-
Pytorch中的DDP
文章目录
一. 概览
- DDP的原理?
在分类上,DDP属于Data Parallel。简单来讲,就是通过提高batch size来增加并行度。 - 为什么快?
DDP通过Ring-Reduce的数据交换方法提高了通讯效率,并通过启动多个进程的方式减轻Python GIL的限制,从而提高训练速度。 - DDP有多快?
一般来说,DDP都是显著地比DP快,能达到略低于卡数的加速比(例如,四卡下加速3倍)。所以,其是目前最流行的多机多卡训练方法。
二. 使用DDP一个简单例子
2.1 依赖
PyTorch(gpu)>=1.5,python>=3.6
2.2 环境准备
推荐使用官方打好的PyTorch docker,避免乱七八糟的环境问题影响心情。
# Dockerfile # Start FROM Nvidia PyTorch image https://ngc.nvidia.com/catalog/containers/nvidia:pytorch FROM nvcr.io/nvidia/pytorch:20.03-py3- 1
- 2
- 3
2.3 代码
2.3.1 单GPU代码
## main.py文件 import torch # 构造模型 model = nn.Linear(10, 10).to(local_rank) # 前向传播 outputs = model(torch.randn(20, 10).to(rank)) labels = torch.randn(20, 10).to(rank) loss_fn = nn.MSELoss() loss_fn(outputs, labels).backward() # 后向传播 optimizer = optim.SGD(model.parameters(), lr=0.001) optimizer.step()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Bash终端运行
python main.py- 1
2.3.2 加入DDP代码
## main.py文件 import torch # 新增: import torch.distributed as dist # 新增:从外面得到local_rank参数 import argparse parser = argparse.ArgumentParser() parser.add_argument("--local_rank", default=-1) FLAGS = parser.parse_args() local_rank = FLAGS.local_rank # 新增:DDP backend初始化 torch.cuda.set_device(local_rank) dist.init_process_group(backend='nccl') # nccl是GPU设备上最快、最推荐的后端 # 构造模型 device = torch.device("cuda", local_rank) model = nn.Linear(10, 10).to(device) # 新增:构造DDP model model = DDP(model, device_ids=[local_rank], output_device=local_rank) # 前向传播 outputs = model(torch.randn(20, 10).to(rank)) labels = torch.randn(20, 10).to(rank) loss_fn = nn.MSELoss() loss_fn(outputs, labels).backward() # 后向传播 optimizer = optim.SGD(model.parameters(), lr=0.001) optimizer.step()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Bash终端运行
# 改变:使用torch.distributed.launch启动DDP模式, # 其会给main.py一个local_rank的参数。这就是之前需要"新增:从外面得到local_rank参数"的原因 python -m torch.distributed.launch --nproc_per_node 4 main.py- 1
- 2
- 3
- 4
三. 基本原理
假如我们有N张显卡,
- (缓解GIL限制)在DDP模式下,会有N个进程被启动,每个进程在一张卡上加载一个模型,这些模型的参数在数值上是相同的。
- (Ring-Reduce加速)在模型训练时,各个进程通过一种叫Ring-Reduce的方法与其他进程通讯,交换各自的梯度,从而获得所有进程的梯度;
- (实际上就是Data Parallelism)各个进程用平均后的梯度更新自己的参数,因为各个进程的初始参数、更新梯度是一致的,所以更新后的参数也是完全相同的。
3.1 DDP与DP模式的不同
DP模式是很早就出现的、单机多卡的、参数服务器架构的多卡训练模式,在PyTorch,即是:
model = torch.nn.DataParallel(model)- 1
在DP模式中,总共只有一个进程(受到GIL很强限制)。master节点相当于参数服务器,其会向其他卡广播其参数;在梯度反向传播后,各卡将梯度集中到master节点,master节点对搜集来的参数进行平均后更新参数,再将参数统一发送到其他卡上。这种参数更新方式,会导致master节点的计算任务、通讯量很重,从而导致网络阻塞,降低训练速度。但是DP也有优点,优点就是代码实现简单,实现比较方便;而DDP速度比较快,代码实现比较复杂。
四. DDP为什么能加速
4.1 Python GIL
Python GIL 最大的特征(缺点):Python GIL的存在使得,一个python进程只能利用一个CPU核心,不适合用于计算密集型的任务。
而只有使用多进程,才能有效率利用多核的计算资源。而DDP启动多进程训练,一定程度地突破了这个限制。4.2 Ring-Reduce梯度合并
Ring-Reduce是一种分布式程序的通讯方法。 因为提高通讯效率,Ring-Reduce比DP的parameter server快。其避免了master阶段的通讯阻塞现象,n个进程的耗时是o(n)。
简单说明:

- 各进程独立计算梯度。
- 每个进程将梯度依次传递给下一个进程,之后再把从上一个进程拿到的梯度传递给下一个进程。循环n次(进程数量)之后,所有进程就可以得到全部的梯度了。
- 可以看到,每个进程只跟自己上下游两个进程进行通讯,极大地缓解了参数服务器的通讯阻塞现象!
五. 并行计算
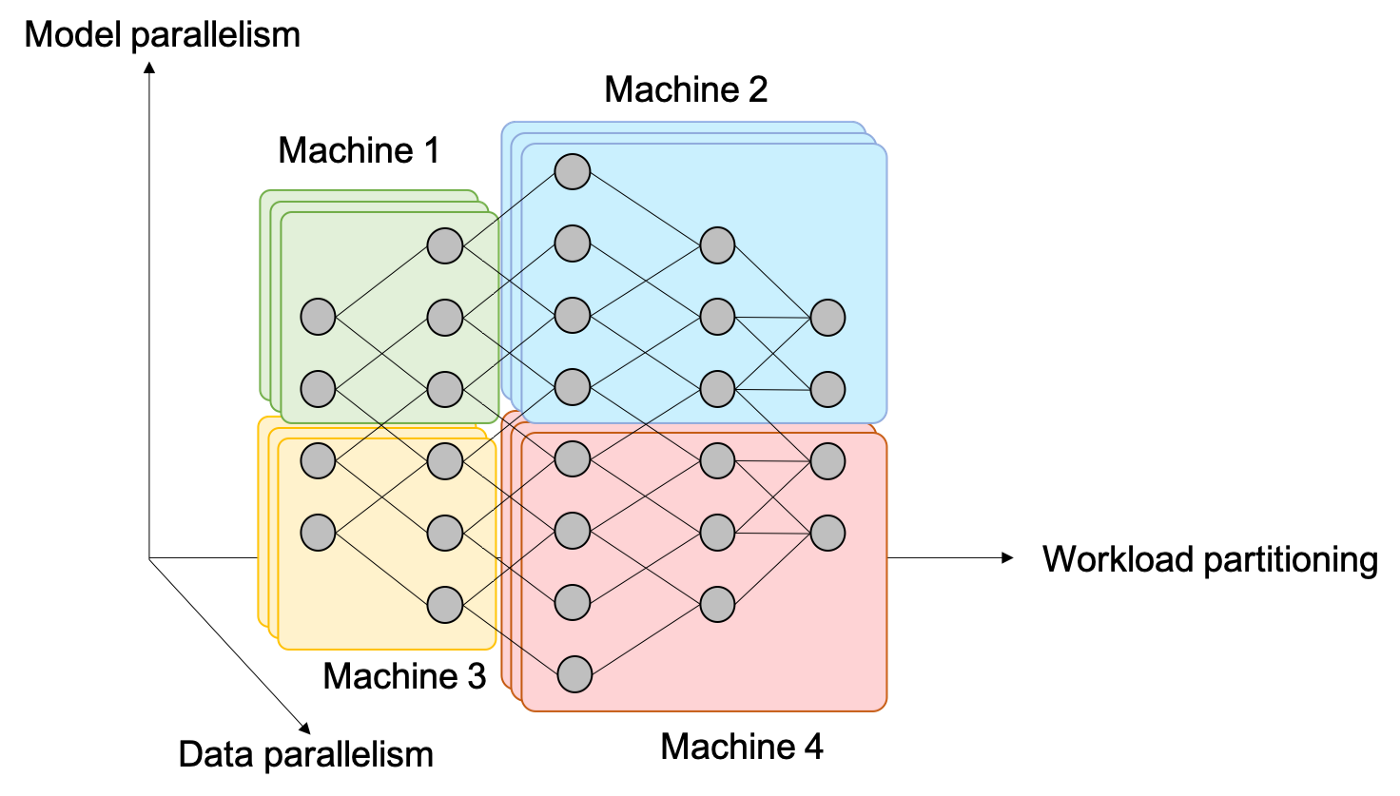
统一来讲,神经网络中的并行有以下三种形式,如下图所示:
5.1 Data Parallelism:
- 这是最常见的形式,通俗来讲,就是增大batch size。
- 平时我们看到的多卡并行就属于这种。比如DP、DDP都是。这能让我们方便地利用多卡计算资源。
- 能加速。
5.2 Model Parallelism:
- 把模型放在不同GPU上,计算是并行的。
- 有可能是加速的,看通讯效率。
5.3 Workload Partitioning:
- 把模型放在不同GPU上,但计算是串行的。
- 不能加速。
六 在PyTorch中使用DDP
DDP有不同的使用模式。DDP的官方最佳实践是,每一张卡对应一个单独的GPU模型(也就是一个进程),在下面介绍中,都会默认遵循这个pattern。
举个例子:我有两台机子,每台8张显卡,那就是2x8=16个进程,并行数是16。但是,我们也是可以给每个进程分配多张卡的。总的来说,分为以下三种情况:
- 每个进程一张卡。这是DDP的最佳使用方法。
- 每个进程多张卡,复制模式。一个模型复制在不同卡上面,每个进程都实质等同于DP模式。这样做是能跑得通的,但是,速度不如上一种方法,一般不采用。
- 每个进程多张卡,并行模式。一个模型的不同部分分布在不同的卡上面。例如,网络的前半部分在0号卡上,后半部分在1号卡上。这种场景,一般是因为我们的模型非常大,大到一张卡都塞不下batch size = 1的一个模型。
6.1 DDP基本概念
在16张显卡,16的并行数下,DDP会同时启动16个进程。下面介绍一些分布式编程的概念。
6.1.1 group
即进程组。默认情况下,只有一个组。这个可以先不管,一直用默认的就行。
6.1.2 world size
表示全局的并行数,简单来讲,就是2x8=16,跟rank总数相同(对应于程序有多少个进程启动),表示全局进程个数。
# 获取world size,在不同进程里都是一样的,得到16 torch.distributed.get_world_size()- 1
- 2
6.1.3 rank
表示当前进程的序号,用于进程间通讯。对于16的world sizel来说,就是0,1,2,…,15(对应于程序有多少个进程启动)。
注意:rank=0的进程就是master进程。也即是当前进程的序号,用于进程间的通讯。rank表示进程序号,用于进程间通讯,表征进程优先级。rank = 0 的主机为 master 节点。# 获取rank,每个进程都有自己的序号,各不相同 torch.distributed.get_rank()- 1
- 2
6.1.4 local_rank
又一个序号。这是每台机子上的进程的序号。机器一上有0,1,2,3,4,5,6,7,机器二上也有0,1,2,3,4,5,6,7,也即是当前进程对应的GPU号。
指在进程内,GPU 编号,非显式参数,由 torch.distributed.launch 内部指定。比方说, rank = 3,local_rank = 0 表示第 3 个进程内的第 1 块 GPU。# 获取local_rank。一般情况下,你需要用这个local_rank来手动设置当前模型是跑在当前机器的哪块GPU上面的。 torch.distributed.local_rank()- 1
- 2
rank是与机器个数有关,两台机器,八张卡,则rank序号范围是0-15,而local_rank是与本地机器的卡数有关,如果两台机器,分别为八张卡,则local_rank序号范围始终是0-7。
group: 进程组,通常DDP的各个进程都是在同一个进程组下。 world_size: 总的进程数量(原则上,一个进程占用一个GPU)。 rank:当前进程的序号,用于进程间通信,rank=0表示主机为master节点。 local_rank:当前进程对应的GPU号,取值为0-7。
举例 : 4台机器 (每台机器8张卡) 进行分布式训练。通过 init_process_group() 对进程组进行初始化。 初始化后 可以通过 get_world_size() 获取到 world size = 32。在该例中为32, 即有32个进程,其编号为0-31 通过 get_rank() 函数可以进行获取 在每台机器上,local rank均为0-8, 这是 local rank 与 rank 的区别, local rank 会对应到实际的 GPU ID 上。七. 使用DDP详细流程
7.1 精髓
DDP的使用非常简单,因为它不需要修改你网络的配置。其精髓只有一句话
model = DDP(model, device_ids=[local_rank], output_device=local_rank)- 1
原本的model就是你的PyTorch模型,新得到的model,就是你的DDP模型。
最重要的是,后续的模型关于前向传播、后向传播的用法,和原来完全一致!DDP把分布式训练的细节都隐藏起来了,不需要暴露给用户,非常优雅!7.2 准备工作
但是,在套model = DDP(model)之前,我们还是需要做一番准备功夫,把环境准备好的。
这里需要注意的是,我们的程序虽然会在16个进程上跑起来,但是它们跑的是同一份代码,所以在写程序的时候要处理好不同进程的关系。## main.py文件 import torch import argparse # 新增1:依赖 import torch.distributed as dist from torch.nn.parallel import DistributedDataParallel as DDP # 新增2:从外面得到local_rank参数,在调用DDP的时候,其会自动给出这个参数,后面还会介绍。所以不用考虑太多,照着抄就是了。 # argparse是python的一个系统库,用来处理命令行调用,如果不熟悉,可以稍微百度一下,很简单! parser = argparse.ArgumentParser() parser.add_argument("--local_rank", default=-1) FLAGS = parser.parse_args() local_rank = FLAGS.local_rank # 新增3:DDP backend初始化 # a.根据local_rank来设定当前使用哪块GPU torch.cuda.set_device(local_rank) # b.初始化DDP,使用默认backend(nccl)就行。如果是CPU模型运行,需要选择其他后端。 dist.init_process_group(backend='nccl') # 新增4:定义并把模型放置到单独的GPU上,需要在调用`model=DDP(model)`前做哦。 # 如果要加载模型,也必须在这里做哦。 device = torch.device("cuda", local_rank) model = nn.Linear(10, 10).to(device) # 可能的load模型... # 新增5:之后才是初始化DDP模型 model = DDP(model, device_ids=[local_rank], output_device=local_rank)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
7.3 前向与后向传播
有一个很重要的概念,就是数据的并行化。
我们知道,DDP同时起了很多个进程,但是他们用的是同一份数据,那么就会有数据上的冗余性。也就是说,平时一个epoch如果是一万份数据,现在就要变成1*16=16万份数据了。
那么,我们需要使用一个特殊的sampler,来使得各个进程上的数据各不相同,进而让一个epoch还是1万份数据。
幸福的是,DDP也帮我们做好了!my_trainset = torchvision.datasets.CIFAR10(root='./data', train=True) # 新增1:使用DistributedSampler,DDP帮我们把细节都封装起来了。用,就完事儿! # sampler的原理,后面也会介绍。 train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset) # 需要注意的是,这里的batch_size指的是每个进程下的batch_size。也就是说,总batch_size是这里的batch_size再乘以并行数(world_size)。 trainloader = torch.utils.data.DataLoader(my_trainset, batch_size=batch_size, sampler=train_sampler) for epoch in range(num_epochs): # 新增2:设置sampler的epoch,DistributedSampler需要这个来维持各个进程之间的相同随机数种子 trainloader.sampler.set_epoch(epoch) # 后面这部分,则与原来完全一致了。 for data, label in trainloader: prediction = model(data) loss = loss_fn(prediction, label) loss.backward() optimizer = optim.SGD(ddp_model.parameters(), lr=0.001) optimizer.step()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
7.4 其他需要注意的地方
- 保存参数
# 1. save模型的时候,和DP模式一样,有一个需要注意的点:保存的是model.module而不是model。 # 因为model其实是DDP model,参数是被`model=DDP(model)`包起来的。 # 2. 我只需要在进程0(多机多卡时,rank=0表示是在第一台机器第一张卡上面保存模型)上保存一次就行了,避免多次保存重复的东西。 if dist.get_rank() == 0: torch.save(model.module, "saved_model.ckpt")- 1
- 2
- 3
- 4
- 5
- 理论上,在没有buffer参数(如BN)的情况下,DDP性能和单卡Gradient Accumulation性能是完全一致的。
1. 并行度为8的DDP 等于 Gradient Accumulation Step为8的单卡
2. 速度上,DDP当然比Graident Accumulation的单卡快,但是还有加速空间;
3. 如果要对齐性能,需要确保喂进去的数据,在DDP下和在单卡Gradient Accumulation下是一致的,说起来简单,但对于复杂模型,可能是相当困难的。
八. 调用方式
DDP模型下,python源代码的调用方式和原来的不一样了。现在需要用torch.distributed.launch来启动训练。
- 分布式训练的重要参数
- –nnodes 表示有多少台机器
- –node_rank 当前是哪台机器?
- –nproc_per_node 每台机器有多少个进程?
- –master_addr 通讯的address
- –master_port 通讯的port
- 实现方式
- 我们需要在每一台机子(总共m台)上都运行一次torch.distributed.launch
- 每个torch.distributed.launch会启动n个进程,并给每个进程一个–local_rank=i的参数,这就是之前需要"新增:从外面得到local_rank参数"的原因,i表示当前进程获得的GPU的编号(如果是单机8卡,local_rank编号范围为:0-7)
- 这样我们就得到 n * m 个进程,world_size = n * m
8.1 单机模式调用
## Bash运行 # 假设我们只在一台机器上运行,可用卡数是8 python -m torch.distributed.launch --nproc_per_node 8 main.py- 1
- 2
- 3
8.2 多机模式调用
master进程就是rank=0的进程。在使用多机模式前,需要介绍两个参数:
- 通讯的address:–master_addr:也就是master进程的网络地址,默认是:127.0.0.1,只能用于单机。
- 通讯的port:–master_port,也就是master进程的一个端口,要先确认这个端口没有被其他程序占用了哦。一般情况下用默认的就行,默认是:29500。
##在每台终端机器命令行上面运行 # 假设我们在2台机器上运行,每台可用卡数是8 # 机器1终端命令行上面运行: python -m torch.distributed.launch --nnodes=2 --node_rank=0 --nproc_per_node 8 \ --master_addr $my_address --master_port $my_port main.py # 机器2终端命令行上面运行: python -m torch.distributed.launch --nnodes=2 --node_rank=1 --nproc_per_node 8 \ --master_adderss $my_address --master_port $my_port main.py- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
特别注意,在两台机器上面的运行命令的master_addr地址必须相同,都是第一台机器的地址,也即是node_rank=0的机器的地址(相当于node_rank=0的机器就是一个master 机器),端口号master_port也必须相同(也即是与node_rank=0的机器的端口号相同),并且保证所有机器的这个端口号没有被占用。同时必须保证需要先在node_rank=0的机器上面先运行这条命令,然后再在其他机器上面运行这些命令。
同时多台机器上面的CUDA,Pytorch版本号必须保证一致,不然会出现一开始通信阻塞情况,如下面问题所示。
Some NCCL operations have failed or timed out. Due to the asynchronous nature of CUDA kernels, subsequent GPU operations might run on corrupted/incomplete data. To avoid this inconsistency, we are taking the entire process down.- 1
8.3 多机多卡相关链接
Pytorch - 多机多卡极简实现(附源码)
PyTorch分布式训练简明教程
PyTorch 分布式训练实现(DP/DDP/torchrun/多机多卡)
pytorch多机多卡分布式训练8.4 小技巧
指定需要使用哪些显卡来跑试验:在DDP命令前面加上CUDA_VISIBLE_DEVICES=“4,5,6,7”
# 假设我们只用4,5,6,7号卡 CUDA_VISIBLE_DEVICES="4,5,6,7" python -m torch.distributed.launch --nproc_per_node 4 main.py # 假如我们还有另外一个实验要跑,也就是同时跑两个不同实验。 # 这时,为避免master_port冲突,我们需要指定一个新的。这里随便敲了一个。 CUDA_VISIBLE_DEVICES="4,5,6,7" python -m torch.distributed.launch --nproc_per_node 4 --master_port 53453 main.py- 1
- 2
- 3
- 4
- 5
8.5 mp.spawn调用方式
PyTorch引入了torch.multiprocessing.spawn,可以使得单卡、DDP下的外部调用一致,即不用使用torch.distributed.launch。 python main.py一句话搞定DDP模式。
给一个mp.spawn的文档:mp.spawn文档一个简单的mp.spawn的demo:
def demo_fn(rank, world_size): dist.init_process_group("nccl", rank=rank, world_size=world_size) # lots of code. ... def run_demo(demo_fn, world_size): mp.spawn(demo_fn, args=(world_size,), nprocs=world_size, join=True)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
mp.spawn与launch各有利弊:如果算法程序是提供给别人用的,那么mp.spawn更方便,因为不用解释launch的用法;但是如果是自己使用,launch更有利,因为你的内部程序会更简单,支持单卡、多卡DDP模式也更简单。
九 Pytorch中DDP相关链接(都写的很好)
PyTorch分布式训练基础–DDP使用
[原创][深度][PyTorch] DDP系列第一篇:入门教程
Pytorch 分布式使用流程
教你如何继续压榨GPU的算力十 一份关于DDP简要流程总结和一份简单的代码模板
10.1 实现DDP流程简单概括如下:
- 首先进行DDP初始化:
dist.init_process_group(backend='nccl')- 1
- 准备数据dataloader和sampler,需要在DDP初始化之后进行:
train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset)- 1
- 构造model模型:
model = model.to(local_rank)- 1
- 如果需要Load模型,则要在构造DDP模型之前,且只需要在master上加载就行了:
if dist.get_rank() == 0 and ckpt_path is not None: model.load_state_dict(torch.load(ckpt_path))- 1
- 2
- 构造DDP model 模型:
model = DDP(model, device_ids=[local_rank], output_device=local_rank)- 1
- 要在构造DDP model之后,才能用model初始化optimizer:
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)- 1
- 创建loss 函数:
loss_func = nn.CrossEntropyLoss().to(local_rank)- 1
- 网络训练,设置DDP sampler的epoch,DistributedSampler需要这个来指定shuffle方式,通过维持各个进程之间的相同随机数种子使不同进程能获得同样的shuffle效果。
trainloader.sampler.set_epoch(epoch)- 1
- 网络训练,计算loss,计算梯度,反向传播,更新lr
- 保存模型:save模型的时候,和DP模式一样,有一个需要注意的点:保存的是model.module而不是model。因为model其实是DDP model,参数是被**model=DDP(model)**包起来的。并且只需要在进程0上保存一次就行了,避免多次保存重复的东西。
if dist.get_rank() == 0: torch.save(model.module.state_dict(), "%d.ckpt" % epoch)- 1
- 2
- 终端bash命令行运行
# DDP: 使用torch.distributed.launch启动DDP模式 # 使用CUDA_VISIBLE_DEVICES,来决定使用哪些GPU # CUDA_VISIBLE_DEVICES="0,1" python -m torch.distributed.launch --nproc_per_node 2 main.py- 1
- 2
- 3
10.2 DDP代码模板
总结一下所有的代码,这份是一份能直接跑的代码(注意使用了多机多卡,单机多卡后,学习率lr也要线性扩大原来batch_size的倍数,也即是batch_size线性扩大,lr也需要线性扩大,注意需要在程序内部加上–local_rank参数,为了从外部命令行中得到local_rank的编号(每个进程需要获得的GPU编号)):
################ ## main.py文件 import argparse from tqdm import tqdm import torch import torchvision import torch.nn as nn import torch.nn.functional as F # 新增: import torch.distributed as dist from torch.nn.parallel import DistributedDataParallel as DDP ### 1. 基础模块 ### # 假设我们的模型是这个,与DDP无关 class ToyModel(nn.Module): def __init__(self): super(ToyModel, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x # 假设我们的数据是这个 def get_dataset(): transform = torchvision.transforms.Compose([ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) ]) my_trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) # DDP:使用DistributedSampler,DDP帮我们把细节都封装起来了。 # 用,就完事儿!sampler的原理,第二篇中有介绍。 train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset) # DDP:需要注意的是,这里的batch_size指的是每个进程下的batch_size。 # 也就是说,总batch_size是这里的batch_size再乘以并行数(world_size)。 trainloader = torch.utils.data.DataLoader(my_trainset, batch_size=16, num_workers=2, sampler=train_sampler) return trainloader ### 2. 初始化我们的模型、数据、各种配置 #### # DDP:从外部得到local_rank参数 parser = argparse.ArgumentParser() parser.add_argument("--local_rank", default=-1, type=int) FLAGS = parser.parse_args() local_rank = FLAGS.local_rank # DDP:DDP backend初始化 torch.cuda.set_device(local_rank) dist.init_process_group(backend='nccl') # nccl是GPU设备上最快、最推荐的后端 # 准备数据,要在DDP初始化之后进行 trainloader = get_dataset() # 构造模型 model = ToyModel().to(local_rank) # DDP: Load模型要在构造DDP模型之前,且只需要在master上加载就行了。 ckpt_path = None if dist.get_rank() == 0 and ckpt_path is not None: model.load_state_dict(torch.load(ckpt_path)) # DDP: 构造DDP model model = DDP(model, device_ids=[local_rank], output_device=local_rank) # DDP: 要在构造DDP model之后,才能用model初始化optimizer。 optimizer = torch.optim.SGD(model.parameters(), lr=0.001) # 假设我们的loss是这个 loss_func = nn.CrossEntropyLoss().to(local_rank) ### 3. 网络训练 ### model.train() iterator = tqdm(range(100)) for epoch in iterator: # DDP:设置sampler的epoch, # DistributedSampler需要这个来指定shuffle方式, # 通过维持各个进程之间的相同随机数种子使不同进程能获得同样的shuffle效果。 trainloader.sampler.set_epoch(epoch) # 后面这部分,则与原来完全一致了。 for data, label in trainloader: data, label = data.to(local_rank), label.to(local_rank) optimizer.zero_grad() prediction = model(data) loss = loss_func(prediction, label) loss.backward() iterator.desc = "loss = %0.3f" % loss optimizer.step() # DDP: # 1. save模型的时候,和DP模式一样,有一个需要注意的点:保存的是model.module而不是model。 # 因为model其实是DDP model,参数是被`model=DDP(model)`包起来的。 # 2. 只需要在进程0上保存一次就行了,避免多次保存重复的东西。 if dist.get_rank() == 0: torch.save(model.module.state_dict(), "%d.ckpt" % epoch) ################ ## Bash终端命令行运行 # DDP: 使用torch.distributed.launch启动DDP模式 # 使用CUDA_VISIBLE_DEVICES,来决定使用哪些GPU # CUDA_VISIBLE_DEVICES="0,1" python -m torch.distributed.launch --nproc_per_node 2 main.py- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
十一. 相关链接
- DDP的原理?
-
相关阅读:
如何使用CloakQuest3r获取受安全服务保护的网站真实IP地址
大模型之十二十-中英双语开源大语言模型选型
linux-review
合肥先进光源束测后台的初步设计
FPGA对EEPROM驱动控制(I2C协议)
Linux操作系统之线程
Vue的事件类型&组件中数据和事件的传递
C# App.xaml.cs的一些操作
java项目-第95期基于ssm的医院智能管理系统-java毕业设计
没晋升没加薪,这一大波刚毕业的程序员两三年后该怎么办?
- 原文地址:https://blog.csdn.net/flyingluohaipeng/article/details/127900749
