-
python学习笔记(08)---(内置容器-集合、字符串)
目录
(4)格式:setname={value1,value2……valuen}
(1)概念:字符串是由单引号和双引号包裹起来的任意不可变文本序列。
(3)多行字符串:字符串长度多于一行时,可以使用三引号将字符串包夹
第七章 内置容器(四)
5.集合
(1)概念:集合是一个无序不重复的序列
(2)作用:用于关系测试,消除重复值
(3)集合使用大括号{}框定元素,逗号分割
(4)格式:setname={value1,value2……valuen}
- s1 = {1, 2, 3, 4, 5}
- s2 = {'age', 'date', 'day', 'mintue'} # 集合本质为无序可变不重复序列,输出时顺序可能不同
- s3 = set('天阶夜色凉如水,卧看牵牛织女星')
- s4 = set([1, 2, 3, 4, 5])
- s5 = set() # 空集合,不能直接写{}
- s6 = set('apple', ) # 必须加逗号
- print(s1, '\n', s2, '\n', s3, '\n', s4, '\n', s5, '\n', s6, '\n', )
- # {1, 2, 3, 4, 5}
- # {'date', 'day', 'mintue', 'age'}
- # {'看', '织', '女', '夜', '星', '牛', '如', '凉', '色', '阶', ',', '牵', '水', '天', '卧'}
- # {1, 2, 3, 4, 5}
- # set()
- # {'p', 'e', 'a', 'l'}
(5)集合应用的核心:去重
- l1 = [1, 2, 3, 3, 3, 3, 4, 5, 6, 7, 8, 8, 9, 8, 9, 9, 9, 8, 6, 56, 4]
- x = set(l1)
- print(x) # 去重 {1, 2, 3, 4, 5, 6, 7, 8, 9, 56}
(6)集合的添加与删除:
<1> 添加元素:setname.add(elemant)
- s1 = set(['java', 'c++', 'go', 'c'])
- s1.add('python')
- print(s1) # 输出内容是无序的 {'python', 'java', 'c++', 'go', 'c'}
<2> 删除元素:setname.remove(elemant)
(7)集合的交、并、差集
<1> 交集:&
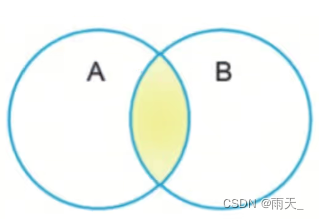
<2> 并集:|

<3> 差集:-

<4> 对称差集:^

<5> 例:
- s1 = set('adafewg')
- s2 = set('aewgawfewaf')
- print(s1 & s2) # {'e', 'a', 'w', 'g', 'f'}
- print(s1 | s2) # {'e', 'a', 'd', 'w', 'g', 'f'}
- print(s1 - s2) # {'d'}
- print(s1 ^ s2) # {'d'}
(8)集合判断是否相等
<1> 符号:== !=
<2> 返回值:True False
- A = {1, 2, 3, 4}
- B = {5, 6, 7, 8}
- C = {1, 2, 3, 4}
- print(A == B, A == C) # False True
(9)特殊操作
<1> sidisjoint():两个集合没有共同元素时返回True

- A = {1, 2, 3, 4}
- B = {5, 6, 7, 8}
- print(A.isdisjoint(B)) # True
<2> issubset():测试是否为子集

- A = {1, 2, 3, 4}
- B = {1, 2, 3, 4, 5, 6, 7, 8}
- print(A.issubset(B)) # True
<3> issuperset():测试是否为父集
- a={1,2,33,4,6,7,8,9}
- b={1,2,3,4}
- print(a.issubset(b)) # False
<4> update():将一个集合加到另一个集合中
- a = {1, 2, 3, 4}
- b = {5, 6, 7, 8}
- a.update(b)
- print(a) # {1, 2, 3, 4, 5, 6, 7, 8}
<5> difference_update():删除集合中重复元素
- a = {1, 2, 3, 4, 5, 6}
- b = {3, 4, 5, 6, 7, 8}
- a.difference_update(b)
- print(a) # {1, 2}
- 覆盖式操作,原有值会被盖掉
(10)冻结集合
<1> 概念:set是可变数据类型,frozenset是不可变的数据类型集合称为冻结集合,定义好内容后不可修改、删除、操作元素
- x = frozenset([1, 2, 3])
- y = frozenset([4, 5, 6])
- print(x, y)
- print(x & y, x | y)
- # print(x[0]) # 报错
- # frozenset({1, 2, 3}) frozenset({4, 5, 6})
- # frozenset() frozenset({1, 2, 3, 4, 5, 6})
(11)查看集合内置的操作方法
print(dir(set))6.列表、元组、字典、集合的区别

(元组括号可以省略不写)
7.字符串
(1)概念:字符串是由单引号和双引号包裹起来的任意不可变文本序列。
- s1 = 'china' # 字符串常量
- print(s1[0]) # 可通过内置容器的索引方式来遍历元素
- # s1[1]='h' # 报错,字符串常量是一个不可变的序列
- s2 = ['china', 'hello', 'world'] # 字符串列表
(2)拼接字符串。符号:+
- s1 = '我今晚跑步'
- num = 30000
- print(s1 + str(num))
- # 字符串拼接的对象只能是字符串
(3)多行字符串:字符串长度多于一行时,可以使用三引号将字符串包夹
- s1 = '''china china china
- china china china
- china china china'''
- print(s1)
- # china china china
- # china china china
- # china china china
(4)字符串的切片
<1> 原则:字符串属于不可变序列,可以通过切片实现字符截取
<2> 格式:strname[start,end,step]
- start:从0索引开始
- end:最有一个字符索引(不包含)
- step:切片长度,默认为1
例:输入员工身份证号,输出出生日期和性别
- s1 = input('请输入您的身份证号:')
- print('您的身份证号是:', s1)
- if int(s1[16]) % 2 == 0:
- print('性别:女')
- else:
- print('性别:男')
- print('出生日期为:' + s1[6:10] + '年' + s1[10:12] + '月' + s1[12:14] + '日')
- # 请输入您的身份证号:1233456200203182343
- # 您的身份证号是: 1233456200203182343
- # 性别:男
- # 出生日期为:6200年20月31日
(5)分隔合并字符串
<1> 分隔:将字符串分隔为列表
<2> 格式:strname.split(sep,maxsplit)
- sep:指定分隔符,可以包含多种符号,(空格,\,\t等),默认为None
- maxsplit:指定分隔次数
- s1 = 'Python 软件官网 >>> https://www.python.org'
- print('原串:', s1)
- l1 = s1.split()
- l2 = s1.split('>>>')
- l3 = s1.split('.')
- l4 = s1.split(' ', 3)
- print(l1, l2, l3, l4, sep='\n')
<3> 合并字符串:将多个字符串采用固定的分隔符进行连接
格式:strnew=string.join(iterable)
- strnew:新串名称
- string:合并时的分隔符
- iterable:可迭代对象,即被合并的字符串
(6)字符串查找
<1> count()方法
作用:检索字符串在另一个串中出现的次数,若不存在则返回0
格式:strname.count(substring---要检索的子串的名称)
- s1 = '****ABC***DEF****'
- c1 = s1.count('*')
- c2 = s1.count('?')
- print('次数:', c1, c2, sep='\n')
- # 次数:
- # 11
- # 0
<2> find()方法
作用:检索是否包含指定字符串,不存在返回-1,否则返回出现的索引值
格式:strname.find(sub)
- s1 = input('主串:')
- s2 = input('子串:')
- n = s1.find(s2)
- if n > -1:
- print('存在,第一次出现的索引为', n)
- else:
- print('不存在')
- # 主串:as123as123
- # 子串:as
- # 存在,第一次出现的索引为 0
find()方法用于在主串中查找子串是否存在,还可使用in实现如下:
print(s2 in s1) # Truerfind():从右侧开始检索
startswitch()方法:检索字符串是否以指定字符串开头
endswitch()方法:检索字符串是否以指定字符串结尾
(7)字母大小写更改
<1> 大写—>小写:strname.lower()
<2> 小写—>大写:strname.upper()
<3> 大小写互换:strname.swapcase()还可排除非字母符号
- s1 = input()
- print(s1.swapcase())
- print(s1.upper())
- print(s1.lower())
- # qwertyASD
- # QWERTYasd
- # QWERTYASD
- # qwertyasd
(8)判断是否为字母
<1> 格式:strname.isalpha()
<2> 成立返回True,否则返回False
例:判断字符串中字母出现的次数
- s1 = input('请输入字符串')
- c = {} # 定义空字典
- for i in s1:
- if i.isalpha() == True:
- c[i] = c.get(i, 0) + 1 # get(i,0)计算i对应的值
- print(c)
- # 请输入字符串12abc112abc12ab
- # {'a': 3, 'b': 3, 'c': 2}
(9)字符串删除
<1> strname.strip(char):删除字符串左右指定字符
<2> strname.lstrip(char):删除字符串左侧指定字符
<3> strname.rstrip(char):删除字符串右侧指定字符
<4> 默认删除所有空白字符(\n \t \r 空格)
例:统计字符串中的单词个数
- s1 = input('请输入字符串:')
- s1 = s1.strip() # 删除左右两侧的空格
- c = 1
- i = 0
- while i < len(s1) - 1:
- if s1[i] != ' ' and s1[i + 1] == ' ':
- c += 1
- i += 1
- if s1 == ' ':
- c = 0
- print('单词个数:', c)
- # 请输入字符串:aa aa aaa aa
- # 单词个数: 4
<4> strname.replace(‘需替换字符串’,’替换结果’)
- s1 = '****ABC****'
- print(s1.replace('*', '?'))
- # ????ABC????
(10)字符串文本对齐
<1> 方法:
- center:居中
- ljust:左对齐
- rjust:右对齐
- p = '静夜思', '李白', '窗前明月光', '疑是地上霜', '举头望明月', '低头思故乡'
- for line in p:
- print('|%s|' % line)
- for line in p:
- print('|%s|' % line.center(10)) # 居中,指定字符宽度
- for line in p:
- print('|%s|' % line.strip().center(10)) # 删除左右空白
(11)程序案例
<1> 例1:编写程序,检测输入的字符串密码是否是一个合法的密码。规则如下:密码至少8个字符;只能包含英文和数字;密码至少包含2个数字
- s1 = input('请输入密码')
- t = 0
- for i in s1:
- if i.isdigit(): # 计算字符串中数字个数,判断字符是否为数字
- t += 1
- if len(s1) >= 8:
- if s1.isalnum(): # 判断字符串只包含字母和数字
- if t >= 2:
- print('密码设置正确')
- else:
- print('密码包含数字少于2个')
- else:
- print('密码只能包含字母和数字')
- else:
- print('密码至少8个字符')
<2> 例2:编写程序,实现输入二进制数转为十进制数。如:1001十进制为9,执行1*2^0+0*2^1+0*2^2+1*2^3
- s1 = input('请输入二进制:')
- d1 = 0 # 接受转换结果
- t = 0 # 权值
- f = 1
- if s1.isnumeric(): # 判断字符串至少一个字符,所有字符均为数字
- s2 = s1[::-1] # s2存储逆序的s1
- for i in s2:
- if i == '1' or i == '0':
- d1 = d1 + int(i) * 2 ** t
- else:
- print('无效数字')
- f = 0
- break
- t += 1 # 权值加1
- if f:
- print(s1, '转为十进制整数是', d1)
- # 请输入二进制:1001
- # 1001 转为十进制整数是 9
<3> 例3:国际标准书号共10位:d1d2d3d4d5d6d7d8d9d10,最后一位d10是校验位,校验位计算公式为:(d1*1+d2*2+d3*3+d4*4+d5*5+d6*6+d7*7+d9*9)%11,若d10计算结果为10则使用x表示。编写程序,输入前9个,输出标准书号。
- s1 = input('请输入前9位国际标准书号')
- ch = 0
- t = 1
- for i in s1:
- ch = ch + int(i) * t
- t += 1
- ch %= 11
- if ch == 10:
- ch = 'x'
- print(s1 + str(ch))
- # 请输入前9位国际标准书号123456789
- # 123456789x
<4> 例4:统计字符串汇总的字母个数,存储在列表b[26]中,a的个数存储在b[0],z的个数存储在b[25]
- 法1:
- s1 = input('请输入英文字符串:')
- b = [0] * 26 # 给b列表清零
- s1 = s1.lower() # 大写转小写
- for i in s1:
- if i.isalpha(): # 判断是否为字母
- b[ord(i) - 97] += 1 # 将当前字母的ASCII码值取出来减去首字母ASCII值划分为b列表的索引
- print(b)
- # 请输入英文字符串:asdfdsgfhgjhk
- # [1, 0, 0, 2, 0, 2, 2, 2, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0]
- 法2:
- s1 = input('请输入英文字符串:')
- b = []
- s1 = s1.lower() # 大转小写
- for i in range(26):
- b.append(s1.count(chr(97 + i)))
- print(b)
<5> 例5:将字符串中的大写字母改为下一个字母,z字母改为首字母a
- s1 = input('请输入英文字母:')
- for i in s1:
- if i >= 'A' and i <= 'Y':
- i = chr(ord(i) + 1)
- else:
- if i == 'Z':
- i = 'A'
- print(i, end='')
- # 请输入英文字母:ASDFGH
- # BTEGHI
将大写字母改为上一个,A改为Z
- s1 = input('请输入英文字母:')
- for i in s1:
- if i >= 'B' and i <= 'Z':
- i = chr(ord(i) - 1)
- else:
- if i == 'A':
- i = 'Z'
- print(i,end='')
- # 请输入英文字母:ASDFG
- # ZRCEF
<6> 例6:将2个串逆置后交叉合并到新串中,如:str1:abcdef str2:12345678.
str3:f8e7d6c5b4a321- s1 = input('请输入第一个串:')
- s2 = input('请输入第二个串:')
- print(s1)
- print(s2)
- s1 = s1[::-1] # 字符串切片逆序
- s2 = s2[::-1]
- s3 = ''
- i = 0
- j = 0
- while i < len(s1) or j < len(s2): # 同步访问两个串
- if i < len(s1):
- s3 += s1[i] # 拼接
- if j < len(s2):
- s3 += s2[i]
- j += 1
- i += 1
- print(s3)
- # 请输入第一个串:abcdefg
- # 请输入第二个串:12345678
- # abcdefg
- # 12345678
- # g8f7e6d5c4b3a21
<7> 例7:将字符串排序,python中字符串类不允许直接修改元素,将其转为列表后在进行排序,排完后转为字符串。
- str1 = 'dfgsgargvza'
- list1 = list(str1)
- list1.sort()
- str1 = ''.join(list1)
- print(str1)
- # aadfgggrsvz
<8> 例8:排除字符串首尾两个元素,剩余内容排序
- str1 = input('请输入字符串:')
- str2 = str1[1:len(str1) - 1] # 将1索引至倒数第2个元素
- list1 = list(str2)
- list1.sort()
- str2 = ''.join(list1)
- str1 = str1[0] + str2 + str1[len(str1) - 1]
- print(str1)
- # 请输入字符串:awrrgawrg
- # aagrrrwwg
(12)格式化字符串
<1> 概念:格式化字符串是指制定一个模板,该模板留出一些空位,再根据需要填上相应的内容
<2> 通过操作符%实现:’%[-][+][0][m][.n]’%exp
<3> 参数说明:
- []:表示可选
- -:左对齐
- +:右对齐
- 0:右对齐,用0填充空白。一般配合参数m使用
- m:宽度
- n:小数保留位数
%格式化字符如下表:

- str1 = '编号:%05d\t公司名称:%s官网:https://www.%s.com'
- str2 = (1, '百度', 'baidu')
- str3 = (2, '腾讯', 'qq')
- str4 = (3, '字节跳动', 'bytedance')
- print(str1 % str2)
- print(str1 % str3)
- print(str1 % str4)
- # 编号:00001 公司名称:百度官网:https://www.baidu.com
- # 编号:00002 公司名称:腾讯官网:https://www.qq.com
- # 编号:00003 公司名称:字节跳动官网:https://www.bytedance.com
(13)通过format()方法实现
<1> python2.6版本以后推荐使用format()方法格式化字符串
<2> 格式:str.format(args)
<3> 参数分析:
- str:字符串显示的样式即模板
- args:需要转换的对象,若有多项可以使用逗号分割
<4> 占位符:{} 和:
<5> 模板格式:{index:fill aglin sign # width.percision type}
- index:索引位置,从0开始。若省略则自动分配
- fill:空白填充的字符
- aglin:对齐方式。一般与width配合使用--- <:左对齐;>:右对齐;=:内容对齐,只对数字类型有效,即将数字放在填充字符的最右侧
- ^:内容居中
- sign:指定有无符号。---+:正数;-:负号;空格:正数加正号,负数加负号
- #:值为2/8/16进制时,数字显示0b、0o、0x的前缀
- width:宽度
- .percision:保留的小数位数
- type:类型
- str1 = '编号:{:0>5s}\t公司名称:{:s}官网:https://www.{:s}.com'
- str2 = str1.format('1', '百度', 'baidu')
- str3 = str1.format('2', '腾讯', 'qq')
- str4 = str1.format('3', '字节跳动', 'bytedance')
- print(str2)
- print(str3)
- print(str4)
- # 编号:00001 公司名称:百度官网:https://www.baidu.com
- # 编号:00002 公司名称:腾讯官网:https://www.qq.com
- # 编号:00003 公司名称:字节跳动官网:https://www.bytedance.com
- import math as m
- print('¥{:,.2f}元'.format(2000000 + 2345))
- print('{0:E}'.format(230000.1))
- print('{:.7f}'.format(m.pi))
- print('二进制:{:#b}'.format(1001))
- print('八进制:{:#o}'.format(1001))
- print('十六进制:{:#x}'.format(1001))
- print('天才是由{:.0%}的灵感,加上{:.0%}的汗水!'.format(0.01,0.99))
(14)python常见字符串编码
<1> ASCII:对10个数字,52个英文大小写字母,其他字符进行编号,最多表示256个字符,每个字符占1B
<2> GBK/GBK2312:中文汉字编码,使用1B表示一个英文字母,2B表示一个汉字。最多表示65535个汉字
<3> UTF-8和Unicode:
1> Unicode:称为万国码—统一码。用于满足跨语言跨平台的文件转换处理要求。包含全球所有国家字符编码的映射关系,已达到编码的统一使用。
问题:表示字符浪费空间。为解决字符的存储和传输问题,而产生了UTF编码。
2> UTF:(unicode transformation format):对Unicode进行转换,以便于在存储和传输时节省空间和时间。
- UTF-8:使用1、2、3、4个字节表示字符,优先使用1B表示字符,无法满足时增加1B,最多4B,英文占1B,欧洲语系占2B,东亚语系占3B,其他占4B
- UTF-16:使用2/4字节表示字符
- UTF-32:使用4B表示字符
总结:UTF编码是为Unicode编码设计的一种在存储和传输时节省空间的编码方案
<4> python的两种字符串类型
1> str:在内存中使用unicode表示字符串
2> bytes:字节类型,网络传输或存储时使用二进制数据表示,以b开头如:b’\xs2\xb0’
<5> 使用encode()方法编码
1> 作用:将字符串str类型转为二进制(bytes)数据
2> 格式:strname.encode(encoding=’编码格式’)
3> 编码格式:可省略,默认UTF-8。也可省略encoding=
- str1 = '书山有路勤为径'
- by1 = str1.encode('GBK')
- by2 = str1.encode()
- print('原串:', str1)
- print('转为GBK:', by1)
- print('转为UTF-8', by2)
- # 原串: 书山有路勤为径
- # 转为GBK: b'\xca\xe9\xc9\xbd\xd3\xd0\xc2\xb7\xc7\xda\xce\xaa\xbe\xb6'
- # 转为UTF-8 b'\xe4\xb9\xa6\xe5\xb1\xb1\xe6\x9c\x89\xe8\xb7\xaf\xe5\x8b\xa4\xe4\xb8\xba\xe5\xbe\x84'
<6> 使用decode()解码
1> 解码:将byte类型二进制数据转换为字符串
2> 格式:bytes.decode(endcoding=’UTF-8’)
- str1 = '学海无涯苦作舟'
- by1 = str1.encode('GBK')
- print(('解码后:', by1.decode('UTF-8')))
-
相关阅读:
使用 EMQX Cloud 实现物联网设备一机一密验证
粘包/拆包问题一直都存在,只是到TCP就拆不动了。
Lua02——应用场景及环境安装
K8S-资源清单和Pod生命周期
一个超好看的音乐网站设计与实现(HTML+CSS)
嵌入式C 语言中的三块技术难点
安装 tensorflow==1.15.2 遇见的问题
受心理学启发,这项眼球追踪生成式模型大幅降低训练成本
Springboot+vue的应急救援物资管理系统,Javaee项目,springboot vue前后端分离项目。
大学迷茫怎么办?
- 原文地址:https://blog.csdn.net/weixin_62443409/article/details/127874330
