-
【Transformer 相关理论深入理解】注意力机制、自注意力机制、多头注意力机制、位置编码
前言
最近在学DETR,看源码的时候,发现自己对位置编码的理解很肤浅,只知道公式是这样的,但是深入的一些原理完全不懂。所以打算重新学习一下transformer相关的理论。然后推荐一个b站up: 去钓鱼的程序猿,和他的个人博客: 二十三岁的有德,他讲transformer讲的太好了。
这一节从头梳理一下Attention、Self-Attention、Muti-Head Self-Attention、Positional Encoding的原理。
一、注意力机制:Attention
人体视觉注意力:人眼的视野是比较开阔的,但是我们关注的焦点只有一个小范围,通常会更关注于更重要的区域,更感兴趣的区域;
注意力机制:让模型去关注在图片中的更重要的区域,忽略更不重要的区域;不同角度理解注意力机制:
从概念角度:从大量信息中,有选择的筛选出少量重要信息,并聚焦到这些少量重要信息上,忽略大多不重要的信息。 从模型角度:通过Q去查询K当中哪些是比较重要的,得到相应的权重矩阵,再乘以V,让V去关注更重要的信息,忽略更不重要的信息。 从相似度角度:其实求取重要性的过程就是求取相似度的过程(相似度匹配),相似度越大说明重要性越高,越关注这部分。- 1
- 2
- 3
如何做注意力:
- 输入Query、Key、Value;
- 根据Query和Key计算两者之间的相关性/相似性(常见方法点乘、余弦相似度,一般用点乘),得到注意力得分;
- 对注意力得分进行缩放scale(除以维度的根号),再softmax归一化,再得到权重系数;
- 根据权重系数对Value值进行加权求和,得到Attention Value(此时的V是具有一些注意力信息的,更重要的信息更关注,不重要的信息被忽视了);
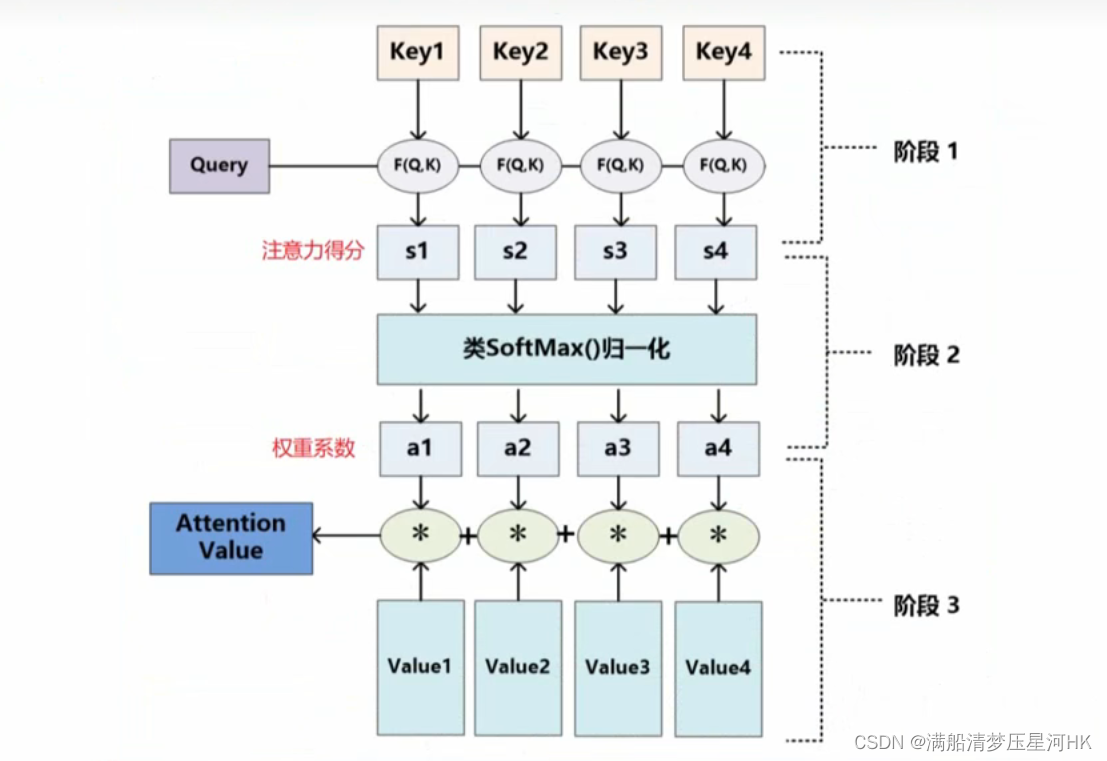
一些需要注意的点:
- 为什么softmax前要缩放?为什么是除以维度的根号?
缩放是因为softmax归一化是有问题的,当缩放前的某个元素非常大的时候,softmax会把大部分的概率分给这个大的元素,这就会产生一个类似one-hot的向量,softmax反向传播会导致梯度消失。所以在softmax前缩放,缓解这种问题。
除以维度的根号因为我们希望输入softmax的数据是均值为0,方差为1。 - 一般K和V是相同的,或者是存在一定的联系的。
- 新的向量Attention Value表示了Key 和Value(Key 一般和Value相同),而且Attention Value还暗含了Q的信息。总结下:通过查询遍历Key找出Key里面的关键点,然后再和Value组合成一个新的向量去表示Key。
- 为什么不能用Key和Key自乘得到相似度,而要新建一个Q?
如果Key自乘得到相似度,这个时候得到的其实是一个对称矩阵,相当于把Key投影到同一个空间中,泛化能力弱。
二、自注意力机制:Self-Attention
Self-Attention 的关键点在于,Q、K、V是同一个东西,或者三者来源于同一个X,三者同源。
通过X找到X里面的关键点,从而更关注X的关键信息,忽略X的不重要信息。Attention和Self-Attention的区别:
- Attention中K和V往往是同源的(也可以不同源),而Q没有任何要求,所以attention其实是一个很宽泛的概念,没有规定Q、K、V是怎么来的,只要满足QKV相乘计算相似度这种流程的都是注意力机制(所以才有通道注意力机制、空间注意力机制);
- Self-Attention属于Attention,要求QKV必须同源,依然代表X,本质上可以看作是相等的,只是对同一个词向量X乘上了参数矩阵,作了空间上的变换;
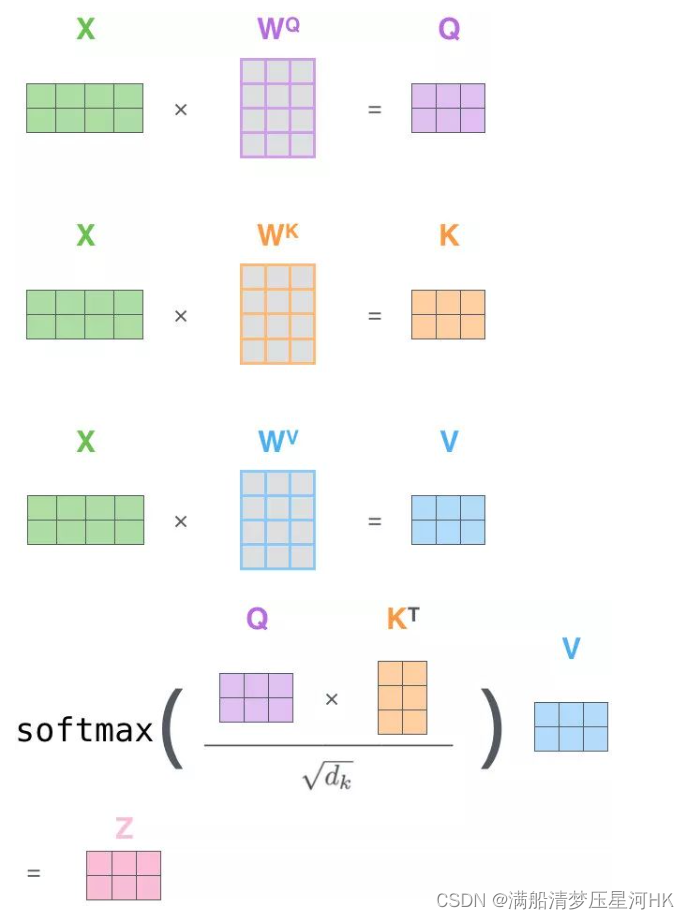
如何做自注意力:
3. 通过共享参数 W Q W_Q WQ、 W K W_K WK、 W V W_V WV和X运算得带Q、K、V;
4. 接下来和注意力机制一模一样;
如上是对Thinking Machines这句话进行自注意力的全过程,最终得到 z 1 z_1 z1和 z 2 z_2 z2两个新向量。其中 z 1 z_1 z1表示的是thinking这个词向量的新的向量表示(通过thinking这个词向量,去查询和thinking machine这句话里面每个单词和thinking之间的相似度),也就是说 z 1 z_1 z1这个新的向量表示其实还是thinking这个词向量表示,还是有联系的,只不过它还包含thinking machine这句话对thinking而言哪个词向量更重要/更相关的信息。自注意力机制的意义?

如上图,如果不做自注意力机制,its词向量就是单纯的its词向量,没有任何附加信息。而做了自注意力信息,its就有了law和application这层意思,可以包含law的信息,挖掘潜在意思,翻译起来就更加准确。总结:self-attention整个过程
Z本质上还是X向量,只不过包含了一些新的信息:包含X中每个向量和所有向量之间的相似度,让x1/x2…去关注更重要的词向量Self-Attention和RNN、LSTM的比较
RNN

梯度消失:RNN梯度=近距离梯度+远距离梯度。而RNN远距离梯度可能会消失,导致梯度被近距离梯度主导。所以RNN无法做长序列,所以有长序列依赖问题。无法并行,只能串行。
LSTM

通过引入门机制,来控制特征的流通和流失,解决RNN的长期依赖问题和梯度消失问题。Self-Attention
解决长序列依赖问题:self-attention可以计算句子中每个词向量和所有词向量的相关性,再长的单词也没关系(一般50个左右的单词最好 因为太长的话计算量过大)。
解决并行问题:矩阵计算,可以同时计算所有单词和其他所有单词的相关性。
self-attention得到的新的词向量具有语法特征(如making -> more/difficult)和语义特征(如its -> law/application),对词向量的表征更完善。缺点:计算量变大了。位置编码问题。
三、多头注意力机制:Multi-Head Self-Attention
Multi-Head Self-Attention得到的新的词向量可以比Self-Attention得到的词向量有进一步提升。
什么是多头?(一般是使用8头)

理论做法:- 输入X;
- 对应8个single head,对应8组 W Q W_Q WQ、 W K W_K WK、 W V W_V WV,再分别进行self-attention,得到 Z 0 Z_0 Z0 - Z 7 Z_7 Z7;
- 再把 Z 0 Z_0 Z0 - Z 7 Z_7 Z7拼接concat起来;
- 再做一次线性变换(降维)得到 Z
源码:
- 输入X;
- 根据 W Q W_Q WQ、 W K W_K WK、 W V W_V WV,生成Q、K、V;
- 再把Q拆分成 q 1 q_1 q1… q 7 q_7 q7,K拆分成 k 1 k_1 k1… k 7 , k_7, k7,V拆分成 v 1 v_1 v1… v 7 v_7 v7;
- 8个头分别做自注意力机制;
- 再把 Z 0 Z_0 Z0 - Z 7 Z_7 Z7拼接concat起来;
- 再做一次线性变换(降维)得到 Z
为什么多头?有什么作用?
机器学习的本质:y = σ ( w x + b ) \sigma(wx+b) σ(wx+b),其实就是在做非线性变换。把数据x(它是不合理的),通过非线性变换,变成数据y(合理)。
非线性变换的本质:空间变换,改变空间上的位置坐标。
self-attention本质,通过非线性变换,把原始数据空间上的X点位置映射到新空间上的点Z上。
muti-head self-attention:把输入数据X,再把X通过非线性变换,映射到8个不同的子空间上,然后通过这8个不同的子空间去找最终的新空间上的点Z。这样可以捕捉更加丰富的特征信息,效果更好。
四、位置编码:Positional Encoding
为什么需要位置编码?
之前提到,self-attention可以解决长序列依赖问题,并且可以并行。但是并行就意味着它是可以同时计算每个位置和其他位置的相关性的,也就是说词与词之间是不存在顺序关系的。所以如果打乱一句话,那么这句话里的词向量依然不变,即无位置关系。总结:self-attention不像RNN那样有先后顺序,可以找到每个序列的位置,self-attention只是负责计算每个位置和其他位置的相关性。为了解决这个问题,就提出了位置编码。
怎么做位置编码?

- 对词向量进行编码生成embedding x1(shape1);
- 生成相应的位置编码 positional emcoding t1(shape1),如上t1包含x1和x2,x1和x3的位置关系;
- 两者相加add(embedding +positional emcoding),生成最终的输入特征 Embedding with time signal(shape1);
位置编码的生成方式
1、正余弦生成

位置编码底层解释

前面我们知道位置编码其实就是让t1知道x1和x2,x1和x3的位置关系。从公式角度理解为什么?sin(pos+k) = sin(pos)*cos(k) + cos(pos)*sin(k) # sin 表示的是偶数维度 cos(pos+k) = cos(pos)*cos(k) - sin(pos)*sin(k) # cos 表示的是奇数维度 这个公式告诉我们:位置pos + k 是 位置pos 和 位置k 的线性组合 即当我知道 位置pos+k 那内部就会暗含 位置pos 和 位置k 的信息 所以,此时即使打乱了词的位置关系,位置编码也会发生改变 这就解决了transformer的问题- 1
- 2
- 3
- 4
- 5
- 6
2、自学习生成
这种方式比较简单,就直接随机初始化和x1一样shape的随机变量,然后训练网络的时候自动学习即可。Reference
b站: 09 Transformer 之什么是注意力机制(Attention)
b站: 10 Transformer 之 Self-Attention(自注意力机制)
b站: 10 Attention 和 Self-Attention 的区别(还不能区分我就真的无能为力了)
b站: 11 Self-Attention 相比较 RNN 和 LSTM 的优缺点
b站: 13 Transformer的多头注意力,Multi-Head Self-Attention(从空间角度解释为什么做多头)
b站: 14 位置编码公式详细理解补充
b站: 14 Transformer之位置编码Positional Encoding (为什么 Self-Attention 需要位置编码)
-
相关阅读:
Linux 开放端口与监控进程
【企业架构框架】TOGAF 10 现已发布并可用!
C++头文件
【PG】PostgreSQL字符集
BMP编程实践1:C语言实现bmp位图分析与创建
esbuild中文文档-路径解析配置项(Path resolution - External、Main fields)
ssm医院人事管理系统设计与实现 毕业设计源码111151
(13.3)Latex参考文献引用及常规引用
Mental Poker- Part 2
Arduino程序设计(十三)触摸按键实验(TTP223)
- 原文地址:https://blog.csdn.net/qq_38253797/article/details/127461558