-
Pytorch框架基础
目录
1-02张量的简介与创建
张量是一个 ,它是标量,向量,矩阵的高维拓展

pytorch中的Tensor
在pytorch中的属性主要有8个

data:张量的数据类型,如torch.FloatTensor,torch.cuda.FloatTensor
shape:张量的形状
devcie:张量所在设备,如GPU/CPU
张量的创建
1:直接创建
Torch.tensor(data,dtype=None,device=None,requires_grad=False,pin_memory=False)
各参数解释

从numpy创建tensor
torch.form_numpy(ndarray).
从torch.form_numpy(ndarray)创建的tensor与原ndarray共享内存,当修改其中的一个数据另一也会被改动。
2:依据数值创建
torch.zero(*size,out=None,dtype=None,layout=torch.stride,required_grad=False)

torch.zeros_like(input,dtype=None,layout=None,required_grad=False):功能是根据input形状创建全0张量
创建全1张量,只需要将上述的zeros替换成ones即可。
创建自定义数值的张量分别为:torch.full()和torch.full_like().比如torch.full((3,3),10) 为创建一个3*3的值为10的张量。
创建等差的一维张量:torch.arange()--比如torch.arange(2,10,2).则创建的一维张量为[2,4,6,8]
创建均分的一维张量:torch.linspace(2,10,5)创建的一维张量为([2,4,6,8,10])使用这个函数的步长为[strat-end]/steps-1
3:依据概率分布创建张量
生成正态分布:torch.normal(mean,std,out=None).mean为均值,std为标准1
生成标准正态分布:torch.randn(),torch.randn_like()生成一个均值为0,标准差为1的标准正态分布。
torch.rand(),torch.rand_like()在区间[0,1]上生成均匀分布
torch.randint();torch.randint_like()在区间[low,high]生成整数均匀分布。
1-03张量的操作
1. 拼接
torch.cat():将张量按维度dim进行拼接
torch.stack():在新创建的维度dim上进行拼接
两者的区别在于,cat()是在原有的张量的维度上进行拼接,不会拓展张量的维度。stack()是在新创建的维度上,如果选择的维度已经存在,那原有的维度往后移。
这两个函数的主要参数都是:tensors:张量序列 dim:要拼接的维度。
2.张量的拼接与切分
torch.chunk():将张量按维度dim进行平均切分,返回值为张量列表。(若不能整除,最后一份张量小于其他张量)input:要切分的张量,Chunks要切分的份数。Dim要切分的维度。
torch.split():按照张量指定的维度进行切分。Tensor:要切分的张量。Split_size_or_sections:为int时,表示每一份的长度,为list时,按list中元素切分,也就是切分得到张量中个数和list的元素对应。Dim:要切分的维度。
3.张量索引
torch.index_select():在维度dim上,按照index索引数据。返回值是依照index索引数据拼接的张量。 Input:要索引的张量。Dim:索引的维度。Index:要索引的序号
Torch.masked_select() :按mask中True进行索引。 返回值为一维张量。 Input:要索引的张量。Mask:与input同形状的布尔类型张量。
4.张量变换
Torch.reshape() :变换张量形状。注意:当张量在内存中连续时,新张量与input共享数据内存(一改全改)。 Input:要变换的张量。 Shape:新张量的形状。
Torch.transpose() :交换张量的两个维度。 Input:要变换的张量。 Dim0:要交换的维度。Dim1:要交换的维度
Torch.t() :2维张量转置,对矩阵而言等价于torch.transpose(input,0,1)
Torch.squeeze() :压缩长度为1的维度(轴) dim:若为None,移除所有长度为1的轴,若指定维度当且仅当该轴长度为1时可以被移除。(当且仅当指定的轴长度为1时才会被移除)
Torch.unsqueeze() 依据dim扩展维度,dim:扩展的维度。(扩展的维度的轴的长度为1)
1-04计算图与动态图机制
计算图是用来描述运算的有向无环图,计算图主要有两个主要元素:结点和表。结点表示数据,如向量,矩阵,张量。边表示运算,如加减乘除卷积等。
动态图:运算与搭建同时进行。灵活,易调节
静态图:先搭建图,后运算。高效,不灵活
叶子结点:用户创建的结点称为叶子结点,如x与w
1-05自动求导和Logist回归
1:Autograd:自动求导系统
torch.autograd.backward:自动求导梯度
torch.autograd.grad 求取梯度 这里进行高阶求导时,需要在低阶中 torch.autograd.grad(y,x,create_graph=True)#create_graph=True这里是创建导数的计算图。
注意1)在autograd中梯度不自动清0
2)依赖于叶子结点的结点,requires_grad默认为True3)叶子结点不可执行in-place
2:Logist回归
逻辑回归模型是线性的二分类模型
机器学习模型训练步骤: 数据 模型 损失函数 优化器
2-01DataLoader和Dataset
机器学习学习模型训练包括五大步骤:数据,模型,损失函数,优化器,迭代训练
数据模块包括:1)数据收集:img;label 2)数据划分train训练模型,valid验证模型是否过拟合,test用于测试性能 3.)数据读取:DataLoader 4)数据预处理:transforms
其中DataLodaer还会继续细分为Sampler和DataSet,其中Sampler的功能是生成索引(也就是样本的序号),而Dataset是根据索引去读取图片以及其标签
DataLoader
torch.utils.data.Dataloader构建可迭代的数据装载器
常用参数:
dataset,batchsize,num_works,shuffle,drop_last

注意:
Epoch:所有训练样本都已输入到模型中
Iteration:一批样本输入到模型中
Batchsize:批大小,决定一个Epoch有多少个Iteration
DataSet

其中返回的这个样本包括数据和其对应标签。主要通过__getitem__()来读取数据
整体流程可以用下图表示:
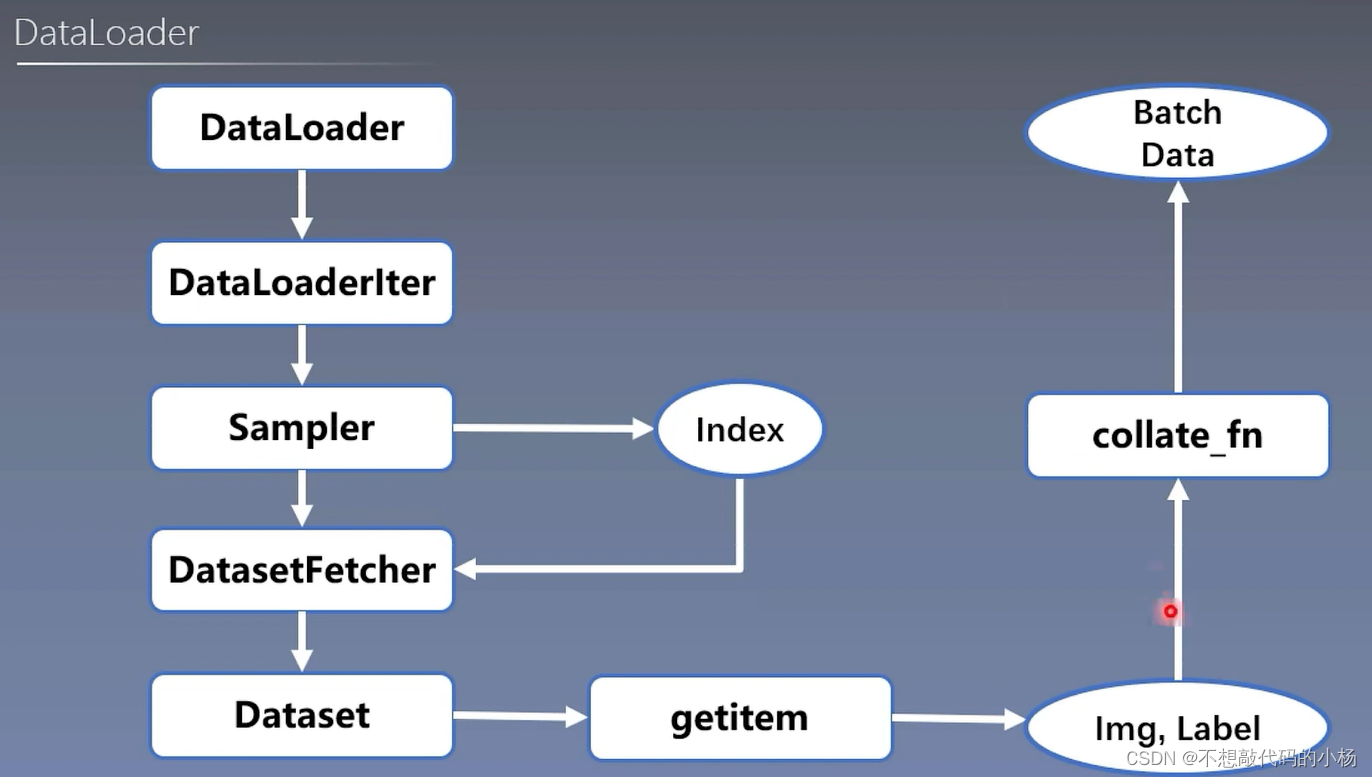
首先在For循环中使用DataLoader,经过DataLoader之后会经过DataLoaderlter来判断是否使用多进程,之后会使用Sampler来获取index,拿到索引之后将索引送入DatasetFetcher。在DatasetFetcher中会调用Dataset。在Dataset中getitem根据先前给定的索引获取单个实际的数据和标签。在获取完一个Batchsize大小的数据后通过Collate_fn进行整理,整理成一个BatchData的形式,然后就输入到模型之中去训练。
2-02Transforms与normalize
1:transforms运行机制
torchvision是计算机视觉工具包,主要包括以下三个部分:

常见的数据预处理方法包括,数据中心化,数据标准化,缩放,裁剪,旋转,翻转,填充等等。
Transform一般是加在Dataset中通过getitem获取数据之后的地方
transforms.Normalize(mean,std,inplace=False):逐通道对图像进行标准化,对模型进行标准化以后可以加快模型的收敛速度

2-03 transforms(一)
数据增强又称为数据增广,数据扩增,它是对训练级进行变换。使训练级更丰富,从而让模型更具泛化能力
transform_invert():这个函数是对transform进行逆操作,使得我们可以观察到模型输入的数据长什么样子
图像可视化:PIL.imshow(img)、PIL.show()
1. transforms.Centercrop():中心裁剪
2.transform.RandomCrop()随机裁剪尺寸为Size的图片,主要指的是随机的位置
3.RandomResizedCrop随机大小,长宽比裁剪图片
4.transforms.FiveCrop(size)在图像的上下左右及中心裁剪出尺寸为size的5张图片
5.trasforms.TenCrop()是上述处理过后得到的5张图片进行水平或者垂直镜像获得10张图片,这个函数是在第四个实现的基础上进行的。
6.transforms.RandomVerticalFlip(p=?)随机概率翻转
7.transforms.Rotation:随机旋转图片
-
相关阅读:
【vue3源码】二、vue3的响应系统分析
Android /android_vendor.32_arm64_armv8-a_shared/libtinyals a.so.abidiff报错
计算机网络 【HTTP--1】
计算机网络—网络层
SwiftFormer:基于Transformer的高效加性注意力用于实时移动视觉应用的模型
剑走偏锋:非传统问题在面试中的应对策略
【已解决】opencv 交叉编译 ffmpeg选项始终为NO
数字化时代,数据仓库是什么?有什么用?
常见的物联网协议
grid布局之容器属性grid-auto-columns&grid-auto-rows
- 原文地址:https://blog.csdn.net/weixin_43921949/article/details/127900961