-
string的应用及模拟实现
目录
string的应用
insert函数

insert函数的作用是插入string对象或者插入字符、字符串。
我们需要牢记的使用方法是上图画红线标注的两个
我们进行实验
insert插入字符串
- void test1()
- {
- string s1("hello world");
- s1.insert(0, "bit");
- cout << s1 << endl;
- }
- int main()
- {
- test1();
- return 0;
- }
我们创建一个类对象s1,用"hello wolrd”进行构造,假如我们想要在hello world的前面头插"bit",我们可以使用insert函数,第一个参数0表示我们要在第一个元素前面进行插入,第二个参数"bit",表示我们要插入的字符串,我们进行打印:
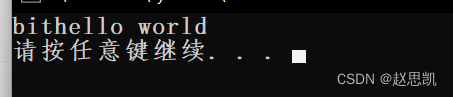
完成了头插。
insert插入string对象
- void test1()
- {
- string s1("hello world");
- string s2("bit");
- s1.insert(0, s2);
- cout << s1 << endl;
- }
- int main()
- {
- test1();
- return 0;
- }

insert函数我们需要牢记下面两种写法:


insert函数的缺点:效率太低,因为头插需要挪动数据,时间复杂度会偏高。
erase函数

erase表示删除元素,对于erase,我们只需要记住第一种使用方法即可。
erase的使用方法:
- void test2()
- {
- string s1("hello world");
- s1.erase(0, 5);
- cout << s1 << endl;
- }
erase的第一个0表示我们从第一个位置开始删除元素,第二个参数5表示我们要删除5个元素。
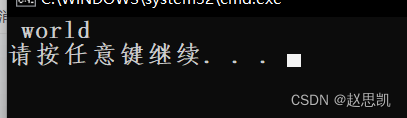
这里有一个问题:npos是什么呢?

npos这里作为缺省参数,npos的值是无符号整型的最大值,大概是42亿多,所以在不输入第二个参数的情况下,我们会删除从第一个参数开始的所有元素。
我们进行实验:
- void test2()
- {
- string s1("hello world");
- s1.erase(0);
- cout << s1 << endl;
- }
- int main()
- {
- /*test1();*/
- test2();
- return 0;
- }
假如我们的erase只有第一个参数0,表示的意思应该是从第一个元素开始删除后面的全部元素。

我们再举一个例子:
- void test2()
- {
- string s1("hello world");
- s1.erase(5);
- cout << s1 << endl;
- }
- int main()
- {
- /*test1();*/
- test2();
- return 0;
- }
这里表示我们删除从第五个元素开始,之后的全部元素,所以打印的结果应该是hello

假如我们的第二个参数大于对象的元素个数会怎么办?
- void test2()
- {
- string s1("hello world");
- s1.erase(0,30);
- cout << s1 << endl;
- }
- int main()
- {
- /*test1();*/
- test2();
- return 0;
- }
这时候,我们可以去看erase的定义。

假如对象的元素个数比我们输入的第二个参数小的情况下,我们会删除掉全部的元素。

assign函数
assign的作用是覆盖

用一个新值覆盖旧的值。
我们需要记住两种种常见的使用方法:
assign的第一种使用方法:
- void test2()
- {
- string s1("hello world");
- /*s1.erase(0,30);
- cout << s1 << endl;*/
- s1.assign("zsk");
- cout << s1 << endl;
- }
- int main()
- {
- /*test1();*/
- test2();
- return 0;
- }
这里表示用zsk来覆盖hello world。
assign的第二种使用方法:
- void test2()
- {
- string s1("hello world");
- /*s1.erase(0,30);
- cout << s1 << endl;*/
- s1.assign("zskkkkkkkkkkkkkkkkkkkk",10,9);
- cout << s1 << endl;
- }
- int main()
- {
- /*test1();*/
- test2();
- return 0;
- }
这里表示用从zskkkkkkk...的第十个元素开始,取9个元素赋值给s1。

assign还有很多其他的写法,例如:

这些函数不需要记住,我们查阅资料会使用即可。
replac函数:

替代string的一部分。

replace的一种使用方法:
- void test3()
- {
- string s1("hello world");
- s1.replace(6, 5, "bit");
- cout << s1 << endl;
- }
- int main()
- {
- /*test1();*/
- test3();
- return 0;
- }
表示我们从用"bit"覆盖从第六个元素开始的五个元素。

find

find函数的作用是找string对象的内容。
find的使用方法
我们用一道算法题来引入find的使用方法。

对于这样的对象s1,我们使用方法把所有的' '也就是空格替换成为%20.
用写这道算法题,我们需要先了解find函数的返回值

返回匹配到的第一个元素的位置,如果没有匹配,就返回npos(无符号整型的最大值)
- void test4()
- {
- string s1("hello world hello world");
- size_t pos = s1.find(" ");
- while (pos != string::npos)
- {
- s1.replace(pos, 1, "%20");
- pos = s1.find(" ", pos + 3);
- }
- cout << s1 << endl;
- }
- int main()
- {
- /*test1();*/
- test4();
- return 0;
- }
我们创建一个对象s1,我们用无符号整型pos来接收find第一个找到的' '所对应的下标,假如没有找到的时候,我们就不对对象s1进行处理,假如找到了,我们使用replace,把从pos位置开始的第一个元素替换成为"%20".然后我们需要对pos的位置进行移动,%20有三个字符,我们用pos来接收find函数从pos+3的位置开始找,第一个' '的位置,如此循环,直到所有的空格都被找到并进行了替换,

但是这里的底层逻辑是通过移动空格后面所有的元素来空出位置来添加%20,所以运行的效率是不够高的,假如我们想要有更高的效率怎么办呢?
我们可以以空间来换取时间
- void test4()
- {
- string s1("hello world hello world");
- string ret;
- for (auto e : s1)
- {
- if (e != ' ')
- {
- ret += e;
- }
- else
- {
- ret += "%20";
- }
- }
- cout << ret << endl;
- }
我们创建一个string对象ret,使用auto for循环来遍历对象s1,当s1对应的元素不为' '时,我们就+=该元素,假如为' ',我们就+="%20"

为了防止我们频繁扩容产生问题,我们可以在创建对象时,对需要的空间进行初始化
ret.reserve(s1.size());表示我们的ret的所要开辟的空间和对象s1的空间相同,接下来,即使我们要扩容,扩容的次数也会大大减小。
c_str

我们的string的底层实现逻辑就像一个顺序表。

这里的c_str我们可以理解为指针,该指针指向动态开辟的元素的地址。
substr

该函数的作用是:取出字符串的一部分来构建新的string对象。
我们举一个例子:假如我们输入一个文件,我们想要输出文件的后缀
我们该怎么操作呢?
- void test_string1()
- {
- string file;
- cin >> file;
- size_t pos = file.find(".");
- if (pos != string::npos)
- {
- string suffix = file.substr(pos, file.size() - pos);
- cout << suffix << endl;
- }
- }
- int main()
- {
- test_string1();
- return 0;
- }
我们首先创建一个对象,我们输入对象的内容,假如我们输入的test.cpp,然后我们使用string的find函数:

我们使用这个find函数,第一个参数是我们要找的对象名,第二个参数是我们从哪一个元素对应的下标开始找,第二个参数的缺省值是0,就是我们不写的时候,默认从第一个参数开始找。
这里表示我们从file对象的第一个元素开始找,直到找到'.'为止,然后返回'.'对应的下标。
这个时候我们就找到了'.'的位置,接下来,我们打印出'.'后面的内容即可。
但是我们不仅要打印,我们还要把这部分后缀放到一个新的string对象中。
接下来,我们调用substr函数:

substr函数的作用是从string对象的pos位置开始取len个字符并返回新的string对象

第一个参数pos的缺省值为0,第二个参数len的缺省值为npos,也就是size_t类型的最大值。
我们要从pos位置开始,取size()-pos个元素放到新的string对象suffix中。

因为substr函数的第二个参数缺省值为npos,所以这里我们可以不写第二个参数
- void test_string1()
- {
- string file;
- cin >> file;
- size_t pos = file.find('.');
- if (pos != string::npos)
- {
- string suffix = file.substr(pos);
- cout << suffix << endl;
- }
- }
- int main()
- {
- test_string1();
- return 0;
- }

但是假如出现这种情况


我们前面的就是压缩文件,我们求出的后缀是.tar,其他的我们都不需要处理。
我们可以从后往前进行寻找,然后找到第一个'.',然后substr对剩下的元素进行处理。
rfind

相当于从后往前查找字符串内容。
- void test_string1()
- {
- string file;
- cin >> file;
- size_t pos = file.rfind('.');
- if (pos != string::npos)
- {
- string suffix = file.substr(pos);
- cout << suffix << endl;
- }
- }
- int main()
- {
- test_string1();
- return 0;
- }
我们进行运行:

find_first_of(+字符串)
表示从一个string对象找第一个出现的字符串中的元素。
例如:
- void test_string1()
- {
- string s1 = "woshihelashdasijdf";
- size_t found = s1.find_first_of("aeiou");
- while (found != string::npos)
- {
- s1[found] = '*';
- found = s1.find_first_of("aeiou", found + 1);
- }
- cout << s1 << endl;
- }
- int main()
- {
- test_string1();
- return 0;
- }
我们首先创建一个string对象s1,s1中是一些字符串,我们的目的是把这些字符串中出现'aeiou'这些元音字母转换为'*'。
我们先使用find_first_of函数:
这里表示我们从s1中进行查找,当找到aeiou中任意一个元素时停下,返回s1中对应元素的下标。
然后我们使用while循环,循环的终止条件是found等于npos
我们把s1[found]置为*,我们更新found,使用find_first_of从下一个元素开始查找元音字母。
调用函数完毕后,我们打印s1.
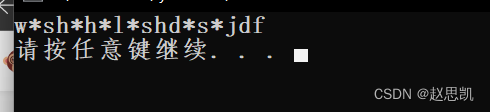
接下来,让我们来看一下比大小函数。
operator ==
这里的比较是使用ASCII码来进行比较的。

这个函数有三种调用形式,接下来我们看看后两种有什么区别?


第一个函数调用的是1,第二个函数调用的是2.
这个operator函数是严格按照参数来进行匹配的。
string的leetcode题目
有了rfind,我们很轻松就可以解决这个问题:我们从后往前找第一个空格对应的下标,我们用总元素下标的个数减去1即可。
我们进行尝试:

这里却报错了,原因是什么呢?
原因是回车和' '在是多项输入的间隔,这两个标志就决定了空格之后和之前的并不是同一个元素,那我们怎么解决呢?
我们可以使用getline函数。
getline

这样只有回车能够表示不同元素之间的间隔,空格并不能够表示。
- int main() {
- string str;
- getline(cin,str);
- size_t pos=str.rfind(' ');
- cout<
- return 0;
- }
这样写就可以编译通过了。
验证回文串

- class Solution {
- public:
- bool isPalindrome(string s) {
- string tmp;
- for(auto ch:s)
- {
- if(isdigit(ch)||islower(ch))
- {
- tmp+=ch;
- }
- else if(isupper(ch))
- {
- tmp+=(ch+32);
- }
- }
- int i=0;
- int j=tmp.size()-1;
- while(i{if(tmp[i]!=tmp[j]){return false;}i++;j--;}return true;}};
我们的思路是以空间换取时间的方法:首先,首先,遍历对象s,把数组元素和小写字母放到临时对象tmp中,再把大写字母转换为小写字母放到数组中,注意:大写字母+32等于小写字母。
然后我们使用前后指针的方法来判断tmp是否是回文字符串即可。
string的模拟实现:
- namespace bit
- {
- class string
- {
- public:
- string(const char*str)
- {
- }
- private:
- char* _str;
- size_t _size;
- size_t _capacity;
- };
- }
我们知道,string的成员变量和我们之前设计的顺序表十分接近,我们首先来实现构造函数
构造函数
- string(const char*str)
- {
- _size = strlen(str);
- _capacity = _size;
- _str = new char[_capacity + 1];
- strcpy(_str, str);
- }
我们需要把字符串str的元素个数,容量,元素内容进行拷贝,并且还要开辟足够的空间。
我们首先处理元素个数,strlen(str)表示求字符串的元素个数(不包括\0)
再处理容量,容量我们可以和_size取相同的值。
当我们需要开辟空间的时候,需要多开辟一个空间,用来存放\0。
接下来,我们调用strcpy字符串拷贝函数:

这个函数是把source指向的字符串拷贝到destination指向的字符串。
注意事项:这个拷贝函数也会把字符串末尾的\0也拷贝进去,所以不需要我们手动添加\0.
为了避免溢出,我们首先要保证目的地的空间能够存储下来源的字符串的全部元素。
并且来源和目的地不能在内存中有重叠部分。
这里就表示把我们的字符串str拷贝到了我们的构造出来的string对象中。
我们进行检验:
- namespace bit
- {
- class string
- {
- public:
- string(const char*str)
- {
- _size = strlen(str);
- _capacity = _size;
- _str = new char[_capacity + 1];
- strcpy(_str, str);
- }
- private:
- char* _str;
- size_t _size;
- size_t _capacity;
- };
- void test_string1()
- {
- string s1("hello world");
- }
- }
- #include"string.h"
- int main()
- {
- bit::test_string1();
- return 0;
- }

我们成功完成了string的拷贝构造的实现。
实现c_str

c_str就等效于这个string对象,也就是说通过c_str能够访问到这个string对象。
- const char*c_str()
- {
- return _str;
- }
用const修饰的原因是我们这个函数只是返回对象指针,并不需要修改,加上const防止修改。
_str是string对象的指针。
_size的实现:
- size_t size()
- {
- return _size;
- }
我们进行检测:


[]的实现:
- char&operator[](size_t pos)
- {
- assert(pos<_size);
- return _str[pos];
- }
参数是pos,返回值类型是char类型,但是我们需要能对[pos]对应的位置进行修改,所以使用引用。
为了防止越界访问,我们对pos进行断言。
然后返回_str[pos]即可。
我们进行检验:
- void test_string1()
- {
- string s1("hello world");
- /*cout << s1.size() << endl;*/
- cout << s1.c_str() << endl;
- for (size_t i = 0; i < s1.size(); ++i)
- {
- s1[i]++;
- }
- cout << s1.c_str() << endl;
- }
我们对s1的每一个元素全部++。

我们实现了[]。
实现迭代器
在目前这个阶段,我们可以把迭代器当作是一个指针。
- typedef char*iterator;
- iterator begin()
- {
- return _str;
- }
- iterator end()
- {
- return _str + _size;
- }
我们的迭代器是指向字符串元素的,所以我们可以把char*重命名为iterator
接下来,我们对iterator begin函数进行定义。
我们画出string类的结构示意图

这里的_str就指向字符串首元素的指针,所以我们这里直接返回对象的_str即可。
接下来,我们对iterator end函数进行定义
_str+_size对应的就是ierator end
我们进行检测。
- void test_string1()
- {
- string s1("hello world");
- /*cout << s1.size() << endl;*/
- cout << s1.c_str() << endl;
- string::iterator it1 = s1.begin();
- while (it1 != s1.end())
- {
- (*it1)--;
- ++it1;
- }
- cout << s1.c_str() << endl;
- }
这里的iterator本质上就是char*的意思,因为我们使用了iterator当作it1的返回值类型,所以我们要使用string::,s1.begin实质上就是使用了迭代器,s1.end表示的是最后一个元素的下一个位置,也就是说我们不需要对s1.end()处的元素进行处理,当it1不等于s1.end()时,我们通过解引用来修改元素,然后将其打印出来。

我们成功实现了string的迭代器。
接下来,我们测试范围for
- void test_string1()
- {
- string s1("hello world");
- /*cout << s1.size() << endl;*/
- cout << s1.c_str() << endl;
- string::iterator it1 = s1.begin();
- while (it1 != s1.end())
- {
- (*it1)--;
- ++it1;
- }
- cout << s1.c_str() << endl;
- for (auto ch : s1)
- {
- cout << ch;
- }
- }

我们并没有对string对象的范围for进行定义,为什么还可以调用范围for函数呢?
答案就是于迭代器,当我们注释掉迭代器的定义时:
- void test_string1()
- {
- string s1("hello world");
- /*cout << s1.size() << endl;*/
- cout << s1.c_str() << endl;
- /*string::iterator it1 = s1.begin();
- while (it1 != s1.end())
- {
- (*it1)--;
- ++it1;
- }*/
- cout << s1.c_str() << endl;
- for (auto ch : s1)
- {
- cout << ch;
- }
- }
我们进行运行:

我们并没有使用迭代器,为什么这里依旧会报错,原因是范围for的本质就是通过迭代器的begin和end来进行遍历的,当我们有了迭代器,我们才能使用范围for
+=的实现
我们的+=分为两个,一个是字符的+=,一个是字符串的+=。
- string&operator+=(char ch)
- {
- push_back(ch);
- return *this;
- }
- string&operator+=(const char*str)
- {
- append(str);
- return *this;
- }
要实现这两个函数,我们还需要实现push back和append
push_back表示尾插一个字符
append表示尾插一个字符串。
但是push_back和append又涉及到扩容的问题,追加一个字符容易扩容,但追加一个字符串不容易扩容。
- void push_back(char ch)
- {
- if (_size == _capacity)
- {
- reserve(_capacity * 2);
- }
- _str[_size] = ch;
- ++_size;
- _str[_size] = '\0';
- }
当有效元素和容量相等时,就意味着我们需要扩容了,这时候,我们把容量变为原来的二倍,然后把ch放到_size的位置,注意:我们在这里不光有添加元素,也要添加'\0',所以我们让_size++,然后把对应位置的元素置为'\0'。
- void append(const char*str)
- {
- size_t len = strlen(str);
- if (_size + len > _capacity)
- {
- reserve(_capacity = _size + len + 1);
- }
- for (int i = 0; i < strlen(str) + 1; i++)
- {
- *this += str[i];
- }
- }
我们的append可以这样实现,首先求出str的有效元素个数为len,如果str和*this的有效元素加起来大于*this的容量时,我们设置*this的容量为str和*this的有效元素相加再加1,原因是我们还需要预留\0。
然后我们使用for循环,使用之前的+=函数,让*this+=str的全部元素(\0也要加),就完成了append
接下来,我们来实现reserve函数
reserve函数的实现:
reserve函数的意思是设置容量大小。
我们的思路是这样的:与其在原位置增加容量,我们不如新开辟一个空间,然后使用strcpy把原空间的元素放到新空间,释放掉原空间,然后把新空间的地址赋给_str,把容量设置为所需容量即可。
- void reserve(size_t n)
- {
- char*tmp = new char[n + 1];
- strcpy(tmp, _str);
- delete[] _str;
- _str = tmp;
- _capacity = n;
- }
因为我们这里需要为\0留位置,所以我们多申请一个char类型的空间,tmp指向这块空间,然后把原空间的元素拷贝到新空间,释放掉原空间,把新空间的地址赋给_str,然后把容量置为n即可。
我们测试+=字符
- void test_string1()
- {
- string s1("hello world");
- /*cout << s1.size() << endl;*/
- /*cout << s1.c_str() << endl;
- string::iterator it1 = s1.begin();
- while (it1 != s1.end())
- {
- (*it1)--;
- ++it1;
- }
- cout << s1.c_str() << endl;
- for (auto ch : s1)
- {
- cout << ch;
- }*/
- /*s1 += 'z';*/
- s1 += 'c';
- cout << s1.c_str() << endl;
- }

我们+=一个字符串
- void test_string1()
- {
- string s1("hello world");
- /*cout << s1.size() << endl;*/
- /*cout << s1.c_str() << endl;
- string::iterator it1 = s1.begin();
- while (it1 != s1.end())
- {
- (*it1)--;
- ++it1;
- }
- cout << s1.c_str() << endl;
- for (auto ch : s1)
- {
- cout << ch;
- }*/
- /*s1 += 'z';*/
- s1 += "ch";
- cout << s1.c_str() << endl;
- }

- 相关阅读:
【K8S系列】Service基础入门
数字货币回测准备:下载与清洗全量历史数据
多组试验时正态分布标准差估计公式
基于JAVA旅行网的设计与实现计算机毕业设计源码+数据库+lw文档+系统+部署
PAT 甲级 A1087 All Roads Lead to Rome
互融云人行二代征信系统对接服务
栈和队列的应用 —— 链栈
0.o?让我看看怎么个事儿之SpringBoot自动配置
基于STM32 CubeMX利用RTC实现带温湿度模块的万年历
logback--进阶--04--配置
- 原文地址:https://blog.csdn.net/qq_66581313/article/details/127822021
