-
在Jeston NX上部署运行PaddleOCR教程(安装whl包方法)
想在Jeston盒子部署PaddleOCR实现识别,但发现官方教程庞大,且教程间互相引用穿插,版本繁多,不够针对,这对刚刚接触的小白来说,会感觉无从下手,而且踩很多坑。因此用这篇博客特来记录一下Jeston盒子部署PaddleOCR(含paddlepaddle)过程
基本概念介绍
运行PaddleOCR,首先需要安装PaddlePaddle(Paddle Inference)这个基础推理框架,这就像是python执行函数之前首先要安装这个函数的包,这是必须的,不安装paddlepaddle,在跑ocr代码的时候是跑不起来的

而要安装paddlepaddle,需要确定安装的版本,这需要根据我们Jeston盒子中所安装的不同JetPack(CUDA+cuDnn+TensorRT)版本来选择,版本匹配才能安装。所以正确的部署步骤流程是:
1.确定盒子python+CUDA+cuDNN+TensorRT版本,或按需求安装对应版本
2.根据版本找到对应的paddlepaddle包,并安装
3.git clone PaddleOCR包,并安装或许有人会说,PaddleOCR没有提供docker吗?一个个安装和确认环境太累了!但事实是,在dockerHub-ppocr提供的是amd64架构的docker,在windows或amd/x86架构服务器可以直接部署,而这个盒子的架构是arm64/aarch64,而官方没有提供这个架构的docker,所以只能用whl安装,类似问题见架构问题
1.确定盒子环境python+CUDA+cuDNN+TensorRT版本
1.1 我还没有安装环境:一步到位整体安装
对于Jeston NX盒子,我们通常在装系统的时候在虚拟机使用NVIDIA SDK Manager工具对盒子进行整体JetPack的刷机安装(这个csdn有很多教程)。

一个JetPack会包含已经搭配好,互相兼容的python+CUDA+cuDNN+TensorRT,一步到位,非常方便。因此我们推荐在安装系统的同时,或者重新把盒子刷机的方式,来一次性安装所需环境,这里的JetPack也将和后面Paddle提供的包匹配,免去了很多版本不一致导致的bug。1.2 我已经安装了环境:查询盒子环境版本
对于Jeston NX盒子,可以安装jetson-stats包,然后执行
sudo jtop- 1
即可查询到盒子当前运行的cpu,gpu信息
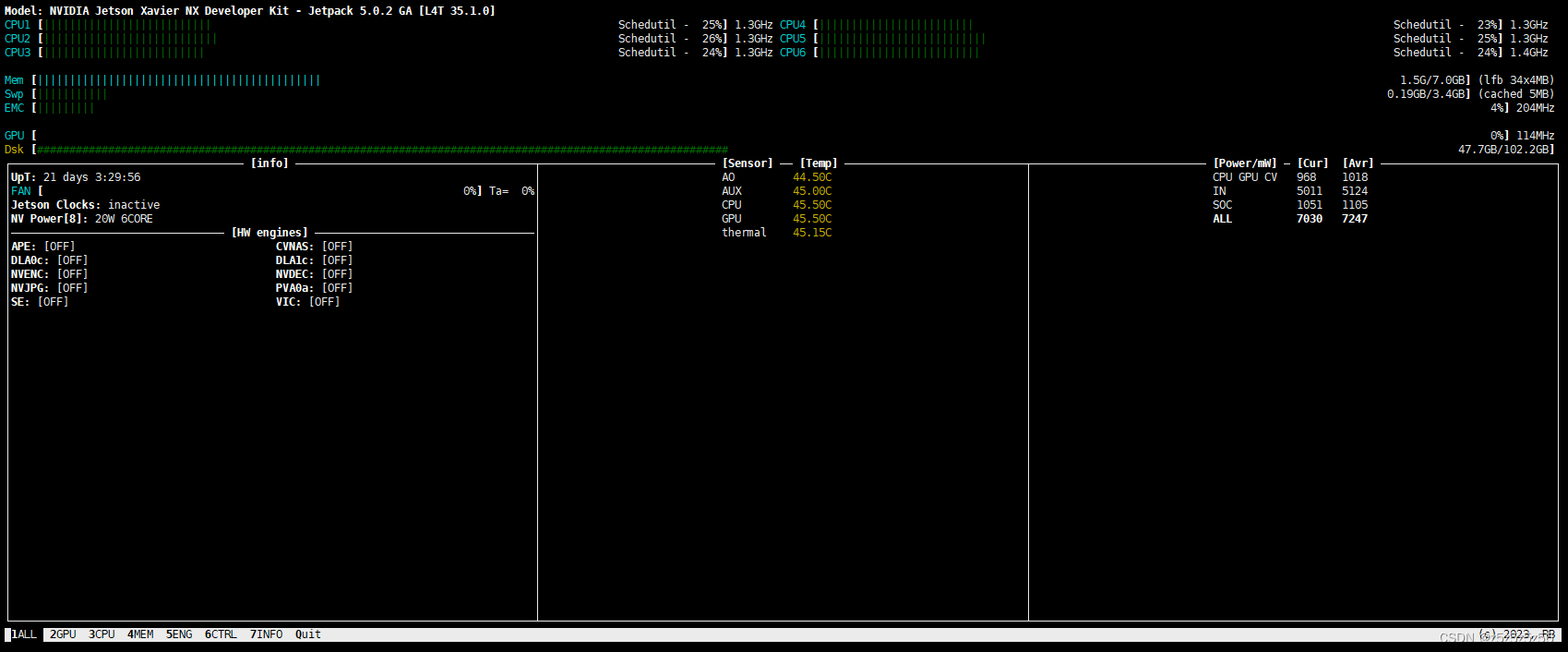
然后左下角有个info,点一下或者按7

这里就有JetPack,CUDA,cuDNN,TensorRT的所有版本信息
如果不是盒子,当然也有更普遍性的查询版本的指令:
- CUDA查询版本:
nvcc -V - cuDNN查询版本:
cat /usr/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
或cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
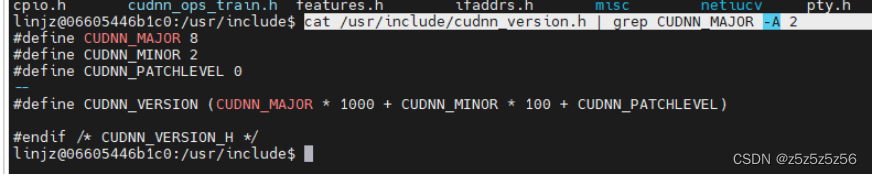
但这里,因为每个人安装的cuDNN位置可能不一样,所以可能会存在找不到但安装了的环境变量问题,这也是不用JetPack的麻烦的地方
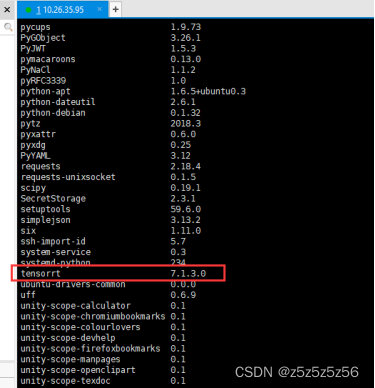
- TensorRT查询版本:可以使用
python import tensorrt或pip list来验证这个包是否安装
1.3 默认python版本设置
这是单独的一个小问题,盒子的linux可能会默认python为2.7版本,执行
whereis python可以知道本机有什么python(JetPack4.5.1对应带有python3.6.9),那么依次执行以下命令,可将python优先版本设置为3.6.9sudo update-alternatives --install /usr/bin/python python /usr/bin/python3.6 1 sudo update-alternatives --install /usr/bin/python python /usr/bin/python2.7 2 #这个命令可以列出当前可以设置优先级的版本 sudo update-alternatives --list python #输入3.6版本对应的数字即可 sudo update-alternatives --config python #查询优先的python版本,应该显示自己设置的3.6.9 python -V- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.安装PaddlePaddle
现在,我们搭好了Python,CUDA,cuDNN,TensorRT的环境,就可以在下载安装Linux推理库下载所需版本
例如,我的环境是Python3.8,CUDA11.4,cuDNN8.4.1,TensorRT8.4.1,盒子的架构是aarch64,对于NX盒子,则对应选择Jetpack5.0.2:nv-jetson-cuda11.4-cudnn8.4.1-trt8.4.1-jetpack5.0.2-xavier
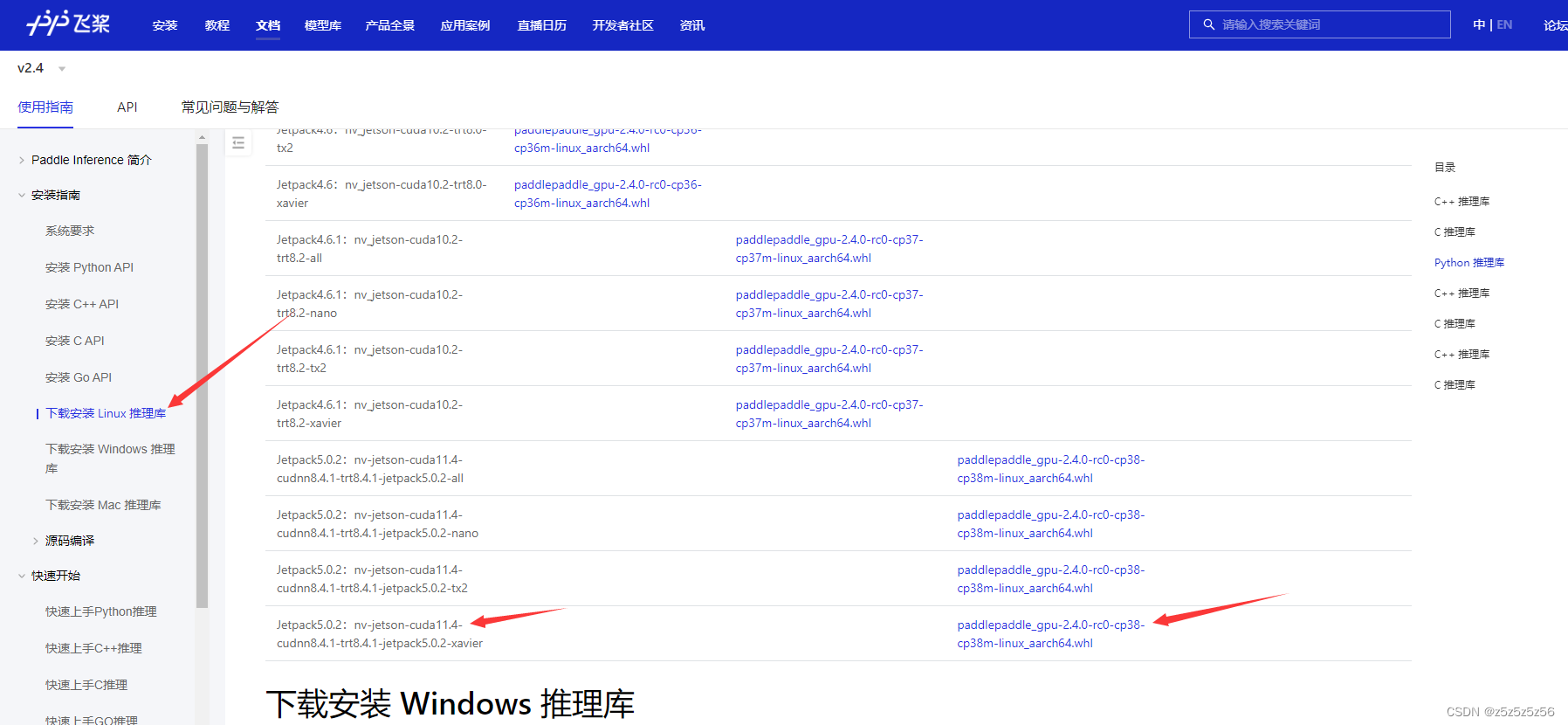
然后把它拷贝到盒子里(推荐xftp和xshell工具),并执行安装
pip3 install paddlepaddle_gpu-2.4.2-cp38-cp38-linux_aarch64 -i https://pypi.tuna.tsinghua.edu.cn/simple- 1
只有环境都符合要求,才能正常安装上,否则会报错的

为什么用whl包安装?因为这里有一个架构的安装坑,如果我们按官网https://www.paddlepaddle.org.cn/install/quick?docurl=/documentation/docs/zh/install/pip/linux-pip.html直接用指令安装PaddlePaddle,即
python -m pip install paddlepaddle-gpu==2.3.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
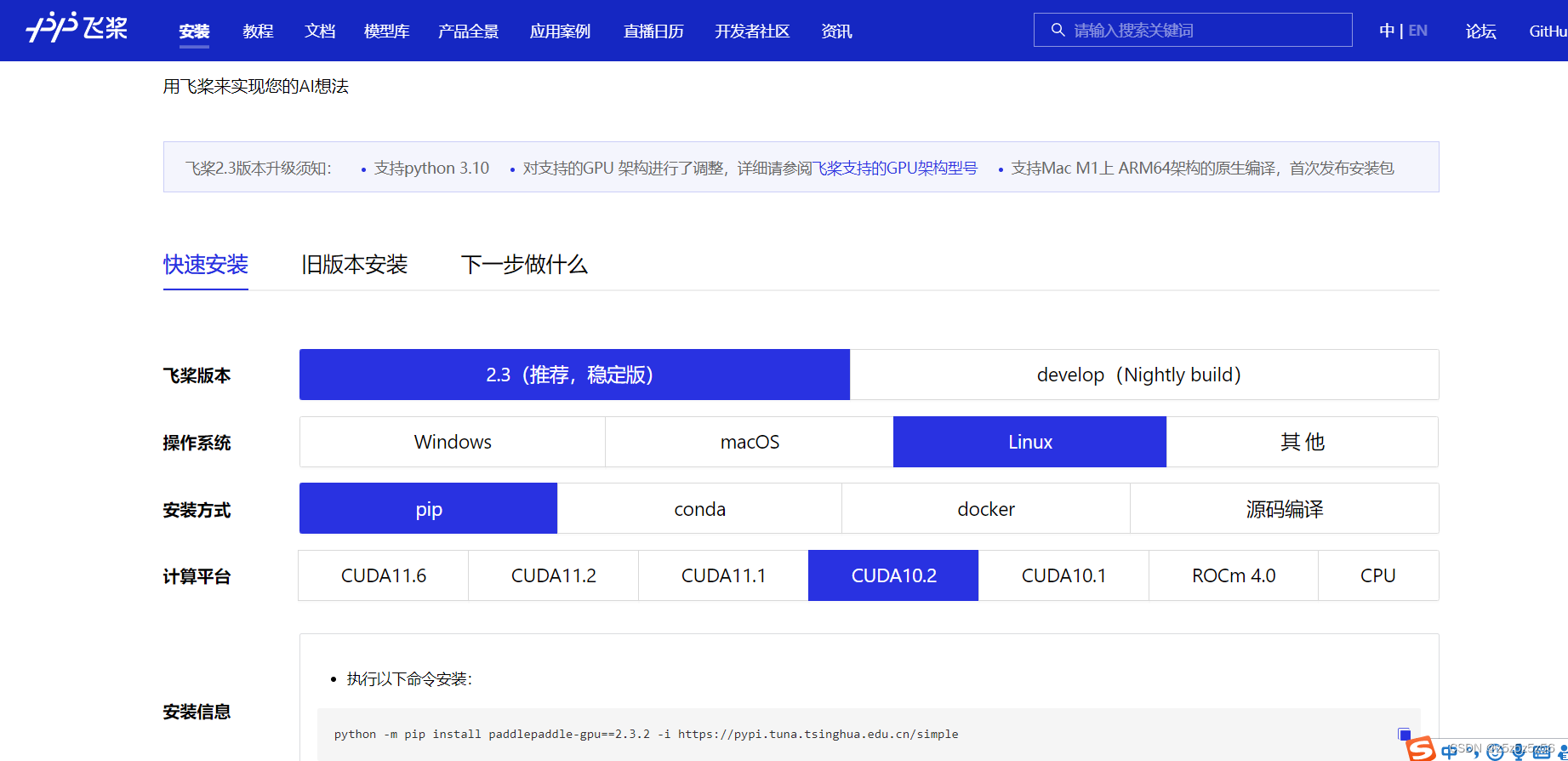
那么我们会发现安装不上,

这是因为NX的架构不同,(官网指南也有特别说明),架构可以用
python -c "import platform;print(platform.architecture()[0]);print(platform.machine())"
命令来查询,只有符合第一行输出的是”64bit”,第二行输出的是”x86_64”、”x64”或”AMD64”,才能用指令安装3. 下载PaddleOCR
安装好了paddlepaddle,即可去下载paddleOCR放进来执行
执行git clone https://gitee.com/paddlepaddle/PaddleOCR.git- 1
或者从https://github.com/PaddlePaddle/PaddleOCR下载压缩包解压放到盒子里
然后cd到PaddleOCR文件夹,安装requirementspip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple 缺skbuild pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-build- 1
- 2
- 3
4. 运行例程
在根目录新建一个文件夹放模型model,或者叫inference等自己取
sudo mkdir model sudo chmod 777 model- 1
- 2
项目自带一些识别图片在doc\imgs
下载模型:
链接见PaddleOCR\README_ch.md中
我这边下载的是中英文的推理模型,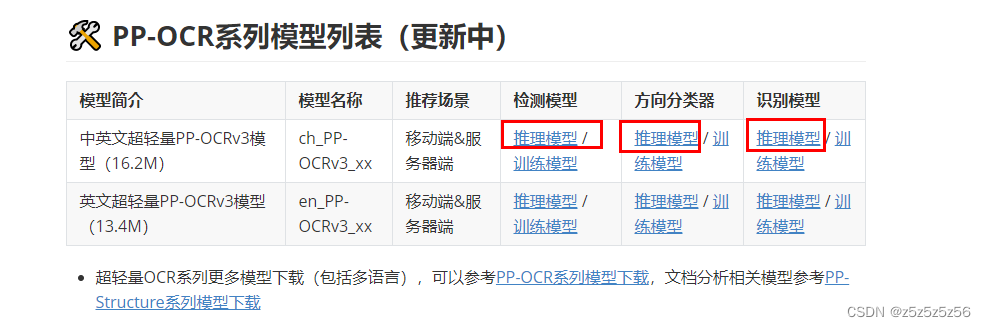
因为我们这边是直接拿来用所以下载的是推理模型,如果要训练或者微调优化则下载训练模型
也可通过命令下载解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar tar xf ch_PP-OCRv3_det_infer.tar tar xf ch_PP-OCRv3_rec_infer.tar- 1
- 2
- 3
- 4
(更多模型可以见doc/doc_ch/models_list.md)
把下载的模型放在项目文件夹下model文件夹中
然后在项目根目录,即可执行文本检测: python tools/infer/predict_det.py --det_model_dir=model/ch_PP-OCRv3_det_infer/ --image_dir=doc/imgs/11.jpg --use_gpu=True 文本识别: python tools/infer/predict_rec.py --rec_model_dir=model/ch_PP-OCRv3_rec_infer --image_dir=doc/imgs/11.jpg --use_gpu=True --rec_image_shape="3,48,320" 文本检测+识别: python tools/infer/predict_system.py --det_model_dir=model/ch_PP-OCRv3_det_infer --rec_model_dir=model/ch_PP-OCRv3_rec_infer --image_dir=doc/imgs/11.jpg --use_gpu=True --rec_image_shape="3,48,320" 开启TRT预测只需要在以上命令基础上设置`--use_tensorrt=True`即可- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如果运行会报错
OSError: Could not find lib geos_c or load any of its variants ['libgeos_c.so.1', 'libgeos_c.so'].
可参考这里以文本检测+识别为例,运行命令,终端会显示识别结果和推理时间

我们在项目根目录运行,则运行结果会保存在根目录的inference_results文件夹里,含有识别文字的位置和内容,以及可视化识别结果


5. 后续工作
PaddleOCR提供了TensorRT加速的方法,后续可以根据教程,提高识别速度
GPU TensorRT 加速推理(NV-GPU/Jetson)
附:参考教程合集
PaddleOCR的Jeston系列部署教程:(在paddleOCR项目工程里)
PaddleOCR\deploy\Jetson\readme_ch.md盒子安装PaddlePaddle
教你如何在三步内Jetson系列上安装PaddlePaddlePaddlePaddle在jetson NX的配置
【项目经验】Jetson xavier nx开发板-从裸机到深度学习环境配置
从0到1教你在Jetson Xavier NX玩转PaddlePaddle!end
-
相关阅读:
洛谷P2065 [TJOI2011] 卡片
schtasks windows定时任务参数及常见问题
PowerBI中导出数据方法汇总
Vue入门(二)
北京和周边景点指南
n皇后问题,不用递归
阿里云视频点播
安卓隐藏状态栏和导航栏
切面Aspect + 策略模式实现待办提醒功能
Docker-可视化管理工具总结-推荐使用Portainer
- 原文地址:https://blog.csdn.net/z5z5z5z56/article/details/127863303