-
flink学习之sql-client之踩坑记录
flink/bin目录下会看到这个脚本,最开始以为是和spark-shell差不多的。结果自行摸索无果,网上查的文章也写的很垃圾,自己查官网看下吧。
直接./sql-client.sh
SELECT 'Hello World';
报错 org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not acquire the minimum required resources.
这里说到了jobmanager resources ,那么设置下(这个报错可能是我运行了测试的flinkstream任务)
vim flink-conf.yaml
jobmanager.memory.process.size: 3200m
调大了也不行。我重启了一下。
注意事项 不能 双引号!!

CLI 为维护和可视化结果提供三种模式。
表格模式(table mode)在内存中实体化结果,并将结果用规则的分页表格可视化展示出来。执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'table';变更日志模式(changelog mode)不会实体化和可视化结果,而是由插入(
+)和撤销(-)组成的持续查询产生结果流。SET 'sql-client.execution.result-mode' = 'changelog';Tableau模式(tableau mode)更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容会取决于作业 执行模式的不同(
execution.type):SET 'sql-client.execution.result-mode' = 'tableau';注意当你使用这个模式运行一个流式查询的时候,Flink 会将结果持续的打印在当前的屏幕之上。如果这个流式查询的输入是有限的数据集, 那么Flink在处理完所有的数据之后,会自动的停止作业,同时屏幕上的打印也会相应的停止。如果你想提前结束这个查询,那么可以直接使用
CTRL-C按键,这个会停掉作业同时停止屏幕上的打印。下面看三种打印区别!!!!!!!!!
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
SET 'sql-client.execution.result-mode' = 'table'; //这个是默认的

执行 SET 'sql-client.execution.result-mode' = 'changelog';

SET 'sql-client.execution.result-mode' = 'tableau';

怎么说呢? table模式一般就行了。想看日志详细变化的就用changelog和 tableau
接着实验
- CREATE CATALOG MyCatalog
- WITH (
- 'type' = 'hive'
- );
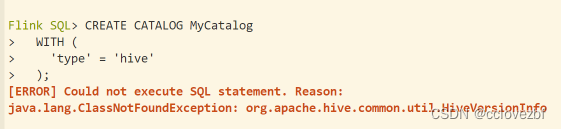
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.hive.common.util.HiveVersionInfo查了下是没有hive-exec的jar包。解决办法 可以cp
ln -s /opt/cloudera/parcels/CDH/jars/hive-exec-3.1.3000.7.1.7.1046-1.jar ./lib/
继续

[ERROR] Could not execute SQL statement. Reason:
java.lang.IllegalArgumentException: Embedded metastore is not allowed. Make sure you have set a valid value for hive.metastore.uris网上的千篇一律是抄袭的。 意思就是hive的uris没有设置,设置一下就好了
 那我这里设置了怎么没有好呢?
那我这里设置了怎么没有好呢?因为他们用的是flink-1.12会读取hive-site的文件
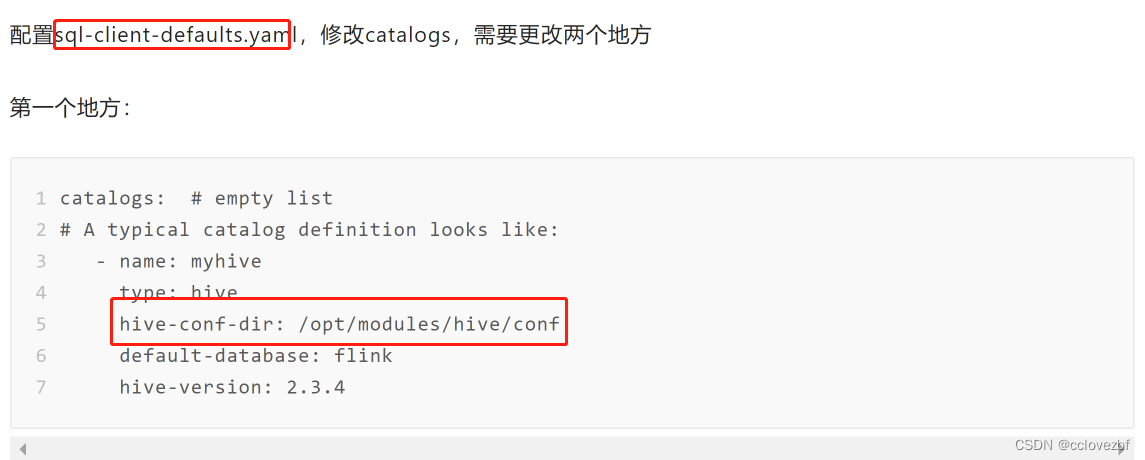
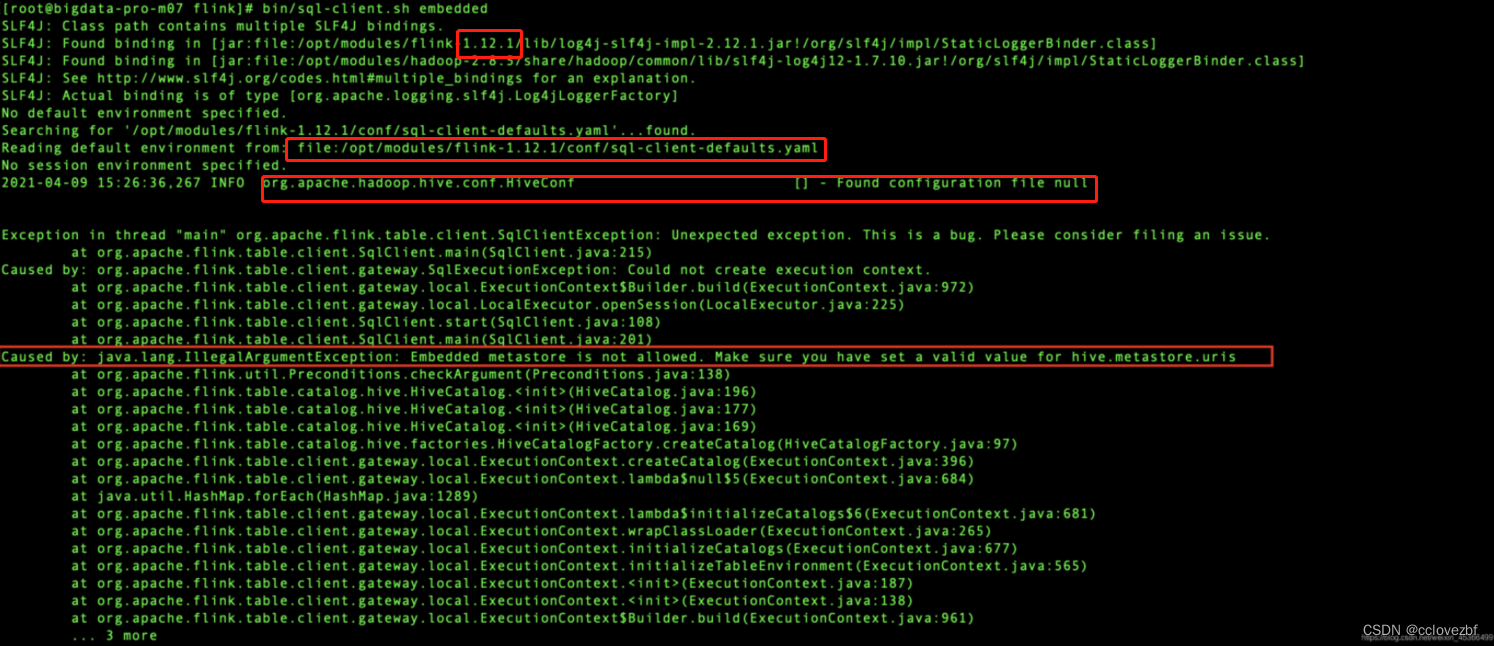
可是我这里1.14跟本没有sql-clients-defaults.yml文件 日志也没打印读取导hive文件 那我怎么搞?
flink1.14.0中集成hive3.1.2_硅谷工具人的博客-CSDN博客
尚硅谷还是吊,工具人很吊!!!
其实我也想到了 !!!!
当时我用了-h 帮助 也看到了-i 但是不知道-i初始的是什么文件。就复制了他们的一份sql-client-default.yml 证明没啥卵用,方向错了
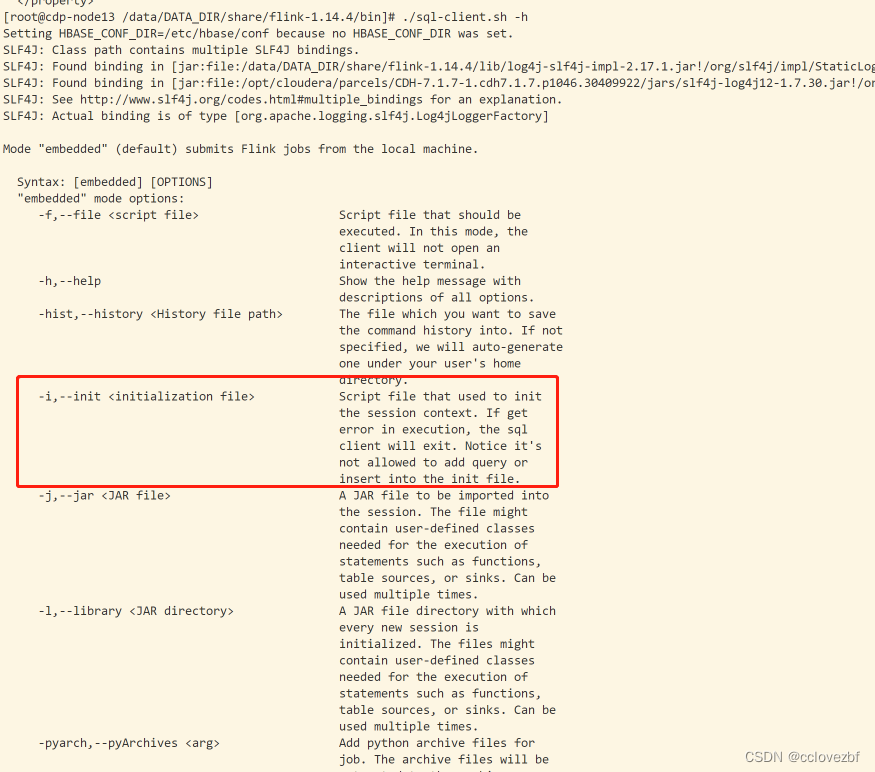
CREATE CATALOG myhive WITH (
'type' = 'hive',
'default-database' = 'default',
'hive-conf-dir' = '/etc/alternatives/hive-conf/',
'hadoop-conf-dir'='/etc/alternatives/hadoop-conf/'
);
--也可以不用hadoop 其实这里的时候就该反应过来,如果写过flink table api就知道连接hive的时候也是这两个参数

ctnn 这里又报了一个hive version的问题。
突然想到flink和hive也需要一个jar取连接,其实是我看了很多文章都提到了这个jar,下载地址
此时我已经有了
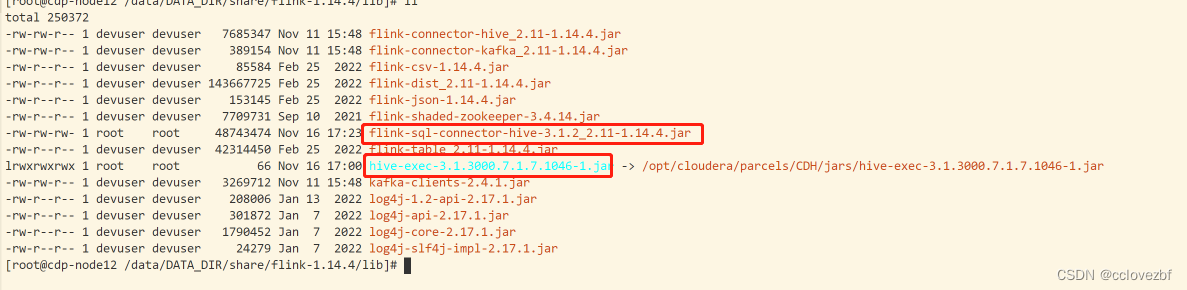
但是还是报错
Flink SQL> CREATE CATALOG myhive WITH (
> 'type' = 'hive',
> 'default-database' = 'default',
> 'hive-conf-dir' = '/etc/alternatives/hive-conf/',
> 'hadoop-conf-dir'='/etc/alternatives/hadoop-conf/'
> );
[ERROR] Could not execute SQL statement. Reason:
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;I)V看样子还是缺包。。。查了下可能是缺一个flink-shaded-hadoop-3.jar 直接mvnrepository.com
org.apache.flink
flink-shaded-hadoop-3
3.1.1.7.2.1.0-327-9.0
provided
然后
Flink SQL> CREATE CATALOG myhive WITH (
> 'type' = 'hive',
> 'default-database' = 'default',
> 'hive-conf-dir' = '/etc/alternatives/hive-conf/',
> 'hadoop-conf-dir'='/etc/alternatives/hadoop-conf/'
> );
[ERROR] Could not execute SQL statement. Reason:
java.lang.ClassNotFoundException: org.apache.htrace.core.Tracer$Builder遇到这种类找不到问题不要急,我遇到的可太多了,早有了一套从头到尾的解决办法。
org.apache.htrace.core.Tracer 这个类一看啥玩意啊,从来没见过怎么办?
记住我们是搞flink遇到的这个问题,那么这个类和flink肯定相关,找到一个我们引入flinkjar最多的工程。
 显示是htrace-core 这个jar
显示是htrace-core 这个jar打开maven插件 好像叫dependcy analyzer ,也可以mvn dependency:tree
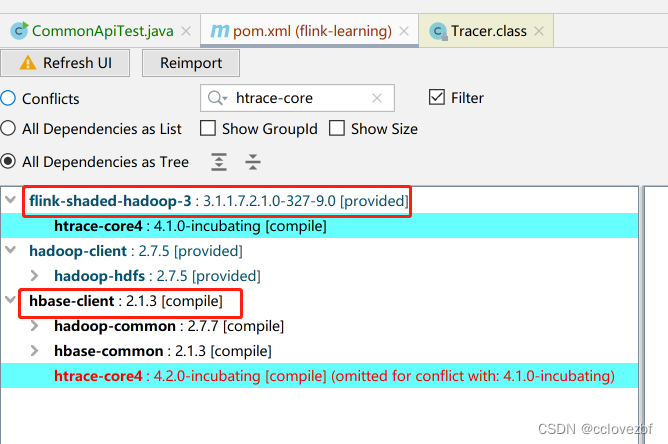
此时我们发现就是flink-shaded-hadoop-3这个jar的。

打开jar 没有啊。。。
所以又要上传这个jar,在自己的本地仓库找到后上传
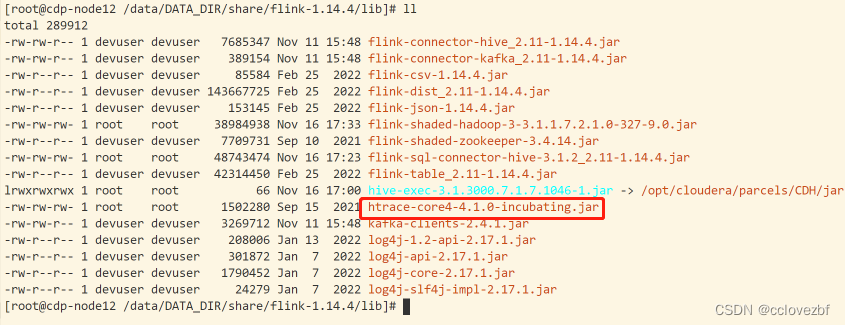
然后又开始报错!!!!!
Flink SQL> CREATE CATALOG myhive WITH (
> 'type' = 'hive',
> 'default-database' = 'default',
> 'hive-conf-dir' = '/etc/alternatives/hive-conf/',
> 'hadoop-conf-dir'='/etc/alternatives/hadoop-conf/'
> );
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.table.catalog.exceptions.CatalogException: Failed to create Hive Metastore client说实话已经快撑不住了。。。
看了log/下的日志
Caused by: org.apache.hadoop.hive.metastore.api.MetaException: Could not connect to meta store using any of the URIs provided. Most recent failure: org.apache.thrift.transport.TTransportException: GSS initiate failed
还好这里提到了一个GSS。应该是kerberos认证失败了。我再去修改配置 flink-conf.yml
flink-conf.yml
security.kerberos.login.use-ticket-cache: true //这个注释也试了。
security.kerberos.login.keytab: /data/DATA_DIR/share/keytab/hive.keytab
security.kerberos.login.principal: hive@CDP.COM还是不行。
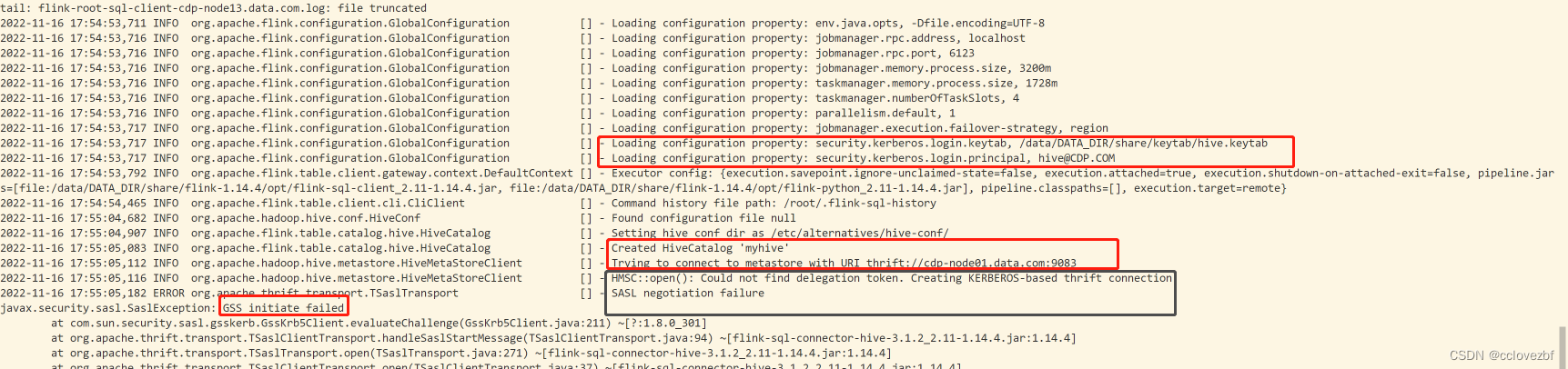
javax.security.sasl.SaslException: GSS initiate failed
Caused by: org.ietf.jgss.GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)
说实话吧这里应该还是kerberos的认证问题。
本身princple 和keytab是可以认证的。不知道哪里出了问题
 若有大神,虚心请假一波。
若有大神,虚心请假一波。 -
相关阅读:
Principal value
【2024秋招】2023-9-16 贝壳后端开发二面
前端工作总结113-点击按钮报错--bug修复--直接写接口里面
读 | SA : The Hard Parts 之代码复用
Java版Word开发工具Aspose.Words功能解析:在Word(DOCX / DOC)中插入或删除注释
记录下跑VUE+webpack-dev-server安装使用的问题
linux学习书籍推荐
AirServer最新Win64位个人版投屏软件
SNARK性能及安全——Verifier篇
HTML静态网页作业——基于html+css+javascript+jquery+bootstarp响应式成都家乡介绍网页
- 原文地址:https://blog.csdn.net/cclovezbf/article/details/127887149