-
JVM虚拟机知识点(保姆级教程)
jvm虚拟机知识点
温馨提示:本章节阅读预计耗时>30分钟,请沏茶细品。如果描述不准确或者缺漏的地方,还请技术大大们指点迷津!
目录索引JVM基础
了解HotSpot
我们日常所说的JVM,一般值得都是Hotspot(热点)虚拟机。
java原先是把源代码编译为字节码在虚拟机执行,这样的执行效率比较慢。而Hotspot是将字节码编译为本地代码,从而提高整体运行效率。
HotSpot包括一个解释器和两个编译器(client or server),采用解释器与编译器混合模式。
编译器:将源代码编译成字节码
解释器:用来解析字节码(书上这么说的)
编译器-client:启动快,占用内存小,执行效率没有server高,默认不开启动态编译,适用于桌面应用
编译器-server:奇动漫,占用内存大,执行效率高,默认开始动态编译,适用于服务端应用可以通过以下命令看当前虚拟机的执行引擎
$ java -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode) $ java -Xint -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, interpreted mode) $ java -Xcomp -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, compiled mode)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
java编译原理
什么是字节码、机器码、本地代码
字节码:即.class文件。javac工具将,java文件进行编译,产生的.class文件即为字节码
机器码:机器指令。操作系统能够识别的语言
本地代码:机器指令。操作系统能够识别的语言编译过程
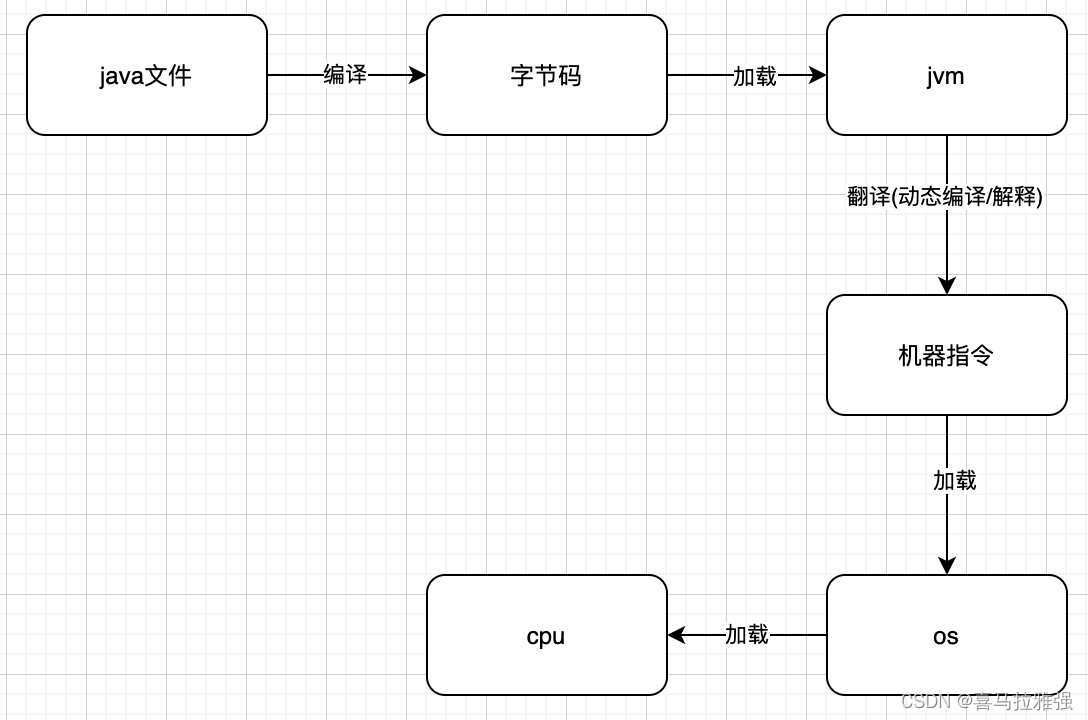
C和C++语言是将源代码编译成机器语言,这样机器可以直接执行。缺点是需要适配不同的操作系统,没法实现”一次编译,到处运行“
java语言是将源代码编译成字节码文件,通过不同版本的JVM去进行适配,最终生成机器指令,实现了”一次编译,到处运行“。 实际上,最重要的指令翻译操作隐藏在JVM中,所以程序员只需要考虑自己的代码编写即可,无需关心操作系统不同所带来的影响。JIT
JIT产生的背景
JVM通过解释器将字节码翻译成机器语言,逐行读取,逐行翻译。经过解释执行,其效率必要要比可执行的二进制程序慢很多,这就是传统JVM解释器(Interpreter)的功能,为了解决执行效率慢的问题,JIT即时编译技术应运而生。
JIT即时编译器
JIT(Just In Time)能在JVM发现热点代码时,将这些代码编译成与本地平台相关的机器码,并执行各个层次的优化,从而提高代码的执行效率。
- 热点代码:频繁执行的方法或代码块
- 目的:提高代码的执行效率
当JVM执行代码时,JIT不会立刻对其进行编译。倘若这段代码只运行一次,让解释器翻译成机器语言效率更高。JIT编译会比较耗时,仅适用于频繁访问的代码。所以一般使用解释器+编译器混合模式(mixed mode)可以发挥他们各自的优势。

热点代码机制
前面提到JIT通过热点代码进行编译成机器码,从而提升代码执行效率。那么热点代码是如何判断的呢?
- 基于采样的热点探测:周期检查各个线程的栈顶,发现某个方法经常出现在栈顶,则为热点方法
- 基于计数器的热点探测(HotSpot采用):为每个方法(代码块)创建计数器,统计方法的执行次数,当超过一定阈值时认为是热点代码。
计数器热点探测
计数器=方法计数器+回边计数器,当计数器达到阈值时会向编译器请求编译。- 方法计数器:顾名思义,就是记录一个方法被调用的次数(PS:方法计数器统计的是一定时间内的调用次数,当超过一定时间,仍然没有到达阈值,那么计数器将减半,此过程也叫“热度衰减”)
- 回边计数器:用于统计循环体的执行次数,字节码中遇到控制流向后跳转的指令,称之为“回边”
JVM运行时数据区
运行时数据区:java程序运行过程数据的存储区域,划分为5个区域(方法区、堆、虚拟机栈、本地方法区、程序计数器)


方法区
存储类信息、常量池、静态变量以及JIT编译后的本地代码等数据JAVA堆
- 堆是jvm中内存最大的一块区域
- 所有的对象实例和数组都在此分配
虚拟机栈
- 虚拟机栈是线程私有的
- 虚拟机栈的生命周期与线程相同
解释:每虚拟机栈中是有单位的,单位就是栈帧,一个方法一个栈帧。一个栈帧中他又要存储,局部变量,操作数栈,动态链接,出口等。
解析栈帧:
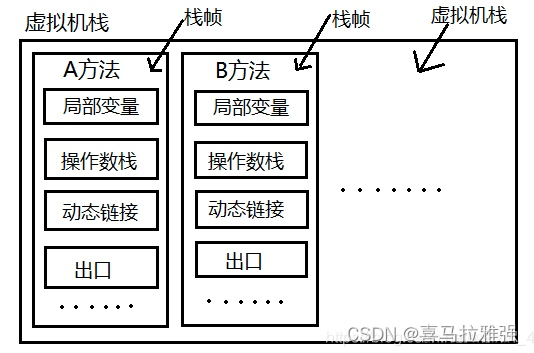
局部变量表:是用来存储我们临时8个基本数据类型、对象引用地址、returnAddress类型。(returnAddress中保存的是return后要执行的字节码的指令地址。)
操作数栈:操作数栈就是用来操作的,例如代码中有个 i = 6*6,他在一开始的时候就会进行操作,读取我们的代码,进行计算后再放入局部变量表中去
动态链接:假如我方法中,有个 service.add()方法,要链接到别的方法中去,这就是动态链接,存储链接的地方。
出口:出口是什呢,出口正常的话就是return 不正常的话就是抛出异常落本地方法区
- 被native修饰的方法
- 底层是C或C++实现,用于实现与操作系统相关的指令
- 本地方法区的生命周期与线程相同
程序计数器
- 程序计数器的内存很小,它用于记录当前线程执行字节码指令的地址
- 由于JVM多线程是通过线程切换分配CPU执行时间来实现的,为了在切换线程后能恢复到正确的位置,因此加入了程序计数器,记录当前线程的执行地址。每个线程独立分配程序计数器,互不影响。
- 程序计数器的生命周期与线程相同。
垃圾回收机制
C或C++语言编程时,程序员经常需要编写代码去操作内存空间释放,这种操作上手难度大,极易出现内存泄露、内存溢出等现象。
因此java语言设计时将内存管理封装在jvm中,程序员无需关心内存是如何回收的,只需要在上层应用编写业务代码即可。这种内存管理模式就是垃圾回收(GC)。如何判断是否为垃圾对象
相信大家有所了解,常见的判断垃圾对象算法有引用计数法、可达性分析
1. 引用计数法
原理:对象创建的时候,给这个对象绑定一个计数器。用计数器统计对象引用的次数,当次数为0时,表示当前对象无引用,判定为垃圾对象。
优点:引用计数法实现简单,效率高
缺点:无法解决循环引用问题
一般不推荐使用,至少主流的jvm都不采用这种方式。// 引用计数法案例 class User{ User user; } public static void main(String[] args){ User a = new User(); User b = new User(); // 循环引用 a.user = b; b.user = a; // a、b指向null a = null; b = null; // 此时堆空间中循环引用对象仍然存在,无法回收 }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2.可达性分析
原理:从根节点开始向下搜索,搜索所走的路径叫引用链。当一个对象到根节点没有任何引用链时,表示该对象不可用,可以被回收。根节点也叫GC Roots
那么GC ROOTS到底是什么呢?什么样的对象可以判定为GC Roots
1、虚拟机栈(栈帧中的本地变量表)中引用的对象; 2、方法区中类静态属于引用的对象; 3、方法区中常量引用的对象; 4、本地方法栈中JNI(即一般说的Native方法)引用的对象。 ...- 1
- 2
- 3
- 4
- 5
垃圾回收算法
当对象识别为垃圾对象后,即可开始进行垃圾清理。常见的垃圾回收算法有以下几种方式
- 复制(Coping)
- 标记-清除(Mark-Sweep)
- 标记-整理(Mark-Conpact)
- 分代回收算法
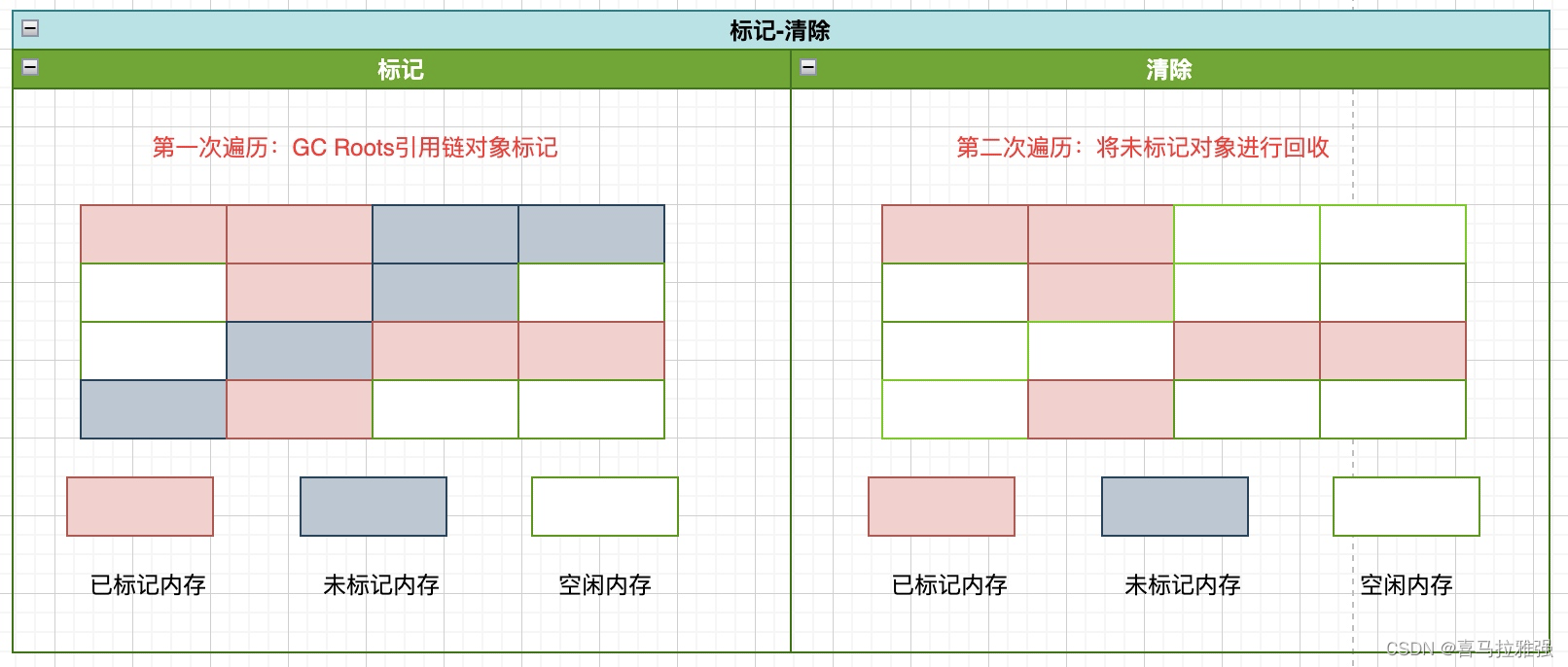
标记-清除
标记-清除算法分为两个阶段
**标记阶段:**通过垃圾识别方式,从GC Roots开始把引用链上的对象打标记,未被标记的对象即为垃圾对象
**清除阶段:**将未被标记的垃圾对象进行内存空间回收不足之处:
- 标记和清除两个阶段的效率都不高
- 空间利用率低。清除之后会产生大量的空间碎片,当内存需要分配一个比较大的对象时,不得不重新触发垃圾回收
标记-整理
标记-整理是标记-清除的改良版,主要解决内存碎片的问题
**标记阶段:**通过垃圾识别方式,从GC Roots开始把引用链上的对象打标记,未被标记的对象即为垃圾对象
**整理阶段:**将标记的对象整理到内存的某一端
**清除阶段:**将未被标记的垃圾对象进行内存空间回收
优点:减少内存碎片,可以存储更多大对象
缺点:比起标记-清除算法,整理算法多了一步内存移动操作,效率会降低复制算法
效率提升,要么时间换空间,要么空间换时间
标记-清除、标记-整理的算法效率都是比较低的,因为涉及到两次遍历。于是有了复制算法
原理:复制算法将内存以1:1比例划分为两个区域,同一时间,只允许一块活跃区域使用。当触发垃圾回收时,会进入以下阶段
**复制阶段:**通过GC Roots寻找存活对象,将其复制到另一块内存空间,标记此空间为活跃区域
**清除阶段:**将旧的活跃区域清空(基本不耗时)
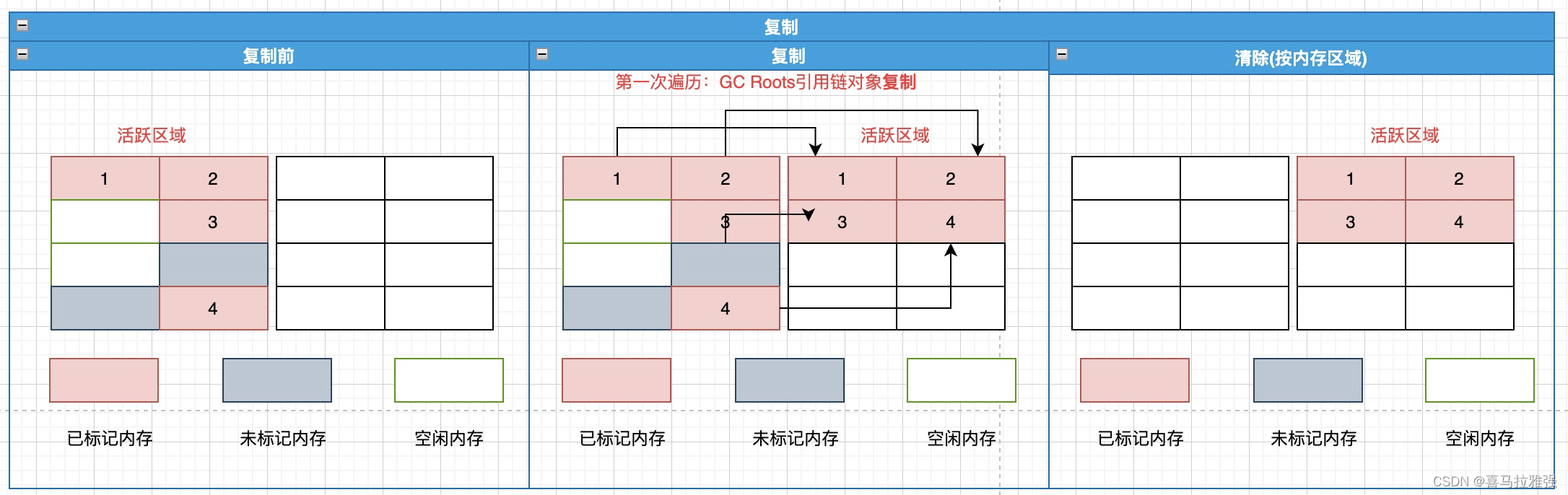
小结:- 时间复杂度比较:复制 > 标记-清除 > 标记-整理
- 空间复杂度比较:标记-清除 ~= 标记-整理 > 复制
技术始终是服务于业务的
当我们进行垃圾回收时,考虑到空间碎片不能太多,因为空间碎片化会导致频繁GC,所以我们只能考虑标记-整理or赋值算法。
试想,假如你有一片内存空间,- 若空间里驻存着大量朝生夕死的对象,垃圾对象多,存活对象少。此时我们可以使用复制算法,只复制少量存活对象,此方式效率是最高的。
- 若空间里老龄化严重,垃圾对象少,存活对象多。此时使用复制算法就不占优势了,复制对象多会导致整体性能下降。所以对于大量对象存活的内存空间,我们采用标记-整理算法
原因:
a.内存利用率高;
b.当存活对象较多时,复制算法和标记-整理算法性能差不多。你想想看,假设内存中98%的对象存活,通过复制算法,一次遍历需要将98%的数据进行复制,这得活活累死JVM;而标记-整理算法第一次遍历只打标记,整理内存,第二次遍历只需要清除较少的垃圾对象,因此综合效率要比复制算法高。
因此我们得到一个结论
对象存活率低时,使用复制算法
对象存活率高时,使用标记-整理算法(或标记-清除算法)分析了一大堆,这完全没提老师傅标记-清除啊,标记-清除算法就要被抛弃了吗?

其实不然,每个算法都有适合它的业务场景。当对象存活率高,且都是小对象时,多一步整理反而显得有些画蛇添足,浪费性能,此时用标记-整理算法反而会更合适。只不过这种场景一般不多,造成了标记-整理算法优于标记-清除算法的假象

分代回收算法
分带回收算法是一个抽象的概念,它不是一个具体的实现,而是将其他垃圾回收算法进行分类组合,从而提升虚拟机的整体性能。
前面提到垃圾回收算法与对象的存活率相关,因此分代回收算法把对象分为年轻代(对象存活率低)、老年代(对象存活率高)两个区域年轻代
年轻代使用复制算法,但不会1:1将内存进行分配,这样的内存利用率太低了,只有50%。为了解决内存利用率低的问题,互联网的大神们纷纷祭出法宝,通过数据计算,最终产生了年轻代最佳的分区方式:eden : survivor1 : survivor = 8:1:1(为了方便描述,下面S代表survivor)
名词解释 eden:伊甸区。你可以想象到亚当和夏娃的故事,伊甸园作为一切生命的起源。因此,所有对象都在这个区域产生 s1: 幸存者1区 s2: 幸存者2区- 1
- 2
- 3
- 4
工作流程:s1和s2同一时间只有一块区域是活跃的,另一块作为备胎使用(为什么我会想到备胎?不要问,问了就是不知道)
首先,jvm启动时会将s1设置成活跃状态,当创建对象时,jvm会向eden区申请内存。当eden内存空间不足以分配新的内存时触发Minor GC老年代
老年代中因为对象存活率高,减少进行垃圾回收,为了使其空间不造浪费,老年代只使用唯一一块内容空间,因此在进行拉取回收时,可以选择“标记-清楚”或者“标记-整理”两种方式。 具体实现方式需要看jvm执行时选择的垃圾收集器
常见的垃圾收集器
什么是垃圾收集器?
垃圾回收器指的是标记-清除、复制算法、标记-整理的具体实现
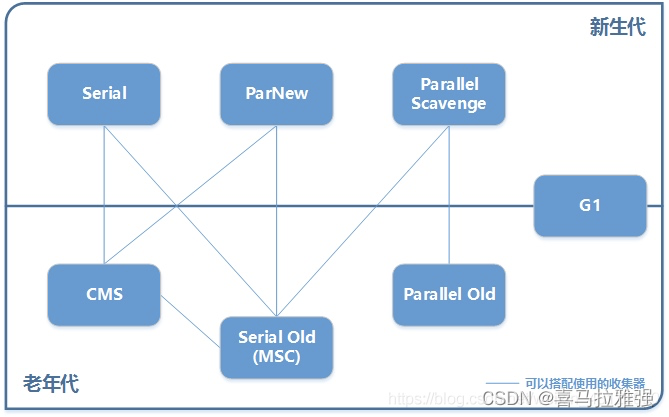
年轻代
Serial、ParNew、Parallel Scavenge
老年代
CMS、Serial Old、Parallel Old年轻代-Serial
单线程垃圾收集器,只能使用一个CPU去进行垃圾回收,且GC时,其他线程会进入暂停状态
特点:- 使用复制算法
- 适合单CPU环境,没有上下文切换的成本,运行效率高
-XX:+UseSerialGC,设置串行收集器,年轻代收集器
年轻代-ParNew
多线程垃圾收集器,同时启动多个线程进行垃圾收集,且GC时,其他线程会进入暂停状态
特点:- 采用复制算法
- 适合多CPU环境
- 只能与CMS配合使用
-XX:+UseParNewGC,设置并行收集器,年轻代收集器
年轻代-Parallel Scavenge
多线程收集器,可以调整程序吞吐量
特点:- 采用复制算法
- 适合多CPU环境
- 可调节吞吐量
-XX:+UseParallelGC,设置并行收集器,目的是达到可控制的吞吐量,年轻代收集器
备注:
吞吐量=程序运行时间/(程序运行时间+GC耗时)
如程序运行时间99s,GC耗时1s,那么吞吐量 = 99/(99+1) = 99%Parallel Scavenge 分别通过-XX:MaxGCPauseMillis和-XX:GCTimeRatio两个参数来控制吞吐量
-XX:MaxGCPauseMillis:设置GC最大停顿时间,单位ms,适用于高用户场景。程序员建议不要修改这个值,jvm会自动调节。理论上降低GC停顿时间,可以获得高吞吐量,但是MinorGC的调用频率就上去了,从而降低了系统的吞吐量。因此MaxGCPauseMillis这个参数比较难控制。老年代-Serial Old
单线程收集器
特点:- 采用标记-整理算法
- 单线程收集器
-XX:+UseSerialOldGC,设置串行收集器,老年代收集器
老年代-Parallel Old
特点:
- 采用标记-整理算法
- 多线程收集器
-XX:+UseParallelOldGC,设置并行收集器,老年代收集器
老年代-CMS
特点:
- 采用标记-清除算法
- 并发收集、低停顿
- GC时,工作线程不暂停
-XX:+UseConcMarkSweepGC,设置并发收集器,老年代收集器
G1
分代回收器
特点:- 多线程收集器
- 并发GC、与工作线程同事进行
- 分年轻代、老年代进行垃圾回收
- 采用复制算法、标记-整理算法
-XX:+UseG1GC,设置G1收集器,jdk1.9默认使用
内存调优
vm选项
或者你曾看过xmx、xms、xss等参数,知道他们是用于vm内存调优,但不知道他们的含义、调整范围。那么这篇文章就非常适合你阅读了。
先看看VM选项, 三种:- -: 标准VM选项,VM规范的选项
- -X: 非标准VM选项,不保证所有VM支持
- -XX: 高级选项,高级特性,但属于不稳定的选项
常见的JVM参数
-X 参数
- -Xmx(memory maxium):最大堆内存,等同于 -XX:MaxHeapSize
- -Xms(memory startup):初始化堆内存大小
- -Xmn(memory new):堆中年轻代初始大小,可具体细化,初始化大小用-XX:NewSize,最大大小用-XX:MaxNewSize
- -Xss(stack size):线程栈大小,等同于 -XX:ThreadStackSize
-XX 参数
- -XX:NewSize=n:设置年轻代大小
- -XX:NewRatio=n: 设置年轻代和年老代的比值。比如n=2,代表年轻代和年老代的比值为1:2。
- -XX:SurvivorRatio=n: 年轻代中Eden区/Suvivor区。比如n=4,代表Eden:Survivor=4:1*2(有两个Survivor区)
- -XX:-UseAdaptiveSizePolicy: 取消默认的Ratio动态设置,只有设置了此选项,上面的那个选项才能生效
- -XX: MaxPermSize=n: 设置持久代大小
- -XX:+PrintTenuringDistribution:打印Tunuring年龄信息
- -XX:+HeapDumpOnOutOfMemoryError: OOM时输出heap dump
- -XX:HeapDumpPath= 目 录 参 数 表 示 生 成 D U M P 文 件 的 路 径 , 也 可 以 指 定 文 件 名 称 , 例 如 : − X X : H e a p D u m p P a t h = {目录}参数表示生成DUMP文件的路径,也可以指定文件名称,例如:-XX:HeapDumpPath= 目录参数表示生成DUMP文件的路径,也可以指定文件名称,例如:−XX:HeapDumpPath={目录}/java_heapdump.hprof。如果不指定文件名,默认为:java_
调优总结
- 在实际工作中,我们可以直接将初始的堆大小与最大堆大小相等,
这样的好处是可以减少程序运行时垃圾回收次数,从而提高效率。 - 初始堆值和最大堆内存内存越大,吞吐量就越高,
但是也要根据自己电脑(服务器)的实际内存来比较。 - 最好使用并行收集器,因为并行收集器速度比串行吞吐量高,速度快。
当然,服务器一定要是多线程的 - 设置堆内存新生代的比例和老年代的比例最好为1:2或者1:3。
默认的就是1:2 - 减少GC对老年代的回收。设置生代带垃圾对象最大年龄,进量不要有大量连续内存空间的java对象,因为会直接到老年代,内存不够就会执行GC
注释:其实最主要的还是服务器要好,你硬件都跟不上,软件再好都没用
注释:老年代GC很慢,新生代没啥事
注释:默认的JVM堆大小好像是电脑实际内存的四分之一左右类加载器
类加载过程
加载-链接-初始化
-
加载
首先,JVM将class文件读入内存,并将这些静态数据转换成方法区的数据结构,JVM还会在堆中生成一个与之对应的java.lang.Class文件. -
连接
当类被加载后,系统生成了class文件,接着将会进入连接阶段。
连接阶段负责把类的二进制数据载入JRE(意思是将java类的二进制数据加载到JVM运行时环境)。连接阶段又分为以下三个过程:
2-1. 验证:检查被加载的class文件是否符合JVM规范。主要检查class二进制数据格式。
2-2. 准备:负责为类的静态变量分配内存,并设置默认初始值。
2-3. 解析:将类的二进制数据中的符号引用替换成直接引用。说明一下:符号引用:符号引用是以一组符号来描述所引用的目标,符号可以是任何的字面形式的字面量,只要不会出现冲突能够定位到就行。布局和内存无关。直接引用:是指向目标的指针,偏移量或者能够直接定位的句柄。该引用是和内存中的布局有关的,并且一定加载进来的。 -
初始化
为类的静态变量赋予正确的初始值。
ps:需要注意的是,准备阶段和初始化阶段不矛盾,来看一个例子吧。
class Demo{ private static int a = 10; }- 1
- 2
- 3
阶段1-加载:JVM加载Demo.class文件,并在方法区中生成class对象
阶段2.1-验证:检查Demo.class文件安全性,数据格式校验等
阶段2.2-准备:找到静态变量a,且a是Int类型,所以给a赋予默认初始值0(整型的默认初始值)
阶段2.3-解析:将字符引用替换为直接引用(可以理解为指针指向)
阶段3-初始化:找到静态变量a,执行赋值表达式,将10赋予给a类加载器
- 启动类加载器
- 扩展类加载器
- 应用类加载器
- 用户自定义类加载器
1. 启动类加载器(Bootstart ClassLoader)
它用来加载java的核心类,使用原生代码编写(C or C++),负责加载jre/lib/rt.jar里所有的class文件。
没有父类加载器2. 扩展类加载器(Extension ClassLoader)
扩展类加载器是指Sun公司(后被Oracle收购)实现的sun.misc.Laucher$ExtClassLoader类,由java语言实现。它负责加载jre/lib/ext目录下的所有jar包
父类加载器为null3. 应用类加载器(Application ClassLoader)
也称为系统类加载器(System ClassLoader),它负责加载-classpath路径下的jar包和类文件(一般是用户的java工程)。应用类加载器继承自扩展类加载器,一般无指定自定义类加载器的话,默认使用的是应用类加载器完成。
父类加载器为Extension ClassLoader4. 自定义类加载器(Custom ClassLoader)
用户自己编写的类加载器,需要继承ClassLoader。
父类加载器为Application ClassLoader双亲委派机制
类加载依靠双亲委派机制(Parents Delegate):当一个类要被加载时,类加载器不会马上进行加载。如果当前类加载器有父类,会让父类进行加载,直到最顶层的Bootstart ClassLoader。当父类无法加载时,才会让子类进行加载。
(也可以理解为:父母做不了的事情,你自己处理)双亲委派机制有安全因素的考虑,可以保证java核心api中定义类型不会被替换。假设通过网络传递一个名为java.lang.Integer的类,通过双亲委派传输到启动类加载器,而启动类加载器发现这个类已经加载过了,并不会加载网络传输过来的java.lang.Integer,直接返回已经加载过的Integer.class
-
相关阅读:
分页处理 - 若依cloud -【 129 】
NET8 BlazorAuto渲染模式
Letter shell移植到AT32WB415
Codeforces Round #835 (Div. 4) D. Challenging Valleys
海思3559万能平台搭建:串口编程
杭电oj 2046 骨牌铺方格 C语言
一步步实现知乎热榜采集:Scala与Sttp库的应用
Python少儿编程小课堂(一)入门篇
Spring Security 在登录时如何添加图形验证码
Docker网络说明
- 原文地址:https://blog.csdn.net/weixin_31257709/article/details/127861719