-
【Java项目】讲讲我用Java爬虫获取LOL英雄数据与图片(附源码)
🚀用Java爬一下英雄联盟数据
📓推荐网站(不断完善中):个人博客
📌个人主页:个人主页
👉相关专栏:CSDN专栏
🏝立志赚钱,干活想躺,瞎分享的摸鱼工程师一枚

🏖前言
本章内容为一个实战项目,主要的实战方向为使用Javad的
WebMagic爬虫框架来爬取LOL的英雄资料和一些图片。本章节需要学习的小伙伴们具备一些初步的JavaSE知识,以及最好能对Maven进行使用。
如果你还不知道
Maven是什么,以及不知道如何创建一个Maven项目的话,请移步:Maven教程传送门那么我们就开始吧!
1.什么是爬虫?
爬虫是指使用代码模拟用户批量发送网络请求,批量获取数据的行为。
通俗点来来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
我们见到的最常见的爬虫就是比如
百度、谷歌..之类的搜索引擎1.1爬虫亦有善恶
我们知道互联网也是一个江湖,在这个大江湖之中,爬虫也是区分善恶的(当然这只是一个概念)。
其实说白了呢就是看使用者如何去使用它。
- 像谷歌这样的搜索引擎爬虫,每隔几天对全网的网页扫一遍,供大家查阅,各个被扫的网站大都很开心。这种就被定义为「善意爬虫」。
- 但是,像抢票软件这样的爬虫,对着 12306 每秒钟恨不得撸几万次。铁总并不觉得很开心。这种就被定义为「恶意爬虫」。(注意,抢票的你觉得开心没用,被扫描的网站觉得不开心,它就是恶意的。)
- 为什么说12306不开心呢,因为在20年前的一份数据表明
12306最高峰时 1 天内页面浏览量达 813.4 亿次,1 小时最高点击量 59.3 亿次,平均每秒 164.8 万次。相信如果被这样捕捉的服务器是你的服务器,你也不会开心的。
- 为什么说12306不开心呢,因为在20年前的一份数据表明
1.2.爬虫的本质
实质上爬虫的本质就是模拟人为打开浏览器,然后去获取页面上的信息。
只不过这种人为的动作被我们的代码所代替。
1.3.爬虫的基本流程
对于初学者入门来说,其实爬虫的基本流程主要在四步
1.请求目标链接 -> 2.获取响应内容 -> 3.解析内容 -> 4.存储数据
- 请求目标链接:发起一个带有header、请求参数等信息的Request,等待服务器响应
- 获取服务器响应内容:服务器正常响应后,Response的内容即包含所有页面内容(可以是HTML、JSON字符串、二进制数据(图片、视频)等等)
- 解析内容:将得到的内容进行解析,HTML解析、JSON解析、二进制流解析等等
- 存储数据:存储形式多样,可以存为文本,也可以存储到数据库,或者存为特定格式的文件
2.WebMagic
一般来说爬虫只是一种技术,其实任何语言都是可以实现爬虫的,区分为简单与复杂。
我们所知道的市面上比较常见的爬虫就是
Python或者Go比较多但是实际上在
Java中也是可以完成爬虫这一操作,并且有一个相对而言比较成熟的框架就是WebMagic今天我们就用这个框架来实战一下如何爬取
英雄联盟的英雄信息与图片。
2.1.框架概述
WebMagic的设计参考了业界最优秀的爬虫Scrapy,而实现则应用了HttpClient、Jsoup等Java世界最成熟的工具,目标就是做一个Java语言Web爬虫的教科书般的实现
2.2.设计架构
WebMagic的结构分为
Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。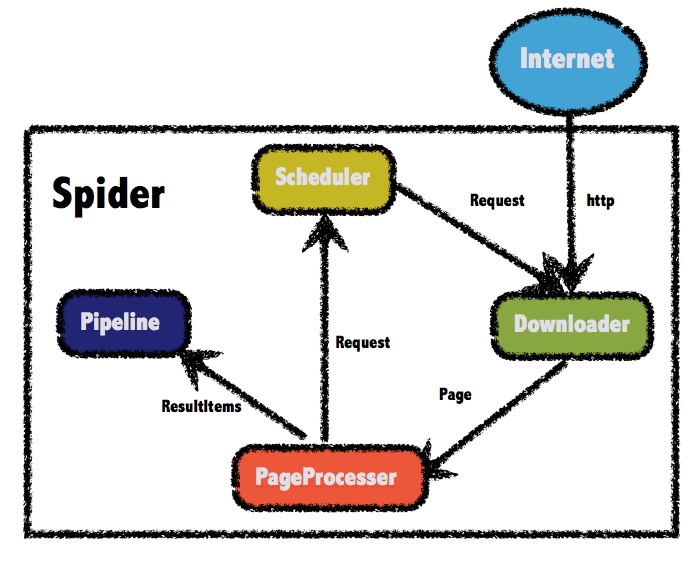
可以依据架构图我们看到整个执行流程大概为
1.发起一个HTTP请求
2.将这个HTTP内容下载下来(Downloader)
3.将内容交给PageProcesser进行处理(框架的处理核心)
4.1.处理内容后,可以再次发起请求
4.2.处理的结果可以交给
Pipeline来进行最后的收尾工作(比如存到数据库、或者保存为文件等等)更详细的内容可以直接查看官方的文档说明,这里就不一一赘述了。🚪 官方传送门
3.项目实战(初窥篇)
3.1.准备工作
直接添加WebMagic相关的框架依赖。
直接复制进pom.xml文件中即可
<dependencies> <dependency> <groupId>us.codecraftgroupId> <artifactId>webmagic-coreartifactId> <version>0.7.3version> dependency> <dependency> <groupId>us.codecraftgroupId> <artifactId>webmagic-extensionartifactId> <version>0.7.3version> dependency> <dependency> <groupId>org.projectlombokgroupId> <artifactId>lombokartifactId> <version>1.18.24version> <scope>providedscope> dependency> <dependency> <groupId>cn.hutoolgroupId> <artifactId>hutool-allartifactId> <version>5.8.9version> dependency> dependencies>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3.2.工具介绍(hutool)
这是一个包含各大常用工具方法的Java工具包。
里面具有丰富的工具资源,可以让你省下不少写一些通用方法的时间。
Hutool是项目中“util”包友好的替代,它节省了开发人员对项目中公用类和公用工具方法的封装时间,使开发专注于业务,同时可以最大限度的避免封装不完善带来的bug
官方传送门:Hutool官方地址
可以在官方地址中查看对应的文档信息。
这次主要我们要用到Hutool工具中对
文件、请求的处理的工具!🎁Hutool名称的由来
Hutool = Hu + tool,是原公司项目底层代码剥离后的开源库,“Hu”是公司名称的表示,tool表示工具。Hutool谐音“糊涂”,一方面简洁易懂,一方面寓意“难得糊涂”。
3.3.初窥门径
我们进行爬虫的第一步就是先明确的我们的需求。
首先我们应当想办法找到
LOL英雄资料的页面(URL),然后我们才开始解析我们的页面。学会解析页面
首先我们要鼠标右键
查看网页源代码
由此我们可以发现我们的页面数据不过是寥寥几十行,并没有我们所需要的英雄数据信息,说明当前网站的页面信息并不是静态的。而是动态的(这里需要大家对HTTP请求有一定的基础知识)
因为数据是动态的所以我们需要去查看当前页面的请求链接去分析和寻找(这里需要耐心一点)
打开官网地址我们需要按下
F12然后选择Network刷新一下来查看当前网页的数据源是怎么展示在页面上的请求链接,我们可以发现一个比较可疑的链接
hero_list.js从名字来看是英雄列表的意思,只要你点进去查看返回结果可以发现这个就是我们想要的信息。
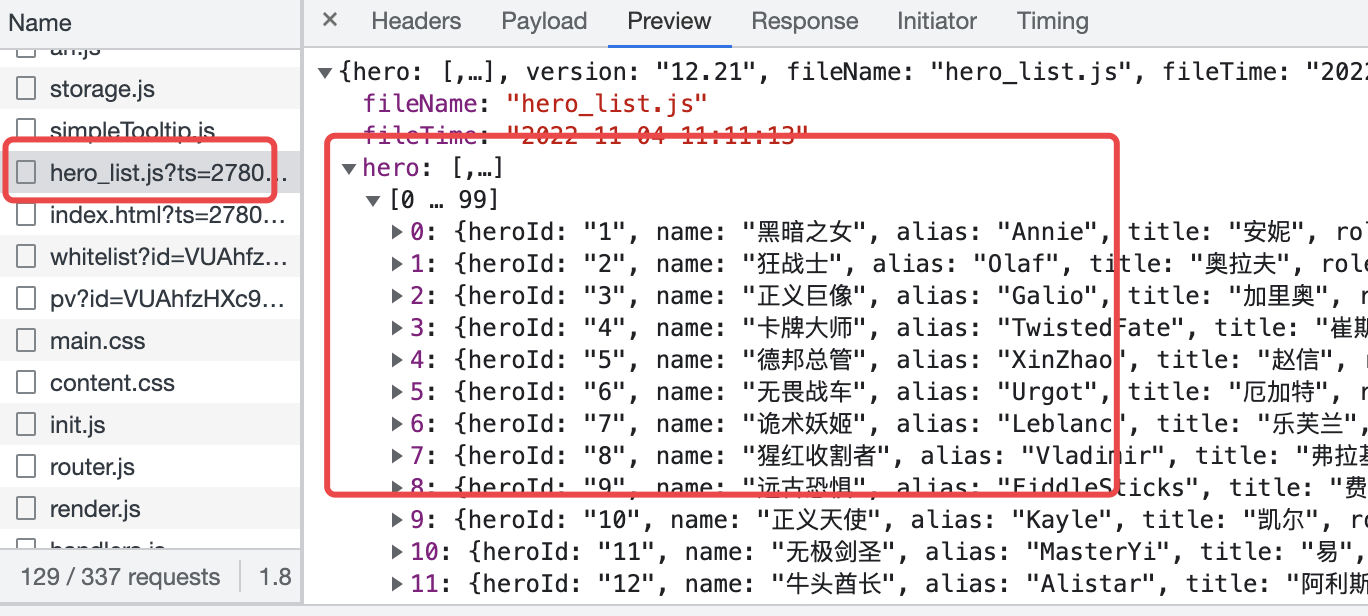
由此分析我们就得到了当前英雄信息的数据源,我们接下来要做的就是去处理这个数据。
我们得到了我们要请求的路径为:https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2780729
3.4.利用WebMagic处理请求
得到我们的需要的数据源之后,我们就要学会利用我们的爬虫来往数据源里面进行爬取数据。
对于数据的处理我们是通过自定义
PageProcessor来完成的,所以我们需要创建一个类来实现这个接口。并且重写我们的
process()核心函数,改为我们要做的事情。简单梳理一下我们要做的事情
- 判断请求路径是否与我们的目标路径一致
- 路径如果一致则获取文件中的
json数据转换成Java对象 - 将处理好变成Java对象的数据存到
page对象中等待Pipeline的处理 Pipeline对象在接收到处理好传递过来的数据的时候,进行收尾工作,可以选择保存文件、输出在控制台等等
博主在代码中也对内容步骤进行了注释,可以进行参考查看。
核心处理代码
import cn.dengsz.common.Constants; import cn.dengsz.common.model.HeroInfo; import cn.dengsz.common.model.HeroSkin; import com.alibaba.fastjson.JSONArray; import com.alibaba.fastjson.JSONObject; import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.processor.PageProcessor; import java.util.List; import java.util.stream.Collectors; /** * @author Deng's * 去获取页面的进程 */ public class HerosListPageProcessor implements PageProcessor { /** * 核心程序部分 */ @Override public void process(Page page) { // 处理英雄列表信息 if (page.getUrl().get().equals(Constants.HERO_URL)) { // 获取页面内容 String jsonResult = page.getJson().toString(); // 利用fastjson解析json内容(根据返回内容决定获取key:hero的内容) JSONObject jsonObject = JSONObject.parseObject(jsonResult); // 将内容转换成数组 JSONArray heros = jsonObject.getJSONArray(Constants.HERO_KEY); // 版本信息、更新时间 String version = jsonObject.getString(Constants.VERSION); String updateFileTime = jsonObject.getString(Constants.UPDATE_TIME); // 获取到数据数组 判断数组内容是否为null if (heros.size() == 0) { return; } // 将处理好的信息存入Pipeline中 List<HeroInfo> heroInfoList = heros.toJavaList(HeroInfo.class); page.putField(Constants.HERO_KEY, heroInfoList); page.putField(Constants.VERSION, version); page.putField(Constants.UPDATE_TIME, updateFileTime); } } @Override public Site getSite() { // 设置相关的请求头信息,防止反爬虫或者无效访问被拒绝 return Site.me().setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/" + "537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36") .addHeader("accept-encoding", "gzip, deflate, br") .addHeader("accept-language", "zh-CN,zh;q=0.9,en;q=0.8") .addHeader("origin", "https://101.qq.com") .setCharset("utf-8") .setRetryTimes(3).setSleepTime(1000); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
英雄信息的对象模型
import lombok.Data; /** * @author Deng's * 仅仅获取一些有用的相关数据 保存下来。 */ @Data public class HeroInfo { /** * 英雄id */ private String heroId; /** * 中文名 */ private String name; /** * 别名 */ private String alias; /** * 信息标题 */ private String title; /** * 金币售价 */ private String goldPrice; /** * 点券售价 */ private String couponPrice; /** * 一些关键信息 */ private String keywords; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
一些固定的常量
写一些常量方便之后需要改动的时候进行全局直接生效。
比如
文件存储位置、初始访问链接、固定常量名等等/** * @author Deng's * 一些解析数据的常量 */ public class Constants { public static final String HERO_KEY = "hero"; public static final String VERSION = "version"; public static final String UPDATE_TIME = "fileTime"; public static final String PIC_URL = "https://game.gtimg.cn/images/lol/act/img/js/hero/"; public static final String HERO_URL = "https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js?ts=2780565"; /** * 预设一些文件存储地址 * 英雄信息文件、英雄图片文件存储路径(默认桌面) */ public static final String HERO_INFO_FILE = "/Users/dengs/Desktop/lol-skins/hero.json"; public static final String HERO_PIC_FILE = "/Users/dengs/Desktop/lol-skins/"; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
核心的自定义Pipeline类
本教程将英雄数据存储为本地的
json文件,存储地址可以去改动Constants类中的HERO_INFO_FILE常量值来改变。import cn.dengsz.common.Constants; import cn.dengsz.common.model.HeroInfo; import cn.dengsz.common.model.HeroSkin; import cn.hutool.core.io.FileUtil; import cn.hutool.http.HttpUtil; import com.alibaba.fastjson.JSONObject; import lombok.extern.slf4j.Slf4j; import us.codecraft.webmagic.ResultItems; import us.codecraft.webmagic.Task; import us.codecraft.webmagic.pipeline.Pipeline; import java.io.FileWriter; import java.io.IOException; import java.util.List; /** * @author Deng's * 处理由pageProcessor处理好后 塞过来的英雄数据(当然你可以在这里改造成存入数据库) */ @Slf4j public class LolHeroPipeline implements Pipeline { @Override public void process(ResultItems resultItems, Task task) { // 判断当前请求路径是什么 再决定做什么事情 if (resultItems.getRequest().getUrl().equals(Constants.HERO_URL)) { // 根据Processor传递过来参数做下一步处理 List<HeroInfo> heroInfoList = resultItems.get(Constants.HERO_KEY); // 利用hutool可以将内容快速输出成文件 try { //Constants.HERO_INFO_FILE 为文件输出的地址 FileWriter fileWriter = new FileWriter(Constants.HERO_INFO_FILE); fileWriter.write(JSONObject.toJSONString(heroInfoList)); fileWriter.close(); } catch (IOException e) { log.error("写出英雄信息出现问题,请查看:{}", e.getMessage()); throw new RuntimeException(e); } } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
最后放上这个项目的启动类
import cn.dengsz.common.Constants; import cn.dengsz.core.HerosListPageProcessor; import cn.dengsz.core.LolHeroPipeline; import us.codecraft.webmagic.Spider; /** * @author Deng's */ public class App { public static void main( String[] args ) { // 调用数据爬虫进程 // 可以增加线程来提高运行效率(thread) long beginTime = System.currentTimeMillis(); Spider.create(new HerosListPageProcessor()) .addUrl(Constants.HERO_URL) .addPipeline(new LolHeroPipeline()) .thread(5) .run(); System.out.printf("用时 %d ms",System.currentTimeMillis()-beginTime); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
总结
通过以上代码我们可以初步完成对于LOL英雄数据信息的爬取与保存,也算是为大家对爬虫有了初步了解。
4.项目实战(提升篇)
有了上面的案例以后,其实获取英雄图片也是同理分析和完成的。
首先第一步,仍然是对于网页请求的分析。思考一下我们英雄的图片从何而来。
4.1.请求分析
我们可以随机点击一个英雄信息后,对英雄的信息进行查看与分析。
🚪 英雄详情页传送门
我们同样通过
F12在请求列表中找到了一个比较可疑的请求1.js为什么会找到这个请求呢?
只要仔细观察会发现我们解析的英雄详情路径是这样的:
https://101.qq.com/#/hero-detail?heroid=1&datatype=5v5可以看到其中有一个关键信息是
heroid=1不用多说基本就代表了当前英雄的id编号了
所以由此才会去找到一个
1.js的这个请求,与heroId相对应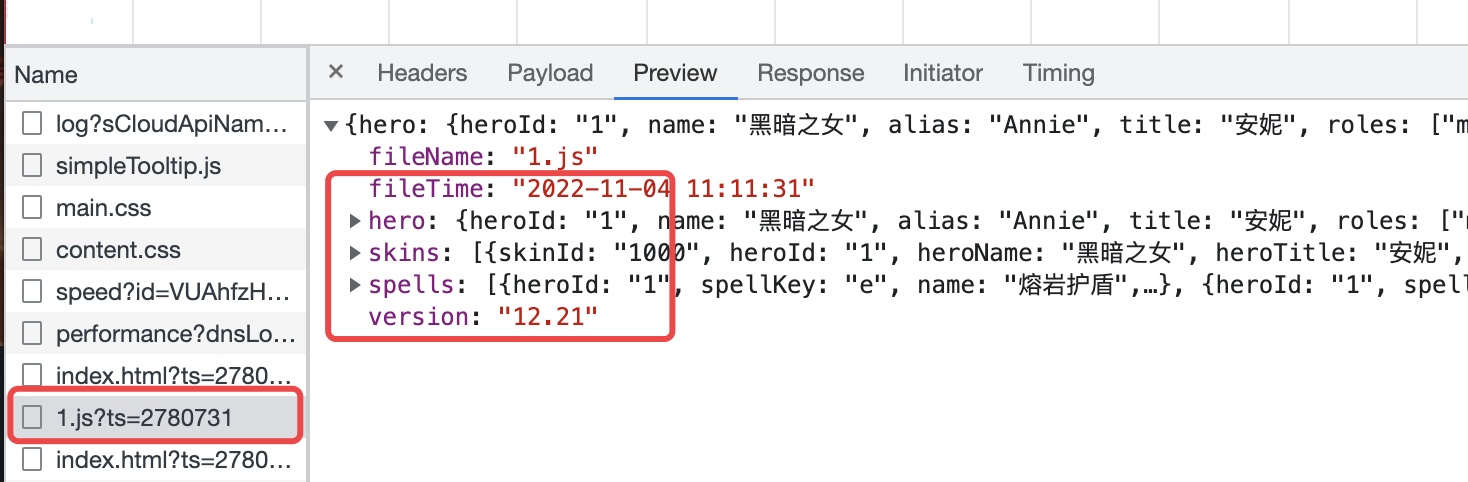
不出所料我们找到了有用的皮肤信息
点开皮肤
skins查看每个skin的数据结构大概如下{ "skinId": "1000", "heroId": "1", "heroName": "黑暗之女", "heroTitle": "安妮", "name": "黑暗之女", "chromas": "0", "chromasBelongId": "0", "isBase": "1", "emblemsName": "base", "description": "", "mainImg": "https://game.gtimg.cn/images/lol/act/img/skin/big1000.jpg", "iconImg": "https://game.gtimg.cn/images/lol/act/img/skin/small1000.jpg", "loadingImg": "https://game.gtimg.cn/images/lol/act/img/skinloading/1000.jpg", "videoImg": "https://game.gtimg.cn/images/lol/act/img/skinvideo/sp1000.jpg", "sourceImg": "https://game.gtimg.cn/images/lol/act/img/sourceImg/guide1000.jpg", "vedioPath": "", "suitType": "", "publishTime": "", "chromaImg": "" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
我们可以看到这里面就包含了图片的请求地址
mainImg当然如果我们继续仔细查看我们就会发现一些炫彩皮肤是没有
mainImg这个属性值的。所以我们可以在代码处理的时候通过
mainImg是否有值来判断是不是皮肤,还是炫彩皮肤。所以爬虫的时候 分析是很重要的一件事情,请大家铭记。
并且获取到了当前内容的请求地址为:
https://game.gtimg.cn/images/lol/act/img/js/hero/1.js?ts=2780731综合上面所有的分析内容,我们就可以知道请求英雄详情的地址是固定的,唯一的变数是结尾的
{heroId}.js所以我们只要一一对每个英雄所对应的
heroId进行拼接访问,再依次获取对应皮肤图片的地址下载下来即可!4.2.代码部分
信息对象模型
同样的这样的内容我们需要建立一个对象模型来方便我们接受处理数据
package cn.dengsz.common.model; import lombok.Data; /** * @author Deng's * 英雄的皮肤信息实体类(这里的内容可以根据返回的json信息自己进行需要的属性定义) */ @Data public class HeroSkin { /** * 皮肤id */ private String skinId; /** * 英雄id */ private String heroId; /** * 英雄名 */ private String heroName; /** * 皮肤名 */ private String name; /** * 主图 */ private String mainImg; /** * 图标 */ private String iconImg; /** * 炫彩皮肤 */ private String chromaImg; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
核心处理类HerosListPageProcessor
因为增加了对于英雄id的记录,以及对每次链接请求的判断(如果是列表就保存英雄数据,如果是英雄详情则下载皮肤图片)
因此改造后的核心
HerosListPageProcessor的process()函数应该如下/** * 核心程序部分 */ @Override public void process(Page page) { // 处理英雄列表信息 if (page.getUrl().get().equals(Constants.HERO_URL)) { // 获取页面内容 String jsonResult = page.getJson().toString(); // 利用fastjson解析json内容(根据返回内容决定获取key:hero的内容) JSONObject jsonObject = JSONObject.parseObject(jsonResult); // 将内容转换成数组 JSONArray heros = jsonObject.getJSONArray(Constants.HERO_KEY); // 版本信息、更新时间 String version = jsonObject.getString(Constants.VERSION); String updateFileTime = jsonObject.getString(Constants.UPDATE_TIME); // 获取到数据数组 判断数组内容是否为null if (heros.size() == 0) { return; } // 将处理好的信息存入Pipeline中 List<HeroInfo> heroInfoList = heros.toJavaList(HeroInfo.class); page.putField(Constants.HERO_KEY, heroInfoList); page.putField(Constants.VERSION, version); page.putField(Constants.UPDATE_TIME, updateFileTime); // 下载英雄图片信息,经过分析得到英雄信息详情的json信息路径(写在Constants中) // 需要根据每个heroId来查询对应的信息 最终返回每张图片的下载地址 this.getImgReqList(page, heroInfoList); } // 判断当前url路径是否是英雄信息详情 if (page.getUrl().get().contains(Constants.PIC_URL)) { // 处理单只英雄详情(先获取json数据对象) JSONObject heroDetail = JSONObject.parseObject(page.getJson().toString()); // 从英雄详情中获取到skins这个属性 JSONArray skins = heroDetail.getJSONArray("skins"); List<HeroSkin> heroSkins = skins.toJavaList(HeroSkin.class); // 不要炫彩皮肤,我们筛选出有主皮肤图的数据即可 List<HeroSkin> screenSkins = heroSkins.stream().filter(item -> !item.getMainImg().isEmpty()).collect(Collectors.toList()); // 存入页面空间中待pipeLine处理 page.putField("skins", screenSkins); } } /** * 批量去添加所有英雄的详细信息的请求路径 */ private void getImgReqList(Page page, List<HeroInfo> heroInfoList) { // 根据heroId去请求不同的英雄信息 for (HeroInfo heroInfo : heroInfoList) { // 拼接图片请求路径(添加目标链接) page.addTargetRequest(Constants.PIC_URL+heroInfo.getHeroId()+".js"); System.out.println(page.getJson().toString()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
最后结果处理类LolHeroPipeline
同样的我们的最终处理类的
process()函数也要添加一个额外操作要对进来的路径进行判断,如果是英雄详情的路径则需要下载图片
// 判断路径如果是英雄详情路径则开始下载图片文件 if (resultItems.getRequest().getUrl().contains(Constants.PIC_URL)) { // 根据捕获到的信息下载图片 List<HeroSkin> skins = resultItems.get("skins"); // 创建文件夹存储皮肤(采用默认路径+英雄名 来作为文件夹路径) String saveFilePath = Constants.HERO_PIC_FILE + skins.get(0).getHeroName(); FileUtil.mkdir(saveFilePath); for (HeroSkin skin : skins) { // 利用hutool工具下载文件 参数一:下载地址 参数二:保存路径 long size = HttpUtil.downloadFile(skin.getMainImg(), FileUtil.file(saveFilePath)); log.info("下载 {} 图片成功,大小为 {}, 存储地址为{}",skin.getName(),size,saveFilePath); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.3.项目源码
完整的项目案例博主已经上传到
Github中,如有需要可以直接访问下载如果对你有参考价值的话,希望能获取你的一个
start🚪 代码仓库:lol-spider源码
🏜写在最后
本文通过实战案例的方式来讲解和应用
WebMagic这个Java爬虫框架。在爬虫的过程中,其实对于页面内容的解析是很重要的。所以在这一步的时候提醒大家需要用心一点哦。
如果本文章对你有用,请不要忘记一键三连!

-
相关阅读:
idea中database的一些用法
Day 32 shell变量及运算
3D视觉系统实现自动化上下料操作
取余和取模和取整
自定义linux cp命令
怎么使用LightPicture开源搭建图片管理系统并远程访问?【搭建私人图床】
Netty入门指南之传统通信的问题
Spring Boot 内置工具类 ObjectUtils
基于uwb和IMU融合的三维空间定位算法matlab仿真
半路入行软件测试岗—这些建议你最好看一下
- 原文地址:https://blog.csdn.net/qq_41048567/article/details/127877700