∫01−xdt1∫01−x−t1dt2...∫01−x−t1−...−tn−1dtn
则我们有:
f n ( x ) = g n − 2 ( x ) / g n − 1 ( 0 ) f_n(x) = g_{n-2}(x) / g_{n-1}(0) fn(x)=gn−2(x)/gn−1(0)
而 g n ( x ) g_{n}(x) gn(x)我们可以通过递归关系 g n ( x ) = ∫ 0 1 − x g n − 1 ( 1 − x − t 1 ) d t 1 g_n(x) = \int_{0}^{1-x} g_{n-1}(1-x-t_1) dt_1 gn(x)=∫01−xgn−1(1−x−t1)dt1快速计算得到:
g n ( x ) = 1 n ! ( 1 − x ) n g_n(x) = \frac{1}{n!}(1-x)^{n} gn(x)=n!1(1−x)n
因此,我们即可解得:
f n ( x ) = ( n − 1 ) ⋅ ( 1 − x ) n − 2 f_n(x) = (n-1) \cdot (1-x)^{n-2} fn(x)=(n−1)⋅(1−x)n−2
特别地,积分即可快速得到,某一个元素要取值得到至少 τ \tau τ的概率为: P ( x ≥ τ ) = ( 1 − τ ) n − 1 P(x \geq \tau) = (1-\tau)^{n-1} P(x≥τ)=(1−τ)n−1。
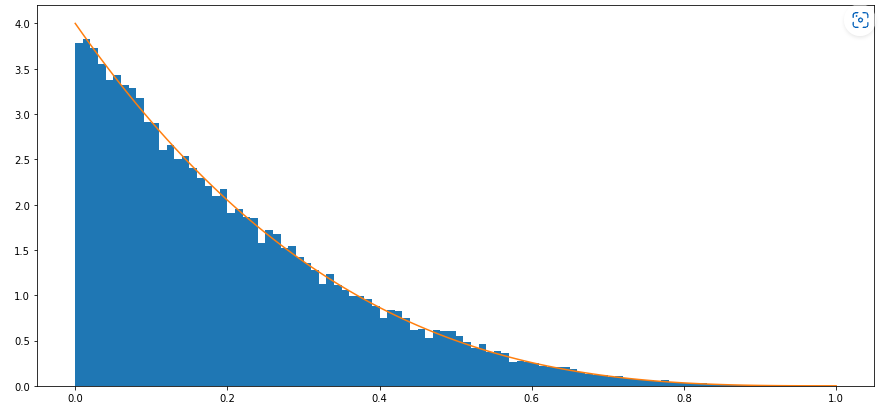
3. 蒙特卡洛模拟
如果我们要对上述结论进行验证,我们可以使用蒙特卡洛模拟来对上述结论进行验证。
我们直接给出代码如下:
import numpy as np from random import random from matplotlib import pyplot as plt def monte_carlo_simulate(n=5, N=10000): s = [] for _ in range(N): while True: tmp = [random() for _ in range(n-1)] if sum(tmp) <= 1: s.append(1 - sum(tmp)) break return s def show_simulate(n=5, N=10000): x = np.linspace(0, 1, num=100) y = (n-1) * np.pow(1-x, n-2) s = monte_carlo_simulate(n=n, N=N) plt.figure(figsize=(15, 7)) plt.hist(s, bins=100, range=[0, 1], density=True) plt.plot(x, y) plt.show() return show_simulate(n=5, N=10000)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
可以看到:
进一步的,如果我们要快速地获取符合 x x x分布的随机数,也只需要做如下构造即可:
import math from random import random def random(k=5): x = random() z = 1 - math.pow(z, 1/(k-1)) return z- 1
- 2
- 3
- 4
- 5
- 6
- 7
3. 离散情况延拓
下面,我们稍微拓展一下,如果 x x x不连续,是离散的情况下,那么结果如何。
我们修改问题为:
假设我们有 k k k个均匀分布的离散项,取值范围为 0 ∼ N 0 \sim N 0∼N,且满足限制条件 x 1 + x 2 + . . . x k = N x_1 + x_2 + ... x_k = N x1+x2+...xk=N,那么其中 x 1 x_1 x1不小于 M M M的概率是多少。
这个问题其实感觉比上述连续的情况还要简单一些,我们只需要将其视为排列组合问题即可进行解答,即视为分堆问题,将 N N N个元素分到 k k k个堆当中,令其中某一个堆中的元素个数不少于 M M M。
1. 正整数的情况
首先,我们来考察一下最简单的情况,即要求每个堆中至少有一个元素,且 N , M N,M N,M均为有限整数。
此时,我们要做的事实上就是在 N N N个元素所构成的 N − 1 N-1 N−1个间隔位置当中放入 k − 1 k-1 k−1个挡板。不妨设要求的堆就是第一个堆,即第一个堆的元素个数不少于 M M M个,此时,符合要求的摆放方式必然要求第一个挡板的出现位置必须要在第 M M M个间隔或者之后。
因此,我们可以得到答案为:
P ( x 1 ≥ M ) = C N − M k − 1 C N − 1 k − 1 P(x_1 \geq M) = \frac{C_{N-M}^{k-1}}{C_{N-1}^{k-1}} P(x1≥M)=CN−1k−1CN−Mk−1
2. 整数的情况
对于整数的情况,其结果本质上是与之前正数的情况完全相同的,唯一的区别在于,挡板可以相邻,因此,我们事实上就是将 N N N个元素与 k − 1 k-1 k−1个挡板合在一起进行排列组合。
同样的,我们要求第一个堆当中至少包含 M M M个元素,此时我们可以仿上求得答案为:
P ( x 1 ≥ M ) = C N − M + k − 1 k − 1 C N + k − 1 k − 1 P(x_1 \geq M) = \frac{C^{k-1}_{N-M+k-1}}{C^{k-1}_{N+k-1}} P(x1≥M)=CN+k−1k−1CN−M+k−1k−1
3. N → ∞ N \to \infty N→∞的情况
最后,我们考察一下 N → ∞ N \to \infty N→∞的情况,令 N → ∞ N \to \infty N→∞,且有 l i m N → ∞ M N = τ \mathop{lim}\limits_{N\to \infty} \frac{M}{N} = \tau N→∞limNM=τ。
此时,上述两个式子的解收敛为:
l i m N → ∞ P ( x 1 ≥ M ) = ( 1 − τ ) k − 1 \mathop{lim}\limits_{N\to \infty} P(x_1 \geq M) = (1-\tau)^{k-1} N→∞limP(x1≥M)=(1−τ)k−1
此结果就是之前讨论的连续情况下的解。
4. 误区分析
这里,其实有一个坑要注意一下,就是如果你在模拟的时候这么写作函数:
def simulate(n=5, N=10000): s = [] for _ in range(N): t = 1.0 for _ in range(n-1): t -= t * random() s.append(t) return s- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
此时,采样得到的 n n n个点事实上也满足 ∑ i = 1 n x i = 1 \sum\limits_{i=1}^{n} x_i = 1 i=1∑nxi=1,但是如果我们将 x i x_i xi的分布画出来的话,可以注意到, x i x_i xi的分布与 i i i的取值有关,且 i i i越大,采样得到的 x i x_i xi的均值越小。
我们以 n = 5 n=5 n=5为例,可以绘制得到曲线如下:
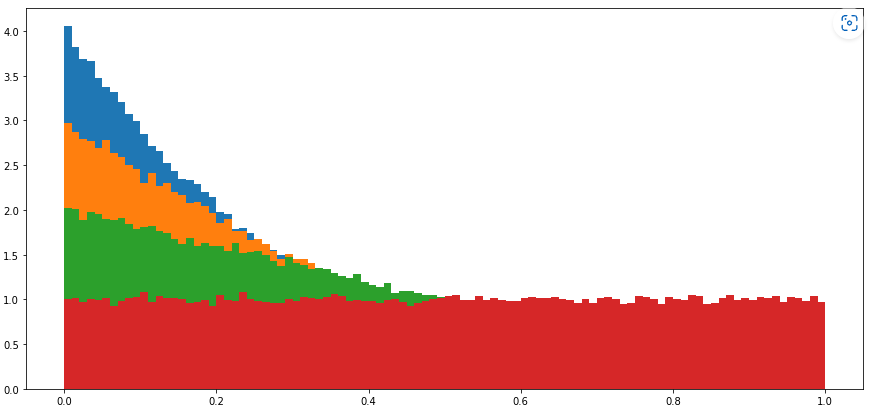
这乍看有点迷糊,其实仔细想想的话你会注意到这里的 x i x_i xi的取值概率是与开始的题目描述不一致的,原本要求的概率应该是:
P ( x i = x ∣ ∑ i = 1 n x i = 1 ) P(x_i=x | \sum\limits_{i=1}^{n}x_i=1) P(xi=x∣i=1∑nxi=1)
而这里模拟的概率事实上是:
P ( x i = x ∣ ∑ j = 1 i − 1 x j ≤ 1 − x ) P(x_i=x | \sum\limits_{j=1}^{i-1}x_j \leq 1-x) P(xi=x∣j=1∑i−1xj≤1−x)
因此就会出现两种模拟的结果不一致的情况。
而同样的,如果有读者感兴趣的话,后者事实上我们也可以很轻松地求出其概率密度函数为:
f n ( x i = x ) = g i − 1 ( x ) g i ( 0 ) = i × ( 1 − x ) i − 1 f_{n}(x_i = x) = \frac{g_{i-1}(x)}{g_i(0)} = i \times(1-x)^{i-1} fn(xi=x)=gi(0)gi−1(x)=i×(1−x)i−1
需要注意的是,这里的 i < n i < n i<n,当 i = n i = n i=n时,此时其分布与 i = n − 1 i=n-1 i=n−1时相同,多多少少有那么一点点特殊。
-
相关阅读:
oracle报错,XML节点值超过varchar(4000)截取方法。ORA-06502,ORA-06512,ORA-01706
浅析 Redisson 的分布式延时队列 RedissonDelayedQueue 运行流程
C语言操作符大全(建议收藏)
行情分析——加密货币市场大盘走势(11.15)
【python学习】基础篇-常用函数-sorted() 对可迭代对象进行排序
反转链表(力扣)
网络技术十三:DNS(域名服务器)
好用的云笔记具备哪些特点,这3款云笔记亲测好用
手写一个 Redis LruCache 缓存机制
AutoSAR入门到精通讲解 (AuroSAR-CP描述) 1.1 AutoSAR-CP简介
- 原文地址:https://blog.csdn.net/codename_cys/article/details/127953949
