-
MySQL查询优化实例
| 导语 通过几个小实例,对实际会经常用到的查询进行对比,通过MySQL的执行计划分析语句的执行性能,最后分析几个在实际中会遇到的小问题。
我们知道一般应用系统的读写比列在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,所以查询语句的优化是非常重要的。
一、测试环境
本篇文章从几个实例来看下MySQL数据库查询优化的过程。测试环境为Windows7专业版(64位,内存16G),MySQL5.7.22
二、前期准备
分别构建student,score,exam三张表,如下:
CREATE TABLE student( idno bigint auto_increment primary key comment '学号' ,s_name varchar(128) comment '姓名' ,s_sex varchar(1) comment '性别' ,s_inyear varchar(4) comment '入学年份' ,s_score double comment '入学成绩' ,key(s_name) ); create table score( idno bigint comment '学号' ,exam_no bigint comment '考试编号' ,score double comment '考试成绩' ); create table exam( exam_no bigint comment '考试标号' ,exam_name varchar(128) comment '考试名称' ,exam_time datetime comment '考试时间' ,class_name varchar(16) comment '科目名,语文/数学/物理/化学等' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
三、查询语句实例
根据上面的三张表,我们分别对以下的查询语句以及问题进行分析(student表:6038386条数据;socre表:6018386条数据;exam表:6018385条数据)(注:生成的数据有问题,但不影响前面的单表数据查询)
1、 如果取出一个姓名对应的学号,那么以下两个语句的区别:
a) select * from student where s_name='张三'; b) select idno from student where s_name='张三';- 1
- 2
1)首先是最直观的不同点,查询结果不同,select * 会把对应的s_name所在的列的值都查询处理,select idno 会把s_name对应的idno选出来;
2)查询性能不同,select * 会把先查询出所有的列(Query Table Metadata For Columns),这在一定程度上增加了数据库执行的负担,然后再执行查询操作;select idno则不用进行查询出所有列,直接查询出所需的列值。在数据量比较低时,查询性能几乎相同,但是当数据量非常大的时候,使用select * 的查询性能要低些。
分析:首先我们根据实际查询时间来看(这里我们使用数据库中有名字的做为测试)
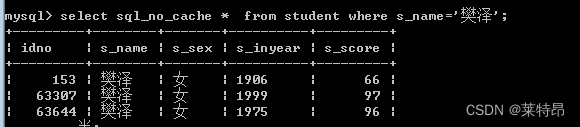



可以明显看出a语句的执行时间要长于b语句查看两条语句的执行计划
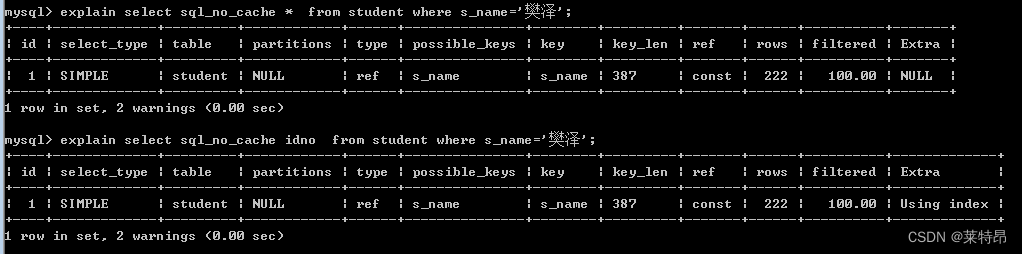
可以看到b语句使用了索引进行查询。
在b语句中由于查询的列为idno,idno属于索引,所以这个索引就是这个查询的覆盖索引,MySQL可以不用读取数据,直接使用index里面的值就可以返回查询结果,而a语句中使用了select *,除了读取idno外还要读取其他列的值,因此在读取完index里面的值后还要再去读取数据才会返回结果。当返回行数比较多,并且读取数据需要进行IO操作时,会出现差异。
2、 取出所有姓张的人的姓名跟学号,以下两个语句的区别:
a) select idno,s_name from student where substr(s_name,1,1)='张'; b) select idno,s_name from student where s_name like '张%';- 1
- 2
在实际环境执行,结果如下:
a语句执行结果
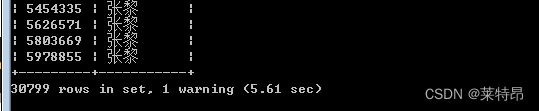
b语句执行结果

从实际执行结果看b语句要明显优于a语句。分析:a语句由于对字段进行了函数操作,会导致数据库引擎放弃使用索引而进行全表扫描,从而使得在性能上a语句没有b语句高。
通过explain查看两条语句,
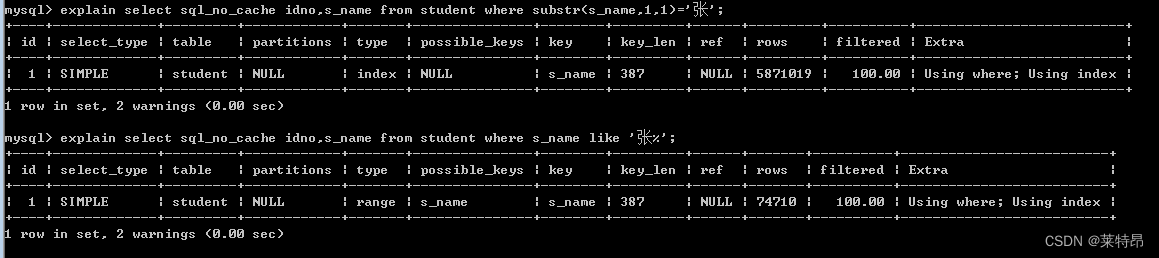
可以看到a语句中 possible_keys为NULL,即说明没有索引满足所要查询的条件,而且根据type可以看到a语句的访问类型为index,b语句的访问类型为range,a语句性能要低于b语句,从rows可以更明显的看出性能的高低,a语句预估计需要查询5871019条数据,而b语句只需要查询74710条数据,性能明显高很多。3、 假设有100w学生数据,那么找出2012年入学成绩最好的100名学生,语句要怎么写,性能如何? 如果要提高性能的话,需要修改表结构吗,请说明原因?
语句如下:
select idno,s_name,s_sex,s_inyear,s_score from student where s_inyear='2012' order by s_score desc limit 100;- 1
- 2
- 3
- 4
- 5
首先查看下语句执行结果

分析:查看下sql语句的执行计划

可以看到sql语句查询使用的是全表扫描,效率要低,而且需要再筛选出前100条数据,除了全表扫描外还需要对数据进行排序(Using filesort),而排序是相当耗时的,所以本句的查询性能比较低。解决方式添加索引:
本条sql语句要想提高查询性能可以通过添加索引的方式。MySQL中每次查询只使用一个索引,另外进行查询时索引使用最左前缀匹配原则,由于查询中where子句用到了字段s_inyear以及order by 子句用到了字段s_score,要满足使用where子句与order 子字句条件列组合满足索引最左前列。修改表结构添加索引语句如下:
create index year_score on student(s_inyear(4),s_score);- 1
再次执行sql查询语句

效率明显提高分析:查看加上索引后sql的执行计划

可以看到加入索引后查询使用了索引,而且rows数量明显小于未加索引的数量,而且没有了Using filesort,即没有使用外部排序了。加上索引后,由于使用的MySQL数据库引擎为INNODB,建立的是BTree索引,在查询过程中除了使用索引外,由于BTree索引本身就是有序的,所以不需要进行排序,查询性能就会很高。未加索引就需要额外的排序,性能就会比较低。
4、select count(1),count(*),count(s_name) from student; 这几个count语义上的差异
count(1)和count()对行的数目进行计算都包括对NULL的统计,在语义上是等价的,性能也是一样的;
count(s_name)是对s_name列的值具有的行数进行计算不包括对NULL的统计。

count(列名)的语义及性能要考虑几方面因素。主要是要考虑列名是否为空,主键不为空,count(主键)的语义和count()以及count(1)等价,而且性能也相同,但是当列名可以为空的时候就需要通过索引来判断是否需要扫描原表数据,因此性能上也会有差异。5、假设idno跟s_name都是全表唯一的,那么以下两个语句结果一样,但是性能上有差异吗?如果性能有差异,那么慢的那个SQL要怎么优化才比较快
a) select count(distinct s_name) from student; b) select count(distinct idno) from student;- 1
- 2
两条语句执行结果(显示条数不同是由于存在着同名的情况)

分析:两条语句的执行计划

select count(distinct s_name) from student;中由于s_name是非唯一键,所以在进行distinct s_name时需要使用group by 进行排序去重;而idno为表的主键,其是非空且唯一,所以在进行distinct idno时不需要进行排序去重 ,count(distinct idno)在语义上和count(idno)是没有区别的。所以在性能上select count(distinct idno) from student要高些。如果要提高性能,由于s_name是唯一的,则直接在s_name上添加一个唯一性约束就可以。
alter table student add unique key(s_name);- 1
6、学号是递增的,但是学号的起始跟结束不知道,那么现在想找出随机一名女同学(男女比例基本1:1)应该怎么写SQL,性能会比较高
1)最简单的一种写法,但是性能非常低
select idno,s_name,s_sex,s_inyear,s_score from student where s_sex='女' order by rand() limit 1;- 1
- 2
- 3
- 4
- 5
性能低的原因是rand()放在order by子句中会被执行多次,而且会进行排序操作,耗时增加,性能降低(通过后面的执行计划可以看的到)。
2)使用join的写法
select idno,s_name,s_sex,s_inyear,s_score from student as t1 join (select floor( (select min(idno) from student)+ rand()*((select max(idno) from student)- (select min(idno) from student)+1 )) as id) as t2 where t1.idno>=t2.id and t1. s_sex='女' order by t1.idno limit 1;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
思路:由于不知道学号的起始和结束,但是学号是递增的,所以根据rand()函数生成一个位于最大和最小之间的学号。为了使效率比较高,根据查到的资料,在where子句中的select会针对外部select取出的每一行执行一次,效率非常低。内部的select生成一个临时表,通过join连接时,加入了所有大于等于随机生成的idno,并且当直接匹配不存在时,只选择最邻近的一条记录,一旦找到一条满足条件的数据,就停止(使用 limit 1),这样性能会比较高。
查看执行计划
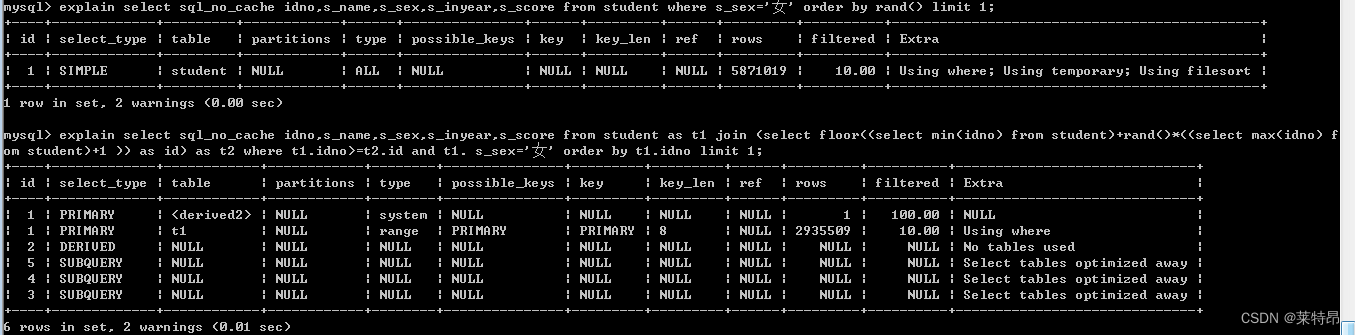
通过查看执行计划,第一条语句使用了全表扫描,而且预估计查询的条数rows相当大,进行了排序操作(Using filesort)性能比较低,而第二条语句中预估计查询条数rows为第一句的一半,而且使用了索引,并未进行排序,性能会明显提升。注:以上生成的数据有问题,但是在进行单表操作时并不影响实验结果,现重新生成数据(student表:1801631条,score表:1800340,exam表:24条)
下面7,8,9三种查询中条件和排序涉及到了idno,s_name,exam_no, score,exam_time,exam_name,class_name几个字段。为了和添加索引后执行性能相互进行比较,我们分享并添加索引如下。
第一个查询语句中涉及到的字段为class_name,exam_time,exam_no,idno; 第二个查询语句中涉及到的字段为exam_name,exam_no,idno; 第三个查询语句中涉及到的字段为exam_time,class_name,exam_no,idno,score;- 1
- 2
- 3
这几个字段分别属于表score,exam。而表score和表exam没有主键,主键作为索引效率会非常高,所以还需要给这两个表添加主键。为了使得索引达到最优,既要使得索引满足最左前缀匹配规则,又要使得让区分度大的字段位于多列索引的前面,所以建立索引如下:
alter table score add primary key(idno,exam_no); alter table exam add primary key(exam_no); create index class_no_time on exam(class_name,exam_no,exam_time); create index name_time on exam(exam_name,exam_time); create index no_score on score(exam_no,score);- 1
- 2
- 3
- 4
- 5
7、查出张三,所有语文科目的考试成绩,按照时间进行排序
select t1.s_name,t3.class_name,t2.score,t3.exam_time from student as t1 join score as t2 on t1.idno=t2.idno and t1.s_name='张三' join exam as t3 on t2.exam_no=t3.exam_no and t3.class_name='语文' order by t3.exam_time desc;- 1
- 2
- 3
- 4
- 5
未加索引执行结果及执行计划
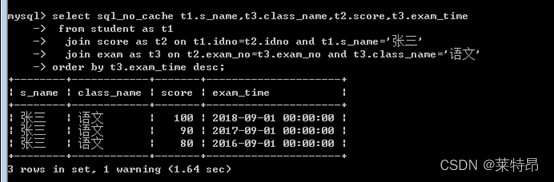

添加索引后执行结果及执行计划
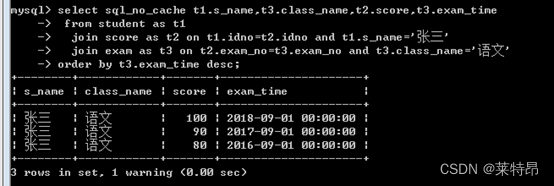

可以看到添加索引后执行时间明显降低,查看执行计划可以看到查询中使用到索引,预估计查询行数rows明显降低,而且没有使用相当耗时的Using join buffer(Block Nested Loop)操作。8、找出没有参加exam_name='2016级语文入学考试’的所有学生学号及姓名,要求至少要写出两种查询SQL
1)使用not in筛选
select idno,s_name from student as t1 where t1.idno not in (select idno from score as t2 join exam as t3 on t2.exam_no=t3.exam_no and t3.exam_name='2016级语文入学考试' );- 1
- 2
- 3
- 4
- 5
- 6
- 7
思路:筛选出参加考试的学生idno,然后通过获取不在其中的学生的idno来获取数据。
未加索引执行结果及执行计划(数据量较大取前100条数据)

加索引后执行结果及执行计划

2)使用join筛选select t1.idno,t1.s_name from student as t1 left join (select t2.idno,t2.exam_no from score as t2 join exam as t3 on t2.exam_no=t3.exam_no and t3. exam_name='2016级语文入学考试' ) as t4 on t1.idno=t4.idno where t4.exam_no is null;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
思路: 通过left join的特性,连接后左表的所有行都保留,但是右表不存在的行会被设置为NULL,最后通过NULL这个特性来筛选出符合条件的数据。 但是该条语句在未加索引时,执行的效率非常慢,性能非常低。该语句在未加索引的执行计划如下,可以看到possible_keys为NULL,另外查询中使用到了Using join buffer(Block Nested Loop),而且使用left join连接表会生成很多无用的数据行,最后再被筛选出符合条件的结果。该条语句的执行效率会非常低下。- 1
- 2
- 3

加入索引后执行结果及执行计划

9、请找出2018-09-04日的语文考试,成绩前十的学生姓名
两种写法,但是性能差别较大
写法一:
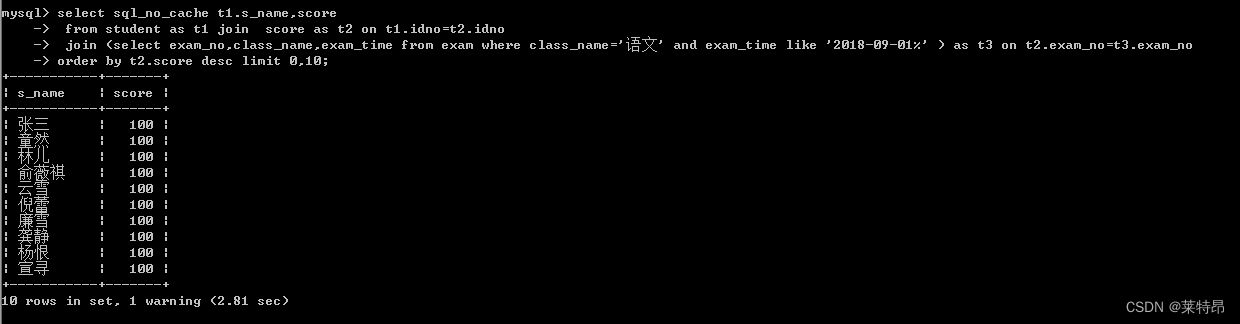
select t1.s_name,score from student as t1 join score as t2 on t1.idno=t2.idno join (select exam_no,class_name,exam_time from exam where class_name='语文' and exam_time like '2018-09-01%' ) as t3 on t2.exam_no=t3.exam_no order by t2.score desc limit 0,10;- 1
- 2
- 3
- 4
未加索引执行结果(2.81s)

写法二:
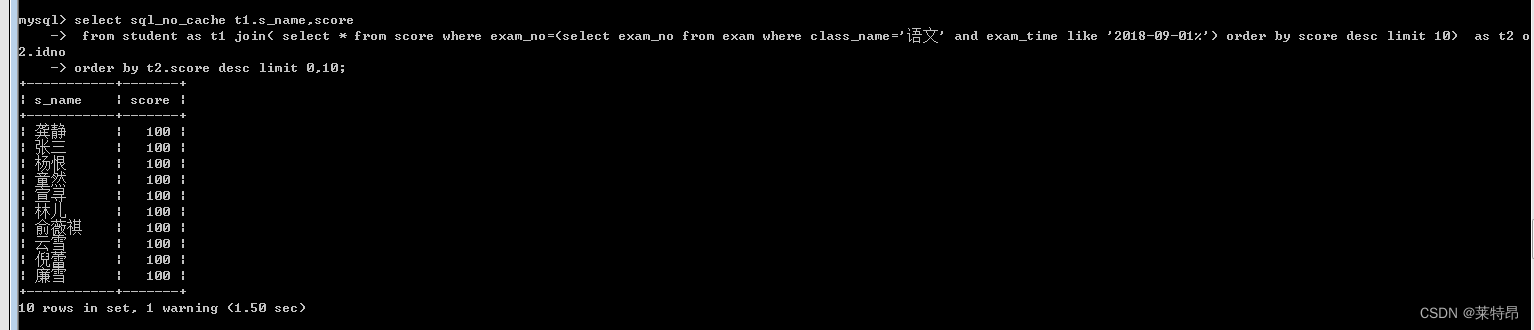
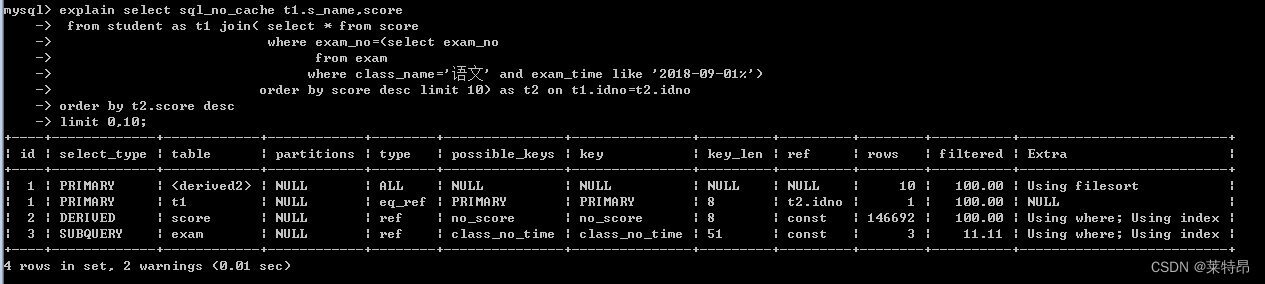
select t1.s_name,score from student as t1 join( select * from score where exam_no=(select exam_no from exam where class_name='语文' and exam_time like '2018-09-01%') order by score desc limit 10) as t2 on t1.idno=t2.idno order by t2.score desc limit 0,10;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
未加索引执行结果(1.5s)

加入索引执行结果及执行计划
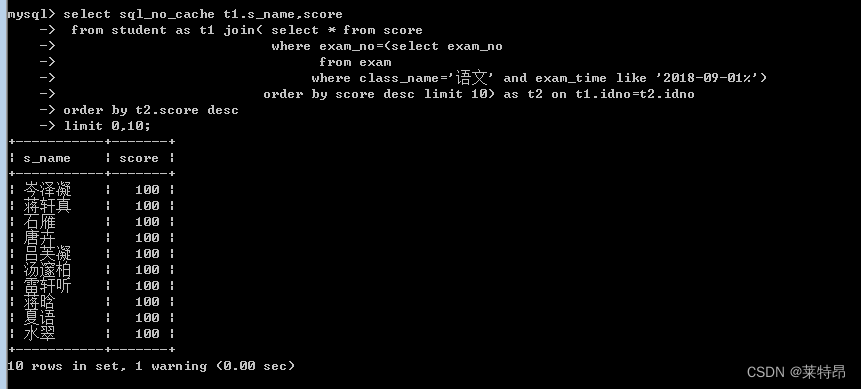
两种不同写法的性能区别:
写法一先根据条件从exam表中获取到符合条件的考试,但是exam表理论上数据量不是太大,而student表和score表数据量都比较大,其联合结果后数据量非常大,然后再对联合后的数据进行排序,性能就会变得低下。
写法二 是由于先对score表进行了筛选,选出符合条件的成绩排名前10的十条数据,然后再选出这10个学生的姓名,最后对这10条数据进行排序,处理的数据量明显减少只有20条,性能会很高。
分析:通过比较加索引前后的实际执行情况以及执行计划,可以看到添加索引后执行耗时都会明显降低,而且在执行计划中都使用到了索引,而且都没有再使用Using join buffer(Block Nested Loop)进行嵌套循环处理,提高了查询的效率。
四、查询字段类型匹配问题
新建表,并插入数据
create table test_convert(id varchar(128) primary key,value varchar(128)); insert into test_convert values('1a','hello'),('1b','world'),('1','hello'),('2','world'),('3','cxf');- 1
- 2
- 3
1、以下语句查出来的结果为什么会出现这种情况:
mysql> select * from test_convert where id=1;
±—±------+
| id | value |
±—±------+
| 1 | hello |
| 1a | hello |
| 1b | world |
±—±------+
3 rows in set, 2 warnings (0.04 sec)
mysql> select * from test_convert where id=‘1’;
±—±------+
| id | value |
±—±------+
| 1 | hello |
±—±------+
1 row in set (0.04 sec)
MySQL在比较的时候,由于比较的两个字符串类型不同,String是有可能被转换为数字的,对于数字开头的字符串来说,转为数字的结果就是截取前面的数字部分,所以结果1是有问题的。而的2结果是正确的。
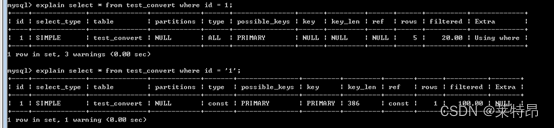
2、假设数据都是数字,那么从性能上分析以下两个语句的性能差异:
select * from test_convert where id = 1; select * from test_convert where id = '1';- 1
- 2
由于所有数据都是数字,第一句中由于id=1 和字段类型为varchar不匹配,即相比较的两个类型不匹配,索引会失效,所以性能没有id = '1’好。
通过执行计划可以看到第一句中由于类型不匹配,索引失效病没有使用索引进行查询,而是使用了全表扫描。
五、连接查询中的join,left join,right join
建表如下:
create table test1(c1 varchar(5),c2 varchar(5)); create table test2(c3 varchar(5),c4 varchar(5));- 1
- 2
insert into test1 values('1','n1'),('2','n2'),('3','n3'),('4','n4'),('5','n5'); insert into test2 values('n1','aa'),('n2','bb'),('n3','cc'),('n6','ff');- 1
- 2
- 3
- 4
1、join,left join,right join的区别
(a) join语句
执行join语句不加条件
select * from test1 join test2;- 1
其结果和语句
select * from test1,test2;- 1
执行结果都是一样的,获取到的数据都是笛卡尔积。
在加上on条件后
select * from test t1 join test2 t2 on t1.c2=t2.c3;- 1
其结果
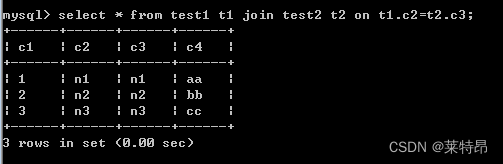
和语句
select * from test1 t1,test2 t2 where t1.c2=t2.c3;- 1
的结果是一样的。
join语句执行的结果和普通的where语句执行的结果是一样的,但是join的写法相对于普通where语句的写法更容易理解,逻辑更加清晰,推荐使用join来进行书写。
(b) left join语句
执行语句
select * from test1 t1 left join test2 t2 on t1.c2=t2.c3;- 1
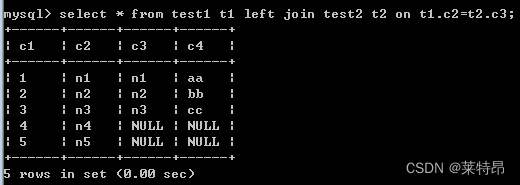
通过结果可以看到left join语句相比于join语句在同等条件下,会多出数据记录来,多出的数据记录是left join左侧即表test1的不符合条件的数据记录,右侧表使用NULL来填充。也就是说左连接中左侧表中的所有记录都会被展示出来,其中左侧表中符合条件的记录会和右侧表中符合条件的记录相互连接组合,而左侧不符合条件的记录会和NULL进行连接。
© right join语句
select * from test1 t1 right join test2 t2 on t1.c2=t2.c3;- 1
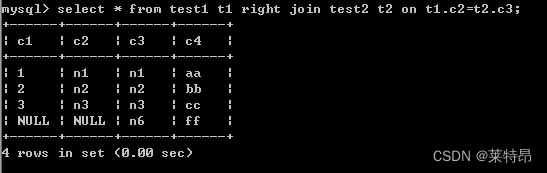
可以看到right join执行的结果和left join执行的结果不同之处是right join右侧表中的所有记录都会被展示出来,不符合条件的记录会和NULl进行连接。
2、连接查询中on条件和where条件区别
分别来看两条语句的查询结果
select * from test1 t1 left join test2 t2 on t1.c2=t2.c3 where t2.c4='aa'; select * from test1 t1 left join test2 t2 on t1.c2=t2.c3 and t2.c4='aa';- 1
- 2
- 3
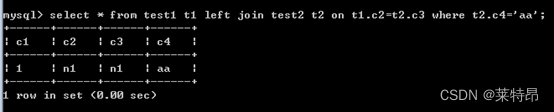
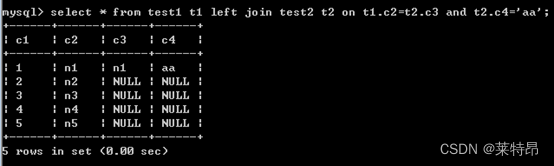
通过查看执行结果,会发现on在执行时会比where先起作用,第一句执行的过程是先通过on条件生成满足条件的临时表,然后再通过where条件进行筛选;第二句执行的过程是首先通过on后面跟随的and条件筛选出test2表中c4='aa’的记录,然后再和左表进行连接,因此会保留左表中的所有记录。
在多表查询时,on会比where更早起作用,系统会首先根据各个表之间的连接条件,把多个表连接成一个临时表,然后再通过where条件进行过滤。对于左连接或右连接的关联操作,如果那些不符合条的记录也需要出现在查询中,就必须把条件放在on的后面,如果放在where条件的后面,左连接或右连接就不起作用会等同于join连接操作。
-
相关阅读:
QT-输入输出
-贪吃蛇-
『现学现忘』Git基础 — 1、版本控制系统介绍
跟随鼠标的粒子特效分享
机器学习处理问题的基本路线
鸿蒙HarmonyOS实战-ArkUI事件(手势方法)
164. 最大间距
linux 系统安装 or-tools 并在c++ 项目中使用
【多传感器融合定位】【学习汇总】
springboot+小程序老年人健康保障管理系统毕业设计源码302303
- 原文地址:https://blog.csdn.net/weixin_44139651/article/details/127887751
