-
异常检测:Towards Total Recall in Industrial Anomaly Detection
Towards Total Recall in Industrial Anomaly Detection
本篇文章采取的方法是基于密度的异常检测方法
原论文链接,2021的一篇异常检测论文在MVTec其检测准确率和分割准确率分别达到了99.1%和98.1%
研究背景:
能够发现工业制造中零部件存在的缺陷是提高工业制造质量的一个很重要的环节。在使用神经网络的模型中,尽管为每个类别手动设置解决方案是可能的,但系统的最终目标是构建一个系统能同时自动在许多不同类别任务上效果良好。
目前最好的方法是将ImageNet模型的嵌入向量和异常检测模型相结合。这篇论文就是沿着目前这条研究线,在这个基础上提出:PatchCore,which uses a maximally representative memory bank of nominal patch features.
本文亮点:
所提出的PatchCore,在MVTec数据集上能够实现不仅检测速度快,还可以实现缺陷的高精确度检测与定位!

论文核心知识点
Patch: 所谓补丁,指的是像素;
PatchCore: 也就是补丁的核心信息;
Embedding: 所谓嵌入,指的是将网络提取的不同特征组合到一块;
Nominal samples: 正常样本即不包含异常的样本;
Memory bank: 就是记忆提取到的特征的集合;Pretrained Encoder: 使用预训练模型(wide_resnet50_2) backbone 提取图像特征, 采用[2, 3]层特征作为图像特征,具有较强的底层特征(轮廓、边缘、颜色、纹理和形状特征),更能够反映图像内容。不采用最后几层原因:深层特征偏向于分类任务,具有更强的语义信息。
Locally aware patch features: 提取图像的 Patch特征,这个特征带有周围数据的信息。特征值的集合构建 PatchCore Memory bank;
Coreset Subsampling: 核心集二次抽样;
Coreset-reduced patch-feature memory bank:: 稀疏采样 目的是Reduce memory bank,加快算法运行速度。
anomaly score: 就是你训练正常的数据,捕获正常图像的特征,然后有一个异常的数据进来,就会和正常数据产生一个差异,通过整个差异来判断是否是异常。模型框架
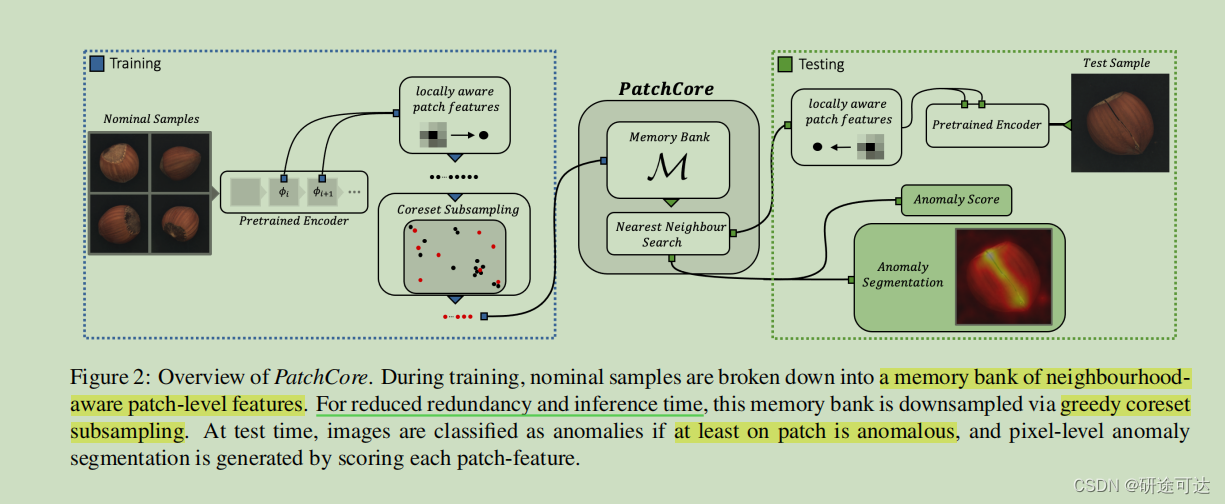
算法流程大致为:通过预训练好的ResNet-50在正常样本上面进行特征提取(不从Resnet最后一层获取特征,而是从中间获取)随后再采用 coreset subsampling,进行有效的降采样生成更加核心的特征集即memory bank 。
在测试的时候,将提取到的特征通过 nearest neighbour search(最近邻搜索:每个query进来,首先找最近距离最近的领域质心,找到距离query最近的质心后,锁定该领域) 然后在该领域内计算距离最远的数据点,用该距离计算anomaly score,判断是否异常,得到结果。 -
相关阅读:
我决定把一个收费视频课全免费公开了,今天起,慢慢放出“人人都需要的产品思维课”...
深入学习Semantic Kernel:创建和配置prompts functions
springboot 集成 zookeeper 问题记录
第五十二天 数论
Mybatis的多表操作之多对多查询与练习
开源微信小程序商城源码PHP带后台管理——构建高效电商平台的基石
redis场用命令及其Java操作
嵌入式实时操作系统的设计与开发(调度策略学习)
Java线程stop,sleep,yield,join
使用.Net对图片进行裁剪、缩放、与加水印
- 原文地址:https://blog.csdn.net/qq_45496282/article/details/127849054