-
【数据治理】Atlas2.2.0独立部署-单节点
独立Atlas部署-单节点
前言
本文描述了基于atlas-2.2.0版本进行独立部署的步骤;独立部署指的是不适用Atlas自带的hbase、Zookeeper、Kafka等组件,使用外部的组件服务,这里使用的组件版本如下:
- Hadoop 3.1.1
- Zookeeper 3.8.0
- Solr 8.11.2
- Hbase 2.0.2
正文
部署Zookeeper
下载安装包
为了使用solr集群,这里需要部署Zookeeper,采用三节点的标准集群,先下载安装包并解压授权:
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz chown -R root:root apache-zookeeper-3.8.0-bin- 1
- 2
- 3
配置修改
创建数据目录,生产环境自己重新规划数据目录,这里直接创建在安装目录里了:
mkdir $ZK_HOME/data- 1
修改配置zoo.cfg:
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/data4/apache-zookeeper-3.8.0-bin/data # the port at which the clients will connect clientPort=2181 # the maximum number of client connections. # increase this if you need to handle more clients maxClientCnxns=200 ## Metrics Providers metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider metricsProvider.httpHost=0.0.0.0 metricsProvider.httpPort=7000 metricsProvider.exportJvmInfo=true # Cluster info server.1=172.18.2.13:2888:3888 server.2=172.18.2.31:2888:3888 server.3=172.18.2.32:2888:3888 # 4lw commands 4lw.commands.whitelist=* # Log and snap auto remove autopurge.purgeInterval=1 autopurge.snapRetainCount=5- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
创建myid:
# 在server.1服务器执行 echo 1 > $ZK_HOME/data/myid # 在server.2服务器执行 echo 2 > $ZK_HOME/data/myid # 在server.3服务器执行 echo 3 > $ZK_HOME/data/myid # 在所有服务器执行 chmod 755 $ZK_HOME/data/myid- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
服务启动
# 在三台都执行 $ZK_HOME/bin/zkServer.sh start- 1
- 2
部署Solr
更改资源限制
由于环境没有用solr,所以要手动部署一个,记得手动先把ulimit设置大点,否则会报错
It should be set to 65000 to avoid operational disruption,把下面内容添加的limit.conf里面,这样添加需要重新登陆终端:* - nofile 100000 * - nproc 100000- 1
- 2
如果立刻生效就这样设置,不过是临时的:
ulimit -n 100000 ulimit -u 100000- 1
- 2
更改solr配置
更改zk连接信息和端口信息,配置文件
solr.in.shZK_HOST="172.18.2.13:2181,172.18.2.31:2181,172.18.2.32:2181" SOLR_PORT=8983- 1
- 2
设置完成后在所有服务器启动solr,官方不建议用root用户启动,如果执意用root启动,需要加上force参数:
$SOLR_HOME/bin/solr start -force- 1

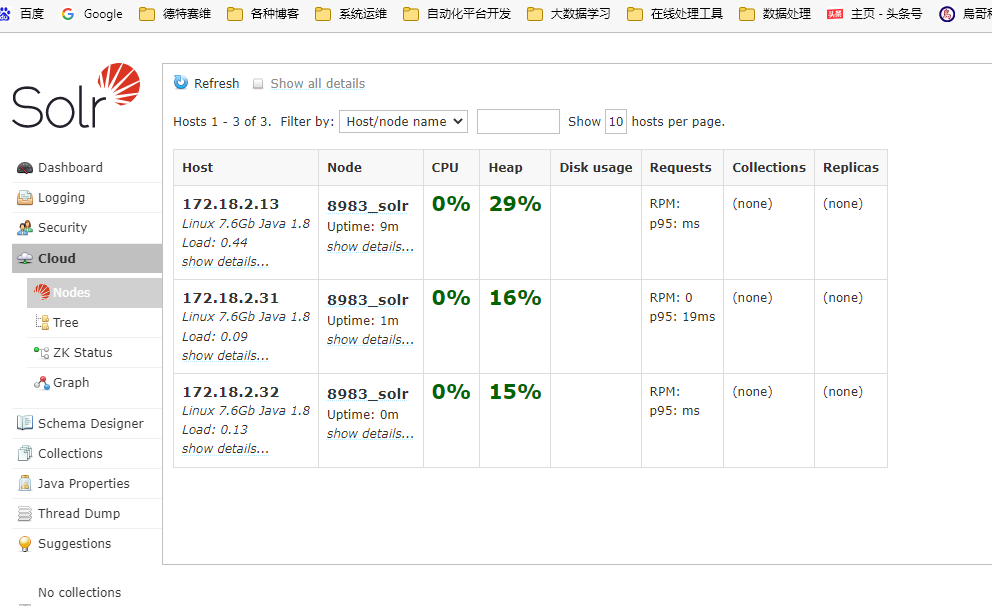
访问ip:8983端口就能访问到solr的webui了,在Cloud中查看集群状态,可以看到是否所有节点都连接到集群:
Kafka配置
使用Atlas提供的脚本配置Kafka Topic:
.$ATLAS_HOME/bin/atlas_kafka_setup.py- 1

部署Atlas
Hbase中授权
Atlas启动和运行过程需要在Hbase中建表和存储数据,因此保证操作用户具备权限:
grant 'root','RWXCA','@default'- 1
创建solr索引
这一步必须执行,无论是单机部署还是独立部署
$SOLR_HOME/bin/solr create -c vertex_index -d $ATLAS_HOME/conf/solr/ -force $SOLR_HOME/bin/solr create -c edge_index -d $ATLAS_HOME/conf/solr/ -force $SOLR_HOME/bin/solr create -c fulltext_index -d $ATLAS_HOME/conf/solr/ -force- 1
- 2
- 3

配置修改
atlas-env.sh中添加一下内容export ATLAS_HOME_DIR=/opt/apache-atlas-2.2.0 export ATLAS_SERVER_OPTS="-server -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+CMSClassUnloadingEnabled -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+PrintTenuringDistribution -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=dumps/atlas_server.hprof -Xloggc:logs/gc-worker.log -verbose:gc -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=1m -XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintGCTimeStamps" export HBASE_CONF_DIR=$ATLAS_HOME/conf/hbase/hbase-site.xml- 1
- 2
- 3
- 4
- 5
hbase-site.xml放在
$ATLAS_HOME_DIR/conf/hbase/下,这个配置文件可以直接从组件的客户端配置下载atlas-application.properties
atlas.graph.index.search.backend=solr #Solr #Solr cloud mode properties atlas.graph.index.search.solr.mode=cloud # Solr使用的Zookeeper集群信息 atlas.graph.index.search.solr.zookeeper-url=172.18.2.13:2181,172.18.2.31:2181,172.18.2.32:2181 atlas.graph.index.search.solr.zookeeper-connect-timeout=60000 # 这是solr的连接信息,默认Atlas配的是8983,注意一下 atlas.graph.index.search.solr.http-urls=http://172.18.2.13:8983/solr # 设置存储引擎hbase2 atlas.graph.storage.backend=hbase2 atlas.graph.storage.hbase.table=apache_atlas_janus # Hbase使用的zk的地址 atlas.graph.storage.hostname=172.18.2.11:2181,172.18.2.37:2181,172.18.2.19:2181 atlas.graph.storage.hbase.regions-per-server=1 # KAFKA配置 ## 使用内置Kafka,false则需要自己搭建kafka,这里使用外部的kafka atlas.notification.embedded=false ## 不做更改 atlas.kafka.data=${sys:atlas.home}/data/kafka ## Kafka使用的ZK信息 atlas.kafka.zookeeper.connect=172.18.2.11:2181,172.18.2.37:2181,172.18.2.19:2181 atlas.kafka.bootstrap.servers=172.18.2.11:6667,172.18.2.37:6667,172.18.2.19:6667 atlas.kafka.zookeeper.session.timeout.ms=400 atlas.kafka.zookeeper.connection.timeout.ms=200 atlas.kafka.zookeeper.sync.time.ms=20 atlas.kafka.auto.commit.interval.ms=1000 atlas.kafka.hook.group.id=atlas ## Topic信息 atlas.notification.create.topics=true atlas.notification.replicas=1 atlas.notification.topics=ATLAS_HOOK,ATLAS_ENTITIES atlas.notification.log.failed.messages=true atlas.notification.consumer.retry.interval=500 atlas.notification.hook.retry.interval=1000 # Atlas服务配置 ## 服务端口 atlas.server.http.port=2100 ## restapi信息 atlas.rest.address=http://172.18.0.25:21000 atlas.ui.editable.entity.types=*- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
启动服务
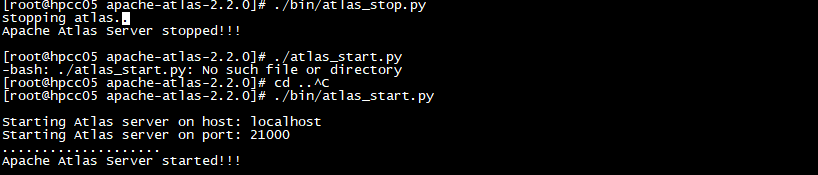
调用启动脚本,启动Atlas服务,第一次启动会创建hbase表等操作,所以启动时间会比较久,如果服务器性能再差一点,就会更久,等着就行。
$ATLAS_HOME/bin/atlas_start.py- 1
结语
Atlas的独立部署在生产环境是很有必要的,自带的hbase和kafka是没法承担海量数据的存储和消息传递的,本博文的所有步骤均在自己的环境中测试成功。
-
相关阅读:
vue在调用摄像头扫码(vue-qrcode-reader)
ETLCloud制造业轻量级数据中台解决方案
[PostgreSql]生产级别数据库安装要考虑哪些问题?
ES使用ik分词器查看分词结果及自定义词汇
重磅发布|美创科技新一代 数据安全管理平台(DSM Cloud)全新升级
Python笔记-从配置读取参数
web前端教程全套:从入门到精通的全方位探索
流体力学基础——简介
Java中类成员访问权限修饰符(public、protected、default、private)
(针对 G1 )JVM常用参数讲解:-XX,-X,-D 的区别与常用JVM配置 +应用程序配置实例+ 调优思路
- 原文地址:https://blog.csdn.net/Meepoljd/article/details/127862758
