-
数据库基础 培训讲义
文章目录
- 1. 数据库概念介绍,应用场景
- 2. 关系型数据库Mysql
- a) 数据库的组成部分介绍(服务器、数据库、表、行和列)
- b) Mysql数据库安装、navicat数据库可视化管理工具安装与基本使用
- c) mysql数据类型
- d) 数据库级别操作(查看现有数据库、建库、删库、切换数据库等)
- e) 表级别操作(建表、删表、清空表格、增加删除字段等)
- f) 约束(非空、主键、外键、唯一键等约束、自增字段)
- g) 增加数据:insert 语句
- h) 查找数据:select语句
- i) 条件:where子句、逻辑运算符
- j) 限制数目:limit子句
- k) 删除数据:delete语句
- l) 更新数据:update语句
- m) 排序:order by语句
- n) 聚集函数(count、sum、max、average等)
- o) group by 语句
- p) 分组筛选:having语句
- q) 高级查询
- r) **字符串查找:like子句(选讲)
- 3. **非关系型数据库mongodb简介(选讲)
- 4. **非关系型数据库redis简介(选讲)
1. 数据库概念介绍,应用场景
引入:
淘宝网,京东、微信,抖音等都有各自的功能,那么当我们退出系统的时候,下次再访问时,为什么信息还存在?什么是数据库
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
每个数据库都有一个或多个不同的 API 用于创建,访问,管理,搜索和复制所保存的数据。
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
所以,现在我们使用关系型数据库管理系统(RDBMS)来存储和管理大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:
- 1.数据以表格的形式出现
- 2.每行为各种记录名称
- 3.每列为记录名称所对应的数据域
- 4.许多的行和列组成一张表单
- 5.若干的表单组成database
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
术语解释
- 数据库: 数据库是一些关联表的集合。
- 数据表: 表是数据的矩阵。在一个数据库中的表看起来像一个简单的电子表格。
- 列: 一列(数据元素) 包含了相同类型的数据。
- 行:一行(=元组,或记录)是一组相关的数据。
- 主键:主键是唯一的。一个数据表中只能包含一个主键。你可以使用主键来查询数据。
- 外键:外键用于关联两个表。
- 复合键:复合键(组合键)将多个列作为一个索引键,一般用于复合索引。
- 索引:使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构。类似于书籍的目录。
- 参照完整性: 参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。
2. 关系型数据库Mysql
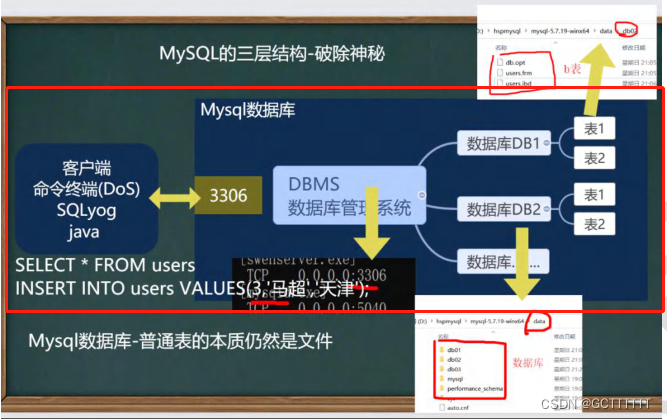
a) 数据库的组成部分介绍(服务器、数据库、表、行和列)
- 所谓安装Mysql数据库,就是在主机安装一个数据库管理系统(DBMS),这个管理程序可以管理多个数据库。DBMS(database manage system)
- 一个数据库中可以创建多个表,以保存数据(信息)。
- 数据库管理系统(DBMS)、数据库和表的关系如图所示:示意图
b) Mysql数据库安装、navicat数据库可视化管理工具安装与基本使用
Mysql安装
参考链接:https://blog.csdn.net/GCTTTTTT/article/details/121436300?spm=1001.2014.3001.5502
验证安装是否成功:
命令行窗口中输入:mysql --version
查看是否能成功显示版本号然后保证mysql服务开启:
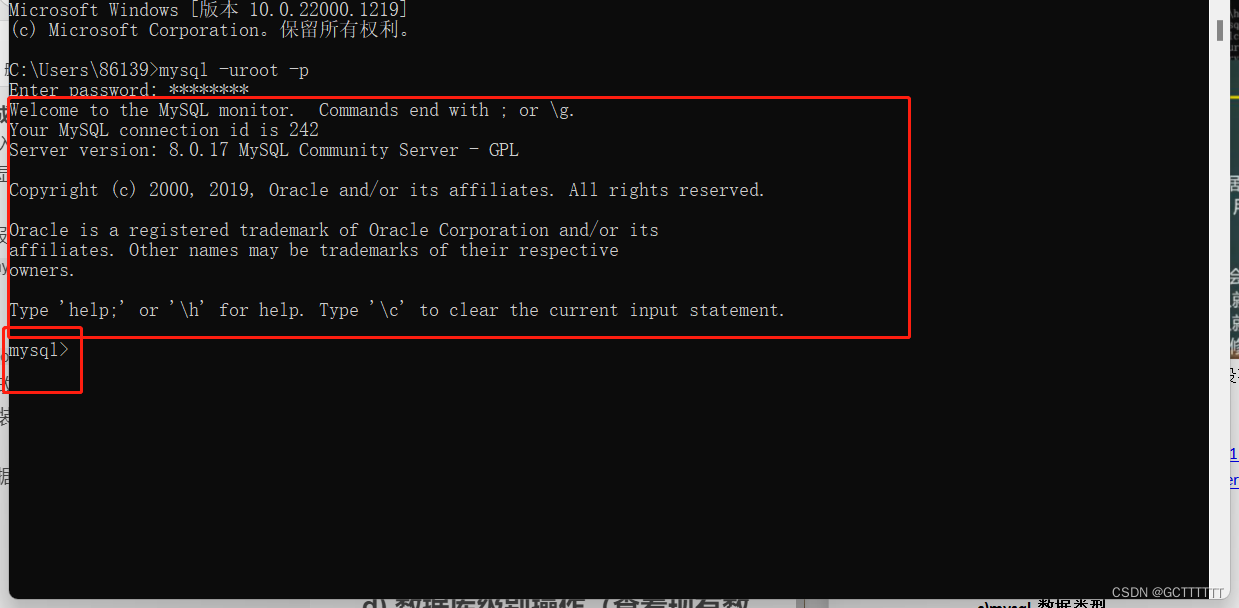
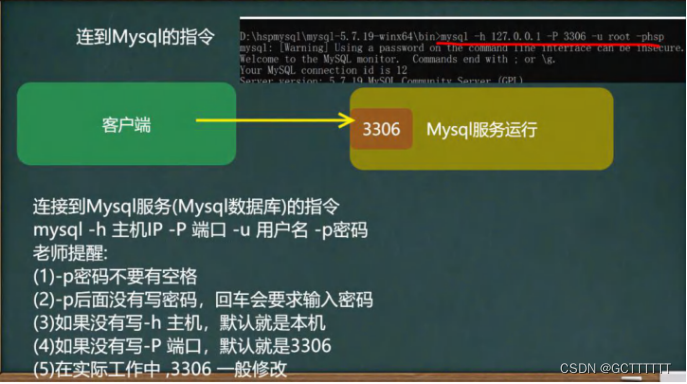
命令:net start mysql使用命令行窗口(cmd)连接mysql数据库:
命令:mysql -uroot -p
然后输入自己修改后的密码(若没有按教程修改密码,则需输入安装数据库时给的原密码)若能成功进入数据库中,则证明MySQL安装成功(如下图所示):
命令解释:
Navicat安装
安装教程:
http://fankey.blog365.cn/database/129.html
https://cloud.tencent.com/developer/article/1804255
注:官网下载navicat安装后,不按教程方法进行完整激活也可免费使用14天Navicat的基本使用
培训时会一步步教学
- Navicat连接数据库方法
- Navicat导入sql文件方法
讲解完sql相关命令后讲
- 使用Navicat操作数据库
- 使用Navicat操作数据表
- 使用Navicat操作数据表数据
c) mysql数据类型
数值类型
MySQL 支持所有标准 SQL 数值数据类型。
这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL 和 NUMERIC),以及近似数值数据类型(FLOAT、REAL 和 DOUBLE PRECISION)。
常用数值类型:
TINYINT :小整数值
SMALLINT:大整数值
MEDIUMINT:大整数值
INT或INTEGER:大整数值
BIGINT:极大整数值
FLOAT:单精度 浮点数值
DOUBLE:双精度 浮点数值
DECIMAL :小数值日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
DATETIME:YYYY-MM-DD hh:mm:ss 混合日期和时间值
DATE:YYYY-MM-DD 日期值
TIMESTAMP:YYYY-MM-DD hh:mm:ss 混合日期和时间值,时间戳
TIME:HH:MM:SS 时间值或持续时间
YEAR:YYYY 年份值字符串类型
字符串类型指CHAR、VARCHAR、TEXT、BLOB等。
CHAR:定长字符串(char(n) 和 varchar(n) 中括号中 n 代表字符的个数,比如 CHAR(30) 就可以存储 30 个字符)
VARCHAR :变长字符串
TINYBLOB:不超过 255 个字符的二进制字符串
TINYTEXT :短文本字符串
BLOB: 二进制形式的长文本数据
TEXT:长文本数据
MEDIUMBLOB:二进制形式的中等长度文本数据
MEDIUMTEXT:中等长度文本数据
LONGBLOB:二进制形式的极大文本数据
LONGTEXT:极大文本数据d) 数据库级别操作(查看现有数据库、建库、删库、切换数据库等)
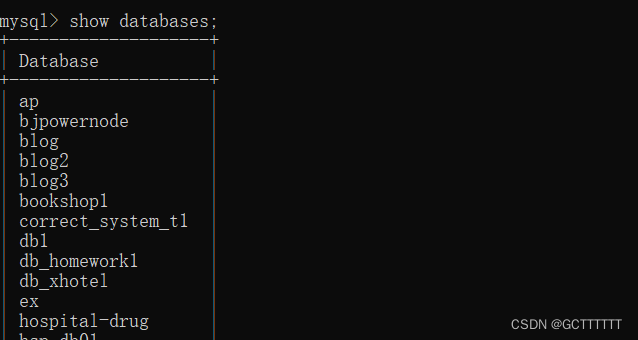
查看现有数据库
列出 MySQL 数据库管理系统的数据库列表
show databases;- 1
创建数据库
create database 数据库名;- 1

删除数据库
drop database <数据库名>;- 1

切换数据库
选择要操作的Mysql数据库,使用该命令后所有Mysql命令都只针对该数据库。
use 数据库名;- 1

显示指定数据库中的所有表
使用该命令前需要使用 use 命令来选择要操作的数据库。
show tables;- 1
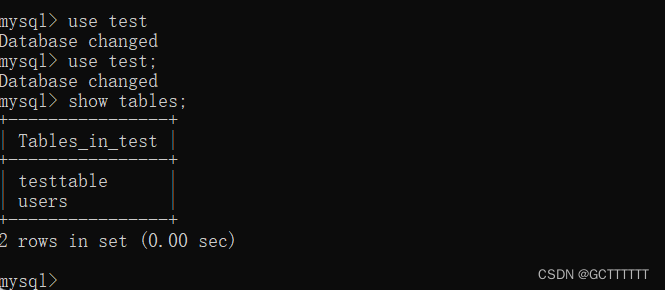
显示表结构
显示数据表的属性,属性类型,主键信息 ,是否为 NULL,默认值等其他信息
有三种命令都可以实现:
show columns from 数据表名;- 1
describe 数据表名;- 1
desc 数据表名;- 1
e) 表级别操作(建表、删表、清空表格、增加删除字段等)
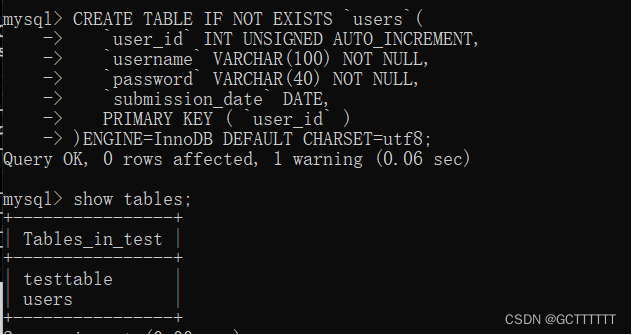
创建数据表
CREATE TABLE table_name (column_name column_type);- 1
实例解释:
CREATE TABLE IF NOT EXISTS `users`( `user_id` INT UNSIGNED AUTO_INCREMENT, `username` VARCHAR(100) NOT NULL, `password` VARCHAR(40) NOT NULL, `submission_date` DATE, PRIMARY KEY (`user_id`) )ENGINE=InnoDB DEFAULT CHARSET=utf8;- 1
- 2
- 3
- 4
- 5
- 6
- 7
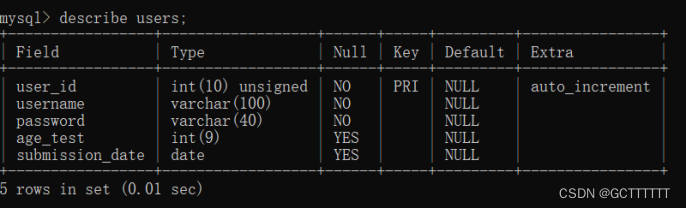
删除数据表
DROP TABLE 数据表名;- 1
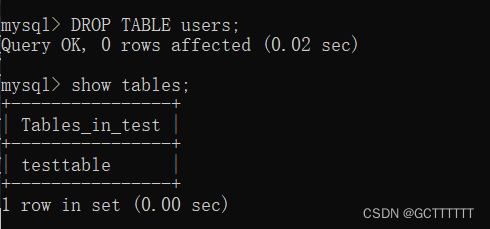
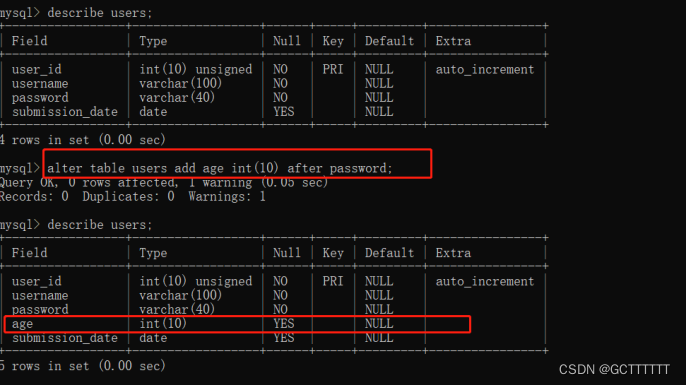
增加字段
ALTER TABLE 表名 ADD 新字段名 数据类型 [约束条件] [FIRST|AFTER 已存在字段名];- 1
实例解释:
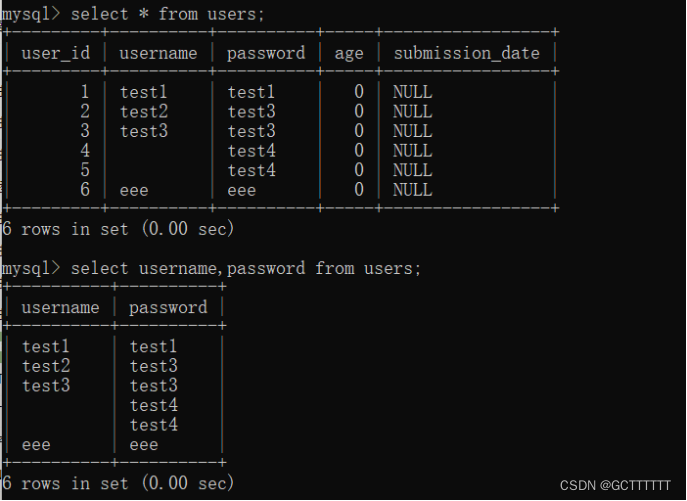
alter table users add age int(10) after password;- 1
修改字段
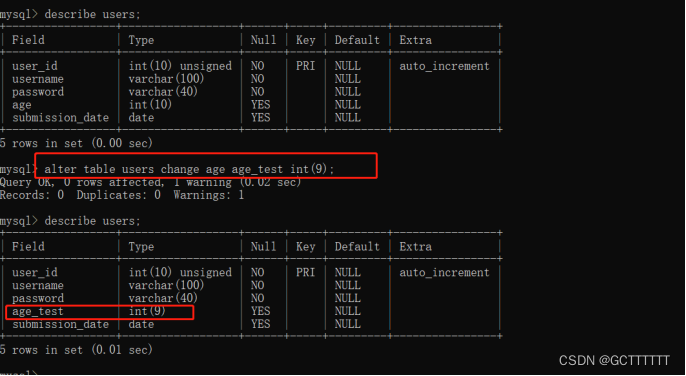
ALTER TABLE <表名> CHANGE <旧字段名> <新字段名> <新数据类型>;- 1
- 旧字段名:指修改前的字段名;
- 新字段名:指修改后的字段名;
- 新数据类型:指修改后的数据类型,如果不需要修改字段的数据类型,可以将新数据类型设置成与原来一样,但数据类型不能为空。
删除字段
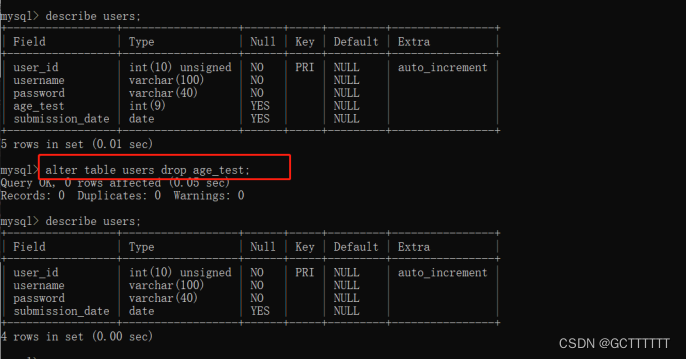
ALTER TABLE <表名> DROP <字段名>;- 1
实例:
alter table users drop age_test;- 1
其中,“字段名”指需要从表中删除的字段的名称。
清空数据表
TRUNCATE [TABLE] 数据表名;- 1
其中,TABLE 关键字可省略。
TRUNCATE 和 DELETE 的区别
从逻辑上说,TRUNCATE 语句与 DELETE 语句作用相同,但是在某些情况下,两者在使用上有所区别。-
DELETE 是 DML 类型的语句;TRUNCATE 是 DDL 类型的语句。它们都用来清空表中的数据。
-
DELETE 是逐行一条一条删除记录的;TRUNCATE则是直接删除原来的表,再重新创建一个一模一样的新表,而不是逐行删除表中的数据,执行数据比 DELETE快。因此需要删除表中全部的数据行时,尽量使用 TRUNCATE 语句, 可以缩短执行时间。
-
DELETE 删除数据后,配合事件回滚可以找回数据;TRUNCATE 不支持事务的回滚,数据删除后无法找回。
-
DELETE 删除数据后,系统不会重新设置自增字段的计数器;TRUNCATE 清空表记录后,系统会重新设置自增字段的计数器。
-
DELETE 的使用范围更广,因为它可以通过 WHERE 子句指定条件来删除部分数据;而 TRUNCATE 不支持 WHERE 子句,只能删除整体。
-
DELETE 会返回删除数据的行数,但是TRUNCATE 只会返回 0,没有任何意义。
f) 约束(非空、主键、外键、唯一键等约束、自增字段)
- 如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错。
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- PRIMARY KEY关键字用于定义列为主键。 您可以使用多列来定义主键,列间以逗号分隔。
- ENGINE 设置存储引擎,CHARSET 设置编码。
g) 增加数据:insert 语句
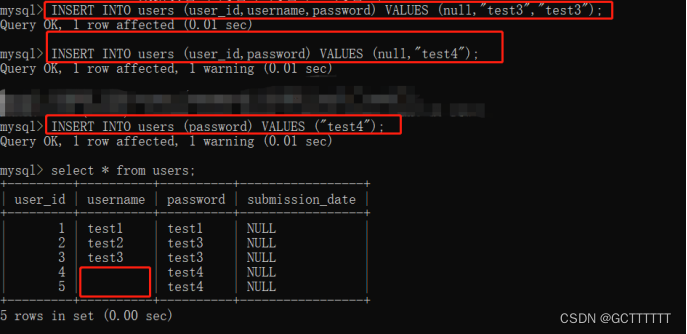
INSERT INTO 数据表名(列名1, 列名2,...列名N ) VALUES (值1, 值2,...值N );- 1
注意该SQL语句中各个列名与值为一一对应的关系,要注意以下几种情况:
- 关于默认值:当该字段为not null且insert语句中没有对该字段赋值时,会默认使用默认值:
(1)整形,我们一般使用0作为默认值。
(2)字符串,默认空字符串(“”)
(3)时间,可以默认1970-01-01 08:00:01
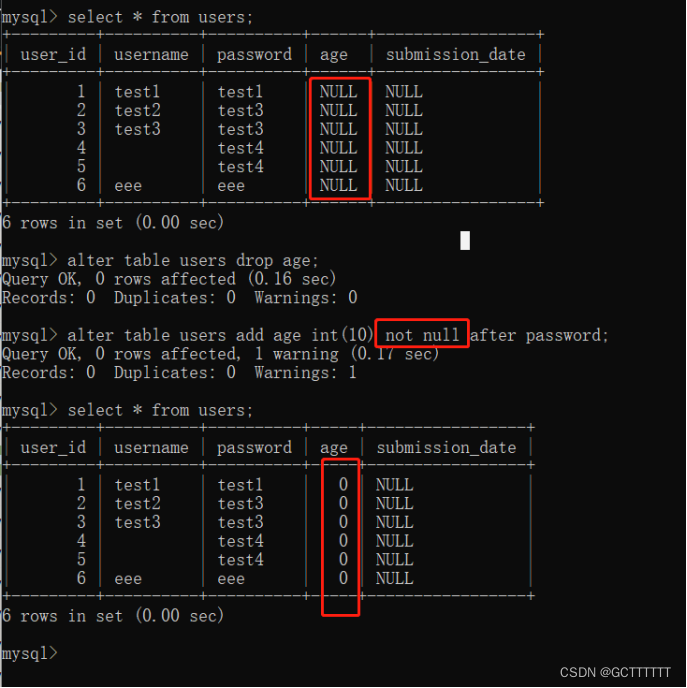
- 若主键设置了自动递增,当主键被赋值null时,该主键字段值会自动递增
- 增加数据时,当想要往每一列中都设置值,可省略命令中的列名,即使用如下命令格式:
INSERT INTO 数据表名 VALUES (值1, 值2,...值N );- 1
但注意这种情况下命令中的values括号中一定要每一列都赋值且与列名一一对应,若对应列为not null则可以为其赋默认值,若列可以为null可以赋值为null,总之若省略列名,则值需要赋完全。
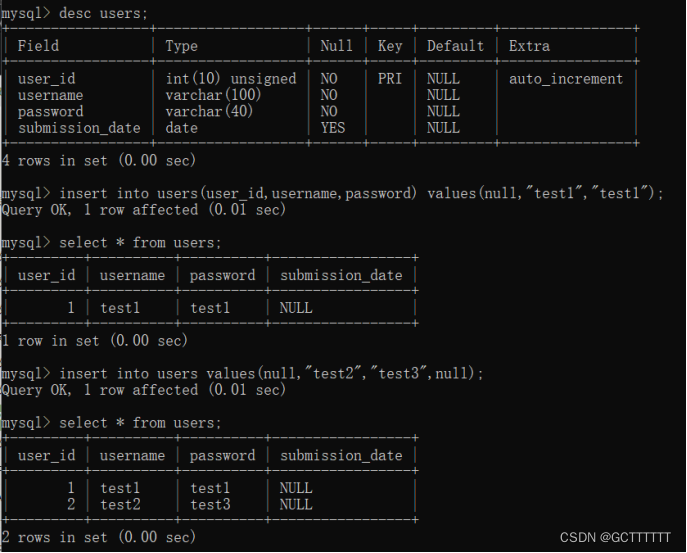
- 列名可以为数据表中一个或多个列名,同样要与values括号中值一一对应,而没有赋值的列若为not null则会被赋值为默认值,若可为null则会被赋为null
h) 查找数据:select语句
常用命令格式:
SELECT {* | <字段列名>} FROM <表 1>, <表 2>… [WHERE <表达式>]- 1
比较完整的命令格式:
中括号[]中的内容表示该内容是可选的,即按照需求选择是否使用SELECT {* | <字段列名>} FROM <表 1>, <表 2>… [WHERE <表达式>] [GROUP BY] [HAVING[{ [ORDER BY}…]] ] [LIMIT[,] ]
- 1
- 2
- 3
- 4
- 5
- 6
注意事项:
- 查询语句中你可以使用一个或者多个表,表之间使用逗号(,)分割,并使用WHERE语句来设定查询条件。
- SELECT 命令可以读取一条或者多条记录。
- 你可以使用星号(*)来代替其他字段,SELECT语句会返回表的所有字段数据
- 你可以使用 WHERE 语句来包含任何条件。
- 你可以使用 LIMIT 属性来设定返回的记录数。
实例:
查询users表中所有信息:select * from users;- 1
查询users表中username列与password列信息:
select username,password from users;- 1
i) 条件:where子句、逻辑运算符
基本命令格式:
SELECT {* | <字段列名>} FROM <表 1>, <表 2>… [WHERE <表达式>]- 1
- 查询语句中你可以使用一个或者多个表,表之间使用逗号, 分割,并使用WHERE语句来设定查询条件。
- 你可以在 WHERE 子句中指定任何条件。
- 你可以使用 AND 或者 OR 指定一个或多个条件。
- WHERE 子句也可以运用于 SQL 的 DELETE 或者 UPDATE 命令。
- WHERE 子句类似于程序语言中的 if 条件,根据 MySQL 表中的字段值来读取指定的数据。
- 使用Navicat新建数据库DB_test
- 使用Navicat导入DB_test.sql文件
实例:
j) 限制数目:limit子句
基本命令格式:
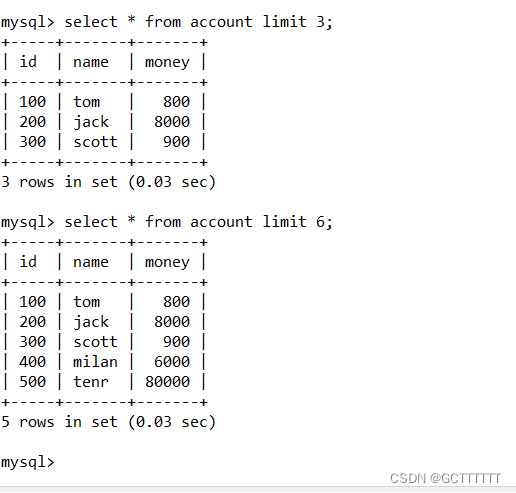
SELECT {* | <字段列名>} FROM <表 1>, <表 2>… [WHERE <表达式>] LIMIT {记录数|初始位置,记录数};- 1
实例:
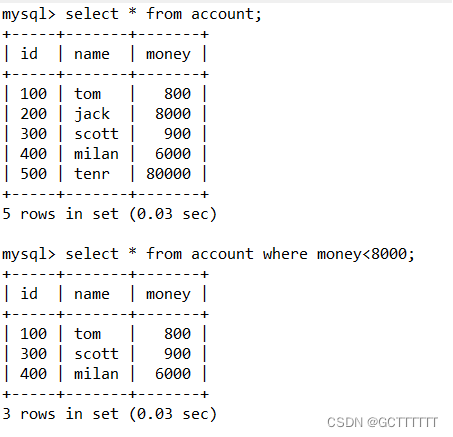
1、select * from account limit 初始位置,记录数;- 1
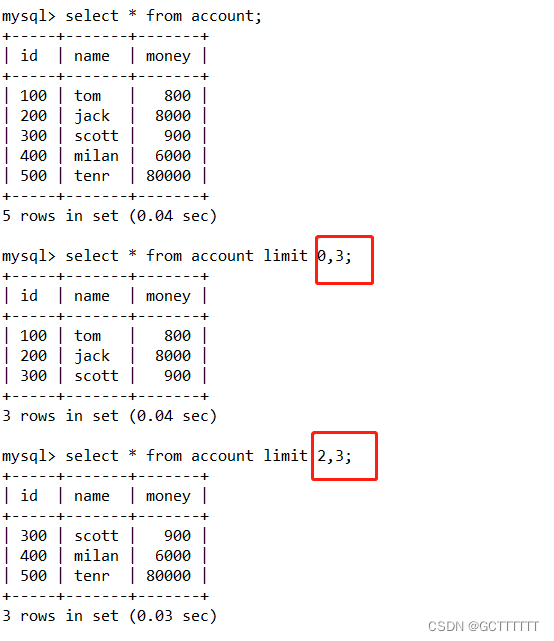
由结果可以看到,该语句返回的分别是从第1、第3条记录开始的之后的 3 条记录。LIMIT 关键字后的第一个数字0、2分别表示从第 1、3 行开始(记录的位置从 0 开始,第 1、3 行的位置为 0、2),第二个数字 3 表示返回的行数。2、
select * from account limit 记录数;- 1
如果“记录数”的值小于查询结果的总数,则会从第一条记录开始,显示指定条数的记录。如果“记录数”的值大于查询结果的总数,则会直接显示查询出来的所有记录。k) 删除数据:delete语句
DELETE FROM 数据表名 [WHERE <条件>]- 1
- 如果没有指定 WHERE 子句,MySQL 表中的所有记录将被删除。
- 你可以在 WHERE 子句中指定任何条件
- 您可以在单个表中一次性删除记录。
- 当想删除数据表中指定的记录时需要使用WHERE 子句
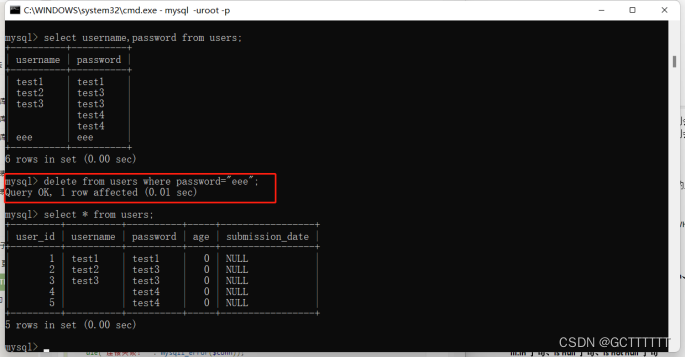
实例:
delete from users where password="eee";- 1
l) 更新数据:update语句
常用命令格式:
UPDATE <表名> SET 字段 1=值 1 [,字段 2=值 2… ] [WHERE 子句 ]- 1
较完整命令格式:
UPDATE <表名> SET 字段 1=值 1 [,字段 2=值 2… ] [WHERE 子句 ] [LIMIT 子句]- 1
- 2
- 3
- <表名>:用于指定要更新的表名称。
- SET 子句:用于指定表中要修改的列名及其列值。其中,每个指定的列值可以是表达式,也可以是该列对应的默认值。如果指定的是默认值,可用关键字 DEFAULT 表示列值。
- WHERE 子句:可选项。用于限定表中要修改的行。若不指定,则修改表中所有的行。
- LIMIT 子句:可选项。用于限定被修改的行数。
- 可以同时更新一个或多个字段。
- 可以在 WHERE 子句中指定任何条件。
- 可以在一个单独表中同时更新数据。
- 当需要更新数据表中指定行的数据时需使用WHERE 子句
实例:
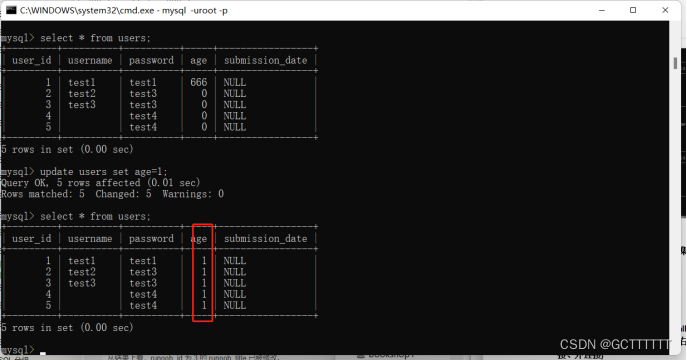
update users set age=666 where username="test1";- 1
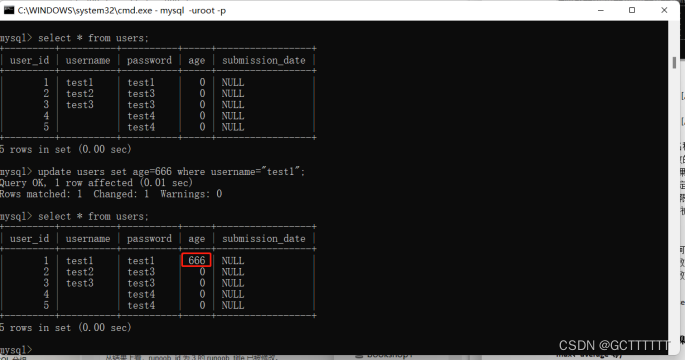
update users set age=1;- 1
m) 排序:order by语句
基本语法格式:
SELECT 列名1[,…] FROM 表名 ORDER BY <字段名> [ASC|DESC]语法说明如下:
- 字段名:表示需要排序的字段名称,多个字段时用逗号隔开。
- ASC|DESC:ASC表示字段按升序排序;DESC表示字段按降序排序。其中ASC为默认值。
使用 ORDER BY 关键字应该注意以下几个方面:
- ORDER BY 关键字后可以跟子查询
- 当排序的字段中存在空值时,ORDER BY 会将该空值作为最小值来对待。
- ORDER BY 指定多个字段进行排序时,MySQL 会按照字段的顺序从左到右依次进行排序。
单字段排序
下面通过一个具体的实例来说明当 ORDER BY 指定单个字段时,MySQL 如何对查询结果进行排序。
select * from emp order by sal;- 1
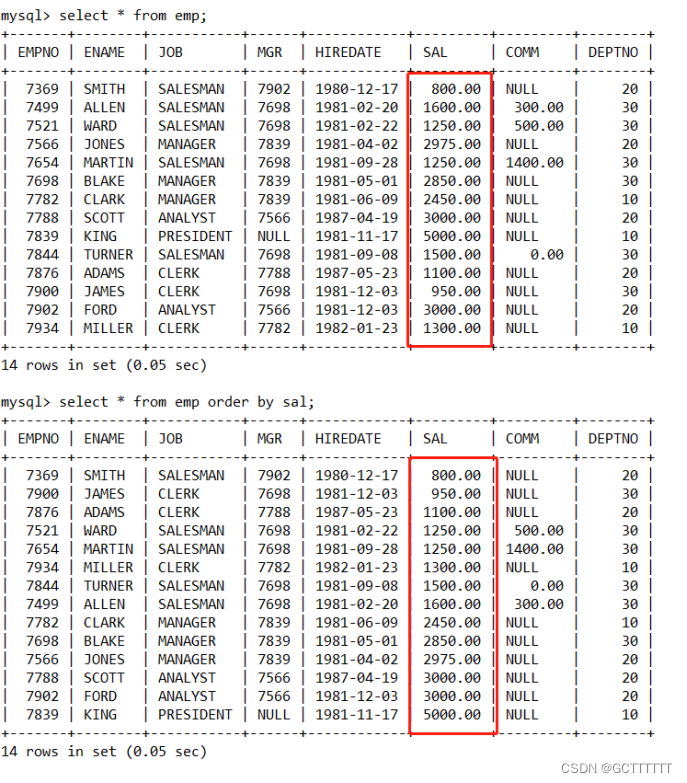
由结果可以看到,MySQL 对查询的 SAL 字段的数据按数值的大小进行了升序排序。多字段排序
下面通过一个具体的实例来说明当 ORDER BY 指定多个字段时,MySQL 如何对查询结果进行排序。
select * from emp order by sal,hiredate;- 1
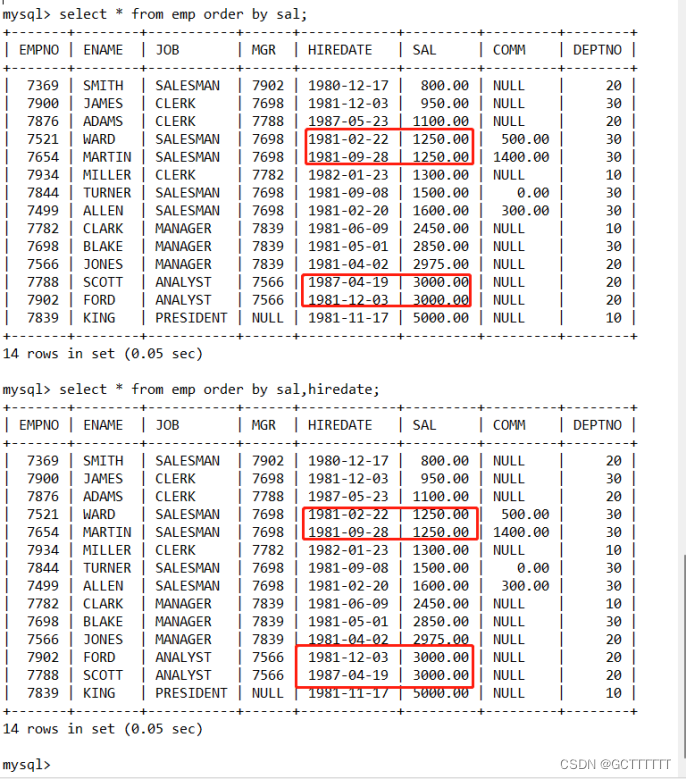
注意:在对多个字段进行排序时,排序的第一个字段必须有相同的值,才会对第二个字段进行排序。如果第一个字段数据中所有的值都是唯一的,MySQL 将不再对第二个字段进行排序。关于字母排序:
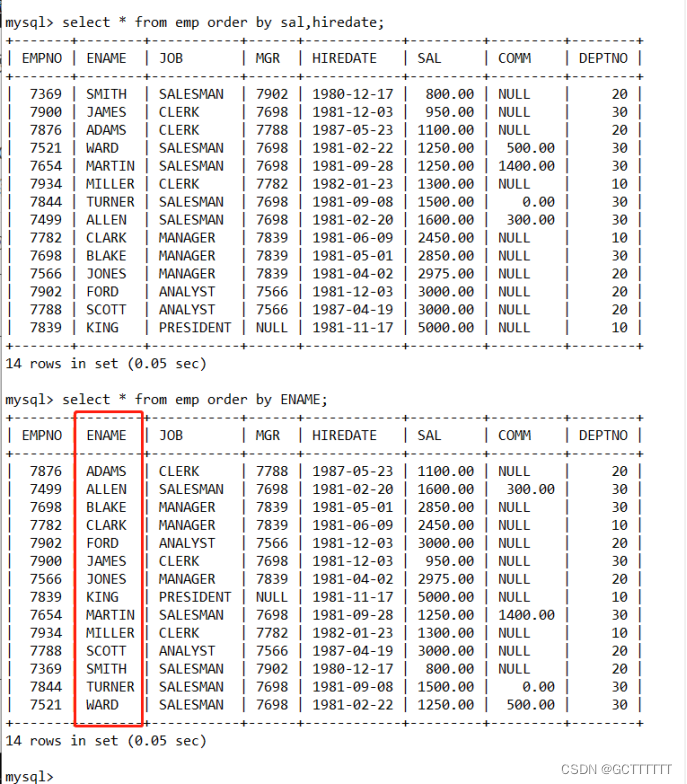
默认情况下,查询数据按字母升序进行排序(A~Z),但数据的排序并不仅限于此,还可以使用 ORDER BY 中的 DESC 对查询结果进行降序排序(Z~A)。
实例:select * from emp order by ENAME;- 1
n) 聚集函数(count、sum、max、average等)
count:
count返回符合条件的行的总数
基本格式:select count(*|列名) from 数据表名 [WHERE ...]- 1
实例:
查看雇员表emp雇员数量:select count(*) from emp;- 1

查看雇员表emp薪资sal大于1500的雇员数量:select count(*) from emp where sal > 1500;- 1

sum:
sum函数返回满足where条件的行的和,一般使用在数值列
基本格式:select sum(列名){,sum(列名)...} from 数据表名 [WHERE ...]- 1
实例:
select sum(sal) from emp;- 1

select sum(sal) from emp where sal>1500;- 1

avg:
AVG函数返回满足where条件的一列的平均值
基本格式:Select avg(列名){,avg(列名)..} from 数据表名 [WHERE ...]- 1
实例:
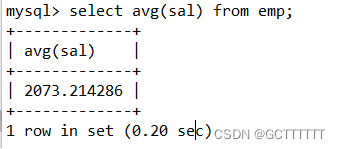
select avg(sal) from emp;- 1
max/min:
Max/min函数返回满足where条件的一列的最大/最小值
基本格式:select max(列名) from 数据表名 [WHERE ...]- 1
select min(列名) from 数据表名 [WHERE ...]- 1
实例:
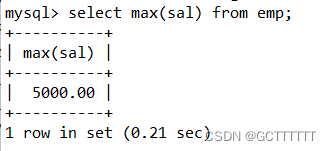
select max(sal) from emp;- 1
select min(sal) from emp;- 1

o) group by 语句
在 MySQL 中,GROUP BY 关键字可以根据一个或多个字段对查询结果进行分组。=
- 单独使用 GROUP BY 关键字时,查询结果会只显示每个分组的第一条记录。
- GROUP BY 关键字可以和 GROUP_CONCAT() 函数一起使用。GROUP_CONCAT() 函数会把每个分组的字段值都显示出来。
- 在数据统计时,GROUP BY 关键字经常和聚合函数一起使用。
- GROUP BY 与 WITH ROLLUP:WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。
基本格式:
SELECT column1[,列名2..] FROM table group by 列名- 1
实例:
显示每个部门的平均工资和最高工资:SELECT AVG(sal), MAX(sal),deptno FROM emp GROUP BY deptno;- 1

使用FORMAT方法,对小数点进行处理
保留两位小数:SELECT FORMAT(AVG(sal),2), MAX(sal),deptno FROM emp GROUP BY deptno;- 1

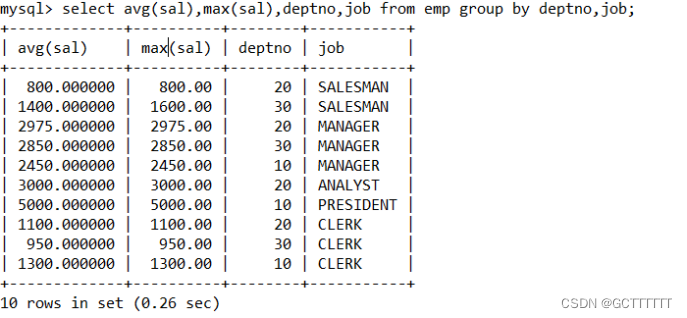
显示每个部门(deptno)的每种岗位(job)的平均工资和最高工资select avg(sal),max(sal),deptno,job from emp group by deptno,job;- 1
GROUP BY 关键字可以和 GROUP_CONCAT() 函数一起使用:
GROUP_CONCAT() 函数会把每个分组的字段值都显示出来
实例:
查找出各个部门(deptno)中员工名字(ename)select deptno,group_concat(ename) from emp group by deptno;- 1

GROUP BY 与 WITH ROLLUP:
WITH ROLLUP 可以实现在分组统计数据基础上再进行相同的统计(SUM,AVG,COUNT…)。
实例:
统计各个部门(deptno)各自的薪资(sal)平均值,并统计各个部门薪资平均值 的平均值select deptno,avg(sal) from emp group by deptno with rollup;- 1

统计各个部门(deptno)各自的薪资(sal)最大值,并统计各个部门薪资最大值 的最大值select deptno,max(sal) from emp group by deptno with rollup;- 1

p) 分组筛选:having语句
使用 having 子句对分组后的结果进行过滤
基本格式:SELECT column1[,列名2..] FROM table group by 列名 having 条件- 1
实例:
显示平均工资低于 2000 的部门号和它的平均工资select deptno,avg(sal) from emp group by deptno having avg(sal)<2000;- 1

使用别名:select deptno,avg(sal) as avgSal from emp group by deptno having avgSal<2000;- 1

q) 高级查询
i. 嵌套子查询
子查询是指嵌入在其它 sql 语句中的 select 语句,也叫嵌套查询
子查询在 WHERE 中的语法格式如下:
WHERE <表达式> <操作符> (子查询)- 1
其中,操作符可以是比较运算符和 IN、NOT IN、EXISTS、NOT EXISTS 等关键字。
实例:
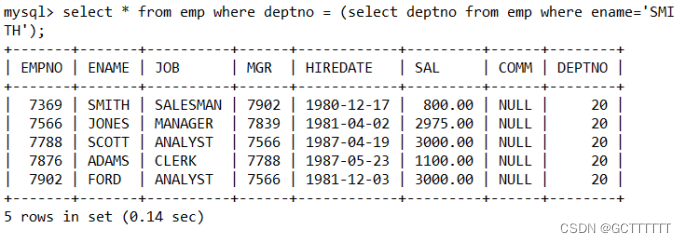
如何显示与 SMITH 同一部门的所有员工?- 先查询得到 SMITH 的部门号
select deptno from emp where ename='SMITH';- 1
- 把上面的 select 语句当做一个子查询来使用
select * from emp where deptno = (select deptno from emp where ename='SMITH');- 1
ii. exists|not exists子句
用于判断子查询的结果集是否为空,若子查询的结果集不为空,返回 TRUE,否则返回 FALSE;若使用关键字 NOT,则返回的值正好相反。
EXISTS 关键字可以和其它查询条件一起使用,条件表达式与 EXISTS 关键字之间用 AND 和 OR 连接。
实例:
查询emp表中是否存在deptno=10的部门,如果存在,就查询出account表中的记录:select * from account where exists (select deptno from emp where deptno='10');- 1

iii. In|not in子句
in子句:当表达式与子查询返回的结果集中的某个值相等时,返回 TRUE,否则返回 FALSE;若使用关键字 NOT,则返回值正好相反。
实例:
如何显示与 SMITH 或ALLEN 同一部门的所有员工?
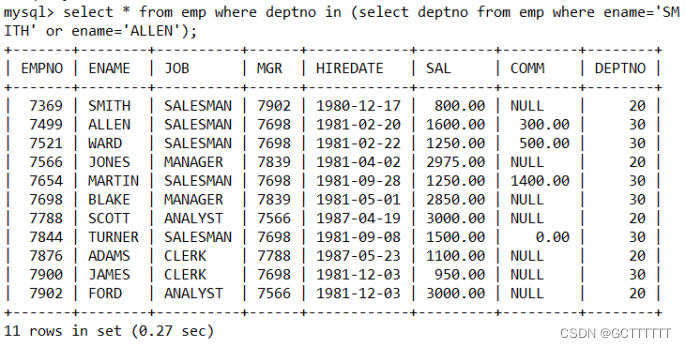
1、先查询SMITH和ALLEN分别在哪个部门:select deptno from emp where ename='SMITH' or ename='ALLEN';- 1

2、将上面select语句作为子查询select * from emp where deptno in (select deptno from emp where ename='SMITH' or ename='ALLEN');- 1
- 2
iv.**连接:(交叉连接(笛卡尔积)、内连接、外连接(左连接、右连接) ) (选讲)
在 MySQL 中,多表查询主要有交叉连接、内连接和外连接(外连接又包括左外连接和右外连接)。
交叉连接(CROSS JOIN或,)
交叉连接(CROSS JOIN)一般用来返回连接表的笛卡尔积。
交叉连接的语法格式如下:SELECT <字段名> FROM <表1> CROSS JOIN <表2> [WHERE子句]- 1
或
SELECT <字段名> FROM <表1>, <表2> [WHERE子句]- 1
语法说明如下:
- 字段名:需要查询的字段名称。
- <表1><表2>:需要交叉连接的表名。
- WHERE 子句:用来设置交叉连接的查询条件。
注意:多个表交叉连接时,在 FROM 后的表名之间连续使用 CROSS JOIN 或逗号,即可。以上两种语法的返回结果是相同的,但是第一种语法才是官方建议的标准写法。
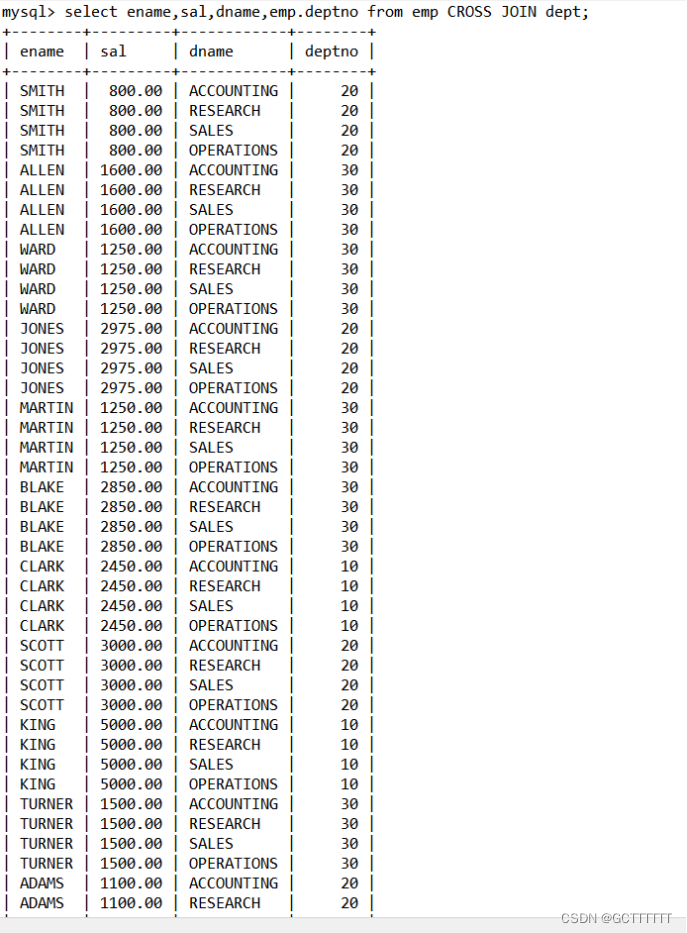
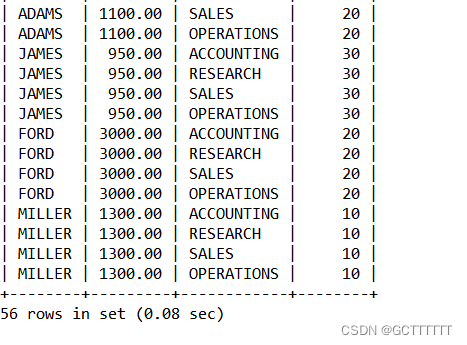
当连接的表之间没有关系时,我们会省略掉 WHERE 子句,这时返回结果就是两个表的笛卡尔积,返回结果数量就是两个表的数据行相乘。需要注意的是,如果每个表有 1000 行,那么返回结果的数量就有 1000×1000 = 1000000 行,数据量是非常巨大的。
实例:
笛卡尔积实例:select ename,sal,dname,emp.deptno from emp CROSS JOIN dept;- 1
交叉查询也可以使用where子句进行结果过滤:
实例:
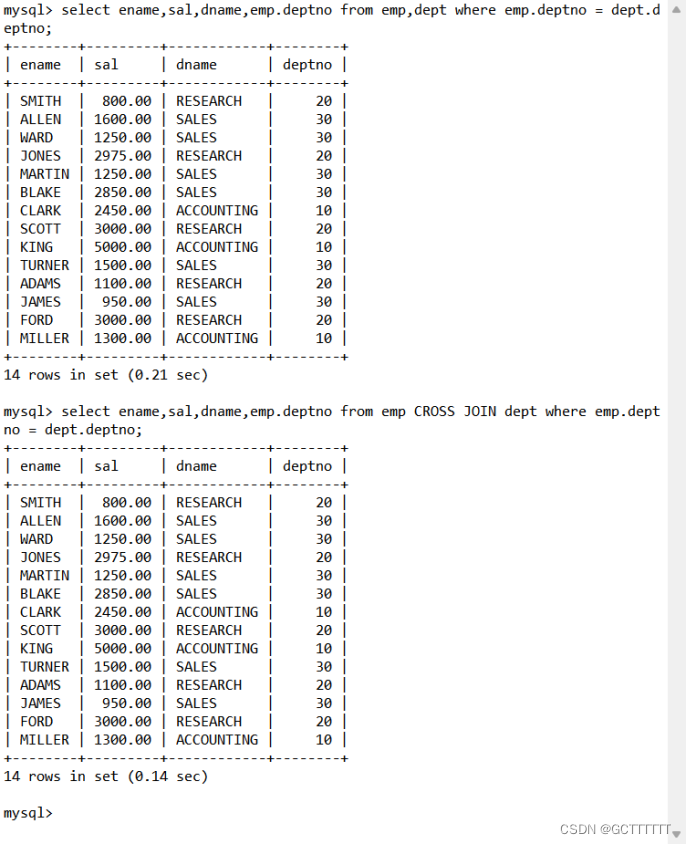
显示雇员名,雇员工资及所在部门的名字分析:
- 雇员名,雇员工资 来自 emp 表
- 部门的名字 来自 dept 表
- 需要对 emp 和 dept 查询 ename,sal,dname,deptno字段
- 当我们指定显示某个表的列时,需要使用:表.列名
使用CROSS JOIN连接表名写法:
select ename,sal,dname,emp.deptno from emp CROSS JOIN dept where emp.deptno = dept.deptno;- 1
- 2
使用逗号,连接表名写法:
select ename,sal,dname,emp.deptno from emp,dept where emp.deptno = dept.deptno;- 1
两种方法的返回结果是相同的:
内连接(INNER JOIN)
内连接(INNER JOIN)主要通过设置连接条件的方式,来移除查询结果中某些数据行的交叉连接。简单来说,就是利用条件表达式来消除交叉连接的某些数据行。内连接使用 INNER JOIN 关键字连接两张表,并使用 ON 子句来设置连接条件。如果没有连接条件,INNER JOIN 和 CROSS JOIN 在语法上是等同的,两者可以互换。
内连接的语法格式如下:
SELECT <字段名> FROM <表1> INNER JOIN <表2> [ON子句]- 1
语法说明如下:
- 字段名:需要查询的字段名称。
- <表1><表2>:需要内连接的表名。
- INNER JOIN :内连接中可以省略 INNER 关键字,只用关键字 JOIN。
- ON 子句:用来设置内连接的连接条件。
INNER JOIN 也可以使用 WHERE 子句指定连接条件,但是 INNER JOIN … ON 语法是官方的标准写法,而且 WHERE 子句在某些时候会影响查询的性能。
多个表内连接时,在 FROM 后连续使用 INNER JOIN 或 JOIN 即可。
内连接可以查询两个或两个以上的表。为了让大家更好的理解,暂时只讲解两个表的连接查询。
实例:
显示雇员名,雇员工资及所在部门的名字分析:
- 雇员名,雇员工资 来自 emp 表
- 部门的名字 来自 dept 表
- 需求对 emp 和 dept 查询 ename,sal,dname,deptno字段
- 当我们需要指定显示某个表的列时,需要使用:表.列名
使用INNER JOIN连接表名,ON后设置连接条件:
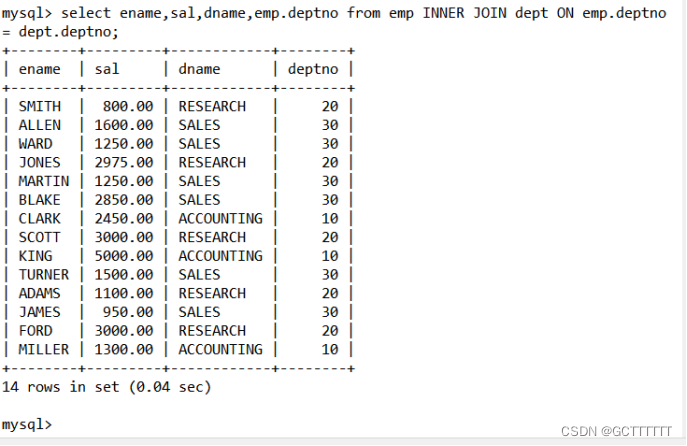
select ename,sal,dname,emp.deptno from emp INNER JOIN dept ON emp.deptno = dept.deptno;- 1
- 2
- 3
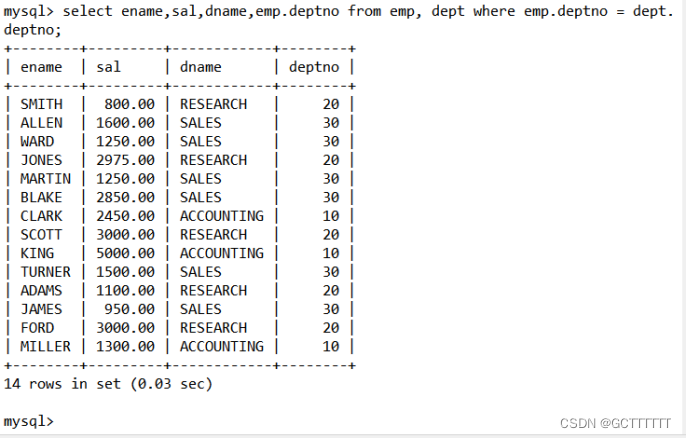
以上命令也相当于:select ename,sal,dname,emp.deptno from emp, dept where emp.deptno = dept.deptno;- 1
- 2
- 3
注意:当对多个表进行查询时,要在 SELECT 语句后面指定字段是来源于哪一张表。因此,在多表查询时,SELECT 语句后面的写法是表名.列名。另外,如果表名非常长的话,也可以给表设置别名,这样就可以直接在 SELECT 语句后面写上表的别名.列名。外连接(左连接、右连接)
外连接可以分为左外连接和右外连接
左连接(…LEFT JOIN…ON…)
获取左表所有记录,即使右表没有对应匹配的记录左外连接又称为左连接,使用 LEFT OUTER JOIN 关键字连接两个表,并使用 ON 子句来设置连接条件。
左连接的语法格式如下:
SELECT <字段名> FROM <表1> LEFT OUTER JOIN <表2>- 1
语法说明如下。
- 字段名:需要查询的字段名称。
- <表1><表2>:需要左连接的表名。
- LEFT OUTER JOIN:左连接中可以省略 OUTER 关键字,只使用关键字 LEFT JOIN。
- ON 子句:用来设置左连接的连接条件,不能省略。
上述语法中,“表1”为基表,“表2”为参考表。左连接查询时,可以查询出“表1”中的所有记录和“表2”中匹配连接条件的记录。如果“表1”的某行在“表2”中没有匹配行,那么在返回结果中,“表2”的字段值均为空值(NULL)。
实例解释:
显示所有人的成绩,如果没有成绩,也要显示该人的姓名和 id 号,成绩显示为空select `name`,stu.id,grade from stu LEFT JOIN exam ON stu.id=exam.id;- 1
- 2
- 3

右连接
与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
右外连接又称为右连接,右连接是左连接的反向连接。使用 RIGHT OUTER JOIN 关键字连接两个表,并使用 ON 子句来设置连接条件。**右连接的语法格式如下:** SELECT <字段名> FROM <表1> RIGHT OUTER JOIN <表2>- 1
- 2
语法说明如下。
- 字段名:需要查询的字段名称。
- <表1><表2>:需要右连接的表名。
- RIGHT OUTER JOIN:右连接中可以省略 OUTER 关键字,只使用关键字 RIGHT JOIN。
- ON 子句:用来设置右连接的连接条件,不能省略。
与左连接相反,右连接以“表2”为基表,“表1”为参考表。右连接查询时,可以查询出“表2”中的所有记录和“表1”中匹配连接条件的记录。如果“表2”的某行在“表1”中没有匹配行,那么在返回结果中,“表1”的字段值均为空值(NULL)。
实例解释:
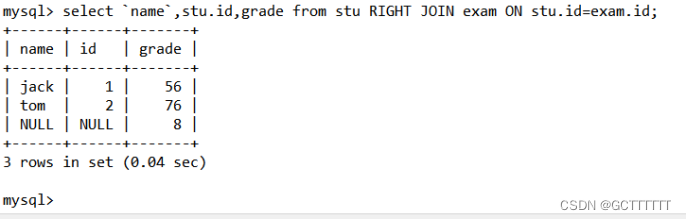
显示所有成绩,如果没有名字匹配,显示空
即:右边的表(exam) 和左表(stu)没有匹配的记录,也会把右表的记录显示出来select `name`,stu.id,grade from stu RIGHT JOIN exam ON stu.id=exam.id;- 1
- 2
- 3
使用外连接查询时,一定要分清需要查询的结果,是需要显示左表的全部记录还是右表的全部记录,然后选择相应的左连接和右连接。r) **字符串查找:like子句(选讲)
在 MySQL 中,LIKE 关键字主要用于搜索匹配字段中的指定内容。
其基本语法格式如下:SELECT {* | <字段列名>} FROM 表名 WHERE 字段列名 [NOT] LIKE '字符串';- 1
其中:
- NOT :可选参数,字段中的内容与指定的字符串不匹配时满足条件。
- 字符串:指定用来匹配的字符串。“字符串”可以是一个很完整的字符串,也可以包含通配符。
- LIKE 关键字支持百分号“%”和下划线“_”通配符(通配符是一种特殊语句,主要用来模糊查询。当不知道真正字符或者懒得输入完整名称时,可以使用通配符来代替一个或多个真正的字符)。
- 注意:匹配的字符串必须加单引号或双引号。
带有“%”通配符的查询
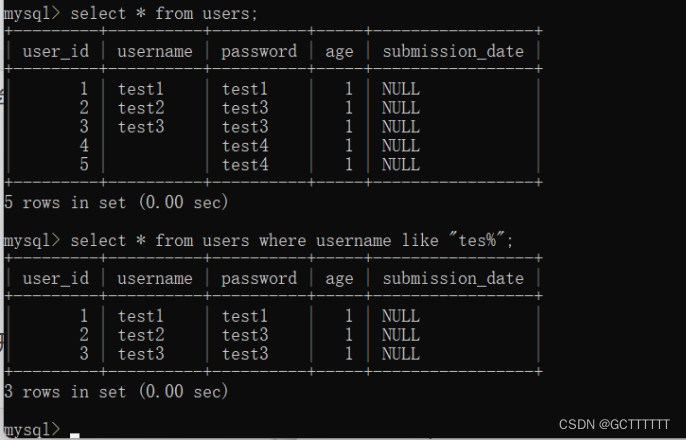
“%”是 MySQL 中最常用的通配符,它能代表任何长度的字符串,字符串的长度可以为 0。例如,a%b表示以字母 a 开头,以字母 b 结尾的任意长度的字符串。该字符串可以代表 ab、acb、accb、accrb 等字符串。
实例:select * from users where username like "tes%";- 1
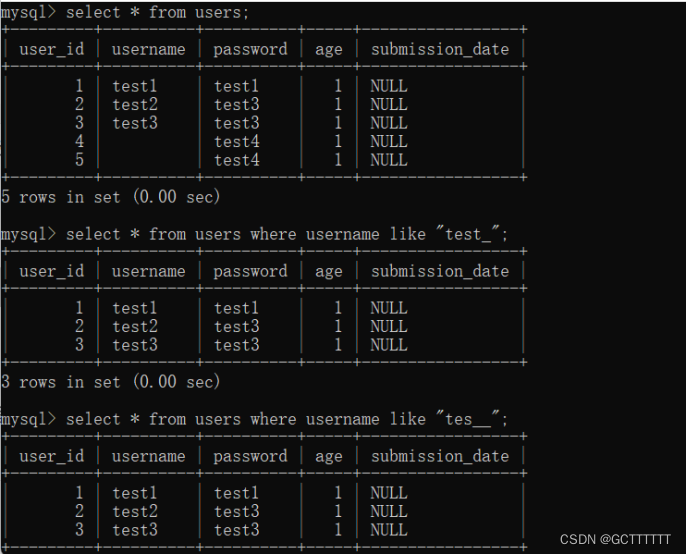
带有“_”通配符的查询
“_”只能代表单个字符,字符的长度不能为 0。例如,a_b可以代表 acb、adb、aub 等字符串。
实例:select * from users where username like "test_";- 1
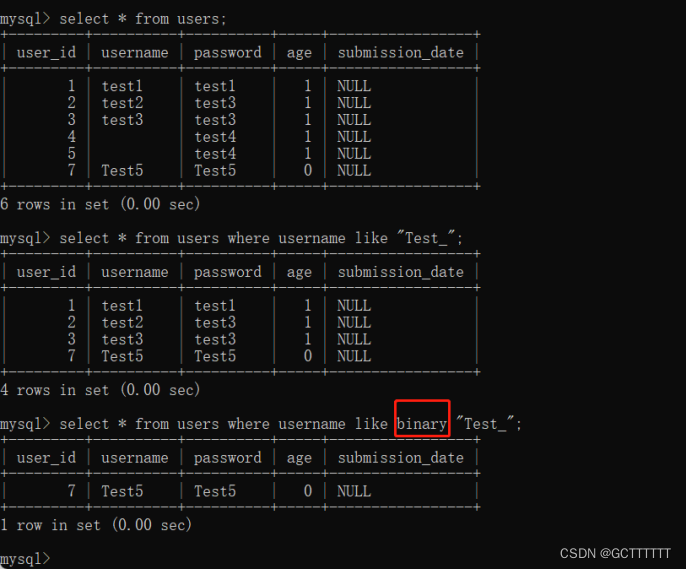
如何让LIKE 区分大小写:
默认情况下,LIKE 关键字匹配字符的时候是不区分大小写的。如果需要区分大小写,可以加入 BINARY 关键字。
实例:select * from users where username like binary "Test_";- 1
使用通配符的注意事项和技巧
下面是使用通配符的一些注意事项:- 注意大小写。MySQL 默认是不区分大小写的。如果区分大小写,像“Tom”这样的数据就不能被“t%”所匹配到。
- 注意尾部空格,尾部空格会干扰通配符的匹配。例如,“T% ”就不能匹配到“Tom”。
- 注意 NULL。“%”通配符可以到匹配任意字符,但是不能匹配 NULL。也就是说 “%”匹配不到 tb_students_info 数据表中值为 NULL 的记录。
下面是一些使用通配符要记住的技巧。
- 不要过度使用通配符,如果其它操作符能达到相同的目的,应该使用其它操作符。因为 MySQL 对通配符的处理一般会比其他操作符花费更长的时间。
- 在确定使用通配符后,除非绝对有必要,否则不要把它们用在字符串的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的。
- 仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据。
拓展
如果查询内容中包含通配符,可以使用“\”转义符转义。3. **非关系型数据库mongodb简介(选讲)
简介:
MongoDB是一个基于分布式文件存储 [1] 的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
4. **非关系型数据库redis简介(选讲)
简介
Redis 是完全开源免费的,遵守 BSD 协议,是一个灵活的高性能 key-value 数据结构存储,可以用来作为数据库、缓存和消息队列。
Redis 比其他 key-value 缓存产品有以下三个特点:
- Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载到内存使用。
- Redis 不仅支持简单的 key-value 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。
- Redis 支持主从复制,即 master-slave 模式的数据备份。
Redis 的特点
- 高性能: Redis 将所有数据集存储在内存中,可以在入门级 Linux 机器中每秒写(SET)11 万次,读(GET)8.1 万次。Redis 支持 Pipelining 命令,可一次发送多条命令来提高吞吐率,减少通信延迟。
- 持久化:当所有数据都存在于内存中时,可以根据自上次保存以来经过的时间和/或更新次数,使用灵活的策略将更改异步保存在磁盘上。Redis 支持仅附加文件(AOF)持久化模式。
- 数据结构: Redis 支持各种类型的数据结构,例如字符串、散列、集合、列表、带有范围查询的有序集、位图、超级日志和带有半径查询的地理空间索引。
- 原子操作:处理不同数据类型的 Redis 操作是原子操作,因此可以安全地 SET 或 INCR 键,添加和删除集合中的元素等。
- 支持的语言: Redis 支持许多语言,如 C、C++、Erlang、Go、Haskell、Java、JavaScript(Node.js)、Lua、Objective-C、Perl、PHP、Python、R、Ruby、Rust、Scala、Smalltalk 等。
- 主/从复制: Redis 遵循非常简单快速的主/从复制。配置文件中只需要一行来设置它,而 Slave 在 Amazon EC2 实例上完成 10 MM key 集的初始同步只需要 21 秒。
- 分片: Redis 支持分片。与其他键值存储一样,跨多个 Redis 实例分发数据集非常容易。
- 可移植: Redis 是用 C 编写的,适用于大多数 POSIX 系统,如 Linux、BSD、Mac OS X、Solaris 等。
与其他 key-value 存储有什么不同?
Redis 有着更为复杂的数据结构并且提供对它们的原子性操作,这是一个不同于其他数据库的进化路径。Redis 的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
Redis 运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样 Redis 可以做很多内部复杂性很强的事情。同时,因 RDB 和 AOF 两种磁盘持久化方式是不适合随机访问,因为它们是顺序写入的。
Redis 架构
Redis 主要由有两个程序组成:
- Redis 客户端 redis-cli
- Redis 服务器 redis-server
客户端、服务器可以位于同一台计算机或两台不同的计算机中。
-
相关阅读:
【python养成】:案例(判断素数、统计字符串中的大写字母、小写字母、数字、其他字符的个数、整数之和、模拟内置函数)
带团队后的日常思考(十二)
JDBC005--使用java来编写查询同一张表的通用代码
StarRocks数据导入
全网最牛,Pytest自动化测试框架-Fixture测试夹具详解(撸码实例)
亚马逊圣诞灯饰UL588测试报告检测项目介绍
分类预测 | Matlab实现BES-ELM秃鹰搜索算法优化极限学习机分类预测
Django ORM 事务和查询优化
(附源码)ssm本科教学合格评估管理系统 毕业设计 180916
npm版本错误——npm ERR! code ERESOLVE 解决方法
- 原文地址:https://blog.csdn.net/GCTTTTTT/article/details/127883211