-
处理csv、bmp等常用数据分析操作--python
请先看思维导图,看是否包含你所需要的东西,如果没有,就可以划走了,免得浪费时间,谢谢

条条大路通罗马,我只是介绍了我掌握的这一条,不喜勿喷,谢谢。
目录
五、综合应用(可直接运行)
一、创建文件夹(多层)
1、创建多层文件夹(包含子文件夹)
- import os
- # 新建多层文件夹
- def mkdir(path):
- if not os.path.exists(path): # 判断是否存在此路径
- os.makedirs(path) # 创建此路径
- print("完成新建")
- # 主函数
- if __name__ == "__main__":
- root_path = os.getcwd() # 获取此py文件的路径
- print(root_path)
- new_folder_path = os.path.join(root_path, "new_folder", "1") # os.path.join的作用,相当于给root_path, "new_folder", "1"添加"\\"
- mkdir(new_folder_path)
运行结果:
- "E:\study software\python3.7\python.exe" D:/test/new_folder.py
- D:\test
- 完成新建
- Process finished with exit code 0
新建多层文件夹效果:

2、查找多层文件夹中内容
在上述新建文件夹中,手动新建一个空的txt文件。

查找到多层文件夹中的txt文件:
- import os
- # 主函数
- if __name__ == "__main__":
- root_path = os.getcwd() # 获取此py文件的路径
- for root, dirs, files in os.walk(root_path): # os.walk类似于二叉树查找
- for file in files: # 判断是否找到最小单位文件,files是文件名列表
- if ".txt" in file:
- print(file)
- print("找到txt文件")
- print(root) # txt文件的文件夹路径
运行结果:
- "E:\study software\python3.7\python.exe" D:/test/find_txt.py
- test.txt
- 找到txt文件
- D:\test\new_folder\1
- Process finished with exit code 0
二、读写CSV
1、写csv文件
利用numpy新建矩阵数据,并保存至csv中。
- import csv
- import numpy as np
- import random # 生成随机数的库
- import os
- # 将data写入对应路径的csv中
- def write_csv(data, csvpath):
- with open(csvpath, "w", newline="") as f:
- writer = csv.writer(f)
- writer.writerows(data)
- f.close()
- print("完成data保存为csv")
- # 主函数
- if __name__ == "__main__":
- root_path = os.getcwd()
- data1 = np.ones([100, 30]) # 构成100*30的矩阵
- # 数据中叠加噪声
- for i in range(100):
- for j in range(30):
- data1[i, j] += random.randint(1, 254)
- csvpath1 = os.path.join(root_path, "test.csv") # csv保存的路径
- write_csv(data1, csvpath1)
运行后上述代码后,得到以下test.csv。

2、读csv文件
- import numpy as np
- import pandas as pd
- row_num = 100
- col_num = 30
- # 读取csv内容至baseData
- def read_csv(csvpath):
- baseData = pd.read_csv(open(csvpath), header=None, encoding="gdk") # 此读取方式,可以读取包含中文路径的csv文件
- baseData = np.array(baseData.values)
- baseData = baseData[:row_num, :col_num]
- return baseData
- # 主函数
- if __name__ == "__main__":
- csvpath = r"\\?\D:\test\test.csv" # csv存放的路径,加上"\\?\",可以突破python路径长度的限制,方便读取更深层路径下文件
- data = read_csv(csvpath)
- print(data)
运行结果:
- "E:\study software\python3.7\python.exe" D:/test/read_csv.py
- [[ 5. 236. 129. ... 72. 166. 201.]
- [ 12. 12. 147. ... 212. 57. 85.]
- [ 16. 114. 194. ... 105. 117. 200.]
- ...
- [ 96. 25. 251. ... 201. 16. 85.]
- [169. 206. 113. ... 55. 67. 87.]
- [225. 236. 188. ... 205. 173. 155.]]
- Process finished with exit code 0
三、读写bmp图
1、读取csv,保存为bmp图
- import numpy as np
- import pandas as pd
- from PIL import Image # 这个库全称是Pillow
- row_num = 100
- col_num = 30
- # 读取csv内容至baseData
- def read_csv(csvpath):
- baseData = pd.read_csv(open(csvpath), header=None, encoding="gdk") # 此读取方式,可以读取包含中文路径的csv文件
- baseData = np.array(baseData.values)
- baseData = baseData[:row_num, :col_num]
- return baseData
- # 将矩阵数据保存为bmp灰度图
- def write_bmp(data, bmppath):
- data1 = np.array(data, dtype="uint8") # 转换为无符号8bit,0~255,灰度图
- data1 = Image.fromarray(data1)
- # 第一个参数为存储地址和名称,第二个为存储的图片类型
- data1.save(bmppath, "bmp")
- # 主函数
- if __name__ == "__main__":
- csvpath = r"\\?\D:\test\test.csv" # csv存放的路径,加上"\\?\",可以突破python路径长度的限制,方便读取更深层路径下文件
- data = read_csv(csvpath)
- bmp_path = r"\\?\D:\test\test.bmp" # bmp存储的路径及名称
- write_bmp(data, bmp_path)
存储的图片,如下所示:(噪点图)

2、读取bmp图
- import numpy as np
- from PIL import Image
- # 读取csv内容至baseData
- def read_bmp(bmp_path):
- pic = open(bmp_path, "rb") # 以这种方式读bmp,方便读了之后关闭文件
- image = Image.open(pic)
- image_data = np.array(image)
- data1 = image_data.astype("int16")
- pic.close()
- return data1
- # 主函数
- if __name__ == "__main__":
- bmp_path = r"\\?\D:\test\test.bmp" # bmp的路径及名称
- data = read_bmp(bmp_path)
- print(data)
运行结果:
- "E:\study software\python3.7\python.exe" D:/test/read_bmp.py
- [[ 5 236 129 ... 72 166 201]
- [ 12 12 147 ... 212 57 85]
- [ 16 114 194 ... 105 117 200]
- ...
- [ 96 25 251 ... 201 16 85]
- [169 206 113 ... 55 67 87]
- [225 236 188 ... 205 173 155]]
- Process finished with exit code 0
四、excel中插入数据及图片
1、先读取csv数据,然后保存为图片,excel中插入数据std结果,及保存的图片,具体代码如下所示:
- import numpy as np
- import pandas as pd
- from PIL import Image
- import xlsxwriter
- import os
- row_num = 100
- col_num = 30
- # 读取csv内容至baseData
- def read_csv(csvpath):
- baseData = pd.read_csv(open(csvpath), header=None, encoding="gdk") # 此读取方式,可以读取包含中文路径的csv文件
- baseData = np.array(baseData.values)
- baseData = baseData[:row_num, :col_num]
- return baseData
- # 将矩阵数据保存为bmp灰度图
- def write_bmp(data, bmppath):
- data1 = np.array(data, dtype="uint8") # 转换为无符号8bit,0~255,灰度图
- data1 = Image.fromarray(data1)
- # 第一个参数为存储地址和名称,第二个为存储的图片类型
- data1.save(bmppath, "bmp")
- # 主函数
- if __name__ == "__main__":
- csvpath = r"\\?\D:\test\test.csv" # csv存放的路径,加上"\\?\",可以突破python路径长度的限制,方便读取更深层路径下文件
- data = read_csv(csvpath)
- bmp_path = r"\\?\D:\test\test.bmp" # bmp存储的路径及名称
- write_bmp(data, bmp_path)
- # excel操作相关
- root_path = os.getcwd() # 获取当前py文件路径
- book = xlsxwriter.Workbook(os.path.join(root_path, "test.xlsx")) # 指定excel存放位置
- sheet = book.add_worksheet("test_data") # 新建一页sheet,方便后续操作
- headings = ["file_name", "data_std", "pic"] # 表头信息
- sheet.write_row("A1", headings) # 从A1开始写表头信息
- # 计算数据列std均值
- std_count = np.zeros([1, col_num]) # 用于存放每列std值
- for i in range(col_num):
- std_count[0, i] = np.std(data[:, i])
- std_mean = int(np.mean(std_count)) # 将最终结果转成整形
- sheet.write_number(1, 1, std_mean) # 第1行,第一列写std_mean,之前的A1相当于是第(0,0)位置
- file_name = csvpath.split("\\")[-1] # 字符串按照"\\"符号进行分割,[-1]表示取分割后最后一个字符串
- sheet.write_string(1, 0, file_name)
- # excel插入图片
- sheet.insert_image(1, 2, bmp_path) # excel的sheet页,第1行、第3列插入bmp_path路径下图片
- book.close() # 关闭excel
2、运行之后,得到excel如下所示:
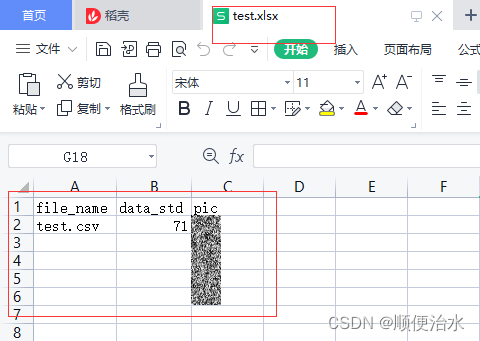
五、综合应用
1、完整代码如下:(可直接运行)
注:需提前安装好库:numpy、pandas、Pillow、xlsxwriter
- # 需提前安装好库:numpy、pandas、Pillow、xlsxwriter
- import numpy as np
- import pandas as pd
- from PIL import Image
- import xlsxwriter
- import os
- import time
- import random
- import csv
- # 定义每帧数据大小
- row_num = 100
- col_num = 30
- # 新建多层文件夹
- def mkdir(path):
- if not os.path.exists(path): # 判断是否存在此路径
- os.makedirs(path) # 创建此路径
- print("完成新建")
- # 读取csv内容至baseData
- def read_csv(csvpath):
- baseData = pd.read_csv(open(csvpath), header=None, encoding="gdk") # 此读取方式,可以读取包含中文路径的csv文件
- baseData = np.array(baseData.values)
- baseData = baseData[:row_num, :col_num]
- return baseData
- # 将data写入对应路径的csv中
- def write_csv(data, csvpath):
- with open(csvpath, "w", newline="") as f:
- writer = csv.writer(f)
- writer.writerows(data)
- f.close()
- print("完成data保存为csv")
- # 将矩阵数据保存为bmp灰度图
- def write_bmp(data, bmppath):
- data1 = np.array(data, dtype="uint8") # 转换为无符号8bit,0~255,灰度图
- data1 = Image.fromarray(data1)
- # 第一个参数为存储地址和名称,第二个为存储的图片类型
- data1.save(bmppath, "bmp")
- # 读取csv内容至baseData
- def read_bmp(bmp_path):
- pic = open(bmp_path, "rb") # 以这种方式读bmp,方便读了之后关闭文件
- image = Image.open(pic)
- image_data = np.array(image)
- data1 = image_data.astype("int16")
- pic.close()
- return data1
- # 主函数
- if __name__ == "__main__":
- current_time = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) # 获取当前时间并以指定格式显示
- root_path = os.getcwd() # 获取py文件路径
- # excel相关信息
- book = xlsxwriter.Workbook(os.path.join(root_path, "test.xlsx")) # 指定excel存放位置
- sheet = book.add_worksheet("test_data") # 新建一页sheet,方便后续操作
- headings = ["file_name", "data_std", "pic"] # 表头信息
- sheet.write_row("A1", headings) # 从A1开始写表头信息
- count_row = 0 # 计算excel行数
- # 1、新建csv数据
- save_csv = os.path.join(root_path, "test_folder", "save_csv", current_time)
- mkdir(save_csv) # 创建多层文件夹
- for k in range(20): # 得到20帧噪声数据 100*30
- data1 = np.ones([100, 30]) # 构成100*30的矩阵
- # 数据中叠加噪声
- for i in range(100):
- for j in range(30):
- data1[i, j] += random.randint(1, 254)
- print("test"+str(k)+".csv")
- csvpath1 = os.path.join(save_csv, "test"+str(k)+".csv") # csv保存的路径
- write_csv(data1, csvpath1)
- # 2、从文件夹中获取csv文件,并绘图
- for root, dirs, files in os.walk(root_path):
- for file in files:
- if ".csv" not in file:
- continue
- else:
- csv_path = os.path.join(root, file)
- data = read_csv(csv_path)
- bmp_path = csv_path.replace(".csv", ".bmp") # 替换后缀,得到bmp保存路径
- write_bmp(data, bmp_path) # 保存图片
- # 计算数据列std均值
- std_count = np.zeros([1, col_num]) # 用于存放每列std值
- for i in range(col_num):
- std_count[0, i] = np.std(data[:, i])
- std_mean = int(np.mean(std_count)) # 将最终结果转成整形
- # 3、插入统计数据及图片至excel中
- count_row += 1
- sheet.write_number((count_row-1)*6+1, 1, std_mean) # 第1行,第一列写std_mean,之前的A1相当于是第(0,0)位置
- file_name = csv_path.split("\\")[-1] # 字符串按照"\\"符号进行分割,[-1]表示取分割后最后一个字符串
- sheet.write_string((count_row-1)*6+1, 0, file_name) # (count_row-1)*5 调整excel行间隔
- # excel插入图片
- sheet.insert_image((count_row-1)*6+1, 2, bmp_path) # excel的sheet页,第1行、第3列插入bmp_path路径下图片
- book.close() # 关闭excel
2、运行生成excel,效果如下所示:
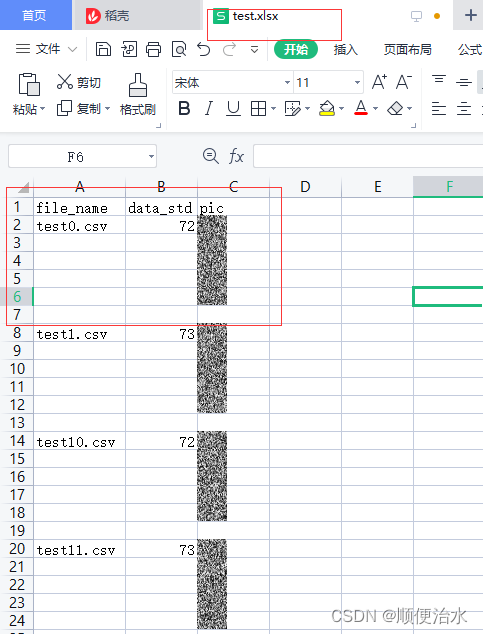
-
相关阅读:
【寒枫顾辞老航小说传】第一回:梦回大唐
【论文精读】Diffusion Transformer(DiT)
异步编程概览
C#的基本知识(1)
【CentOS7】vsftpd学习笔记
盒子模型——边框,以及便捷写法和边框合并
CTFSHOW七夕杯web
数据治理-定义数据治理运营框架
阿里、腾讯、百度大厂的程序员编程指南规范
SQL(Structured Query Language)简介和常见 SQL 命令示例
- 原文地址:https://blog.csdn.net/qq_38984928/article/details/127948439
