-
Kaldi语音识别技术(四) ----- 完成G.fst的生成
Kaldi语音识别技术(四) ----- 完成G.fst的生成
一、N-Gram 语言模型简介
N-Gram是大词汇连续语音识别中常用的一种语言模型,对中文而言,我们称之为汉语语言模型(CLM, Chinese Language Model)。汉语语言模型利用上下文中相邻词间的搭配信息,可以实现到汉字的自动转换,汉语语言模型利用上下文中相邻词间的搭配信息,在需要把连续无空格的拼音、笔划,或代表字母或笔划的数字,转换成汉字串(即句子)时,可以计算出具有最大概率的句子,从而实现到汉字的自动转换,无需用户手动选择,避开了许多汉字对应一个相同的拼音(或笔划串,或数字串)的重码问题。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
二、环境准备
srilm工具的安装
•这是生成ngram的工具-可以用来生成G.fst
•源站下载 http://www.speech.sri.com/projects/srilm/download.html(需要填写信息,国内目前无法访问)
•下载见这里 点我免费下载srilm-1.7.3.tar.gz和srilm-1.7.1.tar.gz
•将下载的srilm-1.7.3.tar.gz上传到kaldi目录的tools目录中 我的路径是
~/kaldi/kaldi/toolsmv srilm-1.7.3.tar.gz srilm.tar.gz # 重命名- 1
cd ~/kaldi/kaldi/tools vim install_srilm.sh # 打开kaldi自带的安装脚本- 1
- 2
该脚本需要从国外下载,先注释19~33行再执行,它会帮我们自动安装srilm,如下:
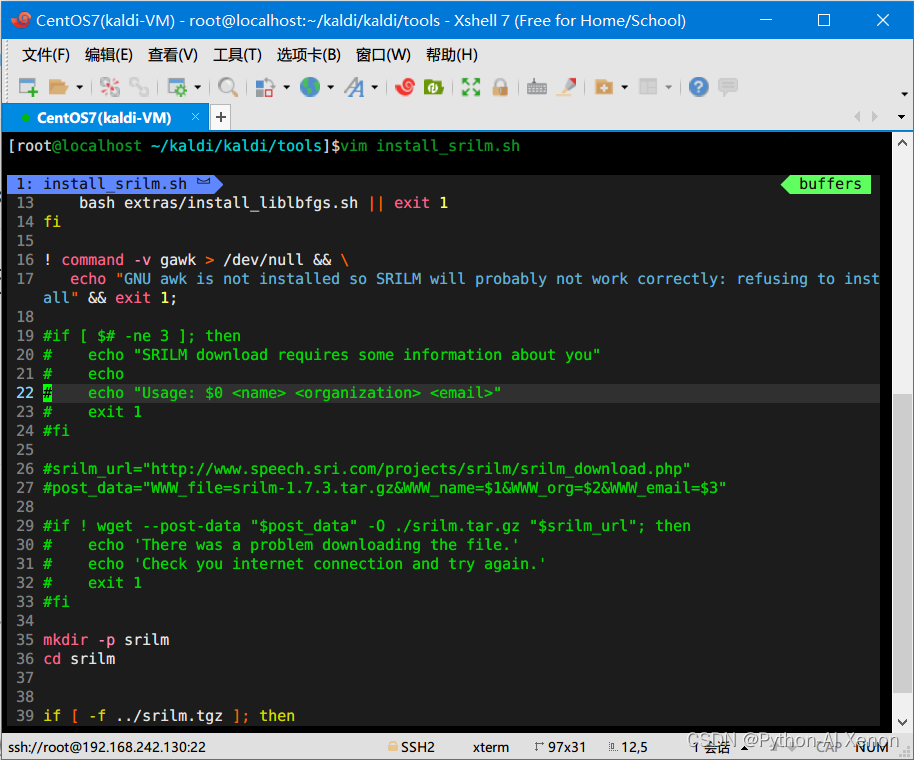
sh install_srilm.sh # 执行安装脚本- 1
安装成功如下所示:
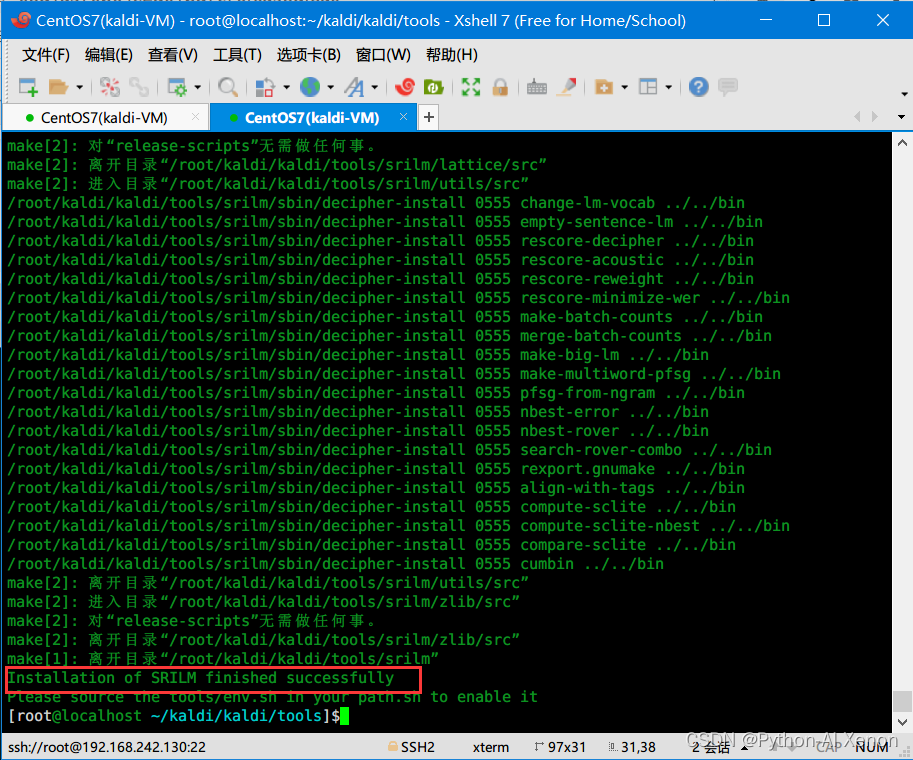
按照提示执行
. ./env.sh刷新环境变量输入
ng按两次TAB键出现以下内容说明srilm安装成功,可以正常使用
可以添加环境变量,避免每次都要执行 env.sh 激活
echo "export PATH=/root/kaldi/kaldi/tools/srilm/bin/i686-m64:/root/kaldi/kaldi/tools/srilm/bin" >> /etc/profile source /etc/profile- 1
- 2
- 3
创建G的文件夹
mkdir -p ~/kaldi/data/G/normal mkdir -p ~/kaldi/data/G/G_learn- 1
- 2
三、文件准备
(一) 准备语料
1. 使用Python生成语料
这里我们使用之前生成好的 text 文件 直接生成
# -*- coding: utf-8 -*- # @Author : yxn # @Date : 2022/11/13 12:23 # @IDE : PyCharm(2022.2.3) Python3.9.13 def get_lm(data): """使用python脚本生成语料""" lm = [] with open(data, "r", encoding="utf-8") as f: for line in f.readlines(): lm.append(line.strip("\n").strip().split(" ")[1:]) # # 保存语料 save_path = "/root/kaldi/data/G/normal/text.lm" with open(save_path, "w", encoding="utf-8") as f: for i in lm: f.writelines(" ".join(i) + "\n") print("text.lm 语料生成成功! ") if __name__ == '__main__': data_path = "/root/kaldi/kaldi_file/text" # 之前数据处理生成的text文件 get_lm(data_path)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
生成的语料如下:
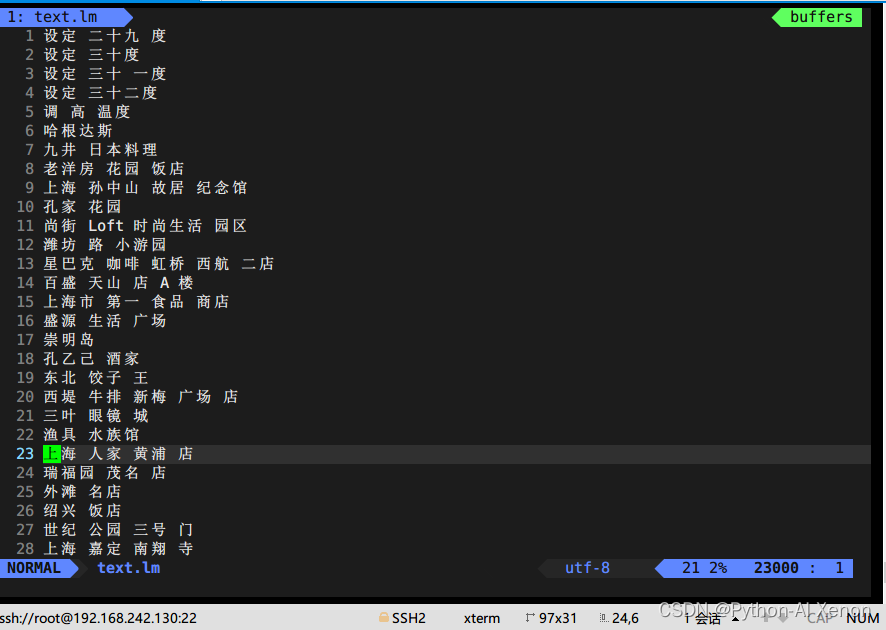
2. 使用awk 快速生成语料
awk -F ' ' '{for (i=2;i<=NF;i++) printf("%s ",$i);print ""}' /root/kaldi/kaldi_file/text > ~/kaldi/data/G/normal/text.lm- 1
效果和上面的python脚本是一模一样的,但是效率要高得多得多!
(二) 语言模型
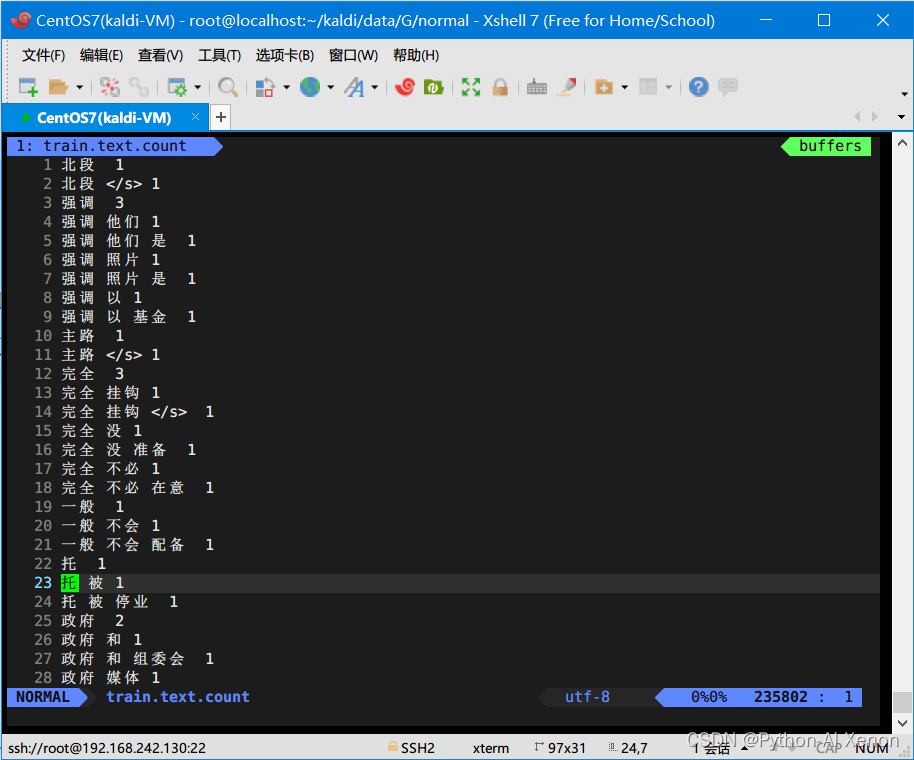
1. 统计词频
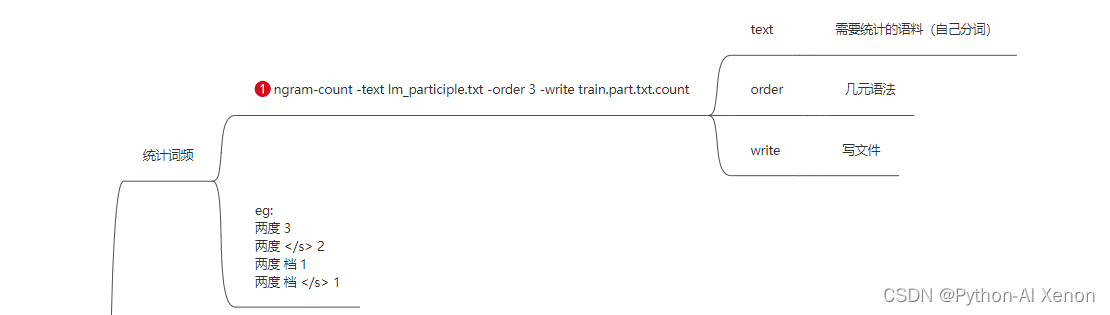
ngram-count -text text.lm -order 3 -write train.text.count #•参数详解: #•-text 后接我们准备的语料 #•-order 后接我们的几元模型,即N-Gram 中的N #•-write 统计的词频文件放入的文件- 1
- 2
- 3
- 4
- 5
结果如下图所示:
2. 生成语言模型
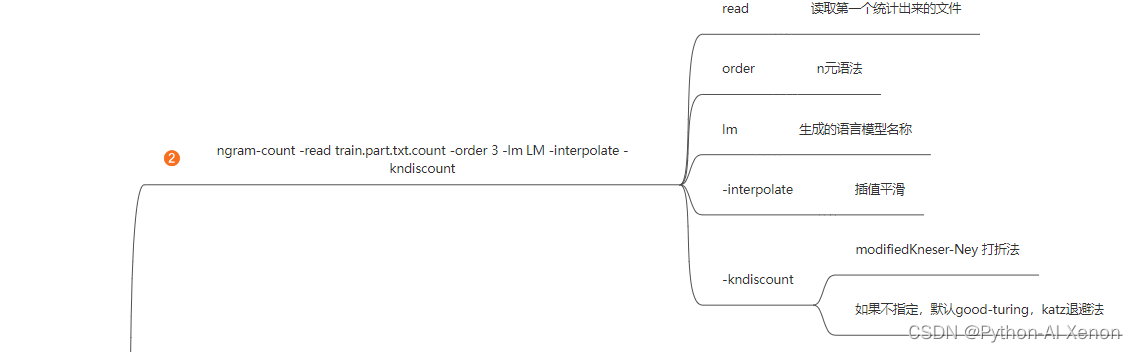
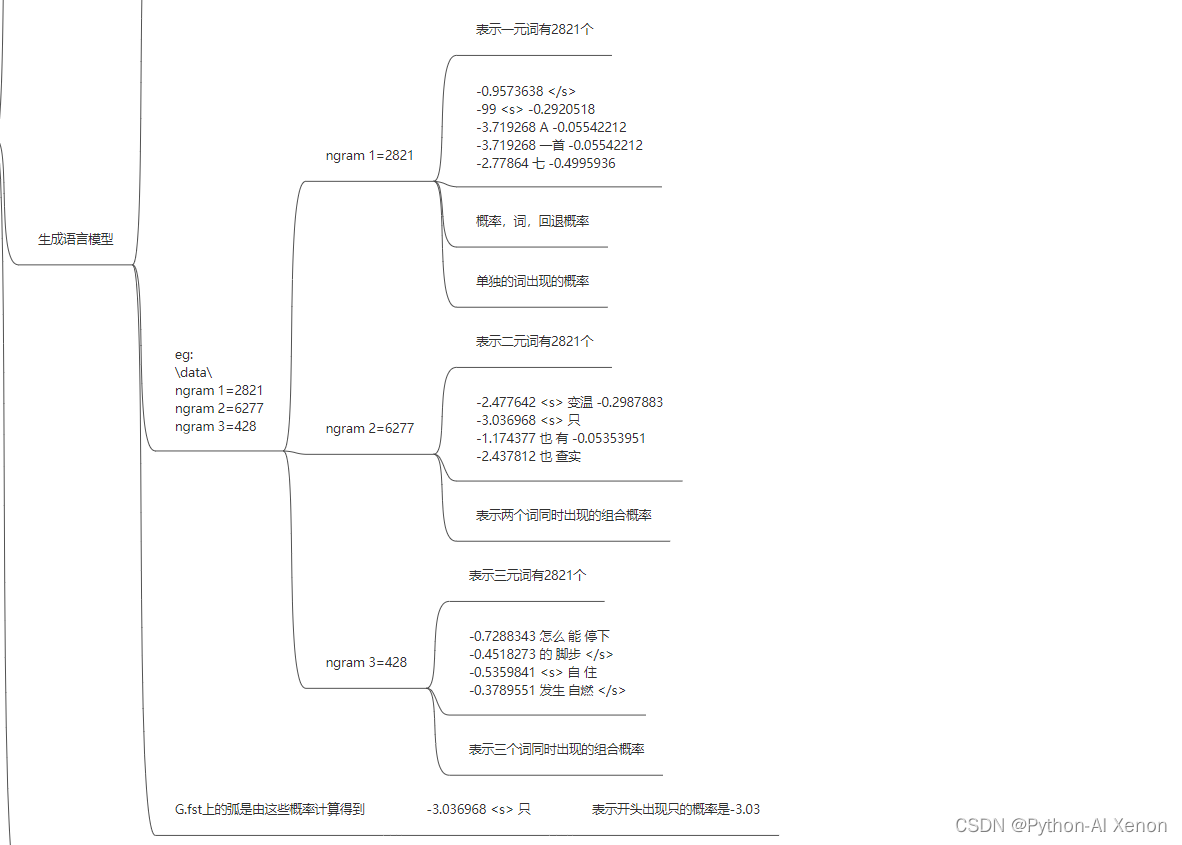
ngram-count -read train.text.count -order 3 -lm LM -interpolate -kndiscount #•参数详解: #•-read 后接我们生成的语料统计文件 #•-order 后接我们的几元模型,即N-Gram 中的N #•-lm 生成的语言模型名称 #•-interpolate 平滑函数 插值平滑 #•-kndiscount 回退概率函数- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果如下图所示:
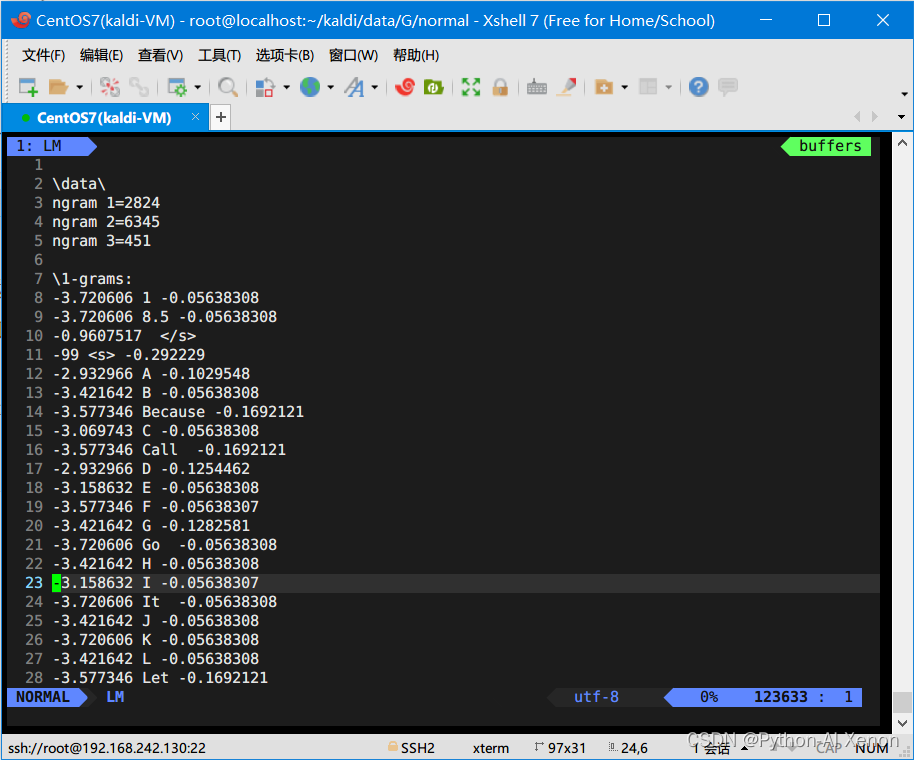
3. 计算困惑度
ngram -ppl text.lm -order 3 -lm LM -debug 1- 1
结果如下图所示:
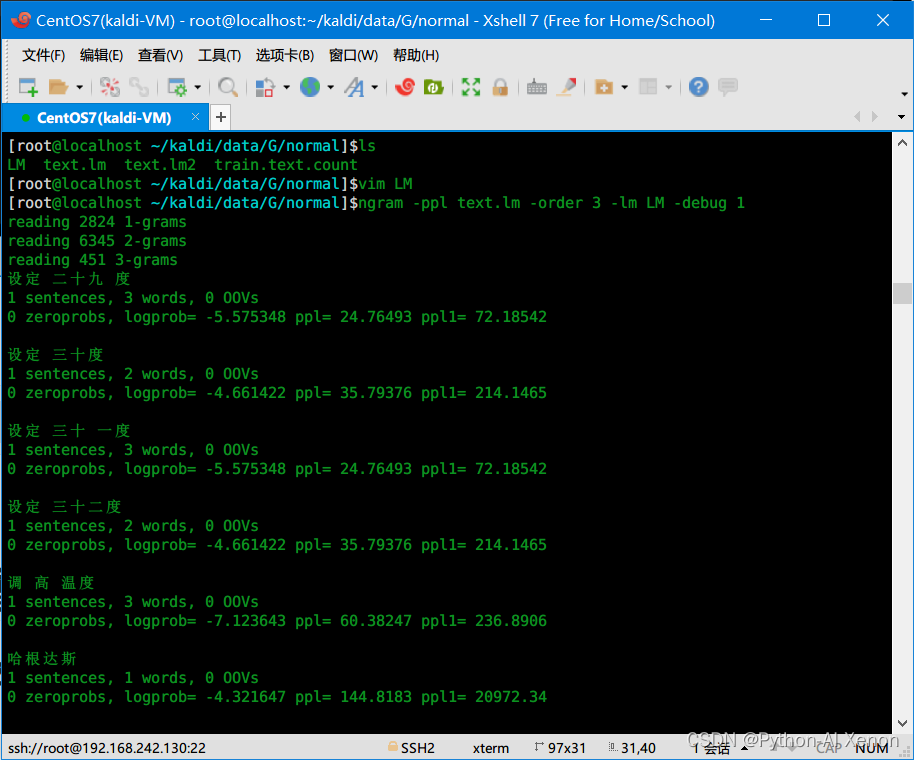
四、G.fst的生成及查看
1. 使用 format_lm_sri.sh 脚本生成
推荐使用该脚本生成,其底层原理就是调用了arpa2fst命令
cd ~/kaldi/data utils/format_lm_sri.sh L/lang G/normal/LM dict/lexicon.txt G/normal- 1
- 2
#•参数详解: #•第一个参数 lang文件夹 #•第二个参数 使用SRI生成的LM #•第三个参数 词典 #•第四个参数 G.fst生成的位置 # Usage: utils/format_lm_sri.sh [options][ ] # E.g.: utils/format_lm_sri.sh data/lang data/local/lm/foo.kn.gz data/local/dict/lexicon.txt data/lang_test - 1
- 2
- 3
- 4
- 5
- 6
- 7
执行成功如下:
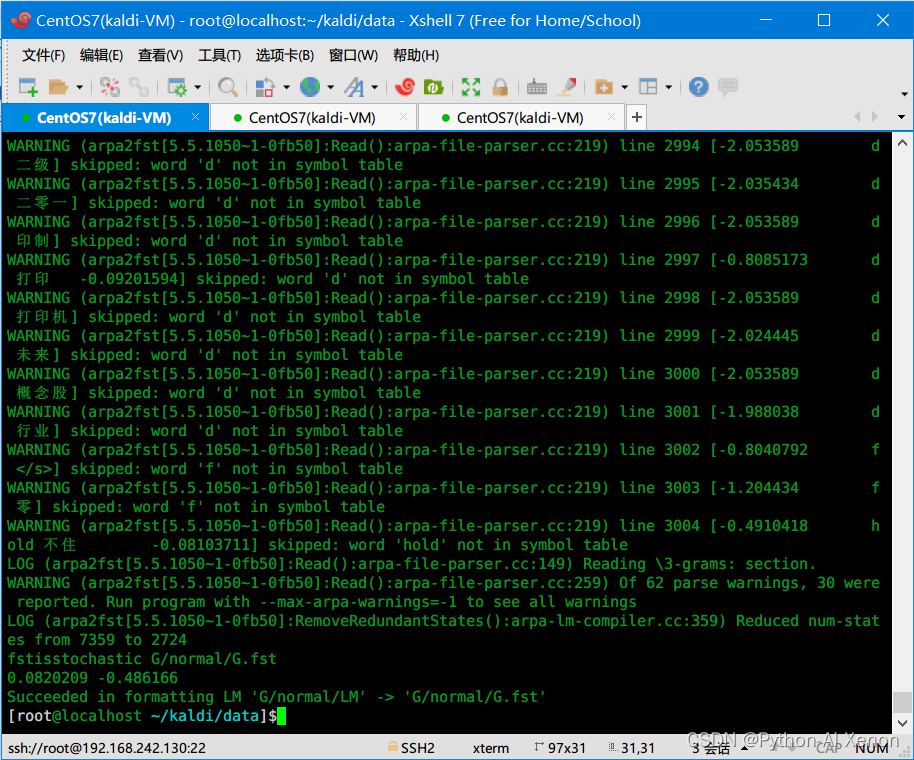
可以看到
~/kaldi/data/G/normal路径下面有了如下文件:
2. 使用 arpa2fst 工具生成
与上面的方法类似,命令如下
arpa2fst --disambig-symbol=#0 --read-symbol-table=L/lang/words.txt G/normal/LM G/test/G.fst- 1
#•参数详解: #•第一个参数 消歧符号 #•第二个参数 words.txt #•第三个参数 使用SRI生成的LM #•第四个参数 G.fst生成的位置 #Usage: arpa2fst [opts]# e.g.: arpa2fst --disambig-symbol=#0 --read-symbol-table=data/lang/words.txt lm/input.arpa G.fst - 1
- 2
- 3
- 4
- 5
- 6
- 7
输出结果如下:
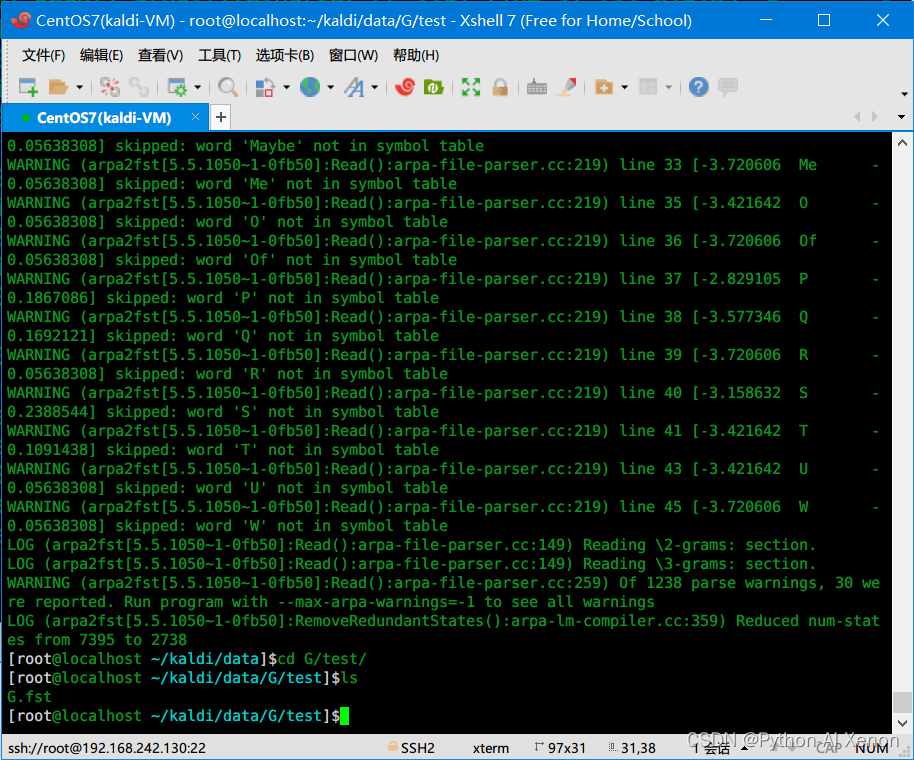
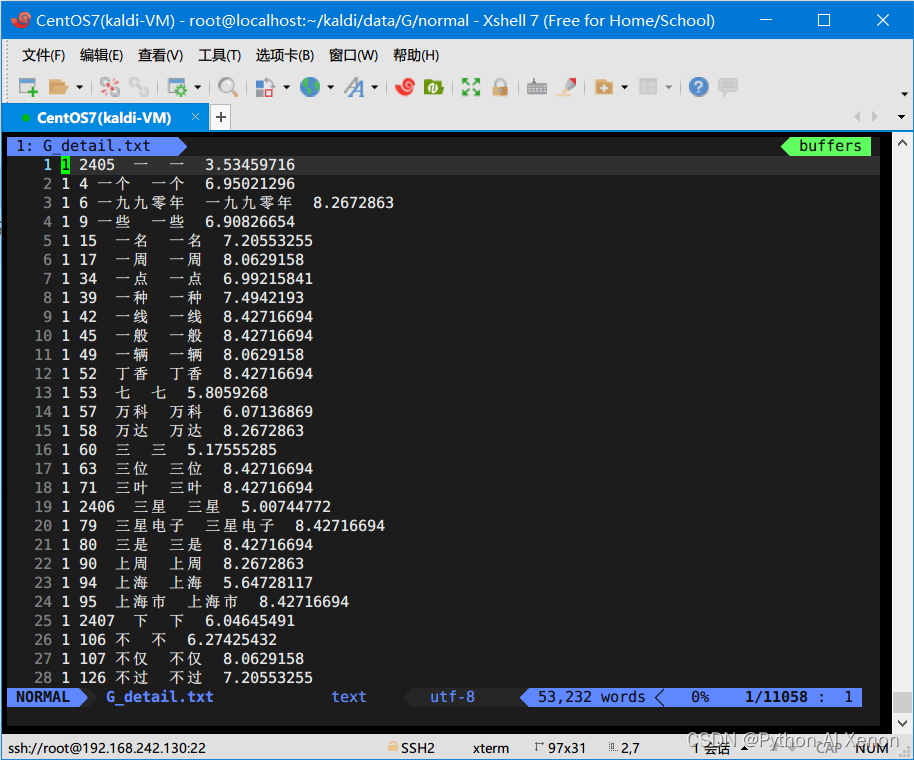
3.G.fst文本可视化
cd ~/kaldi/data/G/normal fstprint --isymbols=words.txt --osymbols=words.txt G.fst > G_detail.txt # 参数中,由于G.fst实际是一个fsa(有限状态接收器),所以输入和输出都是词- 1
- 2
- 3
五、小的G.fst
同前面L.fst 一样,学习过程当中我们同样使用一个小的G.fst来进行学习
这里我们同样以 “今天天气真好 ”、“今天天气还不行 ” 这2句话来制作小的可视化数据
1. 创建小的语料
cd ~/kaldi/data/G/G_learn vim text.lm # 输入以下内容 今天 天气 真好 今天 天气 还 不行 # wq保存退出- 1
- 2
- 3
- 4
- 5
- 6
2. 生成小语料的统计文件
ngram-count -text text.lm -order 3 -write train.text.count- 1
3. 生成小语料的语言模型
ngram-count -read train.text.count -order 2 -lm LM- 1
特别提醒: 由于小语料数据量太小,故不能使用平滑函数和回退函数
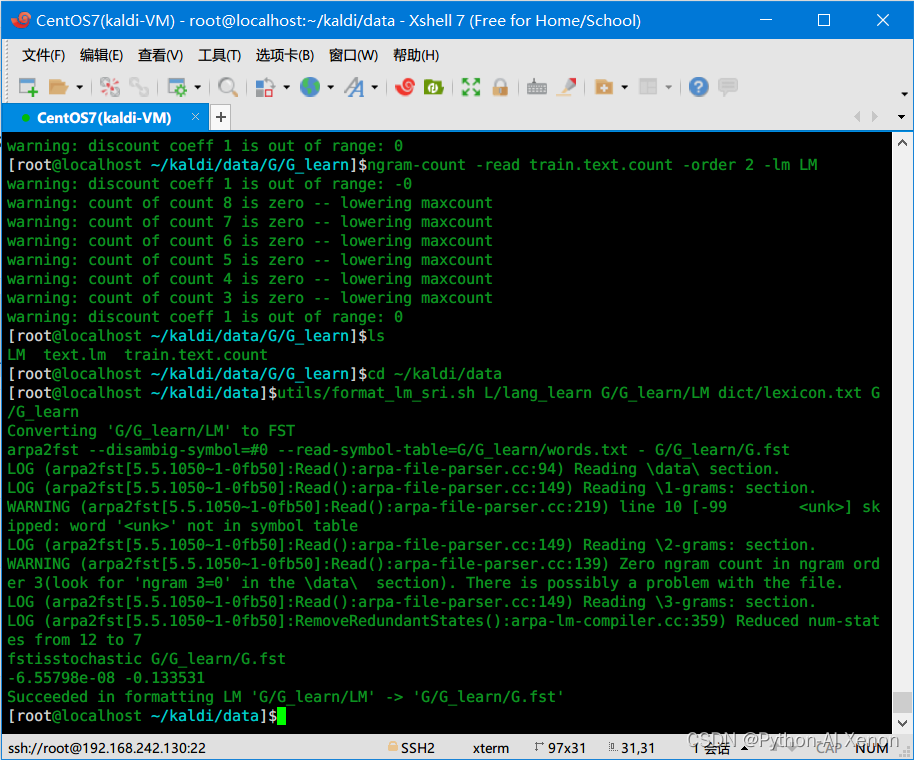
4. 生成小的G.fst
cd ~/kaldi/data utils/format_lm_sri.sh L/lang_learn G/G_learn/LM dict/lexicon.txt G/G_learn- 1
- 2
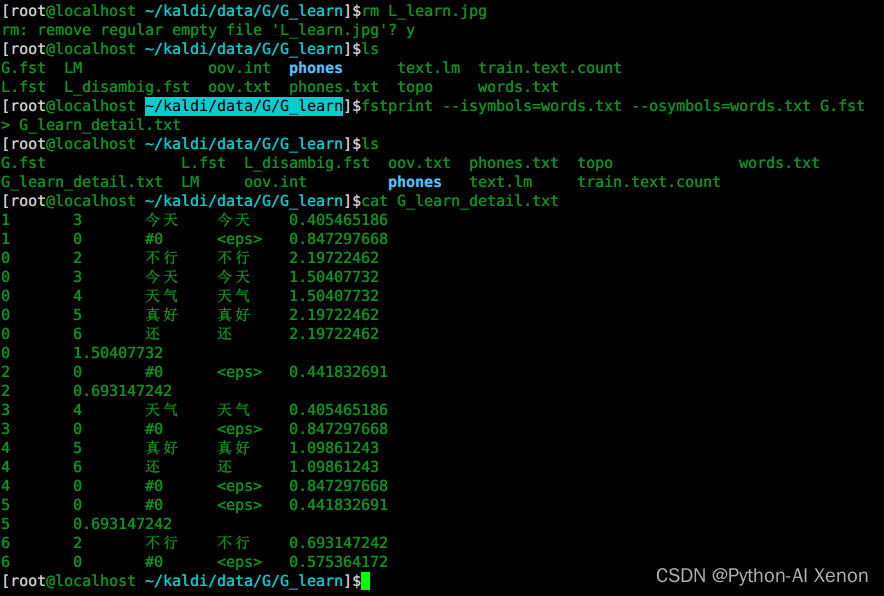
5. G.fst文本可视化
cd ~/kaldi/data/G/G_learn fstprint --isymbols=words.txt --osymbols=words.txt G.fst > G_learn_detail.txt- 1
- 2
6.G.fst图形可视化
#(1)生成dot文件 fstdraw --isymbols=phones.txt --osymbols=words.txt G.fst > G.dot #(2)绘图 dot -Tjpg -Gdpi300 G.dot > G.jpg # 不太清晰 dot -Tsvg G.dot > G.svg- 1
- 2
- 3
- 4
- 5
下载到本地电脑进行查看如下
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nCL7VucQ-1668614245175)(E:\滇西科技师范学院大三\语音识别技术kaldi\学习笔记三(G的生成)]\19.png)](https://1000bd.com/contentImg/2024/04/22/4e44aea59a3c55f8.png)
六、封装成Shell脚本
后面有时间更新...- 1
-
相关阅读:
剑指 Offer 66. 构建乘积数组
Java学习笔记(二十八)
数据可视化在智慧医疗中的重要应用
ROS - launch文件
计算机网络二:应用层
8.25 学习
SSM整合之Mybatis笔记(MyBatis的分页插件(代码生成器))(P060—P062)
外卖订餐系统,外卖点餐系统,外卖系统毕业设计
php+mysql幼儿园早教网站
Spring源码分析(四) Aop全流程
- 原文地址:https://blog.csdn.net/yxn4065/article/details/127895946