-
Rust WASM 与 JS 计算素数性能对比
前言
刚接触Rust wasm,请各看官高抬贵手。
简介
根据网上资料,使用
wasm-pack搭配wasm-bindgen将Rust代码编译成 wasm。
搭好环境后,想对比一下rust-wasm与js的性能差距。- 环境
- OS: Deepin 20.7.1 apricot
- Kernel: Linux 5.15.34
- CPU: Intel Core m3-7Y30 @ 4x 2.6GHz
- RAM: 4GB
- 浏览器: Microsoft Edge 版本 107.0.1418.35 (正式版本) (64 位)
- Rust 依赖
- rustc 1.60.0
- wasm-bindgen: 0.2
方案:计算素数
Rust 函数
#[wasm_bindgen] pub fn cpu_calc(count: i32) { let mut result = 1; // 计算多少数字下 for i in 2..count { let num: f64 = i as f64; let after_sqrt = num.sqrt() as i32 + 1; let mut flag = true; for j in 2..after_sqrt { let dividing = i % j; if dividing == 0 { flag = false; break; } } if flag { result = i; } } // 调用浏览器控制台打印 console_log(&format!("rust 素数:{}", result)); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
JS 函数
function cpuCalc(num) { let result = 0; for (let i = 2; i < num; i++) { let flag = true; for (let j = 2; j < Math.sqrt(i); j++) { if (i % j === 0) { flag = false; break; } } if (flag) { result = i; } } console.log('js素数:', result); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
之后通过js分别调用这两个方法,进行1,000,0000 (100w) 以内的质数计算。并打印最大的质数。
结果
多刷新页面几次,等耗时看起来基本稳定。
先运行wasm方法,再执行js方法。

先执行js方法,再执行wasm方法。
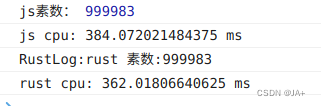
计算素数小结
计算性能和js基本差不多。
而调用wasm 的时候也是同步的代码。
看来js对于处理的cpu计算任务性能还是可以的。
但是总觉得应该wasm更快一点的。那wasm在什么场景下比js具有优势呢,这个还需要继续深入。
方案2:计算斐波那契数列
计算斐波那契数列可使用递归的方式或while循环的方式。循环40次。
下面对两种情况做讨论递归实现
Rust 函数
fn fib_rec(num: i16) -> i64 { if num < 2 { return 1; // rust 中值要return } fib_rec(num - 1) + fib_rec(num - 2) } #[wasm_bindgen] pub fn fib_recursion(time: i16) -> i64 { let mut result = 0; let mut i = 1; while i < time { result = fib_rec(i); i += 1; } result }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
JS函数
function fibRec(num) { if (num < 2) return 1; return fibRec(num - 1) + fibRec(num - 2); } function fibRecursion(time) { let i = 1; let result = 0; while (i < time) { result = fibRec(i++); } return result; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
结果
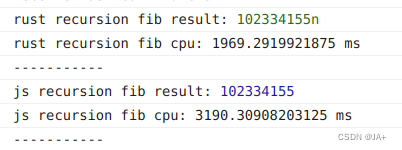
wasm代码2s左右,js3s左右,数据量多的情况下。while循环实现
Rust函数
#[wasm_bindgen] pub fn fib(num: i32) -> i64 { let mut result = 0; for i in 1..num { let mut num1 = 1; let mut num2 = 1; let mut j = 1; while j < i { j += 1; let temp = num2; num2 = num2 + num1; num1 = temp; result = num2; } } result }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
JS函数
function fib(num) { let result = 0; for (let i = 1; i < num; i++) { let num1 = 1; let num2 = 1; let j = 1; while (j < i) { j += 1; let temp = num2; num2 = num1 + num2; num1 = temp; result = num2; } } return result; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
结果
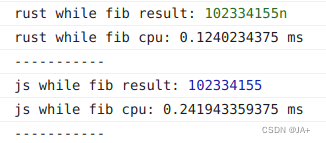
可见直接使用while循环比递归方式速度快不少。
运行速度上rust-wasm 更胜一筹计算斐波那契数列小结
rust-wasm 速度更快。
普通加法计算
JS
let num = 0; for(let i = 0;i<10_000_000;i++){ num += i; } console.log('js add', num);- 1
- 2
- 3
- 4
- 5
Rust
#[wasm_bindgen] pub fn add_range(a:i32,b:i32) -> i64 { let mut sum =0; for i in a..b { sum += i as i64; } sum }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
JS调用wasm
console.log('rust add',add_range(0,10_000_000));- 1
结果
0 - 10,000
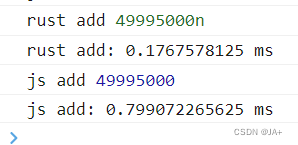
0 - 1千万
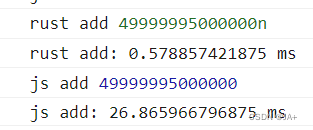
0 - 10亿
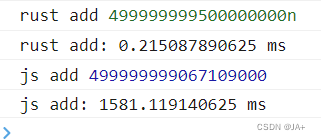
数据越大差距越明显。神奇的是wasm性能始终在0.几毫秒。
怕是被rust优化成等差求和了?小结
计算素数时,性能相近。
计算斐波那契数列时,Rust 性能更好。
为什么计算素数性能相近,而计算斐波那契数列rust较快。值得研究。 - 环境
-
相关阅读:
dubbo泛化调用之消费者传递JavaBean
成都睿趣科技:现在开一家抖音小店还来得及吗
【云原生 二】 Docker架构演进过程
主流商业智能(BI)工具的比较(一):Tableau与Domo
mac无法读取移动硬盘怎么办?mac怎么使用ntfs硬盘
使用LangChain构建问答聊天机器人案例实战(三)
34_ue4进阶末日生存游戏开发[初步拾取功能]
O2O产业怎么使用科技虚拟员工保证数据的及时性
Vue中使用pdf.js实现在线预览pdf文件流
【Numpy总结】第七节:Numpy常用的函数(汇总所有函数,收藏这一篇就OK啦~)
- 原文地址:https://blog.csdn.net/qq_35459724/article/details/127949237
