-
vision transformer 剪枝论文汇总
Vision Transformer Pruning

这篇论文的核心思想很简单,就是剪维度,也就是说
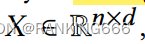 剪的是这个d。
剪的是这个d。具体方法就是通过一个gate,如图中的dimension pruning,输出0或者1,来判断不同维度的重要性,但是由于0和1,是这样的离散值无法优化,所以作者将分数松弛了一下,变成了一个连续的数,这样就可以随着梯度下降进行优化。
通过在剪枝的层后面添加dimension pruning模块,这个模块定义如图

就是前面的输出会乘上这层的参数,然后将参数加到损失函数上,l1正则化,使得大部分的值均为0.然后与networking slimming一样,统计全局的参数值,大小根据剪枝率确定阈值。
Vision Transformer Slimming: Multi-Dimension Searching in Continuous Optimization Space
network slimming 作者新作,沿用了networking slimming的想法
其实我看来思想类似,就是cnn中有bn,可以直接作为每层每个卷积核都用一个重要性系数

对于 ViT Slimming,需要解决的核心问题是如何在没有 BN 层的情况下设计合适的指示参数来反映不同模块规模对于整个分类性能的重要程度。文章采用的是通过显式地定义可导的 soft mask 来确定每个模块的大小和尺度,整个过程如下图所示。

我感觉与上文类似,就说显示的增加一个soft mask对于不同的模块,同时对于soft mask模块施加l1正则化,来达到稀疏化的目的。在开始时,为了确保公平,所以的mask均初始化为1,同时为了防止梯度爆炸,作者还增加了tanh激活函数
ViT Slimming 同时考虑了 ViT 里面三个模块:输入 tokens,MHSA 和 MLP 模块,它的训练过程可以看成是一个基于权重共享的子网络搜索过程,主干网的权重可以通过加载预训练好的模型参数来加快搜索。训练过程中 soft mask 接近 0 对应的特征相当于动态地被裁剪 / 丢弃了。该方法的优点是只需训练 / 搜索一次,就可以通过排序 mask 得到无数个子网络,非常高效灵活。算法优化函数由原始的 cross-entropy 和
 稀疏正则组成。loss如图
稀疏正则组成。loss如图
MSA

MLP

Patch Slimming for Efficient Vision Transformers
这篇论文与其他不同,是剪patch,其实这里我有问题,因为不同的图片其实重要的信息可能在不同的地方,比如有的图在左上角,有的在中间,剪patch的话,我感觉不同的图差距应该挺大的,为什么能剪patch呢?客官先继续往下看
作者认为,attention map中的元素反应的是两个patch之间的相似度(最大的还是与自己的相似度),此外并不是所有patch都能提供充足的信息。

比如对于这张图,我们看l+1层只需要两个patch就可以判断出是狗,所以其他的patch都是冗余的,同时,作者经过实验验证,层数越深,patch之间的相似度越高,如下图,意思是两者之间越相似,那么冗余的信息就越多。

, 同时,作者提出一种自顶向下的剪枝方法,大致的流程就是从最后一层开始反推减去的patch,因为与卷积是不一样的,transformer的patch是一一对应的,而cnn却不是,意思是transformer中,如果我们从头剪,那么剪去的patch在后面是没有的,那么是非常影响精度的,因为前面冗余不代表后面冗余,所以从后往前是最好的选择,具体如图

剪枝的方法的话,也是类似的,都是有一个mask,用来判断patch的重要性,那么就可以转化为一个优化问题。具体用到的是普希茨连续条件,这里偏理论,大家感兴趣可以仔细阅读一下。
Width & Depth Pruning for Vision Transformers
这篇论文就是说我不只要剪维度d,我还要剪去深度,因为其实对于简单的图片或者简单的任务,可能不需要那么多层的block的累加。因此深度方向也是可以进行剪枝的。
首先是宽度,就是与正常的无区别,还是加一个mask,输出二值结果,然后训练mask,需要注意的是,这里的阈值选择,与之前不同,也是学出来的。

然后就是深度,具体是在每一个block后面添加分类头,


训练损失函数,然后We select a shallow classifer to achieve an optimal trade-off between effciency and accuracy
Pruning Self-attentions into Convolutional Layers in Single Path
这篇文章的核心思想史nas,就是attention是全局信息,而缺少了cnn中的偏置局部信息,因此希望将二者结合。

大多数nas都采用左图这种,将msa,卷积分为不同的路径去搜,每个模块都有自己的权重,那么这样的话,会大大提升搜索成本,因为每次搜索是独立更新每条路径的。 本文建议将搜索看做一个自己选择问题,也就是右图,其中卷积运算的输出直接从MSA中间结果索引得到,这样可以简化优化过程同时减少搜索成本。通俗的说就是作者通过预训练好的msa的权重来初始化得到对应卷积的权重,达到一种权重共享的方法。
具体的操作就是,通过一系列变化,将msa中的权重转为cnn中的权重

具体公式可以看


首先是卷积和msa的定义,h指的是不同的head,l,m就是整张图的尺寸,o1o2就是卷积窗口的尺寸,因此将msa转为conv形式

将att中的局部变为1,则原本的公式可以表示为

同时,将不同的head对应到卷积的3*3的9上面
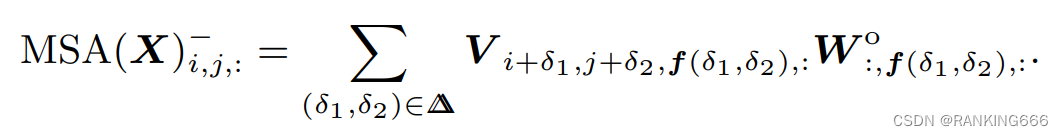
但是一般来说并不会有这么多head,所以需要一个映射函数,将其对应(其实这里不太理解)

这个映射矩阵还要经过一个 softmax 保证在 MSA 中的参数形式不会经过这个矩阵变化太大

因此得到

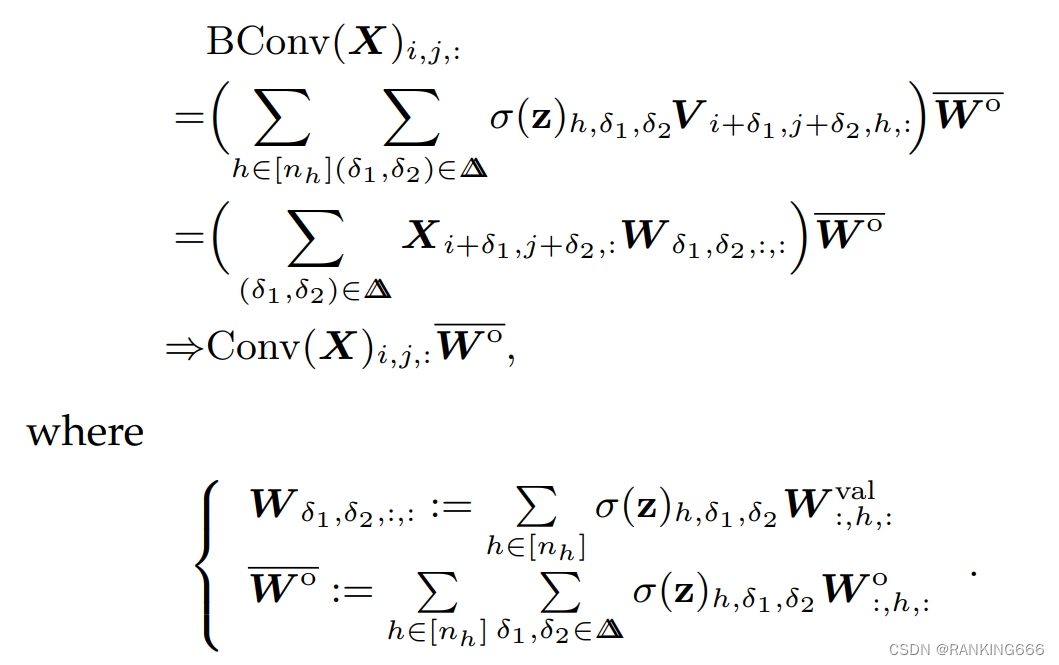
同时作者会在conv后加上bn和relu

这样就达到了通过msa得到conv的效果。
然后,就跟前面的文章类似,都是定义一个可学习的门控,来选择conv还是msa,同时在mlp中也加入了门控,进行维度上的剪枝

NVIT: VISION TRANSFORMER COMPRESSION AND PARAMETER REDISTRIBUTION
本文提出的针对ViT的剪枝规则分为三步:
1.确定剪枝的空间

2. 通过建立全局重要性分数ranking,迭代地进行全局结构剪枝。
3. 观察剪枝后网络结构的维度变化趋势,进行参数重分配,得到最终的NViT.
整体流程图如下:

首先,我们先看第一步确定剪枝的空间

这里的话是把q,k,v按照head提前分开,分别计算,由原来的concat变为累加,这样的好处是我们需要确保qkv的维度是一样的,剪掉的通道是相同的,剪掉的头是相同的,同时避免不同的头之间出现混乱,这样可以将不需要的头之间剪掉,同时对于所有的blocks,emb是需要保持统一的。
第二步
剪枝策略是为了寻找一个合适的权重W,使得模型的尺寸在一个限制C下,具有最小的损失函数。(其中s是将权重分成一个个组,剪枝其实就是砍掉一些权重group)
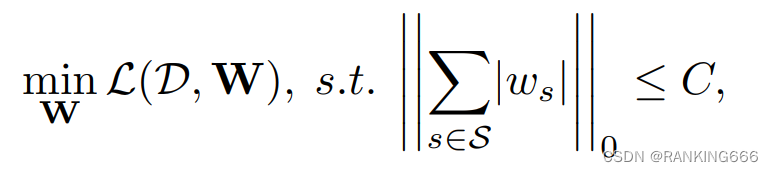
以前的一些方法都是说,mask中得到0,1,这个不好训练,都是将他放松,以此跟模型一起训练。
而这里为了简化,先在数据集D上训练得到一个Loss较小的W(此时的W比较大,不满足C的约束限制)。然后评估各个group的重要性,将一些重要性比较低的group砍掉,每个组重要性评估函数如下(将这个组权重置为0,增加的Loss可以用来评估其重要性):

为了简化运算,作者并没有加入什么mask,训练而是直接进行泰勒展开

代入原始的重要性函数,得到简化后各组权重的重要性函数如下。这样就可以评估各组权重的重要性,将不重要的权重砍掉。

训练的loss就是正常loss和剪枝与pretrained之间的loss



第三步,作者对于剪枝结果进行分析

如图所示,每张表横坐标代表网络块的序号,纵坐标代表一些网络结构(剪枝)参数。蓝色是DEIT-B网络,灰色是剪枝过程的NViT网络,绿色是最终的NViT网络。(绿色是灰色曲线平滑后得到的) 。
从图中可以得到

因此,作者根据观察到的规律,对剪枝的结果进行了平滑处理,比如使得第一个和最后一个大的更加突出点这种。
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
这篇论文首先作者观察到,模型最终输出的预测结果其实是仅仅基于很小的一部分patch,意思是其他大多数的patch是多余的,可以剪掉。
因此本文提出了一种剪枝框架,通过在msa和mlp后面添加一个轻量化的注意力模块来动态的识别不重要的patch,就是输出一个二值mask, 因为patch的重要性对于不同的input来说是完全不一样的,所以相当于是动态剪枝的思想。同时,作者发现仅仅将要剪枝的patch置零是行不通的,因为attention的机制,置零后仍然会对其他的patch有影响因此,提出了一种注意屏蔽策略,通过阻止一个token与其他tokern的交互来差异化地修剪token。
同时,作者说由于self-attention的本质,非结构化剪枝也能在硬件段带来加速(不懂)
轻量化的注意力模块与模型是一起被优化的,为了达到这个效果,作者提出了两点策略:
-
采用 Gumbel-Softmax来克服从分布中采样的不可微问题,从而实现端到端训练。
-
关于如何根据学习到的二进制决策掩码来剪掉冗余的 tokens:对于每个输入图片而言,其二进制决策掩码中0值的位置肯定是不一样的。因此,在训练过程中直接消除每个输入图片的冗余的 tokens 将无法实现并行计算,也无法计算预测模块的反向传播。而且,直接将被剪掉的 tokens 设置为零向量也不可以,因为零向量仍然会影响 Attention 矩阵的计算。因此作者提出注意力masking,即我们根据二进制决策掩码mask,将注意矩阵中从剪去tocken到所有其他tocken的连接,也就是消除剪去的token对其他token的影响。作者还改了原始的训练目标函数,增加了一项 loss 来限制剪掉 tokens 的比例。
对于第二点,需要解释一下,因为我们训模型的时候是传的一个batch,所以如果每个batch的token都不一样,那无法并行计算。
整体计算流程如图

首先:通过预测模块进行 Token 的分层稀疏化:
这里 "分层 (Hierarchical)" 的含义是:随着模型的层数由浅到深,token 的数量逐渐减小,即随着计算的进行,逐渐丢弃无信息的 tokens。举个例子:前几层是1000个,中间几层是500个,最后几层只有200个。这个过程是 "分层 (Hierarchical)" 的。
为了实现这个过程, 作者维持了一个二值的 decision mask 向量:, 来指示这 个 tokens 是丟弃还是保留, 其中 是图片的 Patch 数。将决策掩码 中的所有元素初始化为1, 并逐步更新掩码。预测模块的输入是当前的决策掩码 和特征 。
接下来计算每一层的局部和全局特征
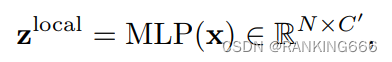

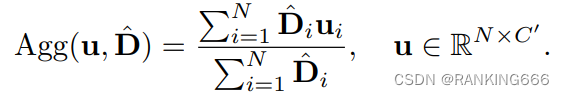
得到
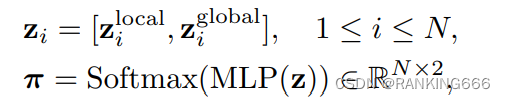
Π就是输出,通过Π来得到D,就是二进制掩码,然后用当前得到的D更新全局的D


通过 Softmax 操作,值为0的 tokens 仍会影响其他 tokens。为此,作者设计了一种称为注意力掩码的策略,可以完全消除掉一些 tokens 的影响。具体来说,通过以下方式计算注意力矩阵 。

整体流程就介绍完了,然后是训练的loss,主要是4部分组成
其中分类损失:

蒸馏损失:注意这里是最后一层输出的token与教师的token
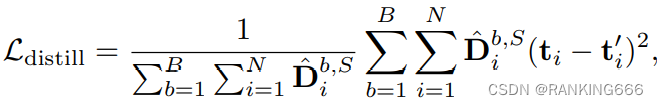
KL损失:通过 logit 蒸馏,即 KL 散度最小化 DynamicViT 和教师模型之间的预测差异:

最后, 作者希望将保留的 token 的比率限制为一个预定义的值。比如一共有 个 stages, 那么每个 stage 的保留 token 的比例可以预设为 , 作者通过 MSE Loss 来监督预测模块:

因此,得到总的loss

DynamicViT 的推理过程就是给定目标 token 的稀疏度 , 可以通过由预测模块产生的概率向量 , 直接丢弃信息较少的 tokens, 使得在第 个 stage 保留 个tokens。比如对于第 个 stages, 对这些 tokens 的概率值进行排序:
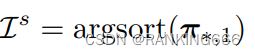
根据排序之后的结果取 为保留的 tokens, 并丟弃掉其他的 tokens。这样, DynamicViT 可以在推理时剪掉信息量较少的 tokens, 从而减少推理过程中的计算开销。
-
-
相关阅读:
分享个轮播的3D饼图,分别用Echarts和HighCharts实现
Python项目运行过程报错处理
SpringSecurity Oauth2实战 - 08 SpEL权限表达式源码分析及两种权限控制方式原理
前端入职配置新电脑!!!
Segment-and-Track Anything——通用智能视频分割、跟踪、编辑算法解读与源码部署
2022最新Java高频面试集锦,让你“金九银十”轻松斩获大厂offer
史诗级PCL和Eigen联合BUG
构建企业全生命周期数字化资产管理新模式
消息队列的简介
字符串压缩(三)之短字符串压缩
- 原文地址:https://blog.csdn.net/weixin_42638415/article/details/127857748