-
tensorflow2 SqueezeNet
前面学习了通过加深网络和加宽网络来改进模型质量,提高模型精度的深度学习backbone模型(LeNet,VGGNet,AlexNet,GoogleNet,ResNet),这里介绍如何使网络更快,结构更轻量化的改进深度神经网络模型之一————SqueezeNet,它能够在ImageNet数据集上达到AlexNet近似的效果,但是参数比AlexNet少50倍。
SqueezeNet 的主要思想如下:- 多用 1x1 的卷积核,而少用 3x3 的卷积核。因为 1x1 的好处是可以在保持 feature map size 的同时减少 channel,使模型参数减少为原来的1/9
- 在用 3x3 卷积的时候尽量减少 channel 的数量,从而减少参数量。
- 延后用 pooling,因为 pooling 会减小 feature map size,延后用 pooling, 这样可以使 size 到后面才减小,而前面的层可以保持一个较大的 size,更大的size保留了更多的信息,可以提高分类准确率,缺点是会增加网络的计算量。
基于上面的思想, 研究人员提出了 fire module,其结构如下:
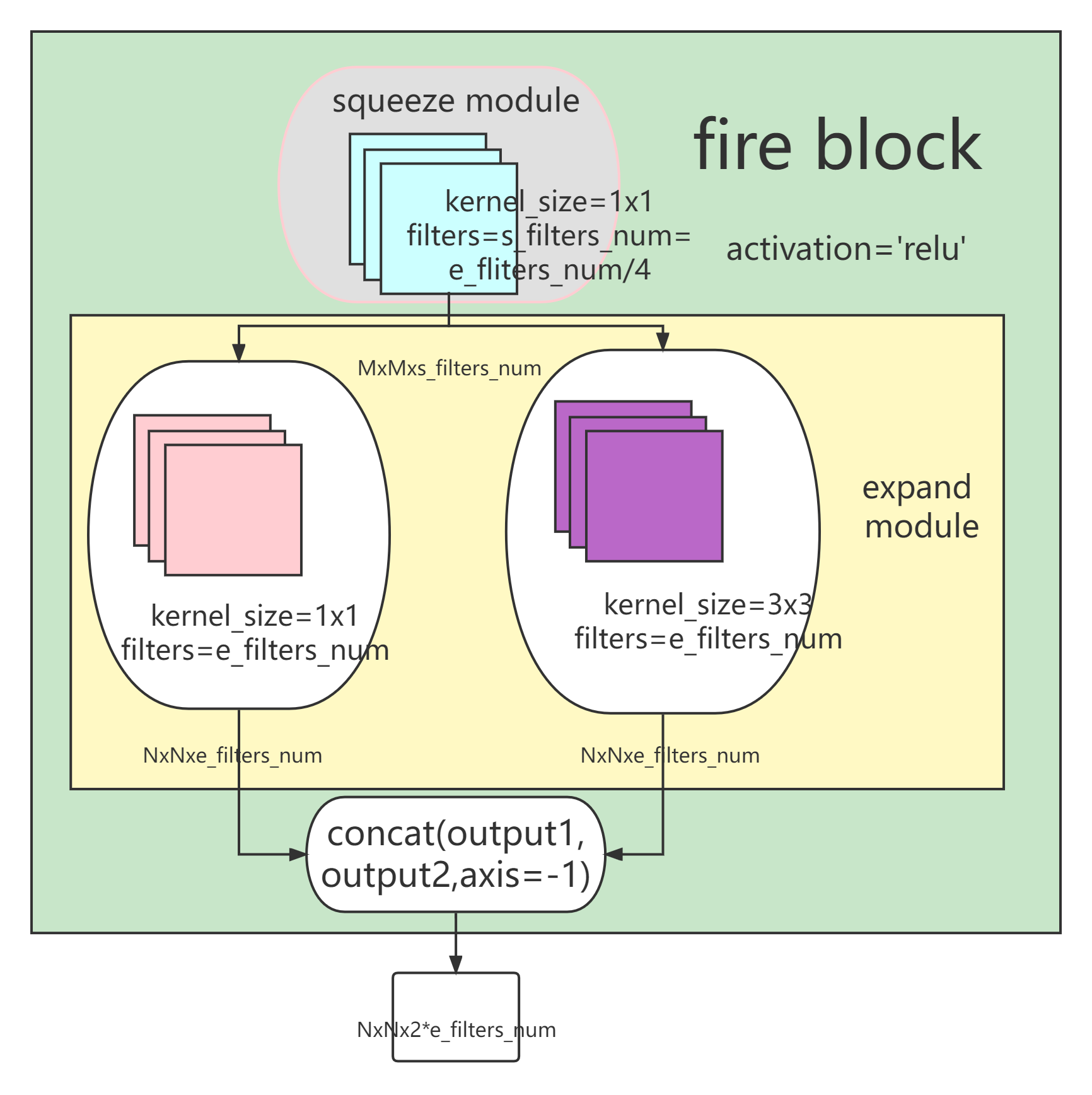
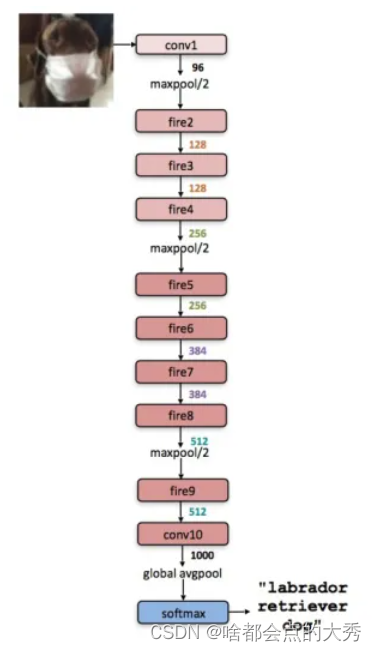
SqueezeNet模型结构采用如下结构:
import tensorflow as tf import os from tensorflow.keras.layers import * from tensorflow.keras import Model import numpy as np class FireBlock(Model): def __init__(self,s_filters_num,e_filters_num): super().__init__() self.squeeze=Conv2D(filters=s_filters_num,kernel_size=1,padding='same',activation='relu') self.expand_1=Conv2D(filters=e_filters_num,kernel_size=1,padding='same',activation='relu') self.expand_3=Conv2D(filters=e_filters_num,kernel_size=3,padding='same',activation='relu') def call(self,x): x=self.squeeze(x) x1=self.expand_1(x) x2=self.expand_3(x) y=tf.concat([x1,x2],-1) return y class SqueezeNet(Model): def __init__(self): super().__init__() self.c1=Conv2D(filters=96,kernel_size=7,padding='same',strides=2,activation='relu') self.p1=MaxPooling2D(pool_size=(3,3),strides=2) self.f1=FireBlock(16,64) self.f2=FireBlock(16,64) self.f3=FireBlock(32,128) self.p2=MaxPooling2D(pool_size=(3,3),strides=2) self.f4=FireBlock(32,128) self.f5=FireBlock(48,192) self.f6=FireBlock(48,192) self.f7=FireBlock(64,256) self.p3=MaxPooling2D(pool_size=(3,3),strides=2) self.f8=FireBlock(64,256) self.c4=Conv2D(filters=1000,kernel_size=1,padding='same',activation='relu') self.p4=GlobalAveragePooling2D() def call(self,x): x=self.c1(x) x=self.p1(x) x=self.f1(x) x=self.f2(x) x=self.f3(x) x=self.p2(x) x=self.f4(x) x=self.f5(x) x=self.f6(x) x=self.f7(x) x=self.p3(x) x=self.f8(x) x=self.c4(x) y=self.p4(x) return y model=SqueezeNet()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
上面为基于tensorflow2.4封装好的SqueezeNet,通过加载数据集,模型编译(model.compile())后就行训练模型了,我的笔记本电脑显卡不行,我只试运行了一下,可以训练数据。
参考:
SqueezeNet详解
SqueezeNet详细解读
深度学习中的经典基础网络结构(backbone)总结 -
相关阅读:
数据结构 - 数组 - 青岛大学(王卓)
11个程序员必备简捷开发辅助工具
几个Web自动化测试框架的比较:Cypress、Selenium和Playwright
Spring 学习(五)——JavaConfig 实现配置
SAP 财务月结之 外币评估(TCODE:FAGL_FC_VAL,S4版本用 FAGL_FCV)<转载>
后悔没有早点遇到你——我亲爱的无货源
POSTGIS数据库操作
扬帆牧哲:跨境电商还有未来吗?
五分钟k8s实战-使用Ingress
设计模式——模板方法模式
- 原文地址:https://blog.csdn.net/Big_SHOe/article/details/127944253
