-
Python如何使用HanNLP工具
目录
目标:使用pycharm调用HanNLP工具完成对文本的分词、自动摘要、关键词提取等任务。
系统安装配置 JDK 1.8
1、windows环境下载 JDK 1.8
2、安装 JDK 1.8

3、配置环境变量

变量名:JAVA_HOME变量值:C:\Program Files\Java\jdk1.8.0_101

双击Path,编辑Path环境变量,
点击新建,添加“%JAVA_HOME%\bin”
再次点击新建,添加“%JAVA_HOME%\jre\bin”

新建环境变量CLASSPATH
变量名:CLASSPATH
变量值:.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
需要注意变量值前面的“.;”

4、测试 JDK是否安装成功
win+r运行cmd

执行有结果表示配置成功
命令:java

命令: javac

系统安装 Visual C++ 2015
安装详看 : https://jingyan.baidu.com/article/e73e26c088e45424acb6a759.html
下载 HanNLP 包
1、下载hanlp.jar包解压 : https://github.com/hankcs/HanLP
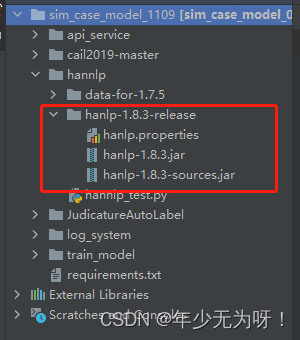
2、下载data.zip: https://github.com/hankcs/HanLP/releases中 http://hanlp.linrunsoft.com/release/data-for-1.7.0.zip 后解压数据包
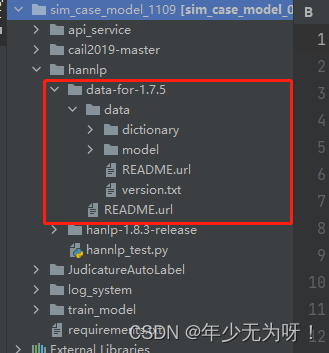
最终将data与hannlp解压的jar包统一放在一个目录下【之前不在一个目录报错】

测试HanNLP工具
from jpype import * startJVM(getDefaultJVMPath(), "-Djava.class.path=hanlp-1.8.3.jar") # 加载java中模型 HanLP = JClass('com.hankcs.hanlp.HanLP') NLPTokenizer = JClass('com.hankcs.hanlp.tokenizer.NLPTokenizer') # 目标据句 document = "徐先生还具体帮助他确定了把画雄鹰、松鼠和麻雀作为主攻目标。" # 分词与词性标注 seg_list = HanLP.segment("你好,欢迎在Python中调用HanLP的API") print(seg_list) # 关键词提取 print(HanLP.extractKeyword(document, 20)) # 自动摘要 print(HanLP.extractSummary(document, int(len(document)/3))) # 依存句法分析 print(HanLP.parseDependency(document)) # 命名实体识别与词性标注 print(NLPTokenizer.segment(document)) shutdownJVM()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
-
相关阅读:
redis八股1
LayUI多文件上传,支持历史上传预览
图扑软件数字孪生 3D 风电场,智慧风电之海上风电
聚焦创新丨赛宁网安亮相2022未来网络发展大会成果展
Springboot老来福平台682f5计算机毕业设计-课程设计-期末作业-毕设程序代做
char*与char[]的区别
无线产品欧盟CE认证RED指令测试要求解读
GBase 8a性能优化之资源管理
Android 11.0 mt6771新增分区功能实现三
Python - Numpy库的使用(简单易懂)
- 原文地址:https://blog.csdn.net/qq_19409845/article/details/127880396
