-
Dubbo基础
目录
为什么 Dubbo 不用 JDK 的 SPI,而是要自己实现?
注意:本文参考 Dubbo系列-扬帆起航
1w+字的 Dubbo 面试题/知识点总结!(2021 最新版)
什么是 RPC
RPC,Remote Procedure Call 即远程过程调用,远程过程调用其实对标的是本地过程调用,本地过程调用你熟悉吧?
想想那青葱岁月,你在大学赶着期末大作业,正在攻克图书管理系统,你奋笔疾书疯狂地敲击键盘,实现了图书借阅、图书归还等等模块,你实现的一个个方法之间的调用就叫本地过程调用。
你要是和我说你实现图书馆里系统已经用了服务化,搞了远程调用了,我只能和你说你有点东西。
简单的说本机上内部的方法调用都可以称为本地过程调用,而远程过程调用实际上就指的是你本地调用了远程机子上的某个方法,这就是远程过程调用。
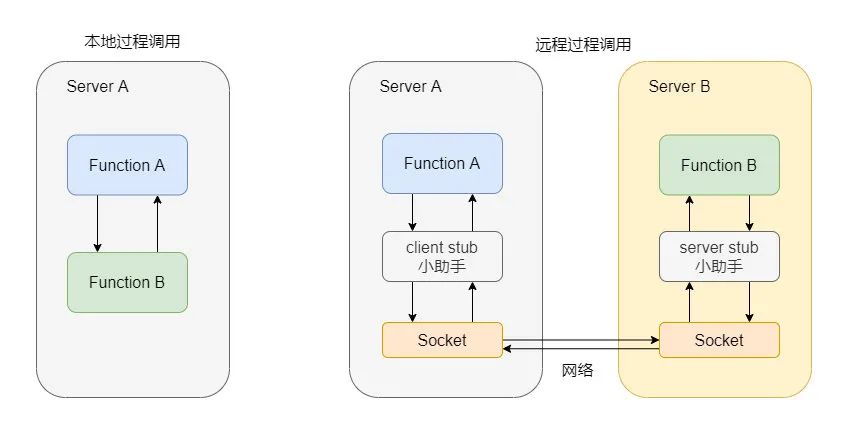
所以说 RPC 对标的是本地过程调用,至于 RPC 要如何调用远程的方法可以走 HTTP、也可以是基于 TCP 自定义协议。
所以说你讨论 RPC 和 HTTP 就不是一个层级的东西。
而 RPC 框架就是要实现像那小助手一样的东西,目的就是让我们使用远程调用像本地调用一样简单方便,并且解决一些远程调用会发生的一些问题,使用户用的无感知、舒心、放心、顺心,它好我也好,快乐没烦恼。
那为什么要有 RPC,HTTP 不好么?
这时候面试官就开始追问了。
这个问题其实很有意思,有些面试官可能自己不太清楚,然后以为自己很清楚,所以问出这个问题,还有一种是真的清楚,问这个问题是为了让你跳坑里。
因为 RPC 和 HTTP 就不是一个层级的东西,所以严格意义上这两个没有可比性,也不应该来作比较,而题目问的就是把这两个作为比较了。
HTTP 只是传输协议,协议只是规范了一定的交流格式,而且 RPC 是早于 HTTP 的,所以真要问也是问有 RPC 为什么还要 HTTP。
RPC 对比的是本地过程调用,是用来作为分布式系统之间的通信,它可以用 HTTP 来传输,也可以基于 TCP 自定义协议传输。
所以你要先提出这两个不是一个层级的东西,没有可比性,然后再表现一下,可以说 HTTP 协议比较冗余,所以 RPC 大多都是基于 TCP 自定义协议,定制化的才是最适合自己的。
当然也有基于 HTTP 协议的 RPC 框架,毕竟 HTTP 是公开的协议,比较通用,像 HTTP2 已经做了相应的压缩了,而且系统之间的调用都在内网,所以说影响也不会很大。
RPC 的原理是什么?
为了能够帮助小伙伴们理解 RPC 原理,我们可以将整个 RPC 的 核心功能看作是下面 👇 6 个部分实现的:
1 客户端(服务消费端) :调用远程方法的一端。
2 客户端 Stub(桩) :这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
3 网络传输 :网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket 或者性能以及封装更加优秀的 Netty(推荐)。
4 服务端 Stub(桩) :这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去指定对应的方法然后返回结果给客户端的类。
5 服务端(服务提供端) :提供远程方法的一端。
具体原理图如下,后面我会串起来将整个 RPC 的过程给大家说一下。
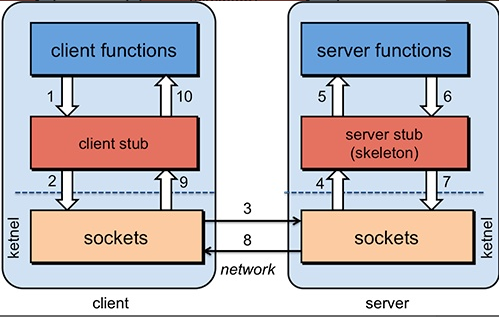
1 服务消费端(client)以本地调用的方式调用远程服务;
2 客户端 Stub(client stub) 接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体(序列化):
RpcRequest;3 客户端 Stub(client stub) 找到远程服务的地址,并将消息发送到服务提供端;
4 服务端 Stub(桩)收到消息将消息反序列化为 Java 对象:
RpcRequest;5 服务端 Stub(桩)根据
RpcRequest中的类、方法、方法参数等信息调用本地的方法;6 服务端 Stub(桩)得到方法执行结果并将组装成能够进行网络传输的消息体:
RpcResponse(序列化)发送至消费方;7 客户端 Stub(client stub)接收到消息并将消息反序列化为 Java 对象:
RpcResponse,这样也就得到了最终结果。over!如何设计一个 RPC 框架
在明确了什么是 RPC,以及 RPC 框架的目的之后,咱们想想如果让你做一款 RPC 框架你该如何设计?
从底向上的思路
首先需要实现高性能的网络传输,可以采用 Netty 来实现,不用自己重复造轮子,然后需要自定义协议,毕竟远程交互都需要遵循一定的协议,然后还需要定义好序列化协议,网络的传输毕竟都是二进制流传输的。
然后可以搞一套描述服务的语言,即 IDL(Interface description language),让所有的服务都用 IDL 定义,再由框架转换为特定编程语言的接口,这样就能跨语言了。
此时最近基本的功能已经有了,但是只是最基础的,工业级的话首先得易用,所以框架需要把上述的细节对使用者进行屏蔽,让他们感觉不到本地调用和远程调用的区别,所以需要代理实现。
然后还需要实现集群功能,因此的要服务发现、注册等功能,所以需要注册中心,当然细节还是需要屏蔽的。
最后还需要一个完善的监控机制,埋点上报调用情况等等,便于运维。
服务消费者
我们先从消费者方(也就是调用方)来看需要些什么,首先消费者面向接口编程,所以需要得知有哪些接口可以调用,可以通过公用 jar 包的方式来维护接口。
现在知道有哪些接口可以调用了,但是只有接口啊,具体的实现怎么来?这事必须框架给处理了!所以还需要来个代理类,让消费者只管调,啥事都别管了,我代理帮你搞定。
对了,还需要告诉代理,你调用的是哪个方法,并且参数的值是什么。
虽说代理帮你搞定但是代理也需要知道它到底要调哪个机子上的远程方法,所以需要有个注册中心,这样调用方从注册中心可以知晓可以调用哪些服务提供方,一般而言提供方不止一个,毕竟只有一个挂了那不就没了。
所以提供方一般都是集群部署,那调用方需要通过负载均衡来选择一个调用,可以通过某些策略例如同机房优先调用啊啥的。
当然还需要有容错机制,毕竟这是远程调用,网络是不可靠的,所以可能需要重试什么的。
还要和服务提供方约定一个协议,例如我们就用 HTTP 来通信就好啦,也就是大家要讲一样的话,不然可能听不懂了。
当然序列化必不可少,毕竟我们本地的结构是“立体”的,需要序列化之后才能传输,因此还需要约定序列化格式。
并且这过程中间可能还需要掺入一些 Filter,来作一波统一的处理,例如调用计数啊等等。
这些都是框架需要做的,让消费者像在调用本地方法一样,无感知。
服务提供者
服务提供者肯定要实现对应的接口这是毋庸置疑的。
然后需要把自己的接口暴露出去,向注册中心注册自己,暴露自己所能提供的服务。
然后有消费者请求过来需要处理,提供者需要用和消费者协商好的协议来处理这个请求,然后做反序列化。
序列化完的请求应该扔到线程池里面做处理,某个线程接受到这个请求之后找到对应的实现调用,然后再将结果原路返回。
注册中心
上面其实我们都提到了注册中心,这东西就相当于一个平台,大家在上面暴露自己的服务,也在上面得知自己能调用哪些服务。
当然还能做配置中心,将配置集中化处理,动态变更通知订阅者。
监控运维
面对众多的服务,精细化的监控和方便的运维必不可少。
这点很多开发者在开发的时候察觉不到,到你真正上线开始运行维护的时候,如果没有良好的监控措施,快速的运维手段,到时候就是睁眼瞎!手足无措,等着挨批把!
那种痛苦不要问我为什么知道,我就是知道!
小结一下
让我们小结一下,大致上一个 RPC 框架需要做的就是约定要通信协议,序列化的格式、一些容错机制、负载均衡策略、监控运维和一个注册中心!
简单实现一个 RPC 框架
没错就是简单的实现,上面我们在思考如何设计一个 RPC 框架的时候想了很多,那算是生产环境使用级别的功能需求了,我们这是 Demo,目的是突出 RPC框架重点功能 - 实现远程调用。
所以啥七七八八的都没,并且我用伪代码来展示,其实也就是删除了一些保护性和约束性的代码,因为看起来太多了不太直观,需要一堆 try-catch 啥的,因此我删减了一些,直击重点。
Let's Do It!
首先我们定义一个接口和一个简单实现。
- public interface AobingService {
- String hello(String name);
- }
- public class AobingServiceImpl implements AobingService {
- public String hello(String name) {
- return "Yo man Hello,I am" + name;
- }
- }
然后我们再来实现服务提供者暴露服务的功能。
- public class AobingRpcFramework {
- public static void export(Object service, int port) throws Exception {
- ServerSocket server = new ServerSocket(port);
- while(true) {
- Socket socket = server.accept();
- new Thread(new Runnable() {
- //反序列化
- ObjectInputStream input = new ObjectInputStream(socket.getInputStream());
- String methodName = input.read(); //读取方法名
- Class<?>[] parameterTypes = (Class<?>[]) input.readObject(); //参数类型
- Object[] arguments = (Object[]) input.readObject(); //参数
- Method method = service.getClass().getMethod(methodName, parameterTypes); //找到方法
- Object result = method.invoke(service, arguments); //调用方法
- // 返回结果
- ObjectOutputStream output = new ObjectOutputStream(socket.getOutputStream());
- output.writeObject(result);
- }).start();
- }
- }
- public static <T> T refer (Class<T> interfaceClass, String host, int port) throws Exception {
- return (T) Proxy.newProxyInstance(interfaceClass.getClassLoader(), new Class<?>[] {interfaceClass},
- new InvocationHandler() {
- public Object invoke(Object proxy, Method method, Object[] arguments) throws Throwable {
- Socket socket = new Socket(host, port); //指定 provider 的 ip 和端口
- ObjectOutputStream output = new ObjectOutputStream(socket.getOutputStream());
- output.write(method.getName()); //传方法名
- output.writeObject(method.getParameterTypes()); //传参数类型
- output.writeObject(arguments); //传参数值
- ObjectInputStream input = new ObjectInputStream(socket.getInputStream());
- Object result = input.readObject(); //读取结果
- return result;
- }
- });
- }
- }
好了,这个 RPC 框架就这样好了,是不是很简单?就是调用者传递了方法名、参数类型和参数值,提供者接收到这样参数之后调用对于的方法返回结果就好了!这就是远程过程调用。
我们来看看如何使用
- //服务提供者只需要暴露出接口
- AobingService service = new AobingServiceImpl ();
- AobingRpcFramework.export(service, 2333);
- //服务调用者只需要设置依赖
- AobingService service = AobingRpcFramework.refer(AobingService.class, "127.0.0.1", 2333);
- service.hello();
看起来好像好不错哟,不过这很是简陋,用作 demo 有助理解还是极好的!
接下来就来看看 Dubbo 吧!上正菜!
Dubbo 简介
Dubbo的历史
Dubbo 是阿里巴巴 2011年开源的一个基于 Java 的 RPC 框架,中间沉寂了一段时间,不过其他一些企业还在用 Dubbo 并自己做了扩展,比如当当网的 Dubbox,还有网易考拉的 Dubbok。
但是在 2017 年阿里巴巴又重启了对 Dubbo 维护。在 2017 年荣获了开源中国 2017 最受欢迎的中国开源软件 Top 3。
在 2018 年和 Dubbox 进行了合并,并且进入 Apache 孵化器,在 2019 年毕业正式成为 Apache 顶级项目。
目前 Dubbo 社区主力维护的是 2.6.x 和 2.7.x 两大版本,2.6.x 版本主要是 bug 修复和少量功能增强为准,是稳定版本。
而 2.7.x 是主要开发版本,更新和新增新的 feature 和优化,并且 2.7.5 版本的发布被 Dubbo 认为是里程碑式的版本发布,之后我们再做分析。
它实现了面向接口的代理 RPC 调用,并且可以配合 ZooKeeper 等组件实现服务注册和发现功能,并且拥有负载均衡、容错机制等。
最新的 3.0 版本往云原生方向上探索着。
Dubbo的功能
根据 Dubbo 官方文档的介绍,Dubbo 提供了六大核心能力
1 面向接口代理的高性能 RPC 调用。
2 智能容错和负载均衡。
3 服务自动注册和发现。
4 高度可扩展能力。
5 运行期流量调度。
6 可视化的服务治理与运维。
简单来说就是:Dubbo 不光可以帮助我们调用远程服务,还提供了一些其他开箱即用的功能比如智能负载均衡。
为什么要用 Dubbo?
随着互联网的发展,网站的规模越来越大,用户数量越来越多。单一应用架构 、垂直应用架构无法满足我们的需求,这个时候分布式服务架构就诞生了。
分布式服务架构下,系统被拆分成不同的服务比如短信服务、安全服务,每个服务独立提供系统的某个核心服务。
我们可以使用 Java RMI(Java Remote Method Invocation)、Hessian 这种支持远程调用的框架来简单地暴露和引用远程服务。但是!当服务越来越多之后,服务调用关系越来越复杂。当应用访问压力越来越大后,负载均衡以及服务监控的需求也迫在眉睫。我们可以用 F5 这类硬件来做负载均衡,但这样增加了成本,并且存在单点故障的风险。
不过,Dubbo 的出现让上述问题得到了解决。Dubbo 帮助我们解决了什么问题呢?
负载均衡 :同一个服务部署在不同的机器时该调用那一台机器上的服务。
服务调用链路生成 :随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
服务访问压力以及时长统计、资源调度和治理 :基于访问压力实时管理集群容量,提高集群利用率。
另外,Dubbo 除了能够应用在分布式系统中,也可以应用在现在比较火的微服务系统中。不过,由于 Spring Cloud 在微服务中应用更加广泛,所以,我觉得一般我们提 Dubbo 的话,大部分是分布式系统的情况。
Dubbo 总体架构
我们先来看下官网的一张图。
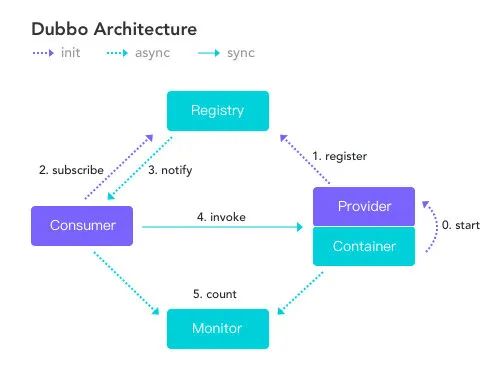
本丙再暖心的给上图内每个节点的角色说明一下。
节点 角色说明 Consumer 需要调用远程服务的服务消费方 Registry 注册中心 Provider 服务提供方 Container 服务运行的容器 Monitor 监控中心 我再来大致说一下整体的流程,首先服务提供者 Provider 启动然后向注册中心注册自己所能提供的服务。
服务消费者 Consumer 启动向注册中心订阅自己所需的服务。然后注册中心将提供者元信息通知给 Consumer, 之后 Consumer 因为已经从注册中心获取提供者的地址,因此可以通过负载均衡选择一个 Provider 直接调用 。
之后服务提供方元数据变更的话注册中心会把变更推送给服务消费者。
服务提供者和消费者都会在内存中记录着调用的次数和时间,然后定时的发送统计数据到监控中心。
架构的一些注意点
首先注册中心和监控中心是可选的,你可以不要监控,也不要注册中心,直接在配置文件里面写然后提供方和消费方直连。
然后注册中心、提供方和消费方之间都是长连接,和监控方不是长连接,并且消费方是直接调用提供方,不经过注册中心。
就算注册中心和监控中心宕机了也不会影响到已经正常运行的提供者和消费者,因为消费者有本地缓存提供者的信息。
注册中心的作用了解么?
注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互。
服务提供者宕机后,注册中心会做什么?
注册中心会立即推送事件通知消费者。
监控中心的作用呢?
监控中心负责统计各服务调用次数,调用时间等。
注册中心和监控中心都宕机的话,服务都会挂掉吗?
不会。两者都宕机也不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表。注册中心和监控中心都是可选的,服务消费者可以直连服务提供者。
Dubbo 中的 Invoker 概念了解么?
Invoker是 Dubbo 领域模型中非常重要的一个概念,你如果阅读过 Dubbo 源码的话,你会无数次看到这玩意。就比如下面我要说的负载均衡这块的源码中就有大量Invoker的身影。简单来说,
Invoker就是 Dubbo 对远程调用的抽象。
按照 Dubbo 官方的话来说,
Invoker分为服务提供
Invoker服务消费
Invoker假如我们需要调用一个远程方法,我们需要动态代理来屏蔽远程调用的细节吧!我们屏蔽掉的这些细节就依赖对应的
Invoker实现,Invoker实现了真正的远程服务调用。Dubbo 分层架构
总的而言 Dubbo 分为三层,如果每一层再细分下去,一共有十层。别怕也就十层,本丙带大家过一遍,大家先有个大致的印象,之后的文章丙会带着大家再深入。
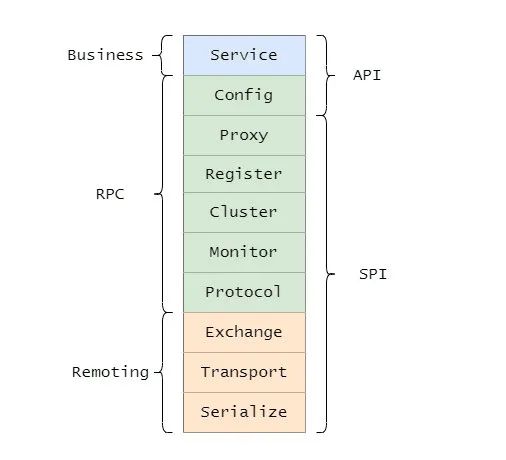
大的三层分别为 Business(业务层)、RPC 层、Remoting,并且还分为 API 层和 SPI 层。
左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。
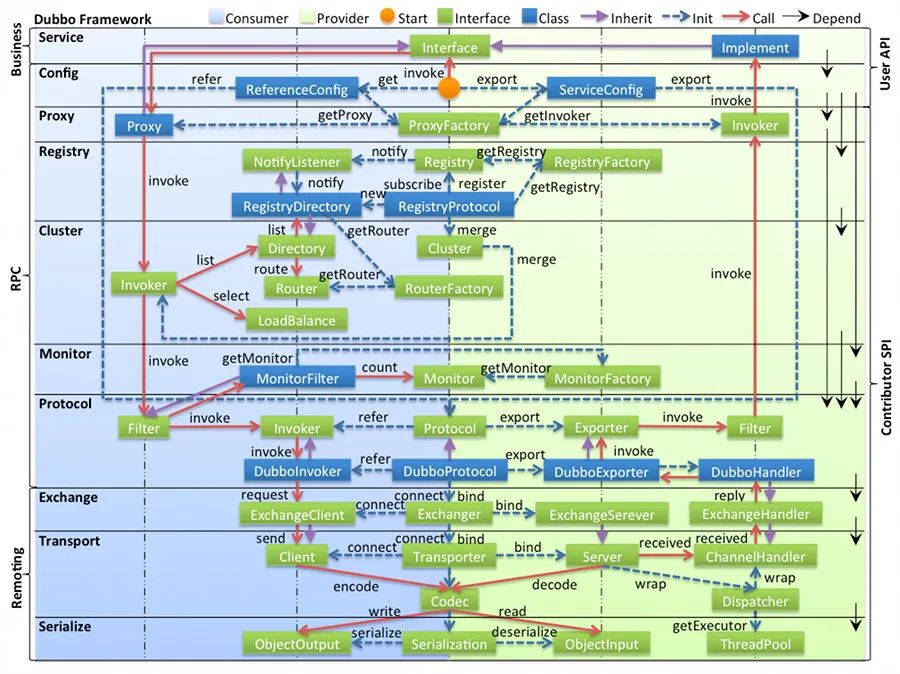
分为大三层其实就是和我们知道的网络分层一样的意思,只有层次分明,职责边界清晰才能更好的扩展。
而分 API 层和 SPI 层这是 Dubbo 成功的一点,采用微内核设计+SPI扩展,使得有特殊需求的接入方可以自定义扩展,做定制的二次开发。
接下来咱们再来看看每一层都是干嘛的。
Service,业务层,就是咱们开发的业务逻辑层。
Config,配置层,主要围绕 ServiceConfig 和 ReferenceConfig,初始化配置信息。支持代码配置,同时也支持基于 Spring 来做配置。
Proxy,代理层,服务提供者还是消费者都会生成一个代理类,使得服务接口透明化,代理层做远程调用和返回结果。真实调用过程依赖代理类,以
ServiceProxy为中心。Register,注册层,封装了服务注册和发现。
Cluster,路由和集群容错层,负责选取具体调用的节点,处理特殊的调用要求和负责远程调用失败的容错措施。封装多个提供者的路由及负载均衡,并桥接注册中心,以
Invoker为中心。Monitor,监控层,负责监控统计调用时间和次数,以
Statistics为中心。Portocol,远程调用层,主要是封装 RPC 调用,主要负责管理 Invoker,Invoker代表一个抽象封装了的执行体,之后再做详解。以
Invocation,Result为中心。Exchange,信息交换层,用来封装请求响应模型,同步转异步,以
Request,Response为中心。Transport,网络传输层,抽象了网络传输的统一接口,这样用户想用 Netty 就用 Netty,想用 Mina 就用 Mina。抽象 mina 和 netty 为统一接口,以
Message为中心。Serialize,序列化层,将数据序列化成二进制流,当然也做反序列化。
SPI
我再稍微提一下 SPI(Service Provider Interface),是 JDK 内置的一个服务发现机制,它使得接口和具体实现完全解耦。我们只声明接口,具体的实现类在配置中选择。
SPI 是 Service Provider Interface,主要用于框架中,框架定义好接口,不同的使用者有不同的需求,因此需要有不同的实现,而 SPI 就通过定义一个特定的位置,Java SPI 约定在 Classpath 下的 META-INF/services/ 目录里创建一个以服务接口命名的文件,然后文件里面记录的是此 jar 包提供的具体实现类的全限定名。
我们在程序运行过程中读取配置文件,通过反射加载实现类。这样,我们可以在运行的时候,动态替换接口的实现类。和 IoC 的解耦思想是类似的。
这样就通过配置来决定具体用哪个实现!
为什么 Dubbo 不用 JDK 的 SPI,而是要自己实现?
问这个问题就是看你有没有深入的了解,或者自己思考过,不是死板的看源码,或者看一些知识点。
很多点是要思考的,不是书上说什么就是什么,你要知道这样做的理由,有什么好处和坏处,这很容易看出一个人是死记硬背还是有自己的思考。
答:因为 Java SPI 在查找扩展实现类的时候遍历 SPI 的配置文件并且将实现类全部实例化,假设一个实现类初始化过程比较消耗资源且耗时,但是你的代码里面又用不上它,这就产生了资源的浪费。
因此 Dubbo 就自己实现了一个 SPI,给每个实现类配了个名字,通过名字去文件里面找到对应的实现类全限定名然后加载实例化,按需加载。
Dubbo 为什么默认用 Javassist
上面你回答 Dubbo 用 Javassist 动态代理,所以很可能会问你为什么要用这个代理,可能还会引申出 JDK 的动态代理、ASM、CGLIB。
所以这也是个注意点,如果你不太清楚的话上面的回答就不要扯到动态代理了,如果清楚的话那肯定得提,来诱导面试官来问你动态代理方面的问题,这很关键。
面试官是需要诱导的,毕竟他也想知道你优秀的方面到底有多优秀,你也取长补短,双赢双赢。
来回答下为什么用 Javassist,很简单,就是快,且字节码生成方便。
ASM 比 Javassist 更快,但是没有快一个数量级,而Javassist 只需用字符串拼接就可以生成字节码,而 ASM 需要手工生成,成本较高,比较麻烦。
那我们如何扩展 Dubbo 中的默认实现呢?
比如说我们想要实现自己的负载均衡策略,我们创建对应的实现类
XxxLoadBalance实现LoadBalance接口或者AbstractLoadBalance类。- package com.xxx;
- import org.apache.dubbo.rpc.cluster.LoadBalance;
- import org.apache.dubbo.rpc.Invoker;
- import org.apache.dubbo.rpc.Invocation;
- import org.apache.dubbo.rpc.RpcException;
- public class XxxLoadBalance implements LoadBalance {
- public <T> Invoker<T> select(List<Invoker<T>> invokers, Invocation invocation) throws RpcException {
- // ...
- }
- }
我们将这个是实现类的路径写入到
resources目录下的META-INF/dubbo/org.apache.dubbo.rpc.cluster.LoadBalance文件中即可。- src
- |-main
- |-java
- |-com
- |-xxx
- |-XxxLoadBalance.java (实现LoadBalance接口)
- |-resources
- |-META-INF
- |-dubbo
- |-org.apache.dubbo.rpc.cluster.LoadBalance (纯文本文件,内容为:xxx=com.xxx.XxxLoadBalance)
org.apache.dubbo.rpc.cluster.LoadBalancexxx=com.xxx.XxxLoadBalance其他还有很多可供扩展的选择,你可以在官方文档@SPI 扩展实现这里找到。
Dubbo 的微内核架构了解吗?
Dubbo 采用 微内核(Microkernel) + 插件(Plugin) 模式,简单来说就是微内核架构。微内核只负责组装插件。
何为微内核架构呢? 《软件架构模式》 这本书是这样介绍的:
微内核架构模式(有时被称为插件架构模式)是实现基于产品应用程序的一种自然模式。基于产品的应用程序是已经打包好并且拥有不同版本,可作为第三方插件下载的。然后,很多公司也在开发、发布自己内部商业应用像有版本号、说明及可加载插件式的应用软件(这也是这种模式的特征)。微内核系统可让用户添加额外的应用如插件,到核心应用,继而提供了可扩展性和功能分离的用法。
微内核架构包含两类组件:核心系统(core system) 和 插件模块(plug-in modules)。
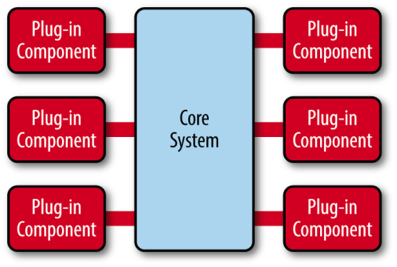
核心系统提供系统所需核心能力,插件模块可以扩展系统的功能。因此, 基于微内核架构的系统,非常易于扩展功能。
我们常见的一些 IDE,都可以看作是基于微内核架构设计的。绝大多数 IDE 比如 IDEA、VSCode 都提供了插件来丰富自己的功能。
正是因为 Dubbo 基于微内核架构,才使得我们可以随心所欲替换 Dubbo 的功能点。比如你觉得 Dubbo 的序列化模块实现的不满足自己要求,没关系啊!你自己实现一个序列化模块就好了啊!
通常情况下,微核心都会采用 Factory、IoC、OSGi 等方式管理插件生命周期。Dubbo 不想依赖 Spring 等 IoC 容器,也不想自已造一个小的 IoC 容器(过度设计),因此采用了一种最简单的 Factory 方式管理插件 :JDK 标准的 SPI 扩展机制 (
java.util.ServiceLoader)。Dubbo 调用过程
上面我已经介绍了每个层到底是干嘛的,我们现在再来串起来走一遍调用的过程,加深你对 Dubbo 的理解,让知识点串起来,由点及面来一波连连看。
我们先从服务提供者开始,看看它是如何工作的。
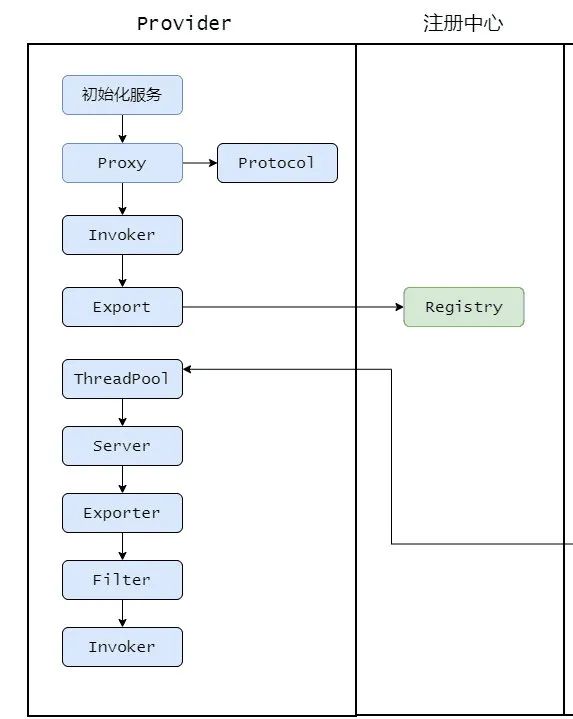
服务暴露过程
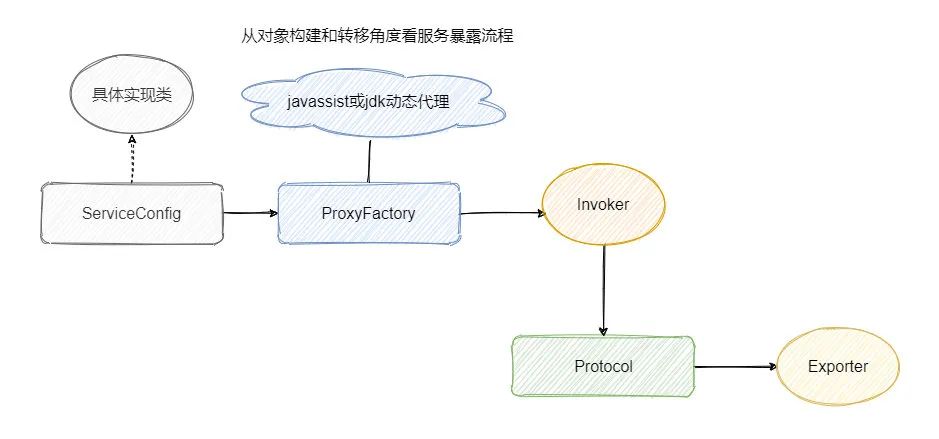
服务的暴露起始于Provider启动后, Spring IOC 容器刷新完毕之后,会根据配置参数组装成 URL, 然后根据 URL 的参数来进行本地或者远程调用。
会通过
proxyFactory.getInvoker,利用 javassist 来进行动态代理,封装真的实现类。通过 Proxy 组件根据具体的协议 Protocol 将需要暴露出去的接口封装成 Invoker,Invoker 是 Dubbo 一个很核心的组件,代表一个可执行体。然后再通过 URL 参数选择对应的协议来进行 protocol.export,默认是 Dubbo 协议。
在第一次暴露的时候会调用 createServer 来创建 Server,默认是 NettyServer。
然后将 export 得到的 exporter 存入一个 Map 中,供之后的远程调用查找,然后将 Exporter 通过 Registry 注册到注册中心。这就是整体服务暴露过程。
服务引入的流程
服务的引入时机有两种,第一种是饿汉式,第二种是懒汉式。
饿汉式就是加载完毕就会引入,懒汉式是只有当这个服务被注入到其他类中时启动引入流程,默认是懒汉式。
会先根据配置参数组装成 URL ,一般而言我们都会配置的注册中心,所以会构建 RegistryDirectory 向注册中心注册消费者的信息,并且订阅提供者、配置、路由等节点。
得知提供者的信息之后会进入 Dubbo 协议的引入,会创建 Invoker ,期间会包含 NettyClient,来进行远程通信,最后通过 Cluster 来包装 Invoker,默认是 FailoverCluster,最终返回代理类。
说这么多差不多了,关键的点都提到了。
切忌不要太过细,不要把你知道的都说了,这样会抓不住重点,比如上面的流程你要插入,引入的三种方式:本地引入、直连远程引入、通过注册中心引入。
然后再分别说本地引入怎样的,芭芭拉的就会很乱,所以面试的时候是需要删减的,要直击重点。
其实真实说的应该比我上面说的还要精简点才行,我是怕大家不太清楚说的稍微详细了一些。
消费过程
接着我们来看消费者调用流程(把服务者暴露的过程也在图里展示出来了,这个图其实算一个挺完整的流程图了)。
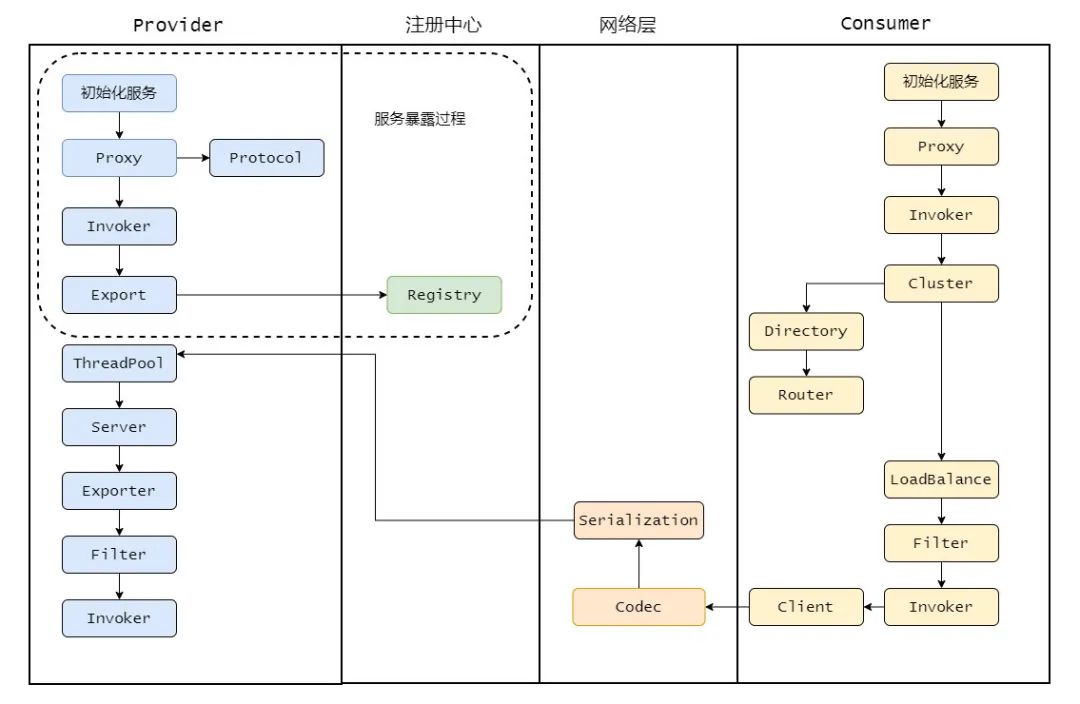
首先消费者启动会向注册中心拉取服务提供者的元信息,然后调用流程也是从 Proxy 开始,毕竟都需要代理才能无感知。
Proxy 持有一个 Invoker 对象,调用 invoke 之后需要通过 Cluster 先从 Directory 获取所有可调用的远程服务的 Invoker 列表,如果配置了某些路由规则,比如某个接口只能调用某个节点的那就再过滤一遍 Invoker 列表。
剩下的 Invoker 再通过 LoadBalance 做负载均衡选取一个。然后再经过 Filter 做一些统计什么的,再通过 Client 做数据传输,比如用 Netty 来传输。
传输需要经过 Codec 接口做协议构造,再序列化。最终发往对应的服务提供者。
服务提供者接收到之后也会进行 Codec 协议处理,然后反序列化后将请求扔到线程池处理。
服务端的某个线程会根据请求找到接受请求之后会通过参数找到之前暴露存储的 map,然后找到对应的 Exporter ,而找到 Exporter 其实就是找到了 Invoker,但是还会有一层层 Filter,经过一层层过滤链之后,最终调用实现类,,再组装好结果返回,这个响应会带上之前请求的 ID。
消费者收到这个响应之后会通过 ID 去找之前记录的请求,然后找到请求之后将响应塞到对应的 Future 中,唤醒等待的线程,最后消费者得到响应,一个流程完毕。
关键的就是 cluster、路由、负载均衡,然后 Dubbo 默认是异步的,所以请求和响应是如何对应上的。
Dubbo 序列化协议
Dubbo 支持哪些序列化方式呢?
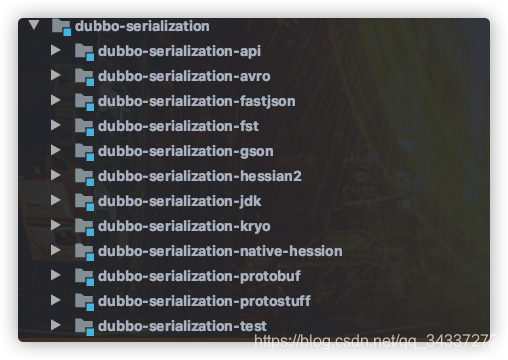
Dubbo 支持多种序列化方式:JDK 自带的序列化、hessian2、JSON、Kryo、FST、Protostuff,ProtoBuf 等等。
Dubbo 默认使用的序列化方式是 hession2。
谈谈你对这些序列化协议了解?
一般我们不会直接使用 JDK 自带的序列化方式。主要原因有两个:
1 不支持跨语言调用 : 如果调用的是其他语言开发的服务的时候就不支持了。
2 性能差 :相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。
JSON 序列化由于性能问题,我们一般也不会考虑使用。
像 Protostuff,ProtoBuf、hessian2 这些都是跨语言的序列化方式,如果有跨语言需求的话可以考虑使用。
Kryo 和 FST 这两种序列化方式是 Dubbo 后来才引入的,性能非常好。不过,这两者都是专门针对 Java 语言的。Dubbo 官网的一篇文章中提到说推荐使用 Kryo 作为生产环境的序列化方式。(文章地址:https://dubbo.apache.org/zh/docs/v2.7/user/references/protocol/rest/)
Dubbo 官方文档中还有一个关于这些序列化协议的性能对比图可供参考。
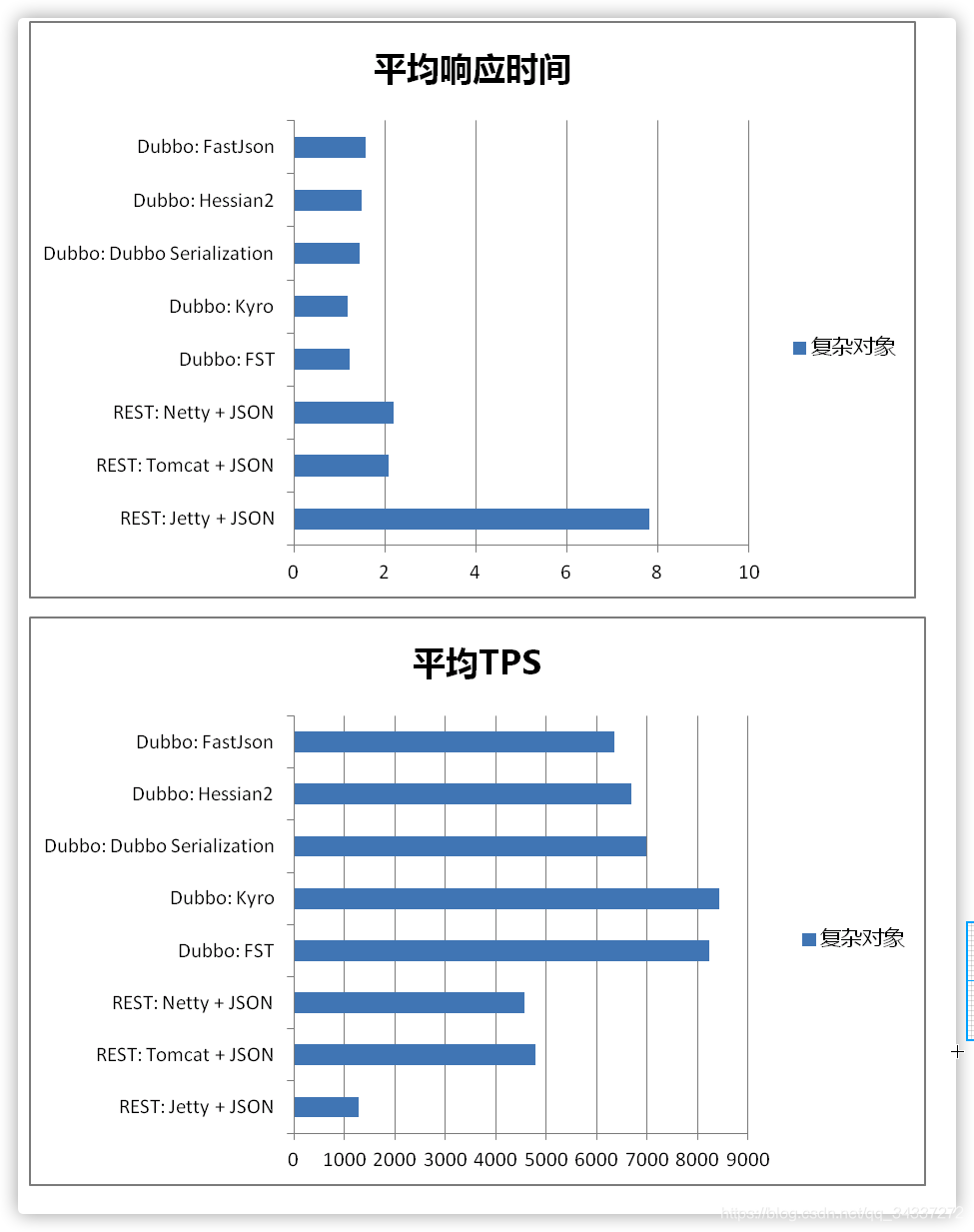
-
相关阅读:
国内网站用香港服务器会被封吗?
法定代表人和股东是什么关系
快速排序压缩算法2024年最新一种压缩算法
spring boot 整合多数据源
一种基于非线性惯性权重的海鸥优化算法-附代码
MySQL函数count
操作符一些代码题
TopoLVM: 基于LVM的Kubernetes本地持久化方案,容量感知,动态创建PV,轻松使用本地磁盘
cron定时任务
Linux在线安装MySQL8.0.24安装、MySQL数据备份和恢复
- 原文地址:https://blog.csdn.net/xushiyu1996818/article/details/127848805
