-
论文分享 | SpeechFormer: 利用语音信号的层次化特性提升Transformer在认知性语音信号处理领域中的性能
本次分享华南理工大学在INTERSPEECH2022会议发表的论文《SpeechFormer: A Hierarchical Efficient Framework Incorporating the Characteristics of Speech》。该论文基于语音层次化发音特性,提出高效的层次化Transformer模型:SpeechFormer。SpeechFormer通过“帧-音素-单词-句子”四阶段建模过程学习语音发音特性,得到的句子表示在语音情感识别和神经性认知障碍检测等认知性语音信号处理任务中取得了出色的表现。
论文作者:陈炜东1 邢晓芬1 徐向民1 庞建新2 杜兰3
(华南理工大学1 优必选研究院2 科大讯飞研究院3)
论文地址:https://www.isca-speech.org/archive/interspeech_2022/chen22_interspeech.html
代码仓库:https://github.com/HappyColor/SpeechFormer
0 Abstract
Transformer在认知性语音信号处理(cognitive speech signal processing,CoSSP)领域,包括在情感分析到神经认知障碍分析等各种应用中,都取得了让人瞩目的成绩。然而,目前大部分工作将语音信号视为一个整体进行处理,忽略了语音信号所特有的、能够反映人类认知过程的发音结构。同时,Transformer中全局注意力(full attention)庞大的计算量再实际应用中带来了很大的计算压力。针对上述问题,本文提出一个层次化的高效Transformer结构来对语音信号进行建模,记作SpeechFormer。SpeechFormer的设计考虑了语音的结构特性,可以作为认知性语音信号处理的通用架构。仿照语音信号的层次化结构,SpeechFormer由frame(帧)、phoneme(音素)、word(字)和utterance(句子)阶段依次组成。每个阶段根据语音的结构特性只在相邻位置间计算注意力,以此提高计算的效率。最后,SpeechFormer在语音情感识别(IEMOCAP & MELD)和神经性认知障碍检测(Pitt & DAIC-WOZ)任务上与Transformer进行比较。实验结果表明,SpeechFormer不仅在性能上优于Transformer,同时还大大降低了计算成本。此外,SpeechFormer在各个数据集上取得了与当前最先进方法不相上下的结果。
1 Introduction
语音信号能够以最简单的形式表达丰富的信息。基于语音信号的情感分析和神经认知障碍分析被统称为认知性语音信号处理(cognitive speech signal processing,CoSSP)并具有很广泛的应用,包括语音情感识别(speech emotion recognition, SER)、抑郁症检测(depression classification)、阿尔兹海默症检测(Alzheimer’s disease detection)等等。由于其广泛的应用价值,CoSSP在语音信号处理中受到越来越多的关注。
在上个世纪,隐马尔科夫模型被提出并对语音信号进行建模。它是一种统计学上的马尔科夫模型,并假定被建模的系统是一个马尔科夫过程。之后,越来越多的机器学习方法,如决策树和受限玻尔兹曼机等,被应用于CoSSP。最近,随着深度学习的发展,卷积神经网络、循环神经网络及其变体被提出并取得了更加优异的性能。
受到注意力机制(attention mechanism)的启发,Transformer在自然语言处理(natural language processing,NLP)领域中被提出并取得了优异的成绩。Transformer在建模序列中的长时依赖方面具有出色的能力。尽管原始的Transformer是被提出来解决NLP领域中的机器翻译问题,研究者们正在积极研究其在其他领域的适应性,特别是在计算机视觉。当然,也有许多研究者尝试将Transformer应用在CoSSP领域。
然而,在CoSSP领域,大多数研究者在使用Transformer时忽略了语音的发音结构等自然特性。然而,语音的发音结构特性可以传达大量的信息。例如,即使测听者听不懂希腊语,他依然可以通过一段希腊语录音中的说话清晰度、延音以及声音的动态变化等特性,来确定该段语音中的情感倾向。同时,由于Transformer中包含计算复杂度为输入序列长度的二次方的全局注意力机制,导致其计算量巨大,难以满足实际需要。
为了解决上述问题,首先,我们要重新回顾语音信号的层次化结构特点。如图1所示,我们可以发现一句话由多个字组成,一个字由多个音素组成(如:字“WANT”由音素“AA1”、“N”和“T”组成),一个音素又由多个语音帧组成(如:音素“AA1”包含了四帧)。

这种渐进式的结构揭示了相邻元素之间交互的重要性,并表明我们可以根据发音的天然特性对语音信号进行分层建模。因此,我们提出了一个层次化的Transformer框架,即SpeechFormer。通过从帧、音素、字和句子四个阶段逐步建模完成对语音信号的完整建模过程。我们先通过前三个阶段捕获帧、音素和字级别的表征,并在每两个阶段之间对学习到的语音表征进行聚合。最后,在句子阶段收集所有的字级表征,并生成一个句子级表征作为分类器的输入,得到分类结果。
2 Methodology
如图2所示,我们提出的SpeechFormer主要由四个阶段和三个聚合模块(Merging Blocks)组成。其中,帧阶段(Frame Stage)、音素阶段(Phoneme Stage)和字阶段(Word Stage)用于学习不同层次的特征,而句子阶段(Utterance Stage)旨在生成一个用于分类的全局表征。三个Merging Blocks通过减少tokens的数量来降低每两个阶段之间的特征冗余。此外,我们用一个额外的分支“Statistical Characteristics of Speech”来提供语音信号的统计性质。

2.1 Vanilla Transformer
图3展示了原始Transformer(本文仅指其编码器部分)的工作原理。Transformer由多头自注意模块(Multi-Head Self-Attention,MSA)和前馈网络(Feed-Forward Network,FFN)两个模块组成。对Transformer的详细介绍可参考原文,此处不再赘述。

2.2 SpeechFormer Framework
Transformer框架忽略了语音中的内部隐含关系,而SpeechFormer利用这些内部隐含关系对语音信号进行分层建模。具体来说,SpeechFormer采用基于语音的多头自注意模块(Speech-based Multi-Head Self-Attention,Speech-MSA)来捕捉相邻元素之间的交互。同时,我们利用聚合模块Merging Blocks来减少特征之间的冗余。上述两个模块都是在语音统计特性的指导下进行的。
2.2.1 Statistical characteristics of speech
Elements of speech signal:音素是语音信号中最小的声音单位,多个音素的组合可以形成一个字。多个字被排列在一起可以形成一个句子,包含句子的语音又被记录在波形文件中。在数据格式方面,数字化的语音信号被划分为许多帧。每一帧都包含该特定时间点的信息。因此,帧是数字系统中最基本的处理单位,然后由多个帧逐渐形成一个音素、一个字,最后形成一个句子。
Time duration:帧长代表窗口持续时间的大小,是可变参数。不同音素时长不同,音素持续时间大约在50ms到200ms不等。为了分析字的持续时间,我们使用P2FA工具提取数据库中每句话中的音素。我们发现,90%以上的字包含少于5个音素。因此,我们将字的持续时间视为在250ms到1000ms之间变化(音素持续时间的5倍)。时间长度除以特征的hop length就是该特征中包含tokens的大致数量。
2.2.2 Speech-MSA in SpeechFormer block
我们将原始Transformer中的MSA模块替换成了Speech-MSA模块以充分利用语音信号的特点。如图4所示,Speech-MSA利用一个窗口Tw将注意力的计算限制在一个小的连续区域内,极大降低计算的负担。
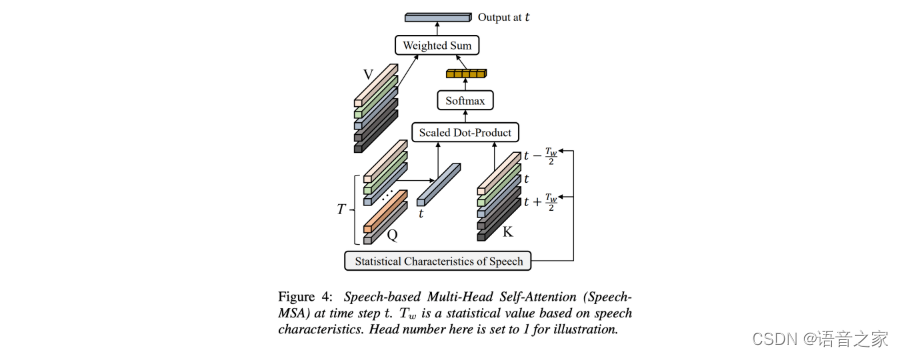
同时,针对不同的阶段,我们设计了不同的窗口大小(Tw),使得SpeechFormer的前三个阶段(Frame Stage、Phoneme Stage、Word Stage)可以分别学习到相邻帧、相邻音素、相邻字之间的交互。最后,在句子阶段(Utterance Stage),Tw的大小设置成输入的长度,用来学习一个全局的表征。每个阶段的窗口大小设置如表格1所示。

最后,Speech-MSA的计算过程可概括为:

2.2.3 Merging block in SpeechFormer framework
每两个阶段之间的聚合模块在语音统计特性的指导下对学习到的表征进行提炼,减少特征之间的冗余。聚合模块的加入使得SpeechFormer具有分层的架构,这更加贴合语音信号的构建过程。每个聚合模块包含一个平均池化层和一个线性层。平均池化层首先将M个连续的tokens聚合成一个,其中M是聚合尺度(merging scale)。线性层将输入tokens的特征维度扩大 r 倍。每一个聚合模块都在为后续的阶段准备合适的输入。具体来说,在Phoneme Stage,每一个token都应该表示一个子音素(sub-phoneme),这样Phoneme Stage就可以对相邻音素之间的交互进行建模。因此,Phoneme Stage之前的聚合模块的聚合尺度M1应该不小于一个音素的最小持续时间。类似的,Word Stage前的聚合模块的聚合尺度M2也应该不小于一个字的最小持续时间。更多的取值细节将展示在表1中。
3 Experiments
3.1
Datasets
语音情感识别任务数据集:IEMOCAP、MELD
阿尔兹海默症检测任务数据集:Pitt
抑郁症检测任务数据集:DAIC-WOZ
3.2
Experimental setup
Acoustic features:本文提取了三种声学特征,分别是spectrogram(Spec)、Log-Mel spectrogram(Logmel)和预训练特征Wav2vec。Spec和Logmel的窗口大小分别设置为20ms和25ms。提取Logmel时使用的Mel频带数量分别为128(IEMOCAP和DAIC-WOZ)和256(MELD和Pitt)。原始hop长度默认设置为10ms。
Hyper-parameters:表2列出了SpeechFormer在不同数据集中训练时的超参数。

我们采用SGD优化器来优化模型。原始Transformer使用的层数是12。对于SpeechFormer,我们使用了两种具有不同参数量的配置,分别为SpeechFormer-S和SpeechFormer-B。它们的超参数分别为:

其中,Ni为第i个阶段中的层数。
3.3
Experimental results and analysis
3.3.1 Comparison to the baseline framework
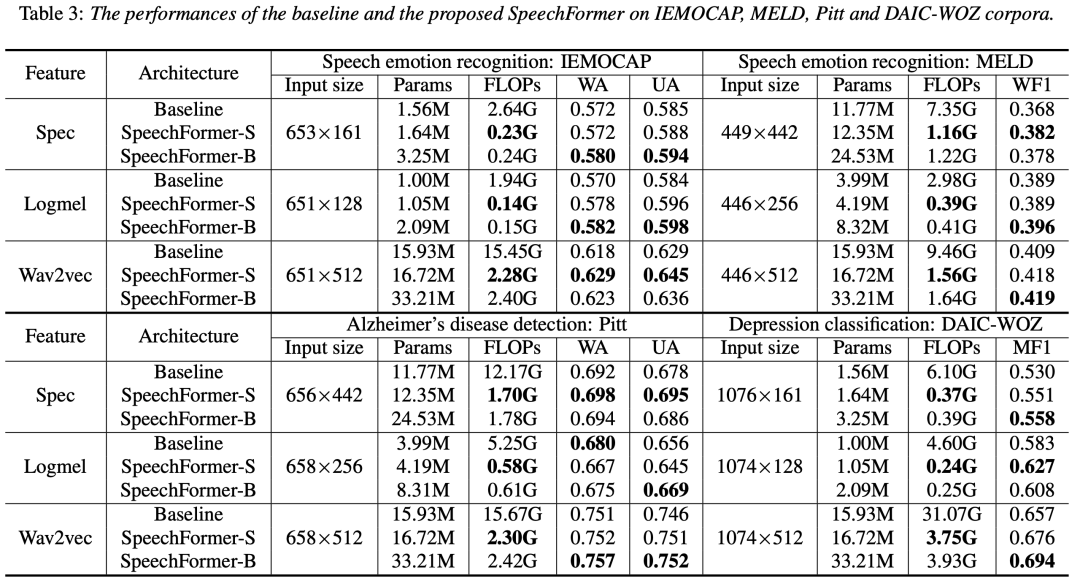
表3展示了SpeechFormer和原始Transformer在IEMOCAP、MELD、Pitt和DAIC-WOZ上的对比结果,包含了语音情感识别、阿尔茨海默症检测和抑郁症检测三个任务。从表3中,我们可以观察到SpeechFormer-S和Transformer的参数量非常接近,其中前者略大于后者。然而,SpeechFormer-S在四个数据库上的计算量(FLOPs)分别约为原始Transformer的10.2%、15.1%、13.2%和7.8%。SpeechFormer-B将SpeechFormer-S的参数量扩大了约2倍,同时保持FLOPs几乎不变。在进行语音情感识别时,无论使用何种特征,原始Transformer的结果都低于SpeechFormer的结果。在进行阿尔茨海默症检测时,Transformer使用Logmel作为输入可以取得更好的WA。而在其他情况下,SpeechFormer都获得了更高的性能。对于抑郁症检测,SpeechFormer在所有情况下都超过了Transforemr。总的来说,我们的SpeechFormer在性能和计算效率方面普遍优于Transformer。
3.3.2 Comparison to previous state-of-the-ar
表4给出了SpeechFormer与一些已知系统在四个数据库上的性能对比。所有系统都只使用语音特征作为输入,以便进行公平的比较。在IEMOCAP上,SpeechFormer-S取得了与当前最好系统相当的性能。在MELD、Pitt和DAIC-WOZ上,SpeechFormer-B的表现均优于其他的对比方法。

4 Conclusion
我们在认知性语音信号处理领域提出了一个高效的层次化Transformer框架,命名为SpeechFormer。SpeechFormer中的Speech-MSA模块和聚合模块通过结合语音信号的特点对语音信号进行分析。在四个数据库上的实验结果也证明了SpeechFormer的优越性。未来工作计划将SpeechFormer扩展到语音识别、说话人识别等更多任务。
-
相关阅读:
家政服务小程序,家政预约小程序,家政服务预约小程序源码
翻译: 如何学习编译器:LLVM Edition
故障安全移动面板KTP900F Mobile下载程序提示无法下载,目标设备正在运行或未处于传输模式的解决办法
CCF CSP认证 历年题目自练Day19
【云原生 · Kubernetes】部署高可用 kube-controller-manager 集群
jQuery 添加元素
CAS:1609659-02-0_TCO-Amine_TCO-NH2-反式环辛烯(TCO)
MyBatis Plus 实现获取自动生成主键值的方法
tomcat的安全配置:
高数笔记03:几何、物理应用
- 原文地址:https://blog.csdn.net/weixin_48827824/article/details/127532343