-
第五周算法题
[NOIP2014 提高组] 生活大爆炸版石头剪刀布
- 题目描述
石头剪刀布是常见的猜拳游戏:石头胜剪刀,剪刀胜布,布胜石头。如果两个人出拳一样,则不分胜负。在《生活大爆炸》第二季第 8 集中出现了一种石头剪刀布的升级版游戏。
升级版游戏在传统的石头剪刀布游戏的基础上,增加了两个新手势:
斯波克:《星际迷航》主角之一。
蜥蜴人:《星际迷航》中的反面角色。
这五种手势的胜负关系如表一所示,表中列出的是甲对乙的游戏结果。

现在,小 A 和小 B 尝试玩这种升级版的猜拳游戏。已知他们的出拳都是有周期性规律的,但周期长度不一定相等。例如:如果小 A 以“石头-布-石头-剪刀-蜥蜴人-斯波克”长度为 6 6 6 的周期出拳,那么他的出拳序列就是“石头-布-石头-剪刀-蜥蜴人-斯波克-石头-布-石头-剪刀-蜥蜴人-斯波克-…”,而如果小 B 以“剪刀-石头-布-斯波克-蜥蜴人”长度为 5 5 5 的周期出拳,那么他出拳的序列就是“剪刀-石头-布-斯波克-蜥蜴人-剪刀-石头-布-斯波克-蜥蜴人-…”
已知小 A 和小 B 一共进行 N N N 次猜拳。每一次赢的人得 1 1 1 分,输的得 0 0 0 分;平局两人都得 0 0 0 分。现请你统计 N N N 次猜拳结束之后两人的得分。
- 输入格式
第一行包含三个整数: N , N A , N B N,N_A,N_B N,NA,NB,分别表示共进行 N N N 次猜拳、小 A 出拳的周期长度,小 B 出拳的周期长度。数与数之间以一个空格分隔。
第二行包含 N A N_A NA 个整数,表示小 A 出拳的规律,第三行包含 N B N_B NB 个整数,表示小 B 出拳的规律。其中, 0 0 0 表示“剪刀”, 1 1 1 表示“石头”, 2 2 2 表示“布”, 3 3 3 表示“蜥蜴人”,$4 $表示“斯波克”。数与数之间以一个空格分隔。
- 输出格式
输出一行,包含两个整数,以一个空格分隔,分别表示小 A、小 B 的得分。
-
样例 #1
-
样例输入 #1
10 5 6 0 1 2 3 4 0 3 4 2 1 0- 1
- 2
- 3
- 样例输出 #1
6 2- 1
-
样例 #2
-
样例输入 #2
9 5 5 0 1 2 3 4 1 0 3 2 4- 1
- 2
- 3
- 样例输出 #2
4 4- 1
- 提示
对于 100 % 100\% 100%的数据, 0 < N ≤ 200 , 0 < N A ≤ 200 , 0 < N B ≤ 200 0 < N \leq 200, 0 < N_A \leq 200, 0 < N_B \leq 200 0<N≤200,0<NA≤200,0<NB≤200 。
n, na, nb = map(int, input().split()) a_list = list(map(int, input().split())) b_list = list(map(int, input().split())) a_score, b_score = 0, 0 cnt_a, cnt_b = 0, 0 for i in range(n): if a_list[cnt_a] == 0: if b_list[cnt_b] == 2 or b_list[cnt_b] == 3: a_score += 1 elif a_list[cnt_a] == 1: if b_list[cnt_b] == 3 or b_list[cnt_b] == 0: a_score += 1 elif a_list[cnt_a] == 2: if b_list[cnt_b] == 4 or b_list[cnt_b] == 1: a_score += 1 elif a_list[cnt_a] == 3: if b_list[cnt_b] == 4 or b_list[cnt_b] == 2: a_score += 1 elif a_list[cnt_a] == 4: if b_list[cnt_b] == 1 or b_list[cnt_b] == 0: a_score += 1 if b_list[cnt_b] == 0: if a_list[cnt_a] == 2 or a_list[cnt_a] == 3: b_score += 1 elif b_list[cnt_b] == 1: if a_list[cnt_a] == 3 or a_list[cnt_a] == 0: b_score += 1 elif b_list[cnt_b] == 2: if a_list[cnt_a] == 4 or a_list[cnt_a] == 1: b_score += 1 elif b_list[cnt_b] == 3: if a_list[cnt_a] == 4 or a_list[cnt_a] == 2: b_score += 1 elif b_list[cnt_b] == 4: if a_list[cnt_a] == 0 or a_list[cnt_a] == 1: b_score += 1 cnt_a += 1 cnt_b += 1 cnt_a %= na cnt_b %= nb print(a_score, b_score)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
[NOIP2016 提高组] 玩具谜题
- 题目背景
NOIP2016 提高组 D1T1
- 题目描述
小南有一套可爱的玩具小人, 它们各有不同的职业。
有一天, 这些玩具小人把小南的眼镜藏了起来。 小南发现玩具小人们围成了一个圈,它们有的面朝圈内,有的面朝圈外。如下图:
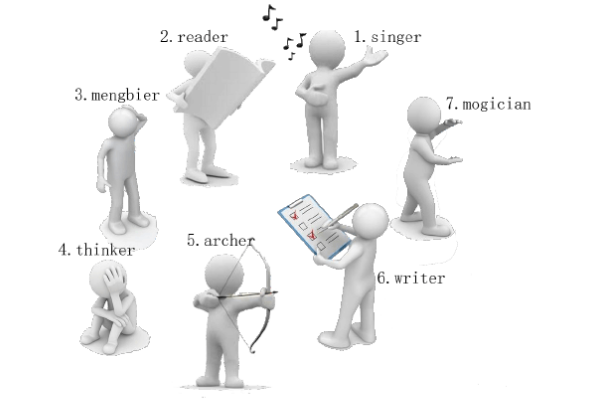
这时 singer 告诉小南一个谜題: “眼镜藏在我左数第 3 3 3 个玩具小人的右数第 1 1 1 个玩具小人的左数第 2 2 2 个玩具小人那里。 ”
小南发现, 这个谜题中玩具小人的朝向非常关键, 因为朝内和朝外的玩具小人的左右方向是相反的: 面朝圈内的玩具小人, 它的左边是顺时针方向, 右边是逆时针方向; 而面向圈外的玩具小人, 它的左边是逆时针方向, 右边是顺时针方向。
小南一边艰难地辨认着玩具小人, 一边数着:
singer 朝内, 左数第 3 3 3 个是 archer。
archer 朝外,右数第 1 1 1 个是 thinker 。
thinker 朝外, 左数第 2 2 2 个是 writer。
所以眼镜藏在 writer 这里!
虽然成功找回了眼镜, 但小南并没有放心。 如果下次有更多的玩具小人藏他的眼镜, 或是谜题的长度更长, 他可能就无法找到眼镜了。所以小南希望你写程序帮他解决类似的谜题。 这样的谜題具体可以描述为:
有 n n n 个玩具小人围成一圈, 已知它们的职业和朝向。现在第 1 1 1 个玩具小人告诉小南一个包含 m m m 条指令的谜題, 其中第 z z z 条指令形如“左数/右数第 s s s,个玩具小人”。 你需要输出依次数完这些指令后,到达的玩具小人的职业。
- 输入格式
输入的第一行包含两个正整数 n , m n,m n,m,表示玩具小人的个数和指令的条数。
接下来 n n n 行,每行包含一个整数和一个字符串,以逆时针为顺序给出每个玩具小人的朝向和职业。其中 0 0 0 表示朝向圈内, 1 1 1 表示朝向圈外。 保证不会出现其他的数。字符串长度不超过 10 10 10 且仅由小写字母构成,字符串不为空,并且字符串两两不同。整数和字符串之间用一个空格隔开。
接下来 m m m 行,其中第 i i i 行包含两个整数 a i , s i a_i,s_i ai,si,表示第 i i i 条指令。若 a i = 0 a_i=0 ai=0,表示向左数 s i s_i si 个人;若 a i = 1 a_i=1 ai=1,表示向右数 s i s_i si 个人。 保证 a i a_i ai 不会出现其他的数, 1 ≤ s i < n 1 \le s_i < n 1≤si<n。
- 输出格式
输出一个字符串,表示从第一个读入的小人开始,依次数完 m m m 条指令后到达的小人的职业。
-
样例 #1
-
样例输入 #1
7 3 0 singer 0 reader 0 mengbier 1 thinker 1 archer 0 writer 1 mogician 0 3 1 1 0 2- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 样例输出 #1
writer- 1
-
样例 #2
-
样例输入 #2
10 10 1 C 0 r 0 P 1 d 1 e 1 m 1 t 1 y 1 u 0 V 1 7 1 1 1 4 0 5 0 3 0 1 1 6 1 2 0 8 0 4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 样例输出 #2
y- 1
- 提示
【样例1说明】
这组数据就是【题目描述】 中提到的例子。
【子任务】
子任务会给出部分测试数据的特点。 如果你在解决题目中遇到了困难, 可以尝试只解决一部分测试数据。
每个测试点的数据规模及特点如下表:

其中一些简写的列意义如下:
-
全朝内: 若为“√”, 表示该测试点保证所有的玩具小人都朝向圈内;
-
全左数:若为“√”,表示该测试点保证所有的指令都向左数,即对任意的 1 ≤ z ≤ m , a i = 0 1\leq z\leq m, a_i=0 1≤z≤m,ai=0;
-
s = 1 s=1 s=1:若为“√”,表示该测试点保证所有的指令都只数 1 1 1 个,即对任意的 1 ≤ z ≤ m , s i = 1 1\leq z\leq m,s_i=1 1≤z≤m,si=1;
职业长度为 1 1 1:若为“√”,表示该测试点保证所有玩具小人的职业一定是一个长度为 1 1 1的字符串。
n, m = map(int, input().split()) p_d = [] for pd in range(n): p_d.append(list(map(str, input().split()))) orders = [] for o in range(m): orders.append(list(map(int, input().split()))) pos = 0 for d, num in orders: if d == 0: if p_d[pos][0] == '0': pos -= num else: pos += num else: if p_d[pos][0] == '0': pos += num else: pos -= num if pos >= n: pos %= n elif pos < 0: pos += n print(p_d[pos][1])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
[NOIP2010 普及组] 数字统计
- 题目描述
请统计某个给定范围 [ L , R ] [L, R] [L,R]的所有整数中,数字 2 2 2 出现的次数。
比如给定范围 [ 2 , 22 ] [2, 22] [2,22],数字$ 2$ 在数 $2 $中出现了 1 1 1 次,在数$ 12$ 中出现 1 1 1 次,在数 20 20 20 中出现 $1 $次,在数 21 中出现 1 1 1 次,在数 22 22 22 中出现 $2 次 , 所 以 数 字 次,所以数字 次,所以数字 2$ 在该范围内一共出现了 6 6 6次。
- 输入格式
2 2 2个正整数 L L L 和 R R R,之间用一个空格隔开。
- 输出格式
数字 $2 $出现的次数。
-
样例 #1
-
样例输入 #1
2 22- 1
- 样例输出 #1
6- 1
-
样例 #2
-
样例输入 #2
2 100- 1
- 样例输出 #2
20- 1
- 提示
1 ≤ L ≤ R ≤ 100000 1 ≤ L ≤R≤ 100000 1≤L≤R≤100000。
L, R = map(int, input().split()) cnt = 0 for num in range(L, R+1): for c in str(num): if c == '2': cnt += 1 print(cnt)- 1
- 2
- 3
- 4
- 5
- 6
- 7
【模板】快速排序
- 题目描述
利用快速排序算法将读入的 N N N 个数从小到大排序后输出。
快速排序是信息学竞赛的必备算法之一。对于快速排序不是很了解的同学可以自行上网查询相关资料,掌握后独立完成。(C++ 选手请不要试图使用
STL,虽然你可以使用sort一遍过,但是你并没有掌握快速排序算法的精髓。)- 输入格式
第 1 1 1 行为一个正整数 N N N,第 2 2 2 行包含 N N N 个空格隔开的正整数 a i a_i ai,为你需要进行排序的数,数据保证了 a i a_i ai 不超过 1 0 9 10^9 109。
- 输出格式
将给定的 N N N 个数从小到大输出,数之间空格隔开,行末换行且无空格。
-
样例 #1
-
样例输入 #1
5 4 2 4 5 1- 1
- 2
- 样例输出 #1
1 2 4 4 5- 1
- 提示
对于 20 % 20\% 20% 的数据,有 N ≤ 1 0 3 N\leq 10^3 N≤103;
对于 100 % 100\% 100% 的数据,有 N ≤ 1 0 5 N\leq 10^5 N≤105。
# def quick_sort(lst, i, j): # if i >= j: # return # pivot = lst[i] # low = i # high = j # while i < j: # while i < j and lst[j] >= pivot: # j -= 1 # lst[i] = lst[j] # # while i < j and lst[i] <= pivot: # i += 1 # lst[j] = lst[i] # # lst[j] = pivot # quick_sort(lst, low, i-1) # quick_sort(lst, i+1, high) # return lst # def quick_sort(array, l, r): # if l < r: # q = partition(array, l, r) # quick_sort(array, l, q - 1) # quick_sort(array, q + 1, r) # # def partition(array, l, r): # x = array[r] # i = l - 1 # for j in range(l, r): # if array[j] <= x: # i += 1 # array[i], array[j] = array[j], array[i] # array[i + 1], array[r] = array[r], array[i+1] # return i + 1 n = int(input()) lst = list(map(int, input().split())) lst.sort() for i in lst: print(i, end=" ")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
-
相关阅读:
卖出看涨期权和买入看跌期权有什么区别?卖出看跌期权有什么用?
JAVA中简单的for循环竟有这么多坑,但愿你没踩过
[附源码]计算机毕业设计springboot新能源汽车租赁
LeetCode-790. 多米诺和托米诺平铺【动态规划,矩阵快速幂】
淘宝商品销量接口/淘宝商品销量监控接口/商品累计销量接口代码对接分享
MySql分库分表
Mathorcup数学建模竞赛第四届-【妈妈杯】B题:基于协同过滤的智能书籍推荐系统(附解题思路和MATLAB代码实现)
[java刷算法]牛客—剑指offer动态规划,位移比较,负乘方转换
畅游青岛旅游系统的设计与实现
c++day5
- 原文地址:https://blog.csdn.net/qq_54804745/article/details/127857509
