-
【毕业设计】电商产品评论数据分析可视化(情感分析) - python 大数据
1 简介
🔥 Hi,大家好,这里是丹成学长的毕设系列文章!
🔥 对毕设有任何疑问都可以问学长哦!
这两年开始,各个学校对毕设的要求越来越高,难度也越来越大… 毕业设计耗费时间,耗费精力,甚至有些题目即使是专业的老师或者硕士生也需要很长时间,所以一旦发现问题,一定要提前准备,避免到后面措手不及,草草了事。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的新项目是
🚩大数据分析:电商产品评论数据情感分析
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
🧿 选题指导, 项目分享:
https://gitee.com/yaa-dc/BJH/blob/master/gg/cc/README.md
2 数据分析目的
针对用户在电商平台上留下的评论数据,对其进行分词、词性标注和去除停用词等文本预处理。基于预处理后的数据进行情感分析,并使用LDA主题模型提取评论关键信息,以了解用户的需求、意见、购买原因及产品的优缺点等,最终提出改善产品的建议。
3 数据预处理
3.1 评论去重
一些电商平台为了避免一些客户长时间不进行评论,往往会设置一道程序,如果用户超过规定的时间仍然没有做出评论,系统就会自动替客户做出评论,这类数据显然没有任何分析价值。由语言的特点可知,在大多数情况下,不同购买者之间的有价值的评论是不会出现完全重复的,如果不同购物者的评论完全重复,那么这些评论一般都是毫无意义的。为了存留更多的有用语料,本节针对完全重复的语料下手,仅删除完全重复部分,以确保保留有用的文本评论信息。
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import re import jieba.posseg as psg import warnings warnings.filterwarnings("ignore") %matplotlib inline path = '/home/kesci/input/emotion_analysi7147' reviews = pd.read_csv(path+'/reviews.csv') print(reviews.shape) reviews.head()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
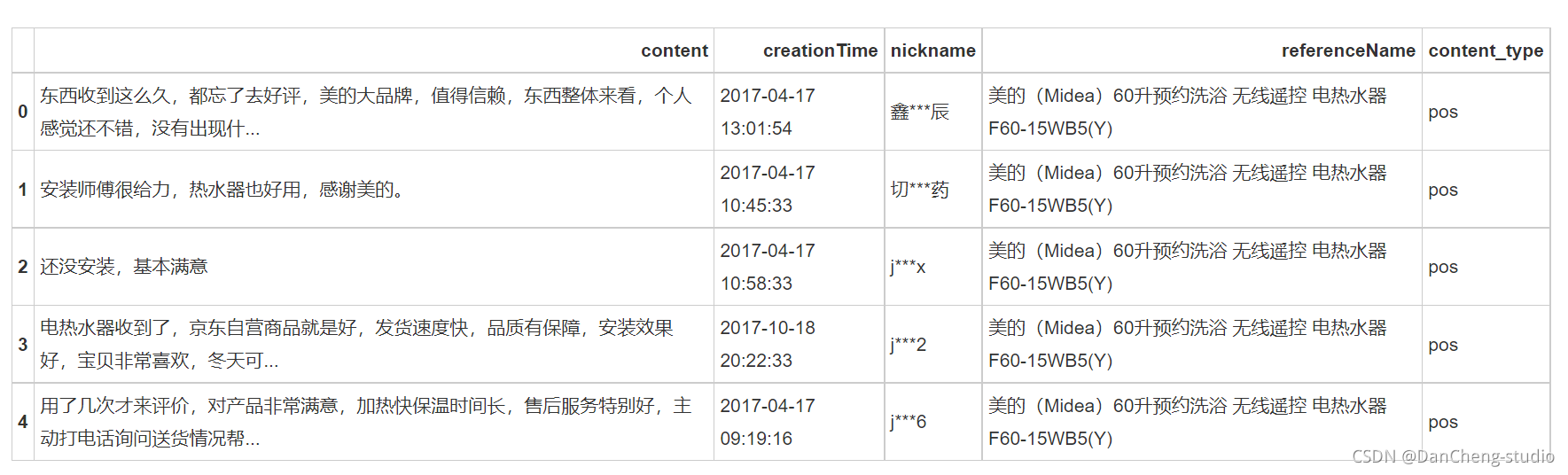
# 删除数据记录中所有列值相同的记录 reviews = reviews[['content','content_type']].drop_duplicates() content = reviews['content']- 1
- 2
- 3
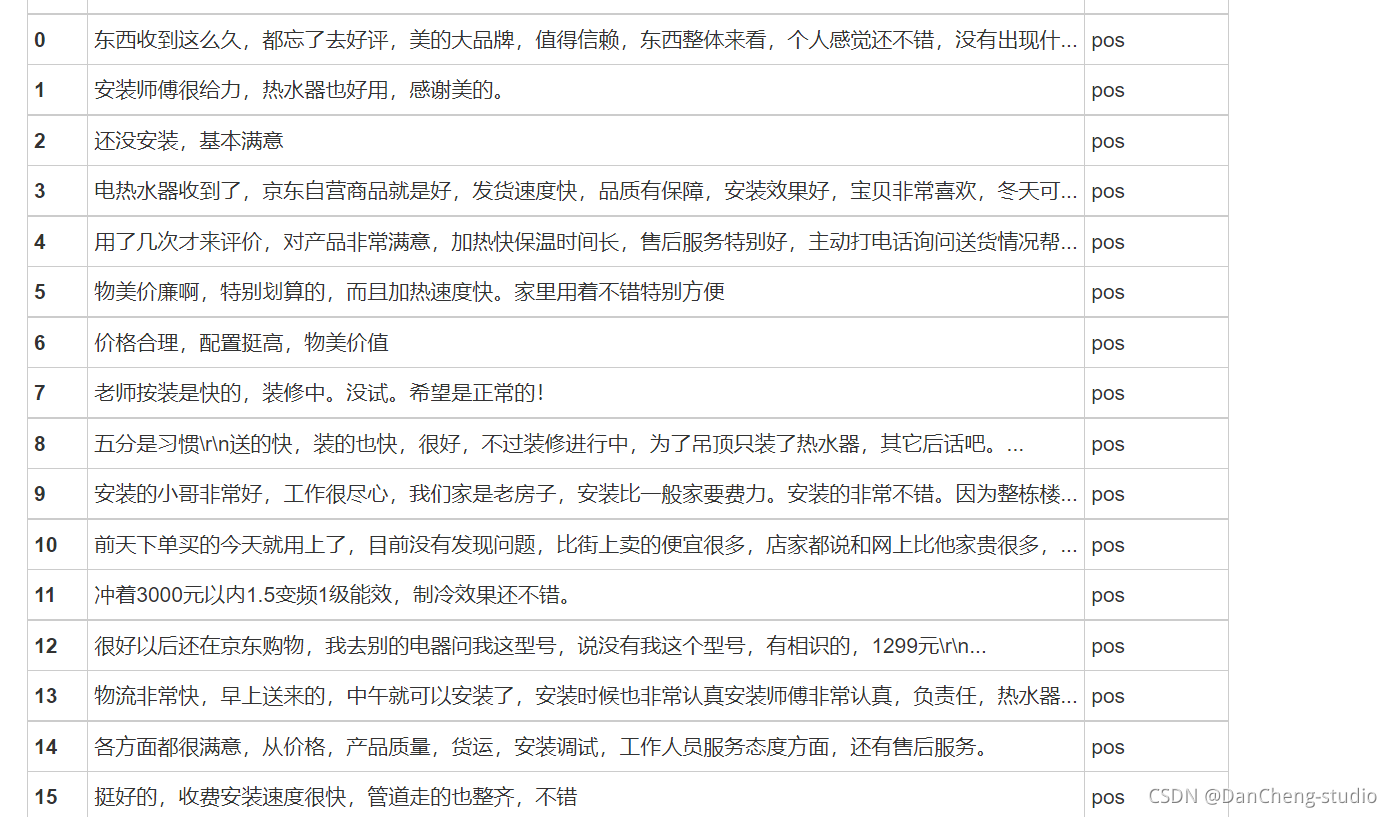
3.2 数据清洗
通过人工观察数据发现,评论中夹杂着许多数字与字母,对于本案例的挖掘目标而言,这类数据本身并没有实质性帮助。另外,由于该评论文本数据主要是围绕京东商城中美的电热水器进行评价的,其中“京东”“京东商城”“美的”“热水器”“电热水器”等词出现的频数很大,但是对分析目标并没有什么作用,因此可以在分词之前将这些词去除,对数据进行清洗
# 去除英文、数字、京东、美的、电热水器等词语 strinfo = re.compile('[0-9a-zA-Z]|京东|美的|电热水器|热水器|') content = content.apply(lambda x: strinfo.sub('',x))- 1
- 2
- 3
3.3 分词、词性标注、去除停用词
词是文本信息处理的基础环节,是将一个单词序列切分成单个单词的过程。准确地分词可以极大地提高计算机对文本信息的识别和理解能力。相反,不准确的分词将会产生大量的噪声,严重干扰计算机的识别理解能力,并对这些信息的后续处理工作产生较大的影响。中文分词的任务就是把中文的序列切分成有意义的词,即添加合适的词串使得所形成的词串反映句子的本意,中文分词的关键问题为切分歧义的消解和未登录词的识别。
未登录词是指词典中没有登录过的人名、地名、机构名、译名及新词语等。当采用匹配的办法来切分词语时,由于词典中没有登录这些词,会引起自动切分词语的困难。
分词最常用的工作包是jieba分词包,jieba分词是Python写成的一个分词开源库,专门用于中文分词,其有3条基本原理,即实现所采用技术。
- 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG)。
- 采用动态规划查找最大概率路径,找出基于词频的最大切分组合。
- 对于未登录词,采用HMM模型,使用了Viterbi算法,将中文词汇按照BEMS 4个状态来标记。
# 分词 worker = lambda s: [(x.word, x.flag) for x in psg.cut(s)] # 自定义简单分词函数 seg_word = content.apply(worker)- 1
- 2
- 3

# 将词语转为数据框形式,一列是词,一列是词语所在的句子ID,最后一列是词语在该句子的位置 n_word = seg_word.apply(lambda x: len(x)) # 每一评论中词的个数 n_content = [[x+1]*y for x,y in zip(list(seg_word.index), list(n_word))] # 将嵌套的列表展开,作为词所在评论的id index_content = sum(n_content, []) seg_word = sum(seg_word, []) # 词 word = [x[0] for x in seg_word] # 词性 nature = [x[1] for x in seg_word] content_type = [[x]*y for x,y in zip(list(reviews['content_type']), list(n_word))] # 评论类型 content_type = sum(content_type, []) result = pd.DataFrame({"index_content":index_content, "word":word, "nature":nature, "content_type":content_type})- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
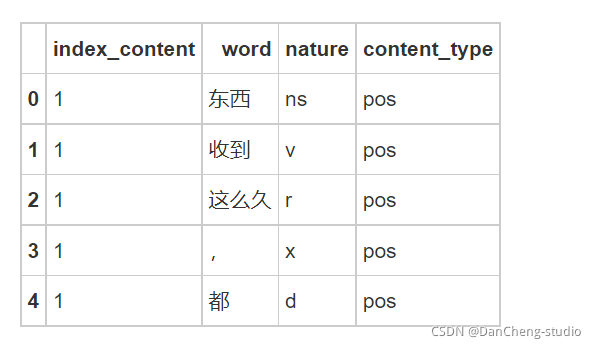
3.4 提取含名词的评论
由于本案例的目标是对产品特征的优缺点进行分析,类似“不错,很好的产品”“很不错,继续支持”等评论虽然表达了对产品的情感倾向,但是实际上无法根据这些评论提取出哪些产品特征是用户满意的。评论中只有出现明确的名词,如机构团体及其他专有名词时,才有意义,因此需要对分词后的词语进行词性标注。之后再根据词性将含有名词类的评论提取出来。
# 提取含有名词类的评论,即词性含有“n”的评论 ind = result[['n' in x for x in result['nature']]]['index_content'].unique() result = result[[x in ind for x in result['index_content']]] result.head()- 1
- 2
- 3
- 4
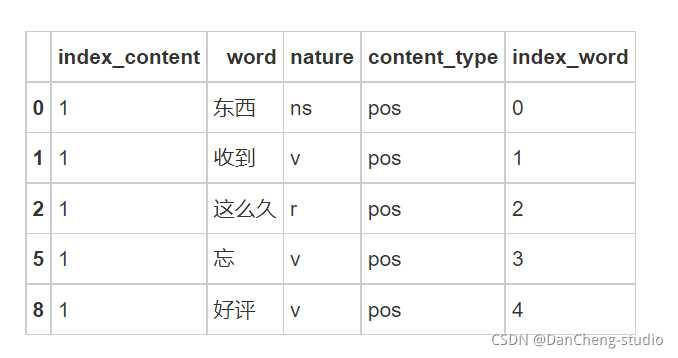
3.5 绘制词云¶
绘制词云查看分词效果,词云会将文本中出现频率较高的“关键词”予以视觉上的突出。首先需要对词语进行词频统计,将词频按照降序排序,选择前100个词,使用wordcloud模块中的WordCloud绘制词云,查看分词效果。

由图可以看出,对评论数据进行预处理后,分词效果较为符合预期。其中“安装”“师傅”“售后”“物流”“服务”等词出现频率较高,因此可以初步判断用户对产品的这几个方面比较重视。4 词典匹配
4.1 评论数据情感倾向分析
匹配情感词情感倾向也称为情感极性。在某商品评论中,可以理解为用户对该商品表达自身观点所持的态度是支持、反对还是中立,即通常所指的正面情感、负面情感、中性情感。由于本案例主要是对产品的优缺点进行分析,因此只要确定用户评论信息中的情感倾向方向分析即可,不需要分析每一评论的情感程度。
对评论情感倾向进行分析首先要对情感词进行匹配,主要采用词典匹配的方法,本案例使用的情感词表是2007年10月22日知网发布的“情感分析用词语集(beta版)”,主要使用“中文正面评价”词表、“中文负面评价”“中文正面情感”“中文负面情感”词表等。将“中文正面评价”“中文正面情感”两个词表合并,并给每个词语赋予初始权重1,作为本案例的正面评论情感词表。将“中文负面评价”“中文负面情感”两个词表合并,并给每个词语赋予初始权重-1,作为本案例的负面评论情感词表。
一般基于词表的情感分析方法,分析的效果往往与情感词表内的词语有较强的相关性,如果情感词表内的词语足够全面,并且词语符合该案例场景下所表达的情感,那么情感分析的效果会更好。针对本案例场景,需要在知网提供的词表基础上进行优化,例如“好评”“超值”“差评”“五分”等词只有在网络购物评论上出现,就可以根据词语的情感倾向添加至对应的情感词表内。将“满意”“好评”“很快”“还好”“还行”“超值”“给力”“支持”“超好”“感谢”“太棒了”“厉害”“挺舒服”“辛苦”“完美”“喜欢”“值得”“省心”等词添加进正面情感词表。将“差评”“贵”“高”“漏水”等词加入负面情感词表。读入正负面评论情感词表,正面词语赋予初始权重1,负面词语赋予初始权重-1。
word = pd.read_csv("./word.csv") # 读入正面、负面情感评价词 pos_comment = pd.read_csv(path+"/正面评价词语(中文).txt", header=None,sep="\n", encoding = 'utf-8', engine='python') neg_comment = pd.read_csv(path+"/负面评价词语(中文).txt", header=None,sep="\n", encoding = 'utf-8', engine='python') pos_emotion = pd.read_csv(path+"/正面情感词语(中文).txt", header=None,sep="\n", encoding = 'utf-8', engine='python') neg_emotion = pd.read_csv(path+"/负面情感词语(中文).txt", header=None,sep="\n", encoding = 'utf-8', engine='python') # 合并情感词与评价词 positive = set(pos_comment.iloc[:,0])|set(pos_emotion.iloc[:,0]) negative = set(neg_comment.iloc[:,0])|set(neg_emotion.iloc[:,0]) # 正负面情感词表中相同的词语 intersection = positive&negative positive = list(positive - intersection) negative = list(negative - intersection) positive = pd.DataFrame({"word":positive, "weight":[1]*len(positive)}) negative = pd.DataFrame({"word":negative, "weight":[-1]*len(negative)}) posneg = positive.append(negative) # 将分词结果与正负面情感词表合并,定位情感词 data_posneg = posneg.merge(word, left_on = 'word', right_on = 'word', how = 'right') data_posneg = data_posneg.sort_values(by = ['index_content','index_word']) data_posneg.head()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
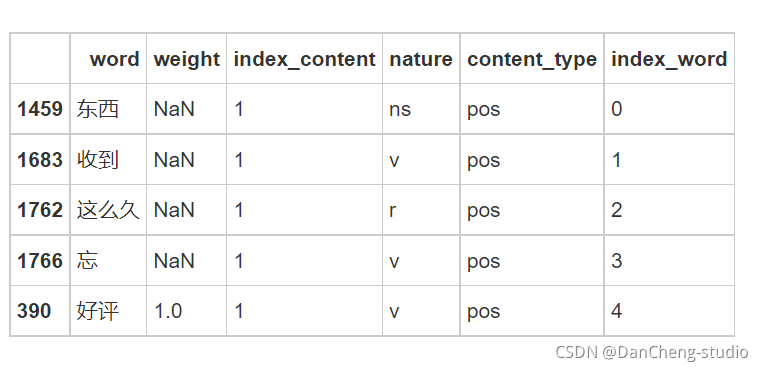
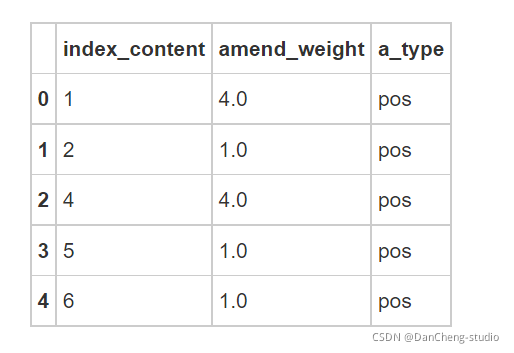
4.2 修正情感倾向
情感倾向修正主要根据情感词前面两个位置的词语是否存在否定词而去判断情感值的正确与否,由于汉语中存在多重否定现象,即当否定词出现奇数次时,表示否定意思;当否定词出现偶数次时,表示肯定意思。按照汉语习惯,搜索每个情感词前两个词语,若出现奇数否定词,则调整为相反的情感极性。
本案例使用的否定词表共有19个否定词,分别为:不、没、无、非、莫、弗、毋、未、否、别、無、休、不是、不能、不可、没有、不用、不要、从没、不太。
读入否定词表,对情感值的方向进行修正。计算每条评论的情感得分,将评论分为正面评论和负面评论,并计算情感分析的准确率。
4.3 LinearSVC模型预测情感¶
将数据集划分为训练集和测试集(8:2),通过TfidfVectorizer将评论文本向量化,在来训练LinearSVC模型,查看模型在训练集上的得分,预测测试集

reviews['content_type'] = reviews['content_type'].map(lambda x:1.0 if x == 'pos' else 0.0) reviews.head()- 1
- 2

# 模型构建 model_tfidf = TFIDF(min_df=5, max_features=5000, ngram_range=(1,3), use_idf=1, smooth_idf=1) # 学习idf vector model_tfidf.fit(train_X) # 把文档转换成 X矩阵(该文档中该特征词出现的频次),行是文档个数,列是特征词的个数 train_vec = model_tfidf.transform(train_X)- 1
- 2
- 3
- 4
- 5
- 6

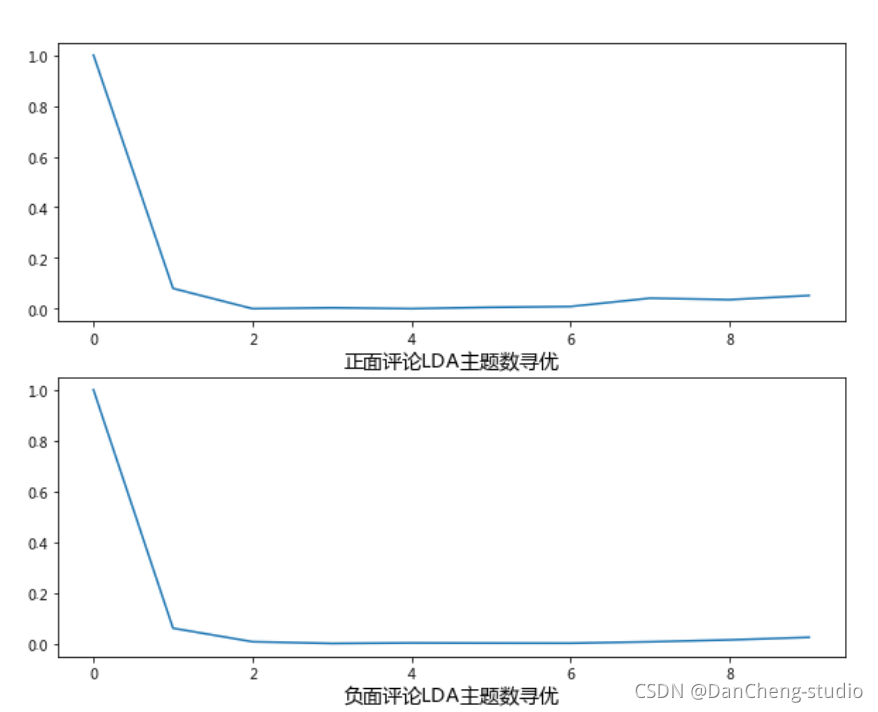
5 最后
-
相关阅读:
backtrader,德国造工业级量化投资框架,支持实盘与机器学习生态
IDEA常用插件
EasyCVR集群部署如何解决项目中的海量视频接入与大并发需求?
mysql_04_01_原理_索引下推
Bash-Snippets – 對重度Linux命令行用戶有用的 BASH 腳本
Linux 驱动PCIE编程接口
【数据库系统概论】实训(四)
Himall商城Web帮助类删除、获取设置指定名称的Cookie特定键的值(2)
55.【Java 线程】
正则判断字符是否包含手机号
- 原文地址:https://blog.csdn.net/caxiou/article/details/127844289
