-
《深度学习进阶 自然语言处理》第四章:Embedding层和负采样介绍
之前文章链接:
开篇介绍:《深度学习进阶 自然语言处理》书籍介绍
第一章:《深度学习进阶 自然语言处理》第一章:神经网络的复习
第二章:《深度学习进阶 自然语言处理》第二章:自然语言和单词的分布式表示
第三章:《深度学习进阶 自然语言处理》第三章:word2vec上一章我们学习了word2vec的机制,并实现了简单的2层神经网络的CBOW模型。目前的实现存在的最大问题是,随着语料库中要处理的词汇量的增加,计算量随之增加。当词汇量达到一定程度后,上一章的2层神经网络的CBOW模型的计算要花费过多的时间。基于此问题,本章将重点讲述如何加速word2vec的计算。主要有两点改进方式:
- 引入Embedding层,
- 引入Negative Sampling(负采样)的损失函数。
4.1 word2vec的改进一
上一章我们构建了一个词汇量为7、窗口为1的CBOW模型。已知上下文单词,预测中间单词。计算过程是先通过输入层和输入侧权重(Win)乘积得到中间层,中间层和输出侧权重(Wout)乘积计算每个单词(这里是7个单词)的得分,得分经过Softmax函数转化为每个单词出现的概率,使用交叉熵计算出损失(如下图所示)。
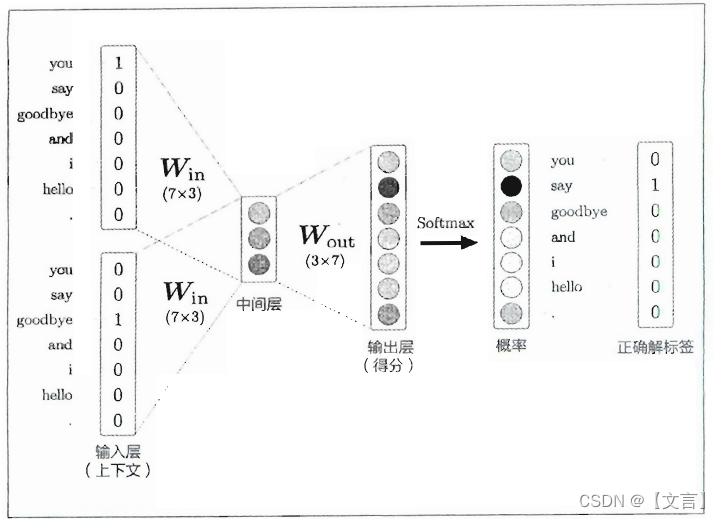
当处理大规模语料库时,词汇量变大,各层的维度变高,中间的计算耗费很长时间,有两个方面的计算出现瓶颈:
-
输入层的one-hot表示和权重矩阵Win的乘积
-
中间层和权重矩阵Wout的乘积以及Softmax层的计算
第1个问题与输入层的one-hot表示有关。我们用one-hot表示来处理单词,随着词汇量的增加,one-hot表示的向量大小也会增加。比如当词汇量有100万个的情况下,one-hot表示本身就需要占用100万个元素的内存大小。此外,在计算one-hot表示和权重矩阵Win的乘积也要花费大量的计算资源。这个问题将通过引入Embedding层来解决。
第2个问题出现在中间层之后的计算。随着词汇量的增加,中间层和权重矩阵Wout的乘积以及Softmax层的计算都需要大量的时间。这个问题将通过引入Negative Sampling(负采样)的损失函数来解决。
4.1.1 Embedding层
上一章的word2vec实现中,我们将单词转化为one-hot表示,并输入MatMul层,在MatMul层中计算该one_hot表示和权重矩阵的乘积,如下图所示。
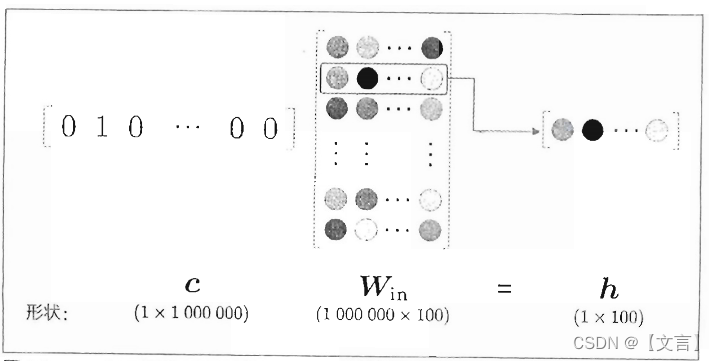
上图所做的乘积无非是从Win矩阵中取出某个特定行,当Win中存放的是10万个单词的分布式表示,c中存放的是待取单词的ID,这样构建的层我们称之为Embedding层。
4.2 word2vec的改进二
如前所述,word2vec的另一个瓶颈在于中间层之后的矩阵乘积和Softmax层的计算。为解决这个问题,我们将采用负采样(negative sampling)
4.2.1 中间层之后的计算问题
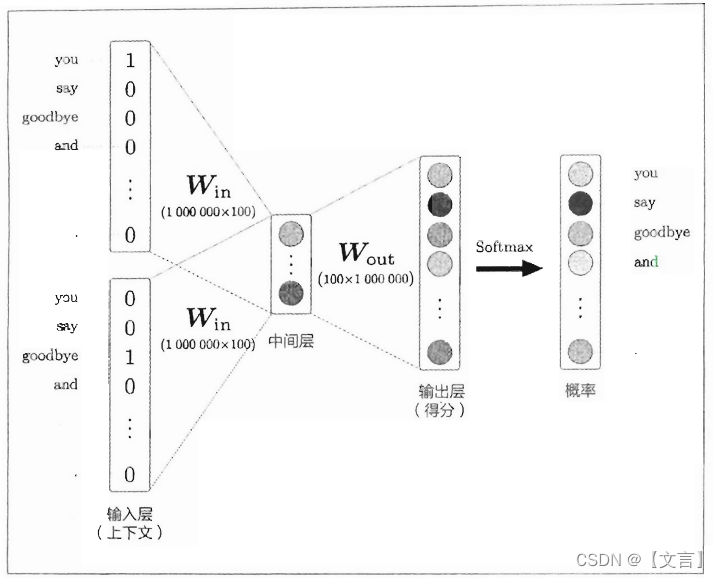
当词汇量足够大,比如100万个的时候(这里假设每个单词是由大小为100的向量来分布式表示),还有两个地方需要很多计算时间:
-
中间层的神经元和权重矩阵(Wout)的乘积
-
Softmax层的计算
word2vec进行的处理如下图所示:
4.2.2 从多分类到二分类
接下来我们来解释一下负采样。用这个方法的关键思想是用二分类拟合多分类。目前为止,我们都是用多分类的方式从词汇库中选出概率最高的1个正确单词,如果词库有100万个单词,最后要计算100万个单词的概率,概率最大的就是我们要的最终单词。如果改成二分类,最后只要计算一个得分,通过sigmoid得到一个概率值,用以判断“是/否”为目标单词,过程举例如下图。
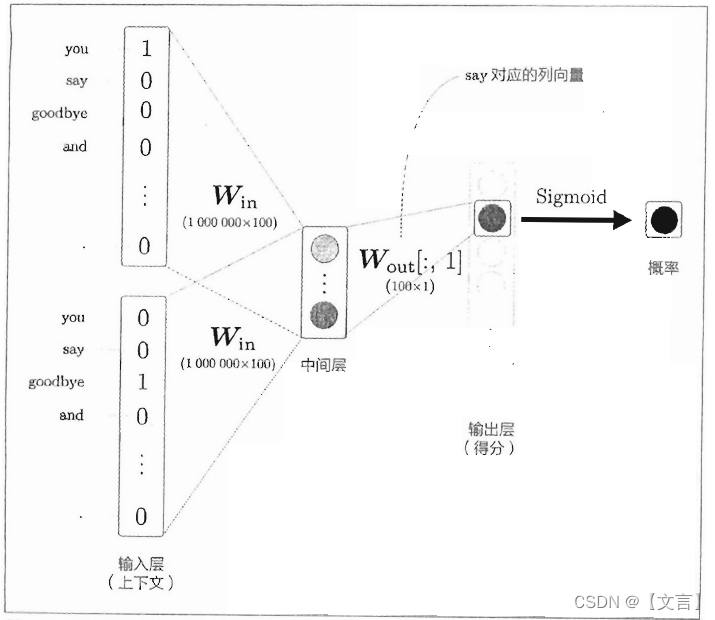
输出的神经元只有一个,所以计算中间层和输出侧权重矩阵Wout的乘积,Wout只需要提取say对应的列单词向量。
4.2.3 负采样
上一节的方式仅学习了正例,即当上下文是you和goodbye,目标词是say时,经过训练后模型的Sigmoid层输出接近1,但是对say之外的负例一无所知。而我们想获得的最终CBOW模型是,对于正例(say),Sigmoid层的输出接近1;对于负例(say以外的单词),Sigmoid层的输出接近0。
为了把多分类问题处理成二分类问题,对于正例和负例,都需要能够正确地进行二分类。我们不会对所有负例进行学习,而是作为近似方法,选择若干个(5个或10个)负例,这也是负“采样”的真正含义。
那么这若干个负例是如何抽取的呢?实际上基于语料库的统计数据进行的采样要比随机抽样好,具体来说,就是让语料库中经常出现的单词容易被抽到,让语料库中不经常出现的单词难以被抽到。因为在现实问题中,稀有单词基本上不出现,处理好高频词才能获得更好的结果。
总结
Word2vec是谷歌2013年提出的在2018年之前比较主流的词嵌入模型之一,word2vec的用处是从语料中训练生成一批词向量,这批词向量可以直接拿来做后续的任务。
本章以word2vec的高速化为主题,对上一章的CBOW模型进行了改进,实现Embedding层和引入负采样。基于本书的写作时间,本章中并没有介绍众所周知的方法,即基于词频作为叶子节点的权重,构造哈弗曼树,减少softmax的计算量。具体过程感兴趣的同学可以查资料了解一下。
-
相关阅读:
jQuery实现输入框提示并点击回显功能呢
xgboost early_stop_rounds是如何生效的?
spring源码环境搭建,测试springmvc
Linux内核有什么之内存管理子系统有什么第三回 —— 小内存分配(1)
现网常见问题及解决思路
【打卡】【sysfs相关API详解】21天学习挑战赛—RK3399平台开发入门到精通-Day20
laravel系列(二) Dcat admin框架开发工具使用
破除“数据孤岛”新策略:Data Fabric(数据编织)和逻辑数据平台
Kafka-Kerberos票据刷新问题
Vue3 之 Vue - Router
- 原文地址:https://blog.csdn.net/weixin_39471848/article/details/127892831