-
树/二叉树/森林之间的相互转换 与遍历
森林就是多棵树的集合,但是森林也可以只有一棵树,二叉树是一种特殊的树,固定的度为2,这是基本前情提要~
树常见的存储方式有三种:
(1)双亲表示法
仅用定义一个结点对象,一个数组,代码定义如下:
typedef struct { char data; int parent; } Node; typedef struct { Node node[100]; int maxSize; } NodeTree;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
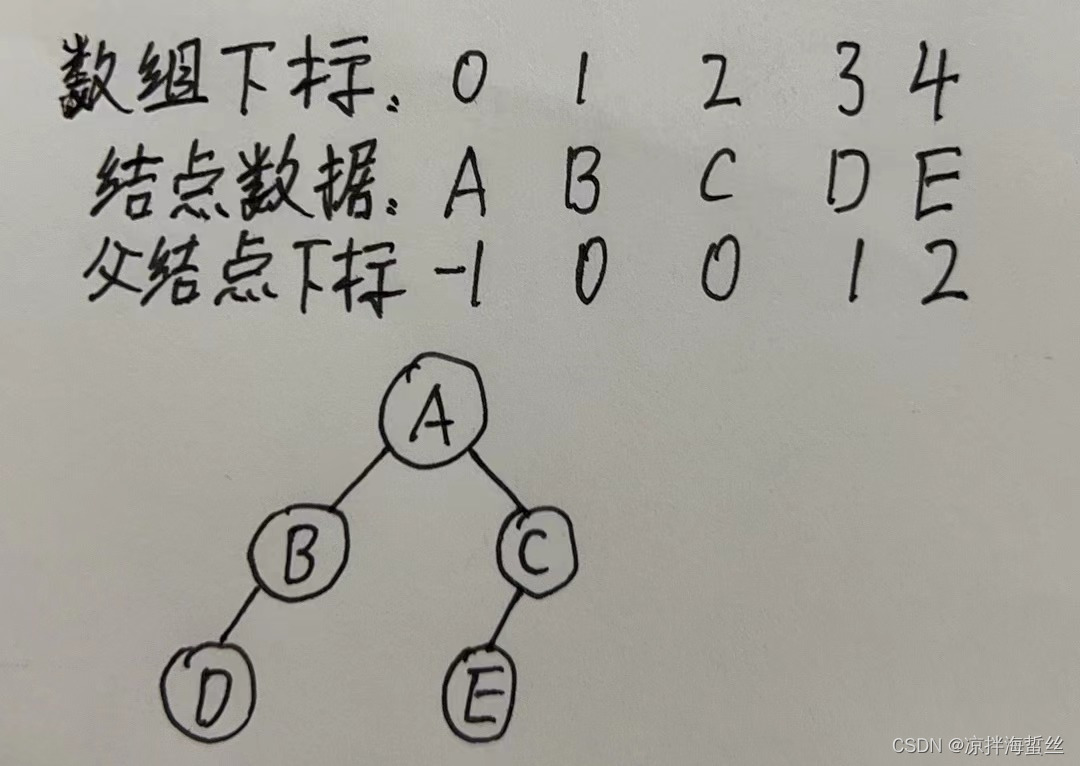
优点:由于对应元素的parent参数存储了父结点在数组中的下标,所以定义某个子结点的父结点非常简单,所以是:找父亲简单
缺点:但是如果想知道某个父亲x有多少个孩子,就必须遍历整个数组,看看哪个元素的parent是x,所以:找儿子们困难(2)孩子表示法
为了克服找孩子困难问题,那么很容易想到把每个结点的孩子存起来,还是看定义比较简单理解
typedef struct { char data; int childs[]; } Node; typedef struct { Node node[100]; int maxSize; } NodeTree;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
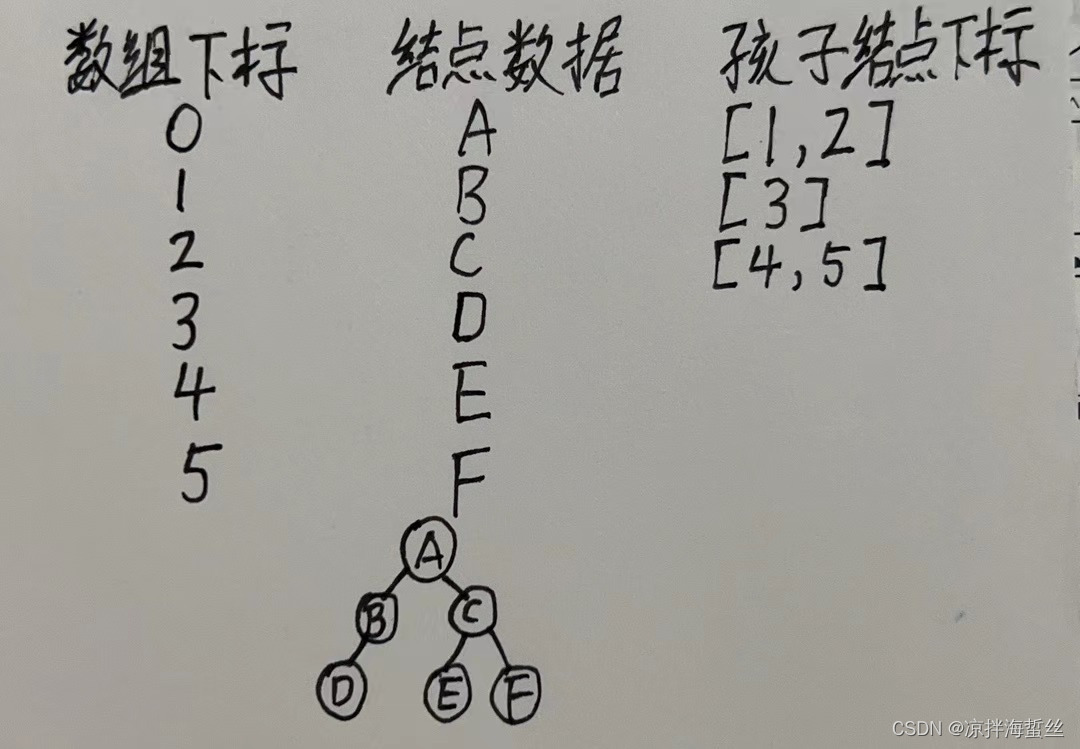
优点:找对应结点的孩子结点们简单
缺点:若要找某个结点的父结点,想象一下是不是应该拿着结点x的下标,去便利数组中所有的结点,看看x的下标在哪个结点的childs数组里面?
(注意,childs数组也可以用链表来实现,都一个意思)记忆:双亲表示法找双亲简单,找孩子难;孩子表示法找孩子简单,找双亲难!
(3)孩子兄弟表示法
这个存储方式是最常用的,最方便的,而且它能很顺利实现树和二叉树甚至森林的转换,所以它很重要
结构定义上,它就是之前学过的双向链表而已,左指针指向孩子,右指针指向兄弟;也就是背到烂的“左孩子右兄弟”typedef struct Nodes -
相关阅读:
我想开发一个小程序,大概需要多少钱?
k8s中应用GlusterFS类型StorageClass
Node.js数电票、全电票查验接口示例、发票查验、票据OCR API
计算机系统概论
Qt编程,文件操作、UDP通信
leetcode-64.最小路径和
AcWing 138. 兔子与兔子
电脑重装系统虚拟机安装xp的教程
ALGO开发源码【node服务】
信息学奥赛一本通:1129:统计数字字符个数
- 原文地址:https://blog.csdn.net/whiteBearClimb/article/details/127919708