-
DDD系列 实战一 应用设计案例 (golang)
DDD系列 实战一 应用设计案例 (golang)
基于 ddd 的设计思想, 核心领域需要由纯内存对象+基础设施的抽象的接口组成
-
独立于外部框架: 比如 web 框架可以是 gin, 也可以是 beego -
独立于客户端: 比如客户端可以是 web, 可以是移动端, 也可以是其他服务 rpc 调用 -
独立于基础组件: 比如数据库可以是 MySQL, 可以是 MongoDB, 甚至是本地文件 -
独立于第三方库: 比如加密库可以是 bcrypt, 也可以是其他加密库, 不会应为第三方库的变更而大幅影响到核心领域 -
可测性: 核心领域的 domain 是纯内存对象, 依赖的基础设施的接口是抽象的, 可以 mock 掉, 便于测试
怎么实现呢? 下面我根据一个案例来一步步展示通过 DDD 重构三层架构的过程
案例描述
本案例将会创建一个应用, 提供如下 web 接口 (目前使用 golang 实现)
-
注册 POST /auth/register -
登录 POST /auth/login -
获取用户信息 GET /user -
转账 POST /transfer
DDD 是为了复杂系统变化而设计的, 如果系统简单, 需求变动不大. 那么脚本代码才是最好的选择, 不仅能快速开发, 而且理解.
所以这次案例里, 为了展示 DDD 设计的高拓展性, 需求主要强调 变化 的场景.
注册
-
目前通过账号和密码注册, 以后可能增加根据手机号邮箱等注册 -
用户的密码需要加密, 目前使用 hash 加密, 后面可能使用其他加密 -
目前保存数据使用的 MySQL, 以后可能使用其他数据库
登录
同理注册
鉴权
除了注册登录, 其他接口都需要鉴权
-
目前使用 redis 鉴权, 以后可能会更换为 jwt 鉴权, 需要有切换的能力
转账 (核心)
一个用户转账给另一个用户
-
需要支持跨币种转账 -
目前转账的汇率从第三方 (微软的 api) 获取, 以后可能会考虑变更或者做缓存 -
目前转账收取手续费 10%, 以后可能根据用户 vip 等级收取不同的手续费 -
需要保存账单, 以便审计和对账用 -
目前账单是保存在 MySQL 中, 以后可能会考虑保存到其他数据库或者消息队列消费
接口
-
目前提供 web 接口, 以后可能会提供 rpc 或者其他接口
什么是 MVC 三层架构?
对于一般的后端开发来说, MVC 架构都不会陌生. 现在几乎所有的 Web 项目, 都是基于这种三层架构开发模式. 甚至连 Java Spring 框架的官方 demo, 都是按照这种开发模式来编写的.
后端的三层架构就是: Controller, Service, Repository. Controller 负责暴力接口, Service 负责业务逻辑, Repository 负责数据操作.
下面是转账服务的核心 Service (忽略所有错误和参数验证和事务)
// TransferService 转账服务
// @param fromUserID 转出用户ID
// @param toUserID 转入用户ID
// @param amount 转账金额
// @param currency 转账币种
func (t *TransferService) Transfer(fromUserID string, toUserID string, amount decimal.Decimal, currency string ) {
// 读数据
var fromUser User
var toUser User
t.Db.Where("id = ?", fromUserID).First(&fromUser)
t.Db.Where("id = ?", toUserID).First(&toUser)
// 币种验证
if fromUser.Currency != currency || toUser.Currency != currency {
return errors.New("currency not match")
}
// 获取汇率
var rate decimal.Decimal
if fromUser.Currency == toUser.Currency {
rate = decimal.NewFromFloat(1)
} else {
// 通过微软的 api 获取汇率
rate = t.MicroService.GetRate(fromUser.Currency, toUser.Currency)
}
// 计算需要的金额
fromAmount = amount.Mul(rate)
// 计算手续费
fee = fromAmount.Mul(decimal.NewFromFloat(0.1))
// 计算总金额
fromTotalAmount = fromAmount.Add(fee)
// 余额验证
if fromUser.Balance.LessThan(fromTotalAmount) {
return errors.New("balance not enough")
}
// 转账
fromUser.Balance = fromUser.Balance.Sub(fromTotalAmount)
toUser.Balance = toUser.Balance.Add(amount)
// 保存数据
t.Db.Save(&fromUser)
t.Db.Save(&toUser)
// 保存账单
t.Db.Create(&Bill{
FromUserID: fromUserID,
ToUserID: toUserID,
Amount: amount,
Currency: currency,
Rate: rate,
Fee: fee,
BillType, "zhuanzhang",
})
return nil
}- 1
我们可以看到, MVC 的 Service 层一般非常臃肿, 包含各种参数校验(这里省略了很多参数校验和错误处理), 逻辑计算, 数据操作, 甚至还包含了一些第三方服务的调用.
这样的代码, 也称之为 "事务脚本", "胶水代码", "面向过程代码" 等等. 优点是简单容易理解, 缺点是代码臃肿, 代码可维护性差, 代码可拓展性差, 代码可测试性差.
问题1: 代码可维护性差
代码可维护性 = 当依赖变化的时候, 需要修改多少代码
参考上面的代码, 我们发现胶水代码的可维护性比较差主要因为以下原因
-
数据结构不稳定: user 是一个存数据类, 通过 gorm 映射了 MySQL 中的 user 表. 这里的问题是 MySQL 属于外部依赖, 长远来看都可能改变. 比如 ID 变成 int64 类型, 比如表中的字段名改变; 比如数据量大了需要分库分表; 比如使用 Redis 或则 MongoDB 代替 MYSQL -
依赖库的不稳定: 比如 grom 升级导致 api 不一致; 比如我们需要用 beego 替代 grom; 比如我们需要用 goweb 框架代替 gin -
依赖服务的不稳定: 比如我们依赖的 MicroServer 升级导致 api 不一致; 比如我们需要用 GoogleService 替代 MicroService
问题2: 代码可拓展性差
可拓展性=增加或者修改需求的时候, 需要修改多少代码
参考上面的代码, 如果我们今天要增加一个充值的功能, 我们可以发现上面的代码基本没有可以复用的逻辑
充值功能需要将银行卡的钱充值到余额, 银行卡可能是其他银行的银行卡, 其他银行卡的用户的数据结构可能不一致
-
数据格式不兼容: 其他银行卡的用户的数据结构可能不一致, 导致数据校验, 数据读写, 错误处理, 金额计算, 手续费计算 等等逻辑都需要重新写 -
业务逻辑无法复用: 因为数据结构的不一致, 所以业务逻辑基本需要将原来的复制过去, 然后重新改 -
业务逻辑和数据储存耦合严重: 当业务逻辑变得越来越复杂的时候, 新增的业务逻辑可能需要新的数据结构, 转账功能和充值功能都需要改代码
一般的胶水代码做需求都非常快, 但是可复用的逻辑很少, 一旦涉及到新增有相同但是又不同的逻辑或者修改需求, 需要修改的代码很多. 如果有地方的代码忘了改就是一个 bug. 在反复变化的需求中, 代码的可拓展性显得很差
问题3: 代码可测试性差
可测试性 = 运行每个测试用例所花费的时间 * 每个需求所需要增加的测试用例数量
除了部分工具类、框架类和中间件类的代码有比较高的测试覆盖之外,我们在日常工作中很难看到业务代码有比较好的测试覆盖,而绝大部分的上线前的测试属于人肉的“集成测试”。低测试率导致我们对代码质量很难有把控,容易错过边界条件,异常case只有线上爆发了才被动发现。而低测试覆盖率的主要原因是业务代码的可测试性比较差。
参考上面的代码, 这种代码可测试性比较差的原因是:
-
基础设施搭建困难: 比如代码中依赖了数据库, 第三方服务 等外部依赖, 想要跑测试用例需要将所有的依赖都跑起来. 本案例作为 demo 依赖还是比较少的. 一般项目有 Reids MySQL ES 消息队列 再加 10 个三方微服务, 请问怎么写单元测试? -
耗时长: 如果跑测试用例的时间超过 1 分钟, 大部分程序员就不会去跑测试用例了, 这种测试即使所有的依赖都搭建起来的了, 各种 IO 网络 都非常耗时, 测试时间比较长. 面对这种困境, 程序员一般选择 "颅内测试" -
测试用例复杂: 假如一个脚本中有 3 个步骤, 每个步骤对应了 N 个状态, 那么测试用例的数量就是 N*N*N当胶水代码中的步骤越来越多, 测试用例将会呈现指数级增长
一般的这样的胶水代码, 当测试比较复杂的时候, 开发人员无法写这个方法的单元测试, 依赖测试人员的 "人肉测试" 或者开发人员的 "颅内测试".
每次代码变动, 之前的测试就可能变得不可靠, 有需要重新 "人肉测试" 或者 "颅内测试", 如果每天变动 2 次代码, 就陷入了无限的测试和代码 review 的风暴中
问题总结
我们重新来分析一下为什么以上的问题会出现?因为以上的代码违背了至少以下几个软件设计的原则:
-
单一性原则(Single Responsibility Principle):单一性原则要求一个对象/类应该只有一个变更的原因。但是在这个案例里,代码可能会因为任意一个外部依赖或计算逻辑的改变而改变。 -
依赖反转原则(Dependency Inversion Principle):上层模块不要依赖底层,应该依赖底层的抽象, 面向接口编程。在这个案例里外部依赖都是具体的实现, 比如 MicroService 虽然是一个接口类,但是它对应的是依赖了MicroSoft提供的具体服务,所以也算是依赖了实现。同样的 grom.DB 实现也属于具体实现。 -
开闭原则(Open Closed Principle):对拓展开放, 对修改关闭。在这个案例里的金额计算属于可能会被修改的代码,这个时候该逻辑应该需要被包装成为不可修改的计算类,新功能通过计算类的拓展实现。
我们需要对代码重构才能解决这些问题。下面我们就来看下如何使用 DDD 重构我们上面的胶水代码
如何使用 DDD 重构?
怎么重构呢? 主要分为 2 方面:
-
抽离逻辑: 贫血的类数据没有逻辑, 充血模型的类既有数据又有逻辑. DDD 的思想是将数据校验和逻辑抽离到存内存的类中, 这种类不能有任何的依赖 -
抽象接口: 将依赖抽象一个接口, 不依赖具体的实例, 依赖接口
参考上面的代码, 我们画一张流程图描述一下主要的步骤:
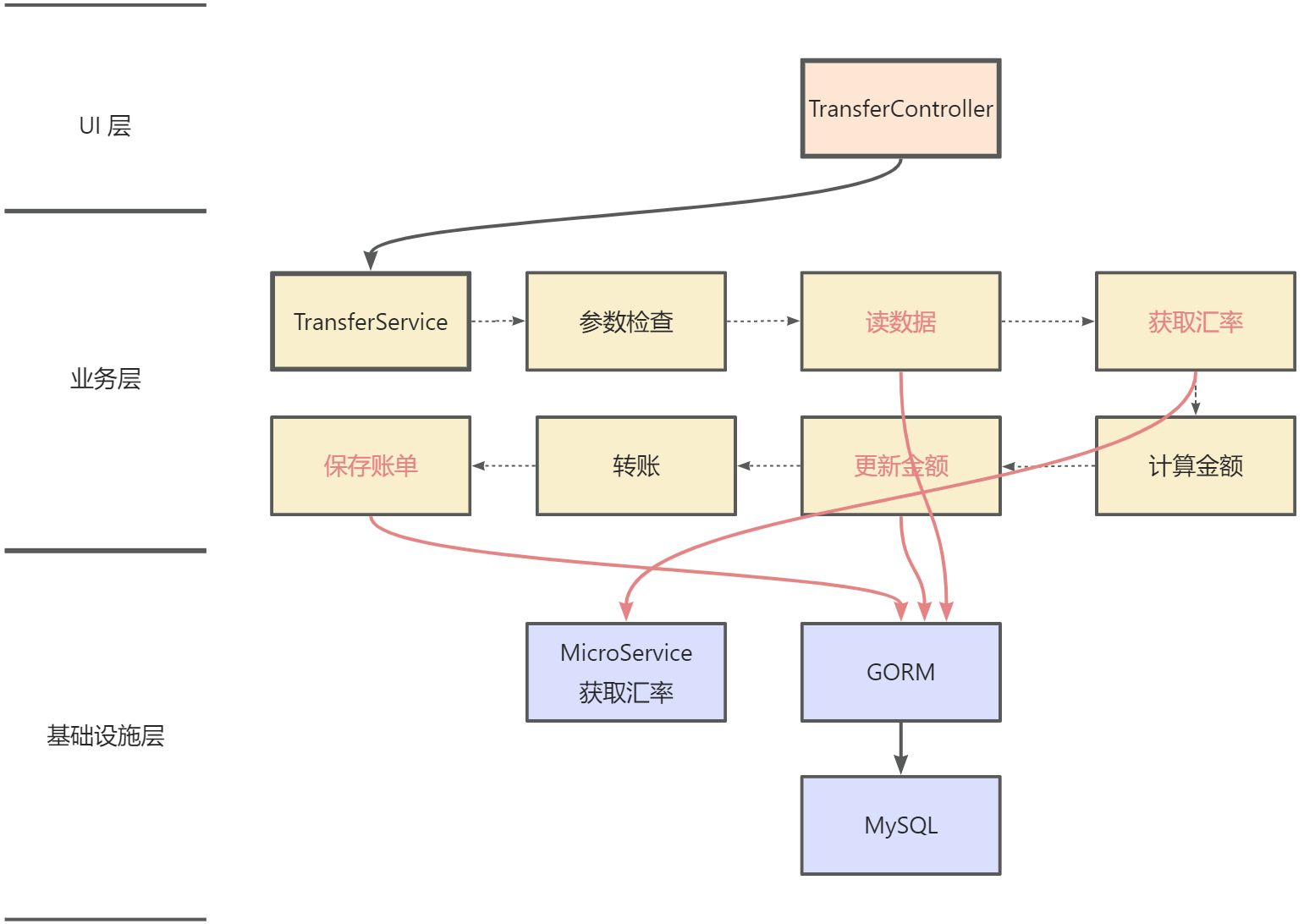
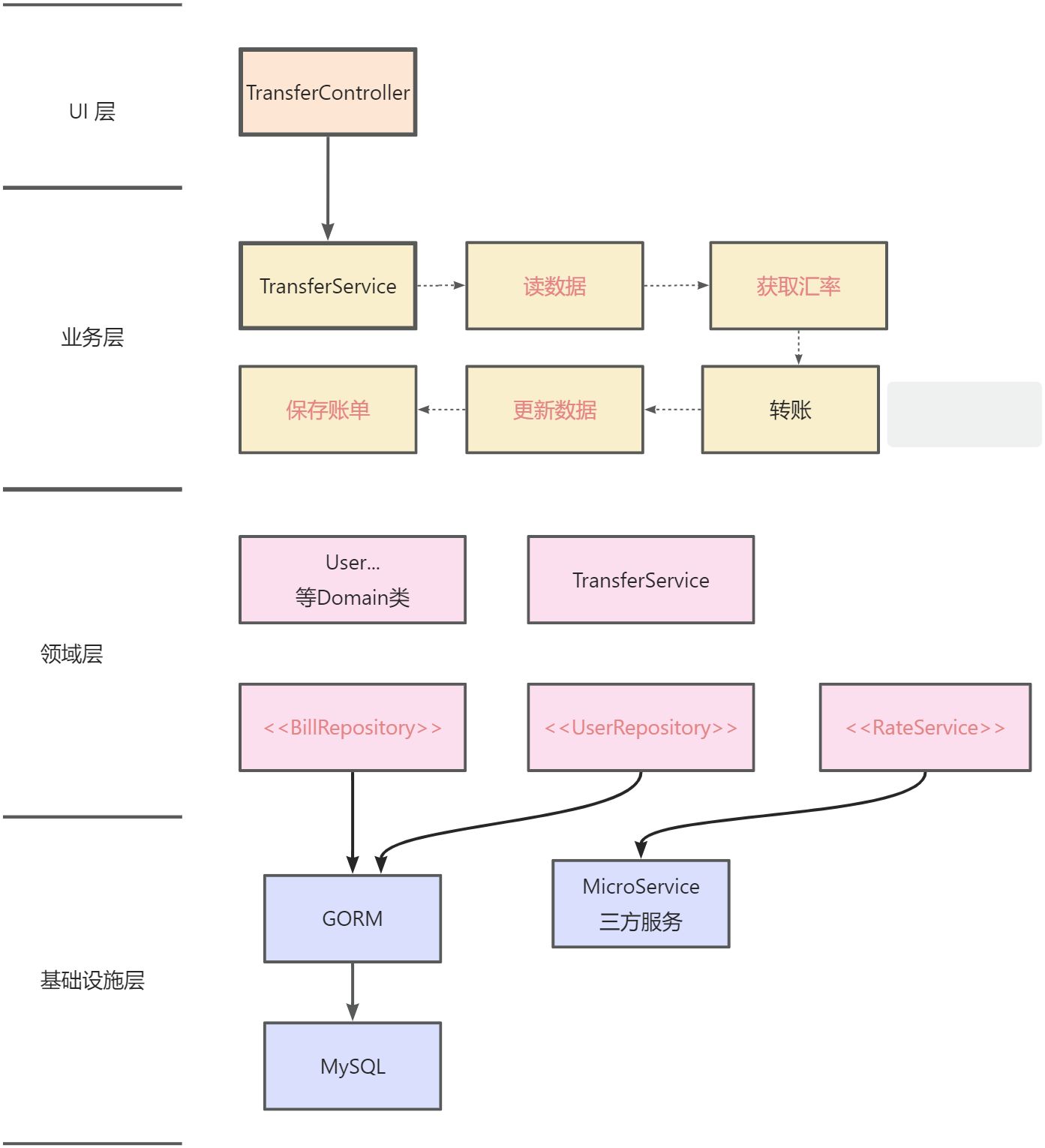
架构流程图 -
TransferController 依赖 TransferService, TransferService 依赖 MicroService 和 GROM -
业务层中黑色字体代表业务逻辑, 红色字体代表需要依赖基础设施的输入输出 -
读数据, 更新金额, 保存账单依赖于 GROM -
获取汇率 依赖 MicroService
第一步 抽离逻辑
业务层中黑色字体代表业务逻辑, 包含 参数检查, 金额计算和转账
MVC 三层架构是一种贫血模型, 贫血模型的类数据没有逻辑, 充血模型的类既有数据又有逻辑
我们要做的是: 将 Service 中的逻辑抽离到类中
(1) 使用 Domain Object 代替基础数据类型
// 基础数据类型
Transfer(fromUserID string, toUserID string, amount decimal.Decimal, currency string ) error
// 领域类
Transfer(fromUserID, toUserID *model.UserID, amount *model.Amount, currencyStr string) error- 1
Domain Object 就是一种充血模型, 既有数据又有逻辑, 比如上面的
model.UserID这个对象的构造方法如下func NewUserID(userID string) (*UserID, error) {
// 参数检查
return &UserID{
value: userID,
}, nil
}- 1
我们可以发现参数检查在构造方法里面, 这样就能保证传入的参数一定是经过参数检查的, 如果所有的 Service 方法都用 Domain Object 替代基础数据类型, 这样就不用担心参数校验的问题了
而且 Domain Object 是纯内存的, 没有任何依赖, 十分方便测试
(2) 使用 Domain Service 封装业务逻辑
之前我们的计算金额和转账逻辑都是由 Controller 下面的 Service 层实现的 因为 Service 需要太多依赖, 比如 MicroService 和 GROM, 所以我们很难对这一块逻辑进行测试 如果我们把这这块逻辑抽离到没有任何依赖的纯内存的 Domain Service 中, 就能很方便的测试
func (*TransferService) Transfer(fromUser *User, toUser *User, amount *Amount, rate *Rate) {
// 通过汇率转换金额
fromAmount := rate.Exchange(amount)
// 根据用户不同的 vip 等级, 计算手续费
fee := fromUser.CalcFee(fromAmount)
// 计算总金额
fromTotalAmount := fromAmount.Add(fee)
// 转账
fromUser.Pay(fromTotalAmount)
toUser.Receive(amount)
}- 1
第二步 抽象接口
我再贴一下我们之前分析的三层架构流程图, 业务层中红色字体代表需要依赖基础设施
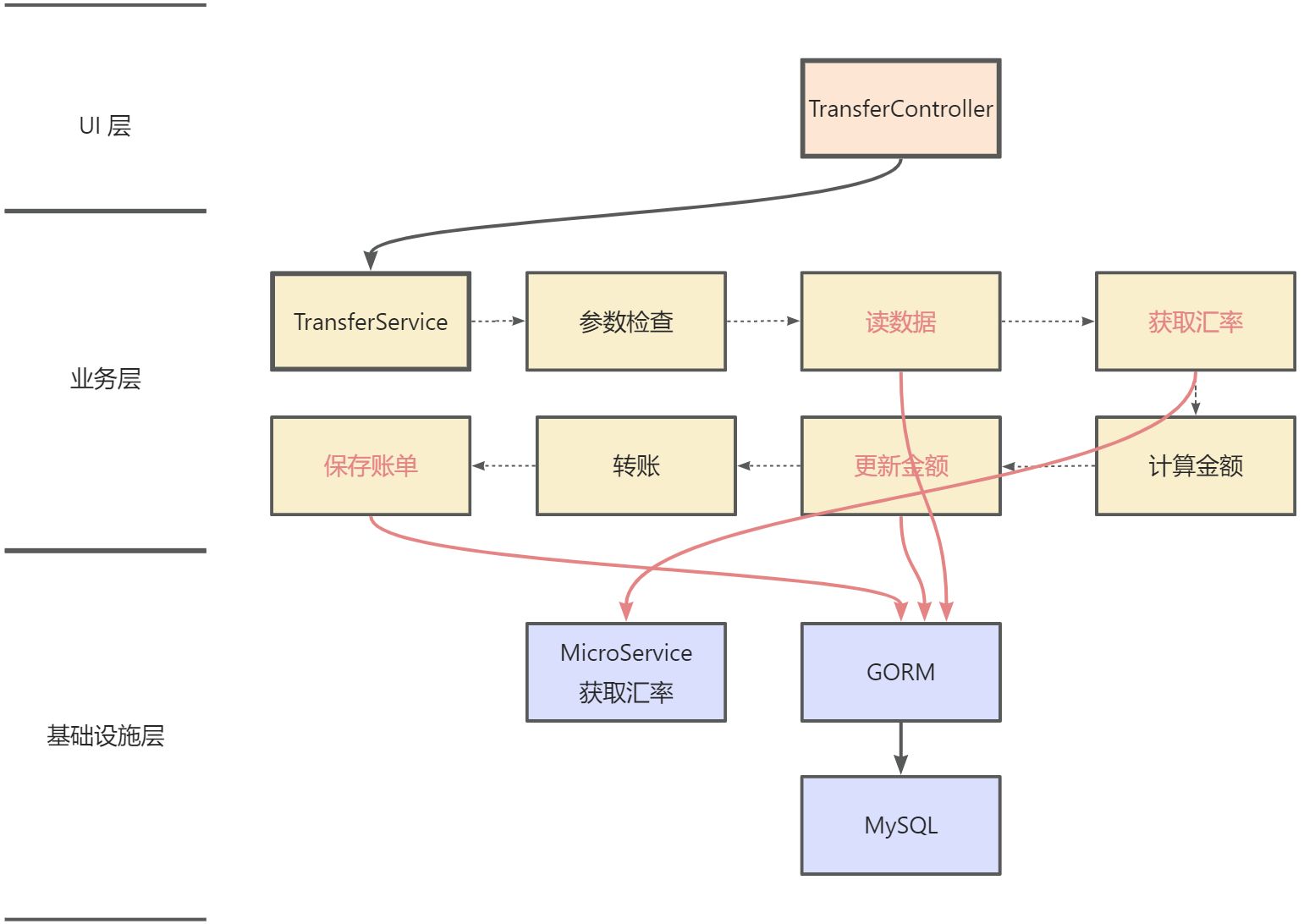
架构流程图 依赖反转原则(Dependency Inversion Principle):上层模块不要依赖底层,应该依赖底层的抽象, 面向接口编程。在这个案例里外部依赖都是具体的实现,比如 MicroService 虽然是一个接口类,但是它对应的是依赖了MicroSoft提供的具体服务,所以也算是依赖了实现。同样的 grom.DB 实现也属于具体实现。
我们要做的就是抽象一层接口出来, 面向接口编程
(1) 抽象汇率获取服务
type RateService interface {
GetRate(from *model.Currency, to *model.Currency) (*model.Rate, error)
}- 1
然后 MicroRateService 是该接口的一种实现, 这种设计叫也做防腐层
防腐层不仅仅是多了一层调用, 它还可以提供如下功能
-
适配器:很多时候外部依赖的数据、接口和协议并不符合内部规范,通过适配器模式,可以将数据转化逻辑封装到防腐层内部,降低对业务代码的侵入。在这个案例里,我们通过封装了Rate 和 Currency 对象,转化了对方的入参和出参,让入参出参更符合我们的标准。 -
缓存:对于频繁调用且数据变更不频繁的外部依赖,通过在防腐层里嵌入缓存逻辑,能够有效的降低对于外部依赖的请求压力。同时,很多时候缓存逻辑是写在业务代码里的,通过将缓存逻辑嵌入防腐层,能够降低业务代码的复杂度。 -
兜底:如果外部依赖的稳定性较差,一个能够有效提升我们系统稳定性的策略是通过防腐层起到兜底的作用,比如当外部依赖出问题后,返回最近一次成功的缓存或业务兜底数据。这种兜底逻辑一般都比较复杂,如果散落在核心业务代码中会很难维护,通过集中在防腐层中,更加容易被测试和修改。 -
易于测试:类似于之前的接口,防腐层的接口类能够很容易的实现Mock或Stub,以便于单元测试。 -
功能开关:有些时候我们希望能在某些场景下开放或关闭某个接口的功能,或者让某个接口返回一个特定的值,我们可以在防腐层配置功能开关来实现,而不会对真实业务代码造成影响。同时,使用功能开关也能让我们容易的实现Monkey测试,而不需要真正物理性的关闭外部依赖。
(2) 抽象 gorm
type UserRepo interface {
Get(*model.UserID) (*model.User, error)
Save(*model.User) (*model.User, error)
}- 1
在接口层面做统一,不关注底层实现。比如,通过 Save 保存一个 Domain 对象,但至于具体是 insert 还是 update 并不关心. 是使用 MYSQL 还是使用 MongoDB 甚至是本地文件储存都不关心.
重构之后是什么样子?
重构之后的 Service 层如下, 为了区别我们抽离出来的纯内存的 TransferService, 我们将这原来的Service层命名为 TransferApp 代表 Application 层
重构之后的 UserApp.Transfer() 代码如下 (忽略所有的错误处理和事务):
func (u *UserApp) Transfer(fromUserID, toUserID *model.UserID, amount *model.Amount, currencyStr string) error {
// 读数据
fromUser := u.userRepo.Get(fromUserID)
toUser := u.userRepo.Get(toUserID)
toCurrency := model.NewCurrency(currencyStr)
// 获取汇率
rate := u.rateService.GetRate(fromUser.Currency, toCurrency)
// 转账
u.transferService.Transfer(fromUser, toUser, amount, rate)
// 保存数据
u.userRepo.Save(fromUser)
u.userRepo.Save(toUser)
// 保存账单
bill := &bill_model.Bill{
FromUserID: fromUser.ID,
ToUserID: toUser.ID,
Amount: amount,
Currency: toCurrency,
}
u.billApp.CreateBill(bill)
return nil
}- 1
重构之后的架构流程图如下, 我们新增了粉色部分的领域层:
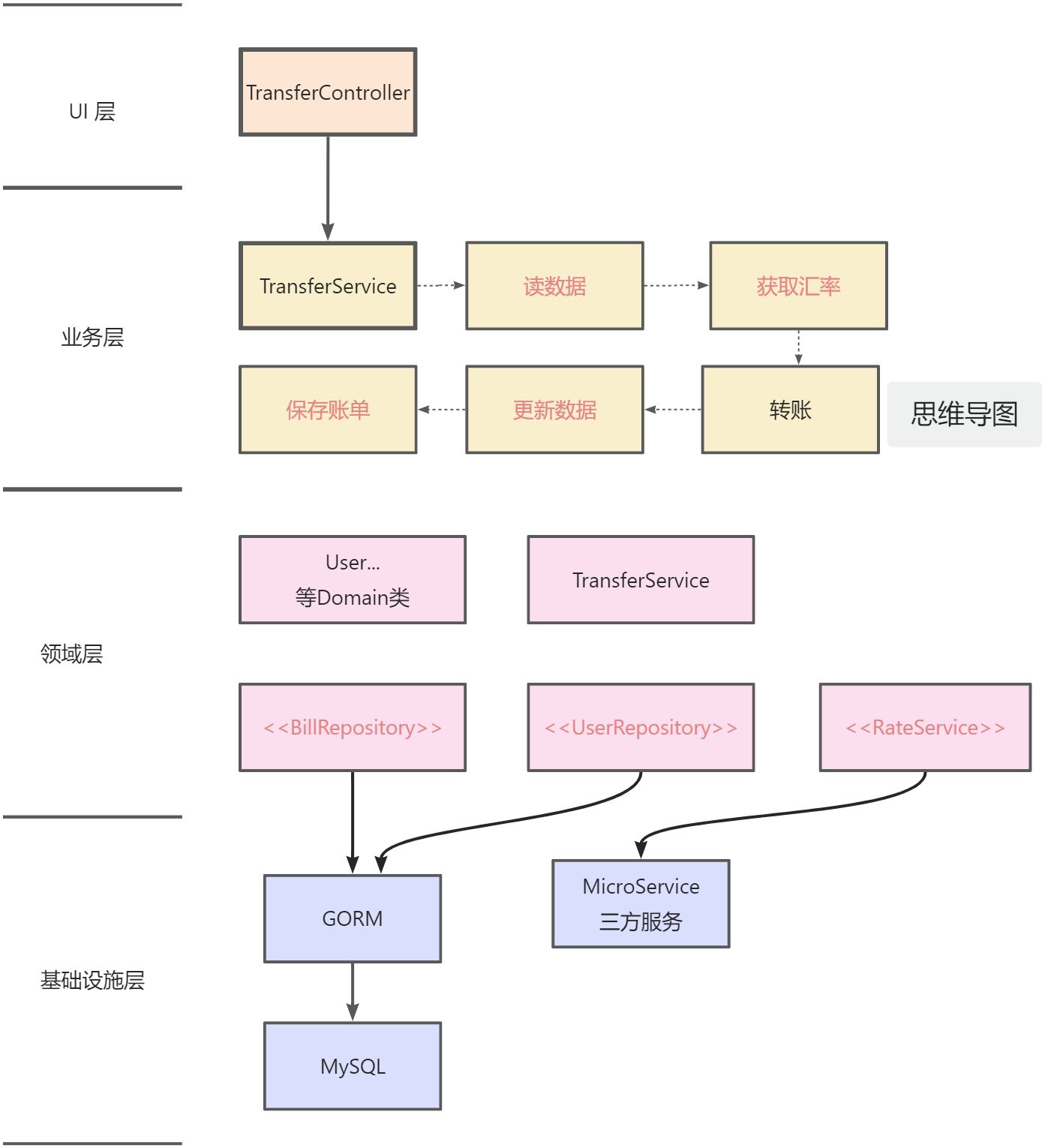
架构流程图 新增的领域层分为 2 个部分
-
抽离逻辑 (黑色字体): 有数据又有逻辑的 Domain Object 对象 和没有任何依赖的 Domain Service 对象, 纯内存, 方便测试 -
抽象接口 (红色字体): 抽象的基础设施层的接口, 方便 mock 测试
如何组织代码结构?
参考上面的代码, 你或许已经跃跃欲试的尝试自己通过 DDD 的思想实现一下这个案例了 但是当你拿到需求时候, 打开 IDE 第一个问题就是: 如何组织代码结构? 要解决这个问题的前提我想是: 明确架构
MVC 三层架构
比如上面代码的例子
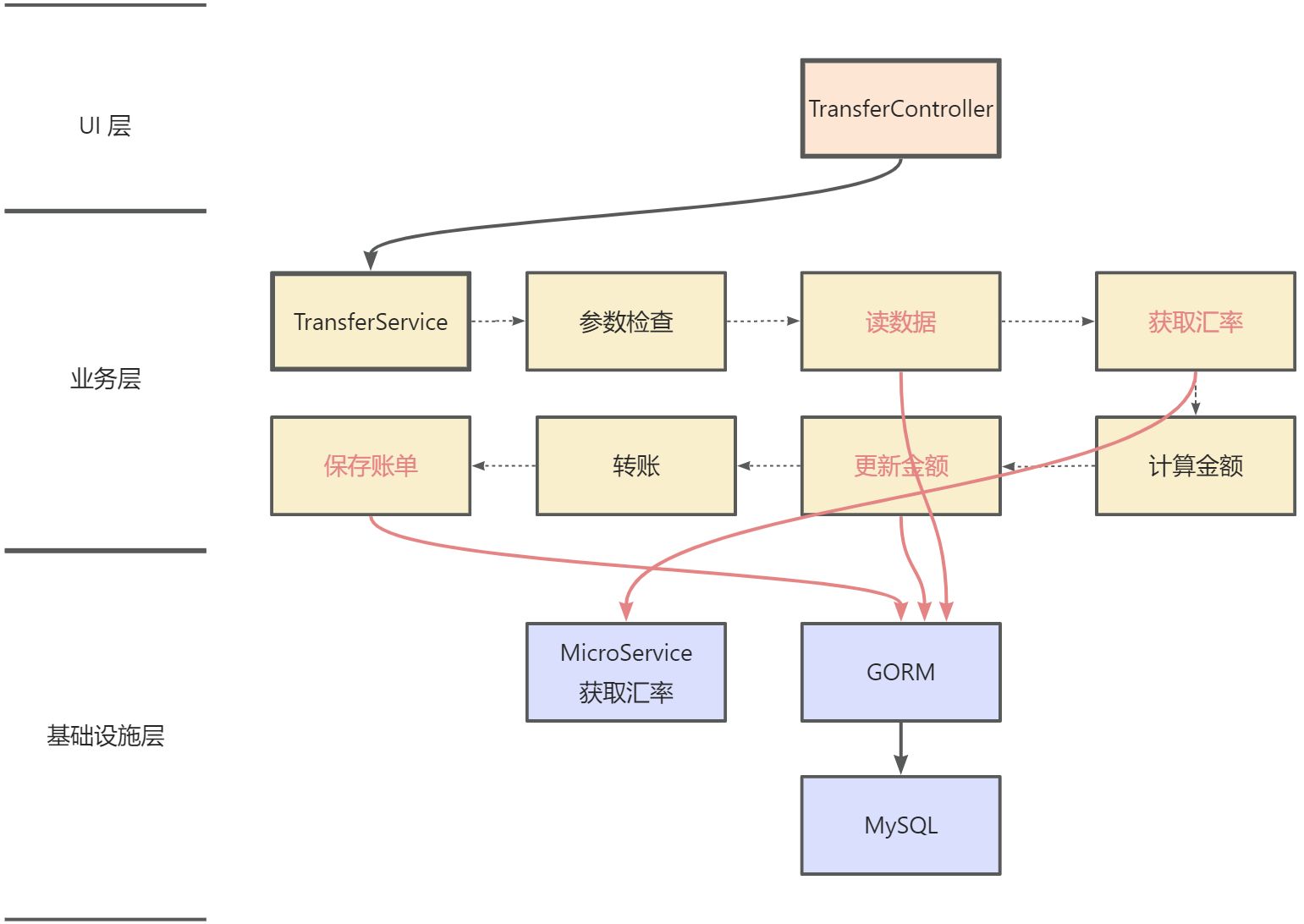
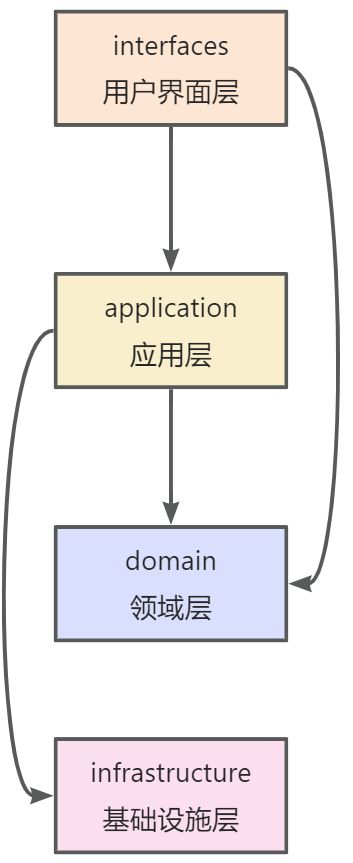
架构流程图 DDD 四层架构
比如上面代码的重构后的例子
架构流程图 对应的四层架构模型如下
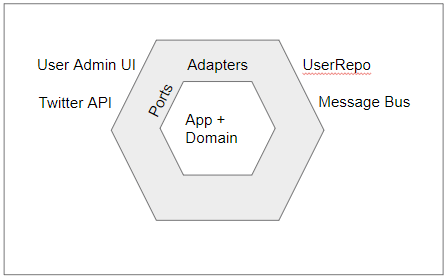
架构流程图 DDD 六边形架构/洋葱架构/干净架构
在上面重构的代码里,如果抛弃掉所有Repository、ACL、Producer等的具体实现细节,我们会发现每一个对外部的抽象类其实就是输入或输出,类似于计算机系统中的I/O节点。这个观点在CQRS架构中也同样适用,将所有接口分为Command(输入)和Query(输出)两种。除了I/O之外其他的内部逻辑,就是应用业务的核心逻辑。基于这个基础,Alistair Cockburn在2005年提出了Hexagonal Architecture(六边形架构),又被称之为Ports and Adapters(端口和适配器架构)。
架构流程图 在这张图中:
-
I/O的具体实现在模型的最外层 -
每个I/O的适配器在灰色地带 -
每个Hex的边是一个端口 -
Hex的中央是应用的核心领域模型
在Hex中,架构的组织关系第一次变成了一个二维的内外关系,而不是传统一维的上下关系。同时在Hex架构中我们第一次发现UI层、DB层、和各种中间件层实际上是没有本质上区别的,都只是数据的输入和输出,而不是在传统架构中的最上层和最下层。
除了2005年的Hex架构,2008年 Jeffery Palermo的Onion Architecture(洋葱架构)和2017年 Robert Martin的Clean Architecture(干净架构),都是极为类似的思想。除了命名不一样、切入点不一样之外,其他的整体架构都是基于一个二维的内外关系。这也说明了基于DDD的架构最终的形态都是类似的。Herberto Graca有一个很全面的图包含了绝大部分现实中的端口类,值得借鉴。
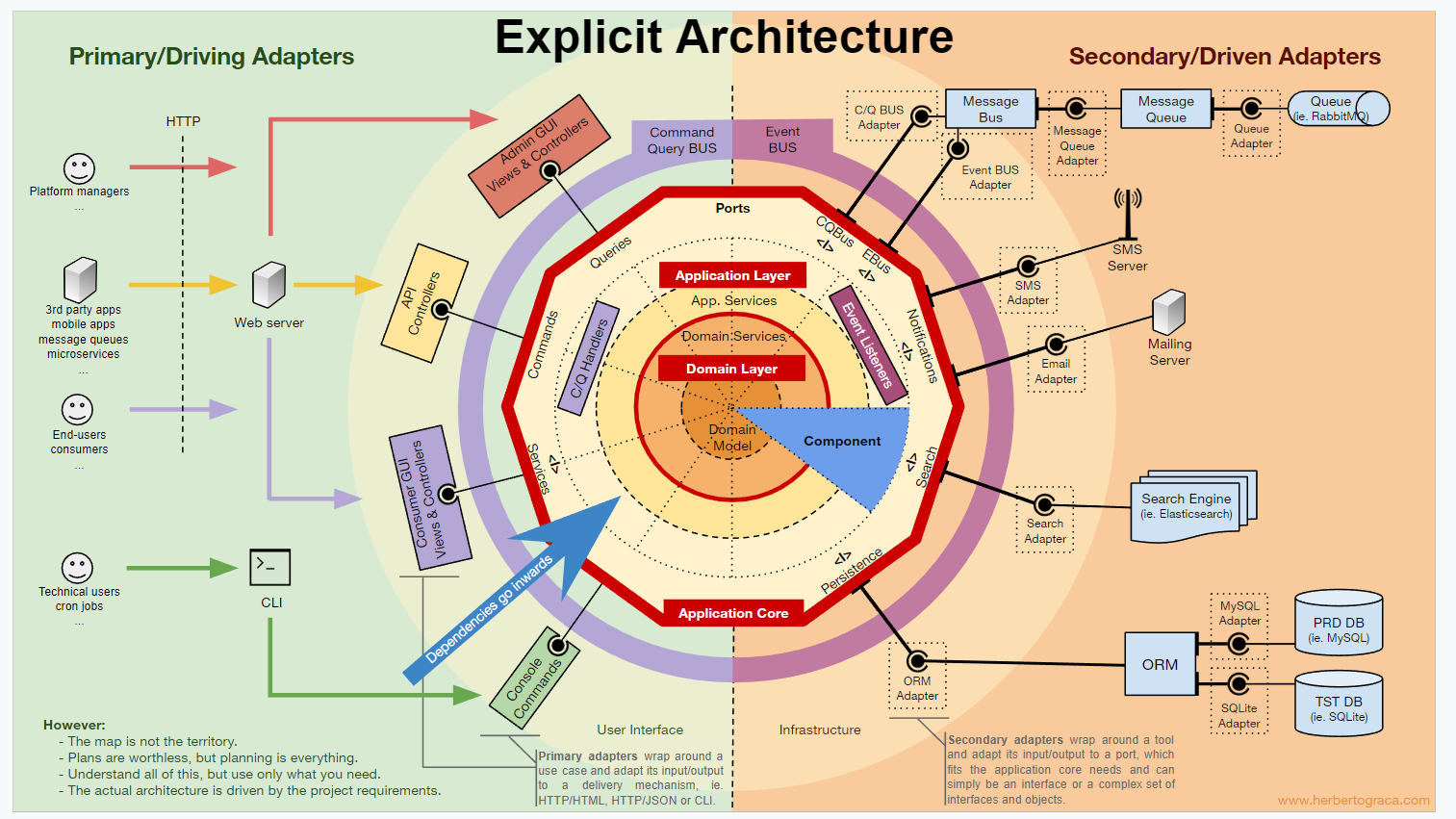
架构流程图 这里不赘述该架构图描述, 可以参考原文: https://herbertograca.com/2017/11/16/explicit-architecture-01-ddd-hexagonal-onion-clean-cqrs-how-i-put-it-all-together/
如何组织代码架构?
到目前为止, 大部分的 DDD 应用使用类似这样的架构, 比如著名的案例: https://github.com/victorsteven/food-app-server
├── application
│ ├── food_app.go
│ ├── food_app_test.go
│ ├── user_app.go
│ └── user_app_test.go
├── domain
│ ├── entity
│ └── repository
├── infrastructure
│ ├── auth
│ ├── persistence
│ └── security
├── interfaces
│ ├── fileupload
│ ├── food_handler.go- 1
这是一种 "按层分包" 的架构, 对于从 MVC 三层架构重构到 DDD 来说只是分解了 Service 层, 比较容易理解
但这是细粒度的代码隔离。粗粒度的代码隔离至少是同样重要的,它是根据子域和有界上下文来隔离代码的。我称之为 "基于业务分包".
我之前一直使用的是 "按层分包" 的结构, 现在我是 "基于业务分包" 的忠实拥护者. 在我的案例中, 我无耻的将上面的按层打包改成下面的内容
├── bill // 账单组件
│ ├── app.go
│ ├── model
│ └── repo.go
├── common // 通用工具
│ ├── logs
│ └── signals
├── servers // 通用 servers
│ ├── apps.go
│ ├── repos.go
│ ├── rpc
│ ├── servers.go
│ └── web
└── user // 用户组件
├── app.go
├── auth_repo.go
├── model
├── rate_service.go
├── repo.go
├── rpc_server.go
├── transfer_service.go
├── web_auth_middleware.go
└── web_handler.go- 1
因为在编码实践中,我们总是基于一个业务用例来实现代码,在 "按层分包" 场景下,我们需要在分散的各包中来回切换,增加了代码导航的成本;另外,代码提交的变更内容也是散落的,在查看代码提交历史时,无法直观的看出该次提交是关于什么业务功能的。在业务分包下,我们只需要在单个统一的包下修改代码,减少了代码导航成本;另外一个好处是,如果哪天我们需要将某个业务迁移到另外的项目(比如识别出了独立的微服务),那么直接整体移动业务包即可。
总结
-
抽离逻辑: 将 service 逻辑抽到 domain 类中, domain 是纯内存对象, 独立于任何外部依赖 -
抽象接口: 根据依赖反转的设计思想, 不要依赖实现, 依赖接口; 如果是三方服务, 抽象一个防腐层出来保护自己的业务
DDD 不是银弹, 它是 复杂业务 的一种设计思想. DDD 的核心在于对业务的理解, 而不是对领域模型的熟悉程度, 不要花太多时间去研究理论
如果今天的内容你只能记住一件事情, 那我希望是: 抽离逻辑, 抽象接口
案例中的代码我已经提交到了 GitHub: https://github.com/dengjiawen8955/ddd_demo
下面的代码可以快速运行案例中的项目:
# 下载项目
git clone git@github.com:dengjiawen8955/ddd_demo.git && cd ddd_demo
# 准备环境 (启动mysql, redis)
docker-compose up -d
# 准备数据库 (创建数据库, 创建表)
make exec.sql
# 启动项目
make- 1
思考题
也许你听说过 "要做好微服务先做好 DDD" 这样类似的话, 因为 DDD 是指导微服务拆分的重要思想
通过上面的代码, 如果你想要拆分这个案例为微服务, 你会怎样拆分呢?
reference
本文由 mdnice 多平台发布
-
-
相关阅读:
Git服务器搭建
字节一面,面试官问我Vue3源码,我说……
JavaWeb中的VUE快速入门
Doris实践——同程数科实时数仓建设
Linux安装kafka-manager
设计模式之简单工厂模式(学习笔记)
【软考 系统架构设计师】嵌入式系统④ 嵌入式操作系统
C++字符串详解
当Serverless遇到Regionless:现状与挑战
Win10怎么快速删除超大数量文件群
- 原文地址:https://blog.csdn.net/jarvan5/article/details/127923721
