-
java常见集合框架的区别
1.说说有哪些常见集合?
集合相关类和接口都在java.util中,主要分为3种:List(列表)、Map(映射)、Set(集)。
Java集合主要关系
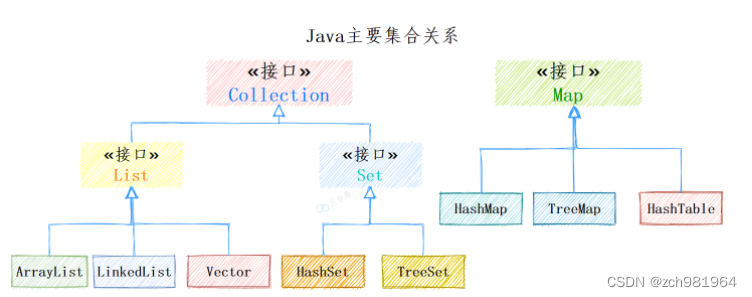
其中Collection是集合List、Set的父接口,它主要有两个子接口:List:存储的元素有序,可重复。
Set:存储的元素不无序,不可重复。
Map是另外的接口,是键值对映射结构的集合。2.ArrayList和LinkedList有什么区别?
(1)数据结构不同
ArrayList基于数组实现
LinkedList基于双向链表实现
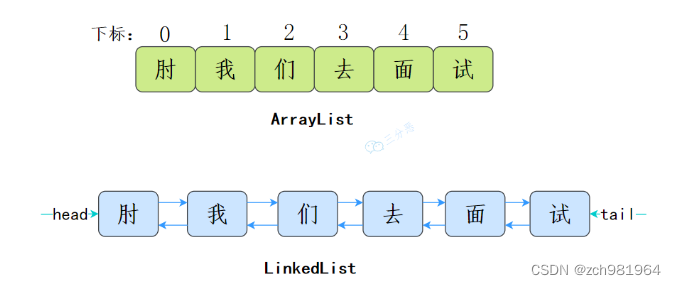
(2) 多数情况下,ArrayList更利于查找,LinkedList更利于增删ArrayList基于数组实现,get(int index)可以直接通过数组下标获取,时间复杂度是O(1);LinkedList基于链表实现,get(int index)需要遍历链表,时间复杂度是O(n);当然,get(E element)这种查找,两种集合都需要遍历,时间复杂度都是O(n)。
ArrayList增删如果是数组末尾的位置,直接插入或者删除就可以了,但是如果插入中间的位置,就需要把插入位置后的元素都向前或者向后移动,甚至还有可能触发扩容;双向链表的插入和删除只需要改变前驱节点、后继节点和插入节点的指向就行了,不需要移动元素。
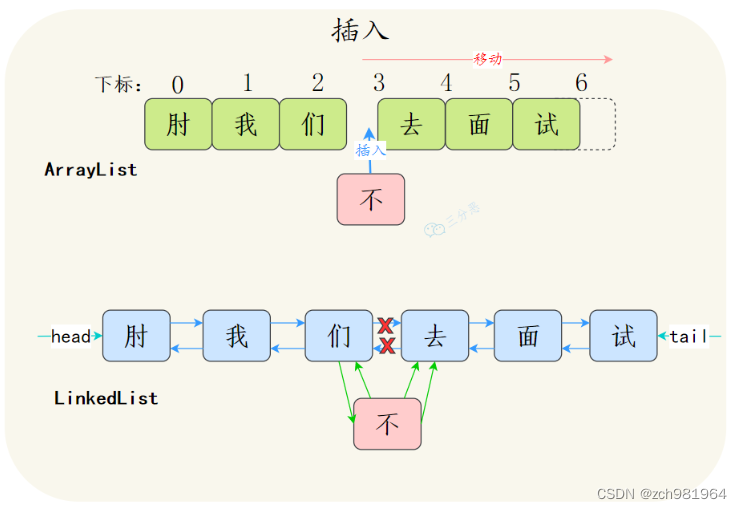
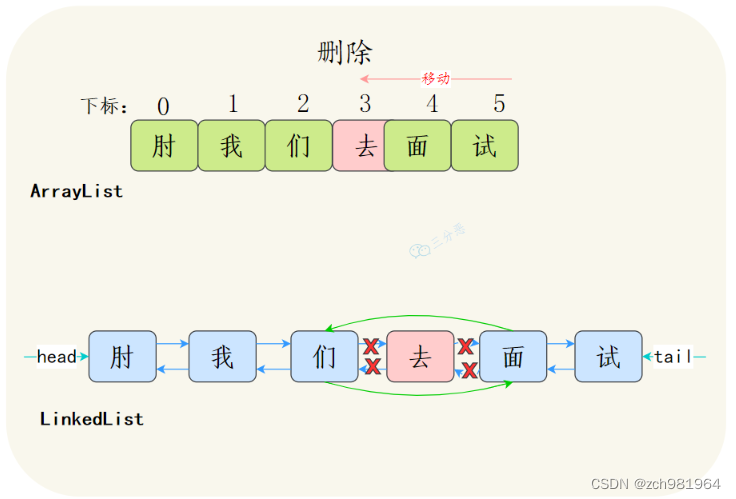 注意,这个地方可能会出陷阱,LinkedList更利于增删更多是体现在平均步长上,不是体现在时间复杂度上,二者增删的时间复杂度都是O(n)
注意,这个地方可能会出陷阱,LinkedList更利于增删更多是体现在平均步长上,不是体现在时间复杂度上,二者增删的时间复杂度都是O(n)**(3)**是否支持随机访问
ArrayList基于数组,所以它可以根据下标查找,支持随机访问,当然,它也实现了RandmoAccess 接口,这个接口只是用来标识是否支持随机访问。
LinkedList基于链表,所以它没法根据序号直接获取元素,它没有实现RandmoAccess 接口,标记不支持随机访问。
**(4)**内存占用,ArrayList基于数组,是一块连续的内存空间,LinkedList基于链表,内存空间不连续,它们在空间占用上都有一些额外的消耗:ArrayList是预先定义好的数组,可能会有空的内存空间,存在一定空间浪费
LinkedList每个节点,需要存储前驱和后继,所以每个节点会占用更多的空间#3.ArrayList的扩容机制了解吗?
ArrayList是基于数组的集合,数组的容量是在定义的时候确定的,如果数组满了,再插入,就会数组溢出。所以在插入时候,会先检查是否需要扩容,如果当前容量+1超过数组长度,就会进行扩容。ArrayList的扩容是创建一个1.5倍的新数组,然后把原数组的值拷贝过去。

4.ArrayList怎么序列化的知道吗? 为什么用transient修饰数组?
ArrayList的序列化不太一样,它使用transient修饰存储元素的elementData的数组,transient关键字的作用是让被修饰的成员属性不被序列化。为什么最ArrayList不直接序列化元素数组呢?
出于效率的考虑,数组可能长度100,但实际只用了50,剩下的50不用其实不用序列化,这样可以提高序列化和反序列化的效率,还可以节省内存空间。
那ArrayList怎么序列化呢?
ArrayList通过两个方法readObject、writeObject自定义序列化和反序列化策略,实际直接使用两个流ObjectOutputStream和ObjectInputStream来进行序列化和反序列化。
5.快速失败(fail-fast)和安全失败(fail-safe)了解吗?
快速失败(fail—fast):快速失败是Java集合的一种错误检测机制在用迭代器遍历一个集合对象时,如果线程A遍历过程中,线程B对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
注意:这里异常的抛出条件是检测到 modCount!=expectedmodCount 这个条件。如果集合发生变化时修改modCount值刚好又设置为了expectedmodCount值,则异常不会抛出。因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的bug。
场景:java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改),比如ArrayList 类。
安全失败(fail—safe)采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发Concurrent Modification Exception。
缺点:基于拷贝内容的优点是避免了Concurrent Modification Exception,但同样地,迭代器并不能访问到修改后的内容,即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
场景:java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改,比如CopyOnWriteArrayList类。6.有哪几种实现ArrayList线程安全的方法?
fail-fast是一种可能触发的机制,实际上,ArrayList的线程安全仍然没有保证,一般,保证ArrayList的线程安全可以通过这些方案:使用 Vector 代替 ArrayList。(不推荐,Vector是一个历史遗留类)
使用 Collections.synchronizedList 包装 ArrayList,然后操作包装后的 list。
使用 CopyOnWriteArrayList 代替 ArrayList。
在使用 ArrayList 时,应用程序通过同步机制去控制 ArrayList 的读写。#7.CopyOnWriteArrayList了解多少?
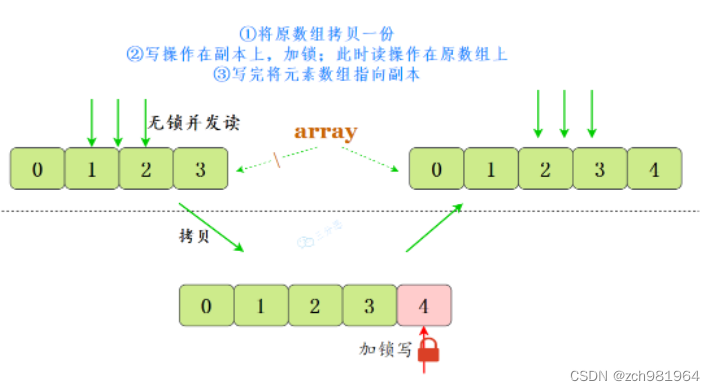
CopyOnWriteArrayList就是线程安全版本的ArrayList。它的名字叫CopyOnWrite——写时复制,已经明示了它的原理。
CopyOnWriteArrayList采用了一种读写分离的并发策略。CopyOnWriteArrayList容器允许并发读,读操作是无锁的,性能较高。至于写操作,比如向容器中添加一个元素,则首先将当前容器复制一份,然后在新副本上执行写操作,结束之后再将原容器的引用指向新容器。
8.能说一下HashMap的数据结构吗?
JDK1.7的数据结构是数组+链表,JDK1.7还有人在用?不会吧……说一下JDK1.8的数据结构吧:
JDK1.8的数据结构是数组+链表+红黑树。
数据结构示意图如下:

其中,桶数组是用来存储数据元素,链表是用来解决冲突,红黑树是为了提高查询的效率。
数据元素通过映射关系,也就是散列函数,映射到桶数组对应索引的位置
如果发生冲突,从冲突的位置拉一个链表,插入冲突的元素
如果链表长度>8&数组大小>=64,链表转为红黑树
如果红黑树节点个数<6 ,转为链表#9.你对红黑树了解多少?为什么不用二叉树/平衡树呢?
红黑树本质上是一种二叉查找树,为了保持平衡,它又在二叉查找树的基础上增加了一些规则:每个节点要么是红色,要么是黑色;
根节点永远是黑色的;
所有的叶子节点都是是黑色的(注意这里说叶子节点其实是图中的 NULL 节点);
每个红色节点的两个子节点一定都是黑色;
从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;

之所以不用二叉树:红黑树是一种平衡的二叉树,插入、删除、查找的最坏时间复杂度都为 O(logn),避免了二叉树最坏情况下的O(n)时间复杂度。
之所以不用平衡二叉树:
平衡二叉树是比红黑树更严格的平衡树,为了保持保持平衡,需要旋转的次数更多,也就是说平衡二叉树保持平衡的效率更低,所以平衡二叉树插入和删除的效率比红黑树要低。
#10.红黑树怎么保持平衡的知道吗?
红黑树有两种方式保持平衡:旋转和染色。旋转:旋转分为两种,左旋和右旋

染⾊:

11.HashMap的put流程知道吗?
先上个流程图吧:
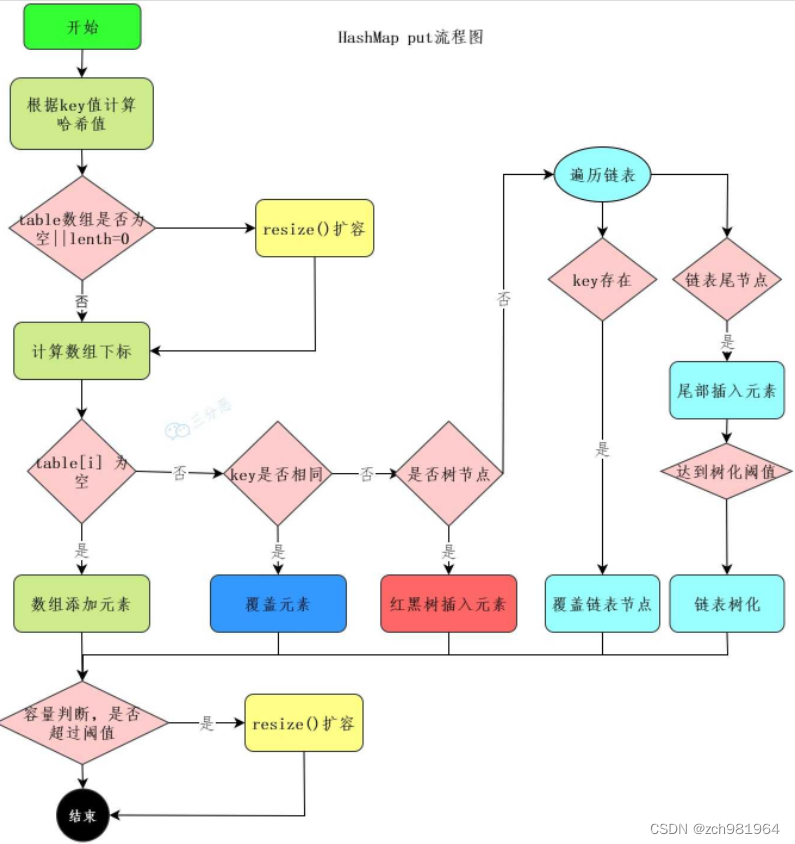
1、首先进行哈希值的扰动,获取一个新的哈希值。(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);2、判断tab是否位空或者长度为0,如果是则进行扩容操作。
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;- 1
- 2
3、根据哈希值计算下标,如果对应小标正好没有存放数据,则直接插入即可否则需要覆盖。tab[i = (n - 1) & hash])
4、判断tab[i]是否为树节点,否则向链表中插入数据,是则向树中插入节点。
5、如果链表中插入节点的时候,链表长度大于等于8,则需要把链表转换为红黑树。treeifyBin(tab, hash);
6、最后所有元素处理完成后,判断是否超过阈值;threshold,超过则扩容。
#12.HashMap怎么查找元素的呢?
先看流程图:
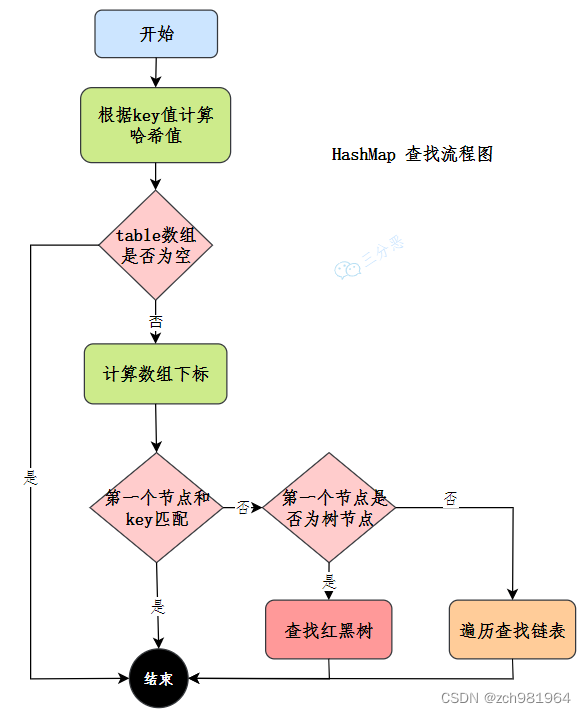
HashMap的查找就简单很多:使用扰动函数,获取新的哈希值
计算数组下标,获取节点
当前节点和key匹配,直接返回
否则,当前节点是否为树节点,查找红黑树
否则,遍历链表查找#13.HashMap的哈希/扰动函数是怎么设计的?
HashMap的哈希函数是先拿到 key 的hashcode,是一个32位的int类型的数值,然后让hashcode的高16位和低16位进行异或操作。
static final int hash(Object key) { int h; // key的hashCode和key的hashCode右移16位做异或运算 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }- 1
- 2
- 3
- 4
- 5
这么设计是为了降低哈希碰撞的概率。
14.为什么HashMap的容量是2的倍数呢?
第一个原因是为了方便哈希取余:
将元素放在table数组上面,是用hash值%数组大小定位位置,而HashMap是用hash值&(数组大小-1),却能和前面达到一样的效果,这就得益于HashMap的大小是2的倍数,2的倍数意味着该数的二进制位只有一位为1,而该数-1就可以得到二进制位上1变成0,后面的0变成1,再通过&运算,就可以得到和%一样的效果,并且位运算比%的效率高得多HashMap的容量是2的n次幂时,(n-1)的2进制也就是1111111***111这样形式的,这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞。
第二个方面是在扩容时,利用扩容后的大小也是2的倍数,将已经产生hash碰撞的元素完美的转移到新的table中去
我们可以简单看看HashMap的扩容机制,HashMap中的元素在超过负载因子*HashMap大小时就会产生扩容。19.为什么HashMap链表转红黑树的阈值为8呢?
树化发生在table数组的长度大于64,且链表的长度大于8的时候。为什么是8呢?源码的注释也给出了答案。
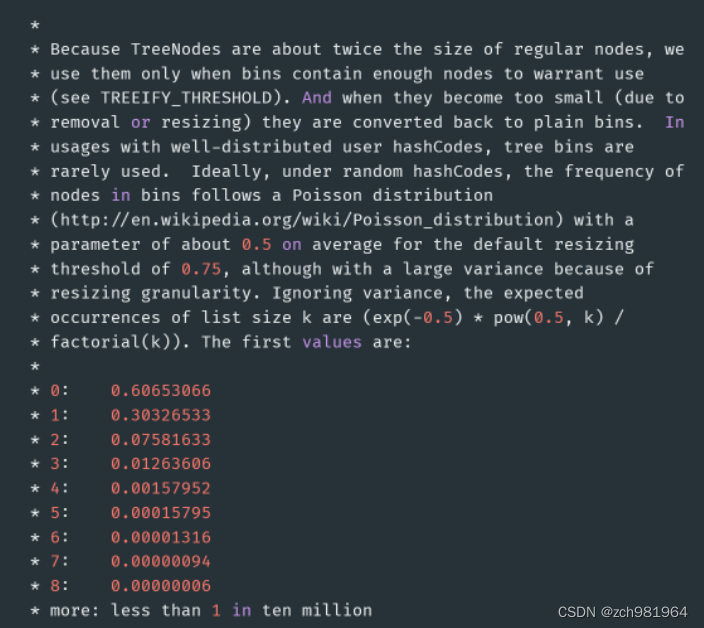 红黑树节点的大小大概是普通节点大小的两倍,所以转红黑树,牺牲了空间换时间,更多的是一种兜底的策略,保证极端情况下的查找效率。
红黑树节点的大小大概是普通节点大小的两倍,所以转红黑树,牺牲了空间换时间,更多的是一种兜底的策略,保证极端情况下的查找效率。阈值为什么要选8呢?和统计学有关。理想情况下,使用随机哈希码,链表里的节点符合泊松分布,出现节点个数的概率是递减的,节点个数为8的情况,发生概率仅为0.00000006。
至于红黑树转回链表的阈值为什么是6,而不是8?是因为如果这个阈值也设置成8,假如发生碰撞,节点增减刚好在8附近,会发生链表和红黑树的不断转换,导致资源浪费。
以下是整理了java基础的相关书籍。旨在帮助那些没有经验或者经验有限的初学者,少走弯路,利用有限的精力,更加高效地学习。由于个人时间有限,暂时整理,后续会持续更新,全是干货,欢迎关注! (访问密码:6798)
- 《码出高效:Java开发手册》.pdf: https://url31.ctfile.com/f/40632231-724721889-4db527?
- Java编程思想第4版.pdf: https://url31.ctfile.com/f/40632231-724721969-fc428d?
- Java 8实战.pdf:https://url31.ctfile.com/f/40632231-724721962-d0969a?
- Java编程思想第4版.pdf:https://url31.ctfile.com/f/40632231-724721969-fc428d
- Java并发编程的艺术.pdf: https://url31.ctfile.com/f/40632231-724721980-748069?
- JAVA并发编程实践.pdf: https://url31.ctfile.com/f/40632231-724722012-47e74b?
- Java从小白到大牛精简版.pdf: https://url31.ctfile.com/f/40632231-724722020-a71a79?
- Java高并发编程详解.pdf: https://url31.ctfile.com/f/40632231-724722133-f60a69?
- Java核心技术 卷Ⅰ 基础知识(第8版).pdf: https://url31.ctfile.com/f/40632231-724722186-aa396a?
- Java核心技术 卷Ⅰ 基础知识(第8版).pdf: https://url31.ctfile.com/f/40632231-724722186-aa396a?
- JAVA核心知识点整理.pdf: https://url31.ctfile.com/f/40632231-724722290-3c7f6d?
- 阿里巴巴Java开发手册v1.2.0.pdf: https://url31.ctfile.com/f/40632231-724722295-6f37ac?
- 分布式Java应用基础与实践.pdf: https://url31.ctfile.com/f/40632231-724722338-385ff7?
- 深入理解Java虚拟机:JVM高级特性与最佳实践(最新第二版).pdf: https://url31.ctfile.com/f/40632231-724722394-093ff9?
-
相关阅读:
2022年最新河北建筑八大员(机械员)模拟考试题库及答案
C++学习 --pair
JSD-2204-Vue-ElementUI-Day06
概率DP—练习
mysql分区表的增删改查操作
【图像融合】基于matlab粒子群优化自适应多光谱图像融合【含Matlab源码 004期】
足疗APP
【线性代数】二次型总结
手把手教你分析MySQL查询性能瓶颈,包教包会
(附源码)计算机毕业设计SSM精品旅游项目管理系统
- 原文地址:https://blog.csdn.net/zch981964/article/details/127902361