-
【爬虫】基于matlab实现火车票信息爬虫
✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,matlab项目合作可私信。
🍎个人主页:Matlab科研工作室
🍊个人信条:格物致知。
更多Matlab仿真内容点击👇
⛄ 内容介绍
1.通用爬虫。
2.聚焦爬虫。
通用爬虫:搜索引擎用的爬虫系统。
一.目标:爬取所有网站的网页下载下来,存放到本地服务器里形成备份。
二.抓取流程:
a.首选选取一部分已有的url,把这些url放到待爬取队列。
b.从队列里取出这些URL,然后解析DNS得到主机IP,然后去找个IP对应的服务器里下载HTML页面,保存到搜索引擎的服务器里。
之后把这个爬过的URL放入已爬过的队列。
c.分析这些网页内容,找出网页里其他的url连接,继续执行第二部,直到爬虫任务结束。
三.搜索引擎如何获取一个新网站的URL
1.主动提交
2.在其他网站里设置网站的外链
3.搜索引擎和DNS服务器合作,可以快速收录网站。
四,通用爬虫并不是万物皆可爬,需要遵守规则。
Robots协议:协议会指明通用爬虫可以爬取的网页权限。
Robots.txt 并不是所有爬虫的遵守,一般只有大型的搜索引擎爬虫才会遵守。
⛄ 完整代码
clc;
clear;
warning off;
[data1,str] = xlsread('\需要爬取的车次.xlsx','Sheet1'); %导入表格中需要爬取的车次信息
str=str(:,1);
str=str(2:end); %提取需要查询的车次信息
%% 循环查询各个车次始发站和终点站
for train = 1:size(str,1)
str1='抓取';
str2=strtrim(str{train}); %删除字符串制表符
str3='数据中...';
str4=[str1,str2,str3];
fprintf(str4)
partURL1 = 'http://search.huochepiao.com/chaxun/resultc.asp?txtCheci=';
partURL2 = str2;
partURL3 = '&cc.x=0&cc.y=0';
fullURL=[partURL1,partURL2,partURL3];
[sourcefile, status] = urlread(sprintf(fullURL),'Charset','GBK'); %urlread函数可以读取网页
if ~status %判断数据是否全部读取成功
error('出问题了哦,请检查\n')
end
expr1 = '
(\w*\.?\w*) '; %要提取的模式,()中为要提取的内容[stationfile, station_tokens]= regexp(sourcefile, expr1, 'match', 'tokens'); %match返回整个匹配类型,token返回()标记的位置,都为元胞类型
% 如果能抓取到高铁信息
if ~isempty(station_tokens)
station_tokens=station_tokens(1:2); %只截取始发站和终点站数据
station = cell(size(station_tokens)); %创建一个等大的元胞数组
for idx = 1:length(station_tokens)
station{idx} = station_tokens{idx}{1}; %将始发站和终点站数据写入
end
sheet = 'Sheet1'; %工作表名称
left=['B',num2str(train+1)];
right=['C',num2str(train+1)];
range = sprintf([left,':',right]); %从源文件中获取的目标数据的放置范围
xlswrite('\需要爬取的车次.xlsx', station, sheet, range); %将查询到的车次始发站和终点站信息写入表格中
fprintf('完成!\n')
end
end
fprintf('全部完成!数据保存在站次信息表格中,请注意查看!\n')
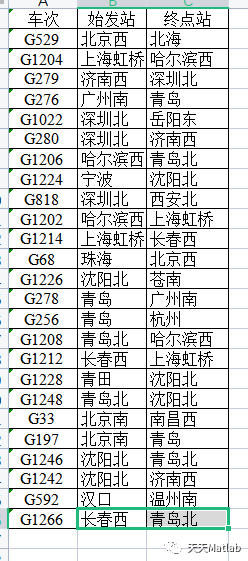
⛄ 运行结果
⛄ 参考文献
[1]王相军. 基于众包协作的分布式爬虫研究[D]. 哈尔滨工业大学.
❤️ 关注我领取海量matlab电子书和数学建模资料
❤️部分理论引用网络文献,若有侵权联系博主删除
-
相关阅读:
环保行业采购协同管理系统:助推环保行业电子采购管理转型升级
解决服务器80端口无法连接的办法
Docker 容器编排技术解析与实践
px4+vio实现无人机室内定位
如何使用Portainer创建Nginx容器并搭建web网站发布至公网可访问【内网穿透】
vue的diff算法
【每日一练】图解:链表内指定区间反转
如何实现蓝牙配对方法混淆攻击
【笑小枫的SpringBoot系列】【十一】SpringBoot接口日志信息统一记录
有财务自由的思维,才能实现财务自由!
- 原文地址:https://blog.csdn.net/matlab_dingdang/article/details/127823450