-
Rust权威指南之认识所有权
一. 什么事所有权
所有权是Rust中最独特的功能,正是所有权概念和相关工具的引入,Rust才能够在没有垃圾回收机制的前提下保证内存安全。
一般来讲,所有程序都需要管理自己在运行时使用的计算机内存空间,常见的有下面几种方式:
- 使用垃圾回收机制会在运行时定期检查并回收那些没有被继续使用的内存
- 程序员手动的分配和释放内存
Rust没有使用上面两种方式,它使用包含特定规则的所有权系统来管理内存,这套规则允许编译器的编译过程中执行检查工作,而不会产生任何运行时开销。
1.1. 所有权规则
先具体看一下所有权规则:
- Rust中每一个值都有一个对应的变量作为它的拥有者;
- 在同一时间内,值有且只有一个所有者;
- 当所有者离开自己的作用域时,它持有的值就会被释放掉;
后面我们通过示例来解释
1.2. 变量作用域
变量作用域,简单来说就是一个对象在程序中有效的范围。例如:
{ // @1 let s = "hello world"; // @2 } // @3- 1
- 2
- 3
这里从@1开始,由于s变量没有被初始化此时还不能用,到@2时变量s被指向了一个字符串字面量,最后@3离开大括号此时说明作用域到这里结束,变量s就变得不可用了。简单来说:变量s指向了一个字符串字面量,它的值被硬编码到了当前程序中。变量次申明的位置开始直到当前作用域结束都是有效的。
这里Rust的变量有效性和作用域和Java/C等语言类似。
1.3. String类型
之前的类型都是存储在栈上的,并在离开自己的作用域时将数据弹出栈空间。下面我们以
String为例,了解一个存储在堆上的数据Rust如何自动回收这些数据。String类型会在堆上分配自己所需要的存储空间,所以可以支持可变、可增长的文本。
{ let s = String::from("hello world"); // 通过from创建String实例 }- 1
- 2
- 3
从上面的定义,此时就意味着:
- 使用内存是由操作系统在运行时动态分配的,此时调用
from函数,函数自己就可以申请自己需要的内存空间 - 当使用完
String时,需要通过某种方式来将这些内存归还给操作系统;此处Rust提供了当s变量离开作用域时会调用一个名为drop的特殊函数,进行内存释放(Rust在离开作用域的时候会自动调用drop函数)。
1.3.1. 变量和数据交互的方式:移动
接着我们在看一个例子:
let s1 = String::from("hello"); // @1 let s2 = s1; // @2- 1
- 2
先了解下
@1这个行表达式做什么什么事:申请堆内存存放“hello”,在栈中创建一个s1变量(s1变量是包含:指向堆中地址的指针、当前字符串长度和String类型当前的容量),结构如下图: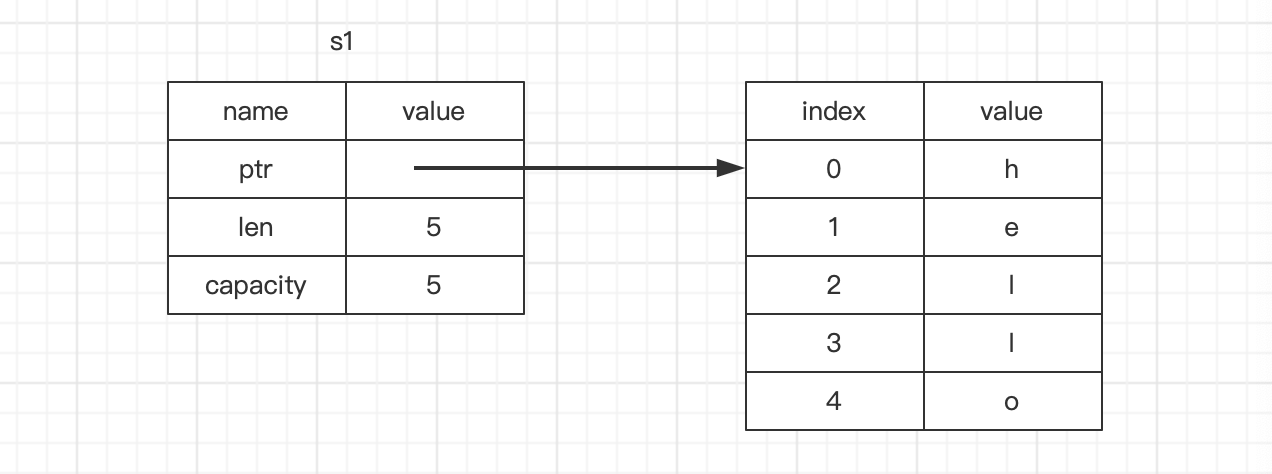
当我们使用
@2表达式s1赋值给s2时,便复制了一次String的数据,这意味着我们复制了它存储在栈上的指针、长度和容量。但是此时并没有复制指针指向的堆数据。此时内存结果如下: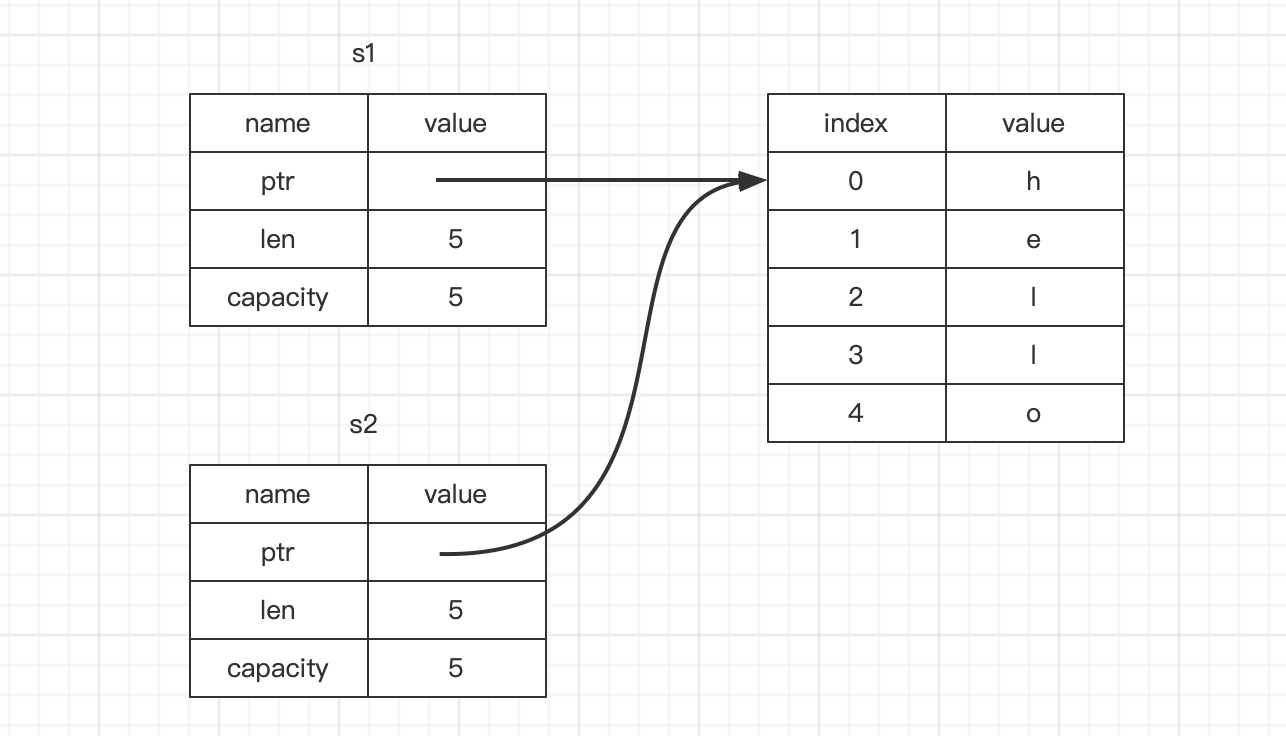
此时当离开作用域的时候,此时
s1和s2都是指向同一个地址,此时会导致一个问题就是s1和s2离开作用域会尝试使用drop函数释放相同的内存(二次释放)。重复释放内存会导致某些正在使用的数据发生损坏,进而产生潜在的安全问题。Rust为了保证内存安全,同时避免复制分配内存,Rust会在此场景简单的将s1废弃,不再视为有效的变量。如下例子:fn main() { let s1 = String::from("hello world"); let s2 = s1; println!("{}", s1); // ERROR }- 1
- 2
- 3
- 4
- 5
此时编译器会报如下错误:
error[E0382]: borrow of moved value: `s1` --> src/main.rs:5:20 | 3 | let s1 = String::from("hello world"); | -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait 4 | let s2 = s1; | -- value moved here 5 | println!("{}", s1); | ^^ value borrowed here after move | = note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.3.2. 变量和数据交互的方式:克隆
当你确实需要去深度拷贝
String堆上的数据,可以使用clone函数。fn main() { let s1 = String::from("hello world"); let s2 = s1.clone(); println!("{}, {}", s1, s2); // hello world, hello world }- 1
- 2
- 3
- 4
- 5
接着我们在看一个有趣的现象:
fn main() { let s1 = 5; let s2 = s1; println!("{}, {}", s1, s2); // 5, 5 }- 1
- 2
- 3
- 4
- 5
此时
s1和s2都是可用的(代码没有调用clone,x在赋值给y后依然可以有效,且没有发生移动现象),为什么呢?这时因为类似于整型的类型可以在编译时确定自己的大小,并且能够将自己的数据完整的存储在栈中,对于这些值的复制操作永远都非常快速的。
在Rust中提供了一个
Copy的接口,一旦某种类型拥有Copy的实现,那么它的变量就可以在赋值给其他变量之后保持可用性。注意:如果一种类型本身或者这种类的任意成员变量实现了Drop接口,那么Rust是不允许其实现Copy,这会导致编译时错误。
此时你一定会疑问,究竟哪些类型时
Copy的呢?一般来说,任何简单标量的组合类型都可以是Copy的;任何需要分配内存或者某种资源的类型都不会是Copy的。下面列举一些拥有Copy的类型:- 所有整数类型,诸如:
u32 - 仅拥有两种值的布尔类型:
bool - 字符串类型:
char - 所有浮点类型,诸如:
f64 - 如果元组包含的所有字段的类型都是
Copy的,那么这个元组也是Copy。例如,(i32, i32)是Copy的,但是(i32, String)则不是。
1.4. 所有权和函数
将值传递给函数在语义上类似于对变量进行赋值。将变量传递给函数将会触发移动和复制。例子:
fn takes_ownership(some_string: String) { // some_string进入作用域 println!("{}", some_string); } // some_string 在这里离开了作用域,drop函数被自动调用,some_string所占用的内存也随之被释放 fn makes_copy(some_integer: i32) { // some_integer进入作用域 println!("{}", some_integer); } // some_integer在这里离开作用域,没有什么特别的事情发生 fn main() { let s = String::from("hello"); // 变量s进入作用域 takes_ownership(s); // s的值被移动进入函数 // println!("{}", s); // ERROR 在此处不再有效 let x = 5; // 变量x开始进入作用域 makes_copy(x); // 变量x同样被传递进入了函数 println!("{}", x); // OK 但由于x的值是Copy的,所以在这儿依然可以使用过x }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
1.5. 返回值与作用域
函数在返回值的过程中也会发生所有权的转移。先看一个例子:
fn main() { let s1 = gives_ownership(); // gives_ownership将它返回值移动至s1中 let s2 = String::from("hello"); // s2进入作用域 let s3 = takes_and_gives_back(s2); // s2被移动到函数, take_and_gives_back函数将返回值移动到了s3上 println!("s1:{} s2:{} s3:{}", s1, s2, s3); // ERROR 此时是报错的 } fn gives_ownership() -> String { // 该函数会将它的返回值移动到调用它的函数中 let some_string = String::from("hello"); // some_string 进入作用域 some_string // 作为返回值移动至调用函数 } fn takes_and_gives_back(a: String) -> String { // 该函数将取得一个String的所有权并将它作为结果返回 a }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
变量所有权的转移总是遵循相同的模式:将一个值赋值给另一个变量时会就发生转移所有权。当一个持有堆数据的变量离开作用域的是你,它的数据会被drop清理回收,处理这些数据的所有权移动到另一个变量上。
上面的这种写法太笨拙,下面我们看看Rust针对这类场景提供了一个名为引用的功能。
二. 引用和借用
在上面的例子中,我们将变量传递给函数会导致变量所有权转移到函数内部,而我们又希望在调用完毕后继续使用该
String,导致我们还的返回来。针对这个问题,我们先看一个例子:fn main() { let s1 = String::from("hello"); // @0 let s2 = calculate_length(&s1); // @1 println!("s1:{} s2:{}", s1, s2); // s1:hello s2:5 } fn calculate_length(s: &String) -> usize { s.len() }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
编译执行发现可以通过,变量
s1还可以使用。此时我们可以注意到@1的的&s1参数,此时&表示引用语义,它们允许在不获取所有权的前提下使用值。接着我们看一个&s1的内存结构: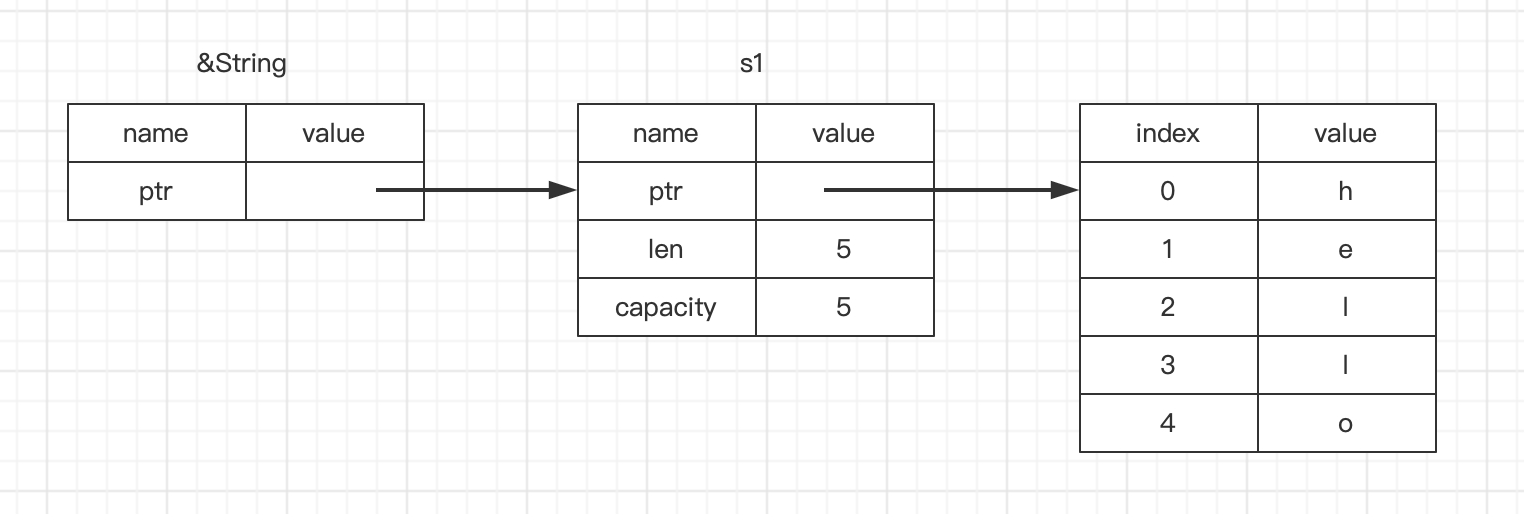
与使用&进行引用相反的操作被称为解引用,它使用*作为运算符。
对于上面例子
@0和@1两行代码,&s1语法允许我们在不转移所有权的前提下,创建一个指向s1值的引用。由于引用不持有值的所有权,所有当引用离开当前作用域,它指向的值不会发生丢弃。接着我们看一下函数
calculate_length,它的参数s的作用域虽然和其他任何函数参数一样,但是因为其是引用,不拥有所有权;这种通过引用传递参数给函数的方法也被称为借用。2.1. 可变引用
如果我们想改变引用的数据怎么办呢?那就的将引用变成可变的:
fn main() { // 将变量s1声明为mut let mut s1 = String::from("hello"); // 传参数修改为&mut s1 calculate_length(&mut s1); println!("s1 => {}", s1); } // 函数参数类型修改&mut String fn calculate_length(s: &mut String) { s.push_str(", world"); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这里需要注意可变引用在使用中有很大的限制:对于特定作用域中特定数据来说,一次只能申明一个可变引用。例子:
fn main() { let mut s1 = String::from("hello"); let r1 = &mut s1; let r2 = &mut s1; println!("{} {}", r1, r2); }- 1
- 2
- 3
- 4
- 5
- 6
此时编译会报错:
Compiling rust-example v0.1.0 (/TestProject/rust-example) error[E0499]: cannot borrow `s1` as mutable more than once at a time --> src/main.rs:4:14 | 3 | let r1 = &mut s1; | ------- first mutable borrow occurs here 4 | let r2 = &mut s1; | ^^^^^^^ second mutable borrow occurs here 5 | println!("{} {}", r1, r2); | -- first borrow later used here- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
另一方面,在Rust中遵循这条限制可以帮助我们避免数据竞争。
数据竞争和竞态条件十分类似,它会在满足下面3中情况下发生:两个或两个以上的指针同时访问同一个空间;其中至少有一个指针会向空间中写入数据;没有同步数据访问的机制。
最后我们再看一个例子:
fn main() { let mut s1 = String::from("hello"); let r1 = &s1; let r2 = &s1; let r3 = &mut s1; println!("{}, {}, {}", r1, r2, r3); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
此时编译执行会报错,这时因为Rust不允许我们在用户不可变引用的同时创建可变引用。
error[E0502]: cannot borrow `s1` as mutable because it is also borrowed as immutable --> src/main.rs:5:14 | 3 | let r1 = &s1; | --- immutable borrow occurs here 4 | let r2 = &s1; 5 | let r3 = &mut s1; | ^^^^^^^ mutable borrow occurs here 6 | println!("{}, {}, {}", r1, r2, r3); | -- immutable borrow later used here- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.2. 悬垂引用
在拥有指针概念的语言会非常容易错误的创建出悬垂指针(这类指针指向曾经存在的某处内存地址,但是该内存已经被释放掉甚至是被重新分配另作他用了)。
在Rust中,编译器会确保引用永远不会进入这种悬垂状态,例如我们当前持有某一个数据的引用,那么编译器可以保证这个数据不会在引用被销毁前离开自己的作用域。看一个例子:
fn no_dangle() -> &String { let s = String::from("hello"); &s }- 1
- 2
- 3
- 4
这个例子的问题我们应该可以很容易看错来,在函数中创建变量s,在函数执行完成之后随之释放,但是我们却将其引用返回,那显然是不对的,编译器也会报错:
error[E0106]: missing lifetime specifier --> src/main.rs:9:19 | 9 | fn no_dangle() -> &String { | ^ expected named lifetime parameter | = help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.3. 总结
下面我们总结下关于引用的知识点:
- 在任何一段给定的时间里,你要么只能拥有一个可变引用,要么只能拥有任意数量的不可变引用;
- 引用总是有效的;
三. 切片
除了引用,Rust还有另一种不持有所有权的数据类型:切片。切片允许我们引用集合中某一段连续的元素序列,而不是整个集合。
3.1. 字符串切片
字符串切片是指向String对象中某个连续部分的引用,下面看一下他们的使用方法:
fn main() { let s1 = String::from("hello world"); let hello = &s1[0..5]; let world = &s1[6..11]; println!("{}, {}, {}", s1, hello, world); // hello world, hello, world }- 1
- 2
- 3
- 4
- 5
- 6
这里
&s1[0..5]的语法,是用来指定切片的范围区间:[starting_index..ending_index],其中starting_index是切片起始位置的索引值,ending_index是切片终止位置的下一个位置的索引值。切片数据结构在内部存储了指向起始位置的引用和一个描述切片长度的字段,这个描述切片长度的字段等价于ending_index - starting_index。下图为world变量的内存结构图: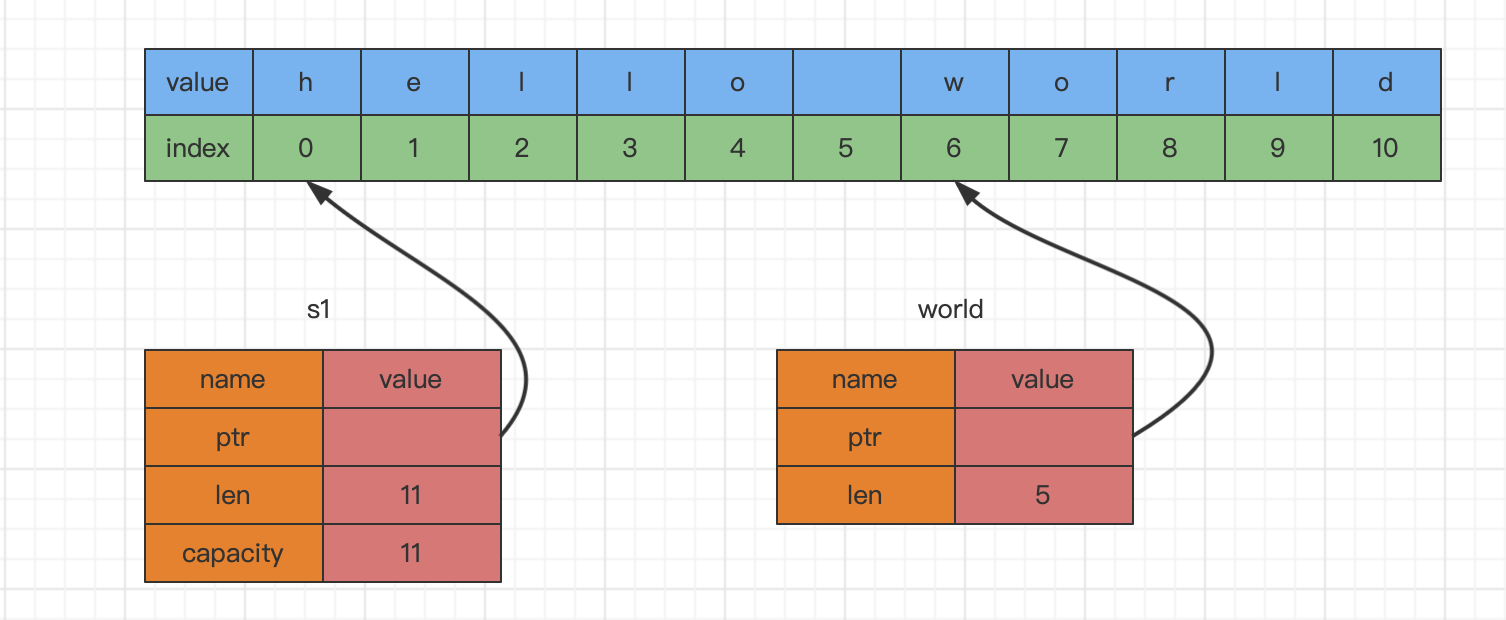
在rust中为切片还有一些其他的写法,下面我们看一下:
let s1 = String::from("hello world"); let q1 = &s1[0..5]; // "hello" let q2 = &s1[..5]; // "hello" let q3 = &s1[6..11]; // "world" let q4 = &s1[6..]; // "world" let q5 = &s1[..]; // "hello world"- 1
- 2
- 3
- 4
- 5
- 6
字符串切片的边界必须位于有效的UTF-8字符串边界内。
这里我们还需要了解,字面量本身就是切片。看例子:
let s1 = String::from("hello world"); let s2 = &s1[..]; let s3 = "hello world"; //s3 和 s2是等价的- 1
- 2
- 3
最后我们看一下字符串切片的函数入参和返回值方面的使用,例子:
fn main() { let s1 = String::from("hello world"); let s2 = &s1[..]; let s3 = "hello world"; let world1 = first_world(s2); let world2 = first_world(s3); println!("{}, {}", world1, world2); // hello, hello } fn first_world(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
3.2. 其他类型切片
字符串切片是专门用于字符串的,但是Rust中还有其他更加通用的切片类型,例如数组:
let a = [1, 2, 3, 4, 5];- 1
如果我们想获取数组的某一部分引用可以这样做:
let slice = &a[1..3];- 1
这里的切片类型是
&[i32],它在内部存储了一个指向起始元素的引用以及长度,这与字符串切片的工作机制是完全一样的。下一篇再见!
-
相关阅读:
Vue3鼠标悬浮个人头像时出现修改头像,点击出现弹框,上传头像使用cropperjs可裁剪预览
全连接神经网络学习MNIST实现手写数字识别
08【保姆级】-GO语言的函数、包、错误处理
Articulate360在线学习课件制作工具
利用浩客无代码开发API集成客服系统,提升用户服务质量
STM32(五):STM32指南者-按键控制灯开关实验
哪个版本的JVM最快?
超融合时序数据库YMatrixDB与PostGIS案例
云打印api搭建,云打印api怎么对接?
Python学习笔记--生成器
- 原文地址:https://blog.csdn.net/yhflyl/article/details/127854346
