-
ceph浅谈
总谈
ceph简介
1、ceph中的 Cluster Map 可以设置更高故障域级别(如 Rack, Row等)能保证整机柜或同一排机柜在掉电情况下数据的可用性和完整性
2、CephFS比 NFS更可靠,因为提供了副本冗余,表现形式:把ceph存储挂载到一个目录上
3、对象存储,涉及到nginx,http,S3 API,搭建好RGW服务,使用s3 客户端访问,上传下载Object,还支持GUI,支持代码或者命令行
4、Calamari 可视化,简化Ceph集群管理
5、备好osd, RBD和 cephFS 接口都是由存储池pool定义出来的, 而对象存储通过代码脚本,http


6、Crush rule
下面这些英文词汇就是隔离域
pool是由存储的基本单位pg组成,pg分布在磁盘逻辑单元osd上,osd一般是对应一块物理硬盘,osd分布在物理主机host,host分布在机框chassis中,机框chassis分布在机架rack中,几家rack分布在机柜阵列raw中,后面可以继续归属,->pdupod->room->datacenter 。其中host/chasis/rack 等等在ceph属于中叫做bucket(桶)。可以自定义新的级别bucket,比如新定义一个bucket级别host-SSD ,专门将SSD盘的OSD归入这个bucket中。

可以修改默认 Crush Rule,把隔离域换成 OSDCRUSH使得 Ceph 能自我修复
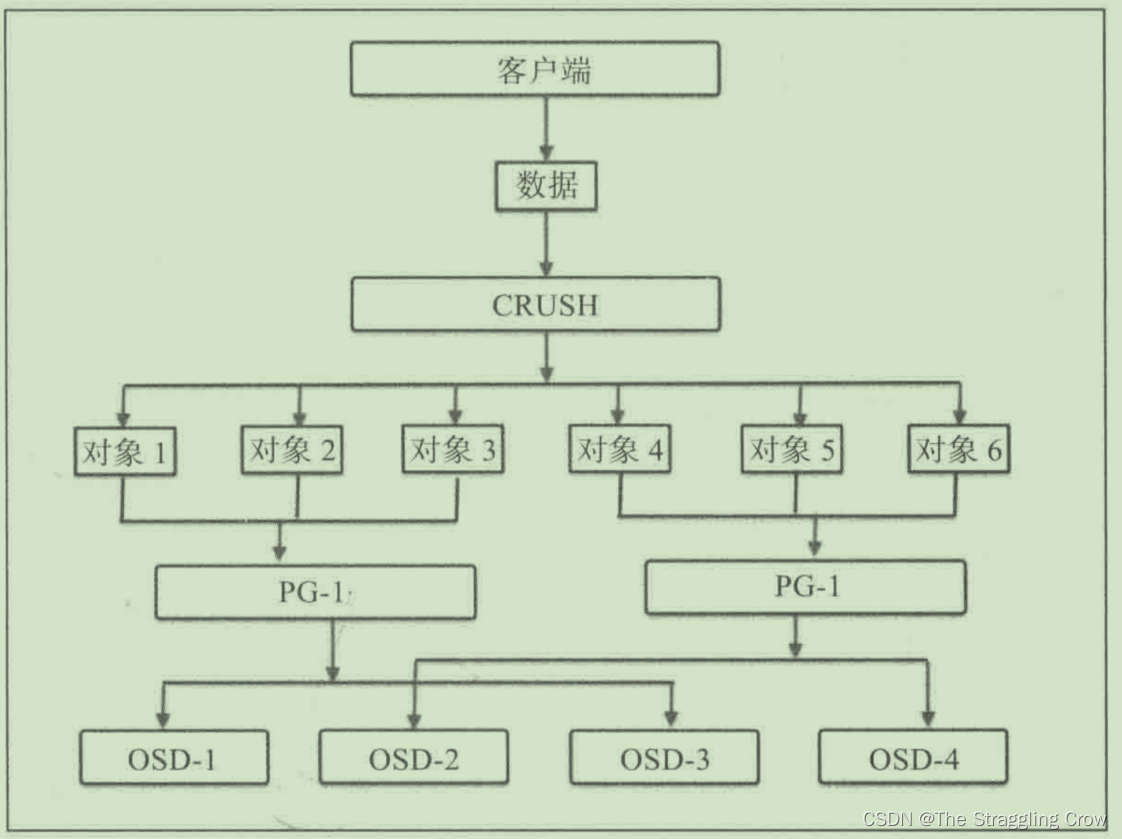
pg_num和pgd_num 要相等才能实现再平衡7、RAID时代终结
4 6TB的大硬盘恢复甚至需要几天,还需要备用盘,而且RAID组中磁盘必须完全相同,还需要RAID卡,RAID卡的扩展有限制。Ceph可以解决所有这些问题
8、纠删码比副本方式更加节省存储空间。
9、ceph获取数据的位置通过动态计算,不是靠查,这样性能提升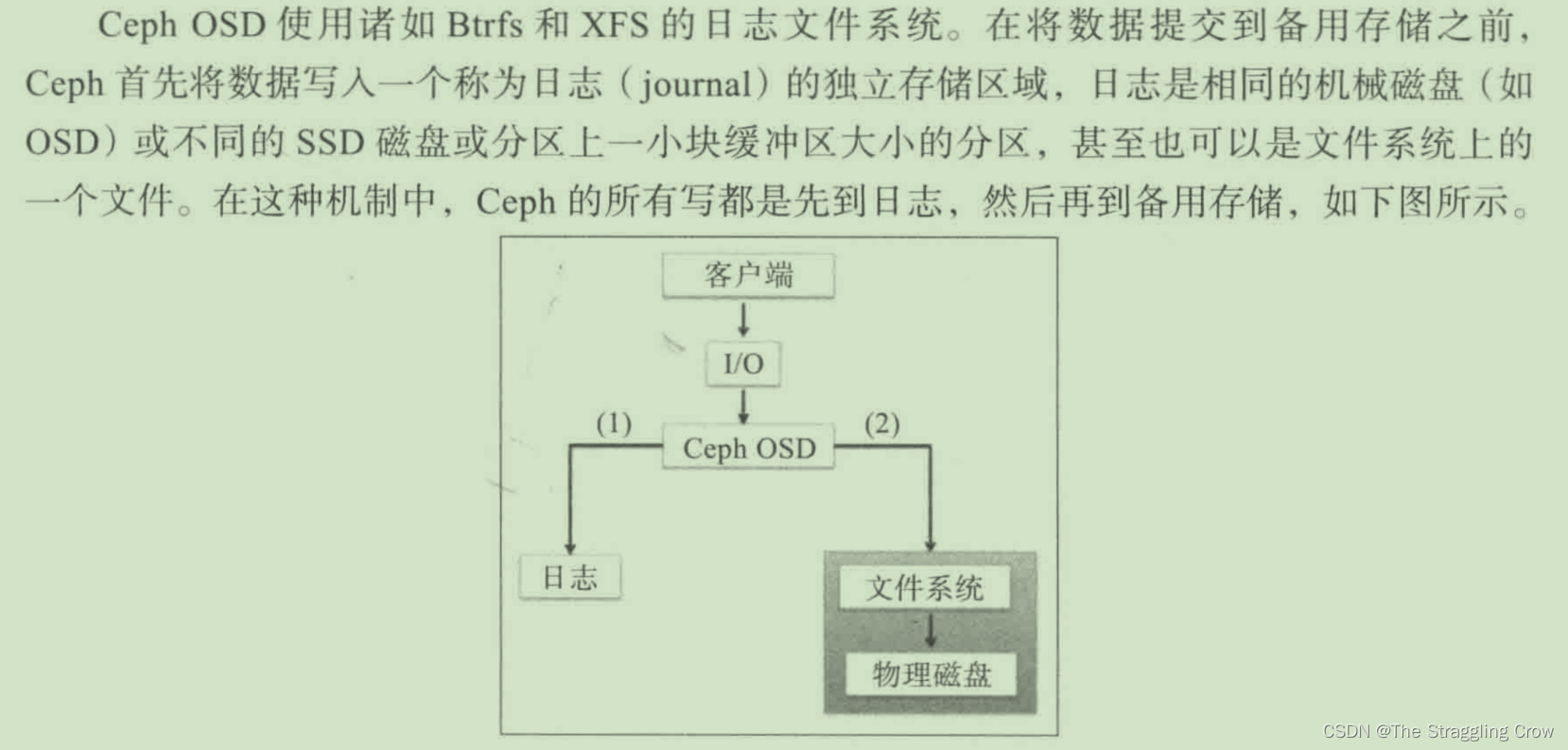



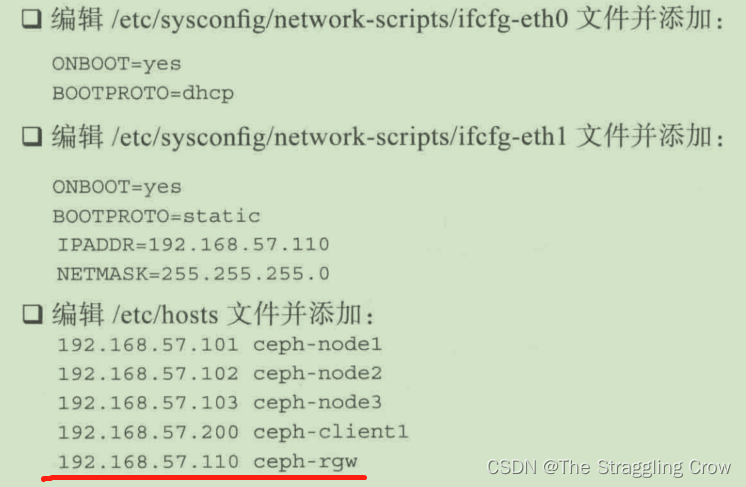
需要集群内部和集群对外的工作网络两组 内外网络,内外网应该是物理隔离的


新的机器 ceph-client1 添加密钥后就能使用集群中rbd,好像在自己的机器上一样基本不会数据丢失,可扩展,用于PB级数据和最少成百台存储设计的
条带化— 条带化是指数据在阵列中所有硬盘中的存储过程,文件中的数据被分割成小块在阵列中的硬盘上顺序存储,这小块就叫条带单元,Ceph 条带化他提供了类似RAID0的吞吐量
用上ceph,多台机器的磁盘空间在一起了,在一台机器上就可以看到使用所有空间。
还可以保存多份安全备份
存储先ceph,自我管理修复,跨机房,节点越多,并行化,论上,节点越多,整个cpeh集群的IOPS和吞吐量就越⾼;然后再装数据库等IOPS(I/Os per second):即每秒输入输出次数。也就是每秒钟接受I/O指令的次数。指的是系统在单位时间内能处理的最大的I/O频度;一般,OLTP应用涉及更多的频繁读写,更多的考虑IOPS;
IOPS测试结果与很多测试参数和存储系统具体配置有关。IOPS还可以细分为100%顺序读(Sequential Read)IOPS、100%顺序写IOPS、100%随机读IOPS、100%随机写IOPS等,在同等情况下这四种IOPS中100%顺序读的IOPS最高。吞吐量是指在一定时间内由一处传输到另一处或被处理的数据量。如同高速路上的单位时间内通过的车辆总数。
带宽是指通讯线路中允许的最大数据传输速度也可以说是最大数据传办理的频率。如同高速公路上允许通过的车的最高车速。
读取10000个1KB文件,用时10秒 ,Throught(吞吐量)=1MB/s,IOPS=1000
读取1个10MB文件,用时0.2秒 ,Throught(吞吐量)=50MB/s,IOPS=5IOPS计算公式
IOPS=1s/【寻道时间+旋转速度+数据传输(忽略)】
固态硬盘SSD是一种电子装置,避免了传统磁盘在寻道和旋转上的时间花费,存储单元寻址开销大大降低,因此IOPS可以非常高,能够达到数万甚至数十万
RAID5 对于任何一次写入,在存储端,需要分别进行两次读+两次写,所以说RAID-5的Write Penalty的值是4
增删改多的OLTP环境,IO性能要求高的选raid10,
读多的OLAP环境,追求空间利用率的选RAID5,Iaas Paas Saas
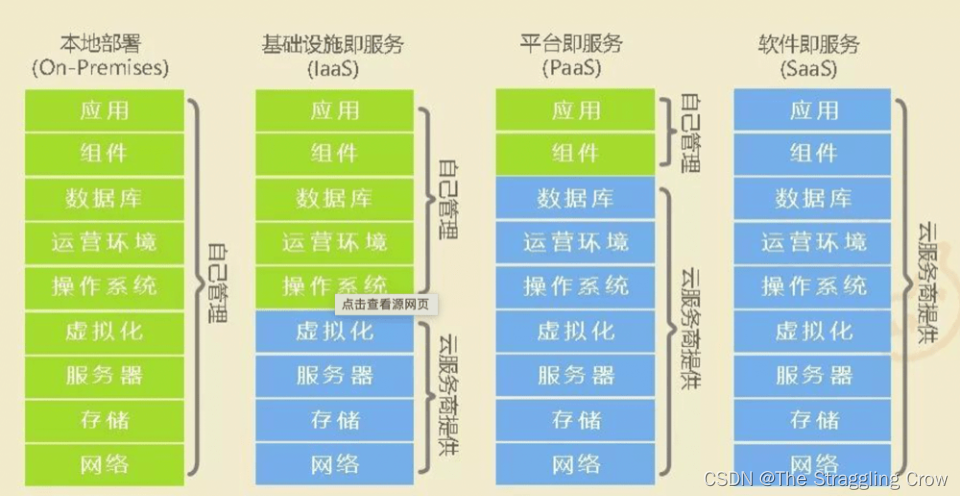
SaaS 是软件的开发、管理、部署都交给第三方,不需要关心技术问题,可以拿来即用。普通用户接触到的互联网服务,几乎都是 SaaSPaaS 提供软件部署平台(runtime),抽象掉了硬件和操作系统细节,可以无缝地扩展(scaling)。开发者只需要关注自己的业务逻辑,不需要关注底层
IaaS 是云服务的最底层,主要提供一些基础资源。它与 PaaS 的区别是,用户需要自己控制底层,实现基础设施的使用逻辑
ceph 应用场景
ceph是⼀种分布式存储系统,可以将多台服务器组成⼀个超⼤集群,把这些机器中的磁盘资源整合到⼀块⼉,形成⼀个⼤的资源池(⽀持PB级别,大厂用得多)
ceph提供
对象存储: 网盘应用业务
块设备存储:IaaS
文件系统服务:还不成熟,不建议生产环境下使用文件存储:是最易于理解的存储类型,有传统的目录结构,抽象文件语义 。
块存储:对外提供块存储语义,挂载在操作系统上就像一个块设备,在云上的产品形态是云硬盘。
对象存储:本质就是是kv存储,无目录结构。
一句话:块存储–裸盘读写。文件存储–文件读写。对象存储–键值对存储
企业中不同场景使用的存储,使用表现形式无非是这三种:磁盘(块存储设备),挂载至目录像本地文件一样使用(文件共享存储),通过API向存储系统中上传PUT和下载GET文件(对象存储)。

测试性能用 RADOS bench
测试的写入,顺序读和随机读 MB/s
ceph
架构

工作流是从上到下
能够横向扩展到数千台机器,通过Crush算法,数据它自己会备份到其他节点上,那么一个挂了还能找回来
也是横向扩展,每台压力越小,性能应该越强
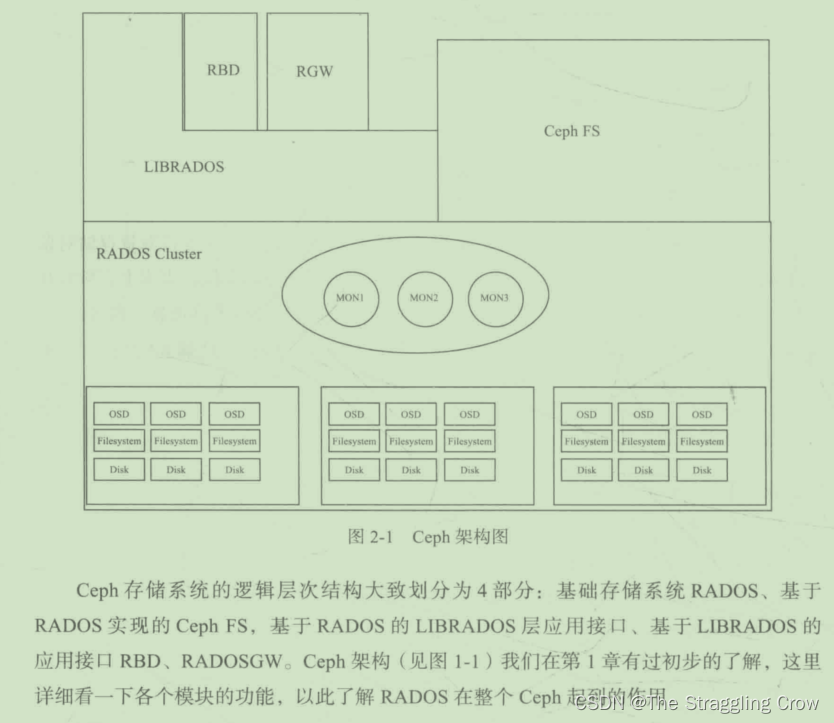
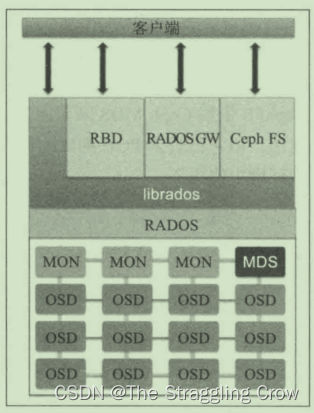
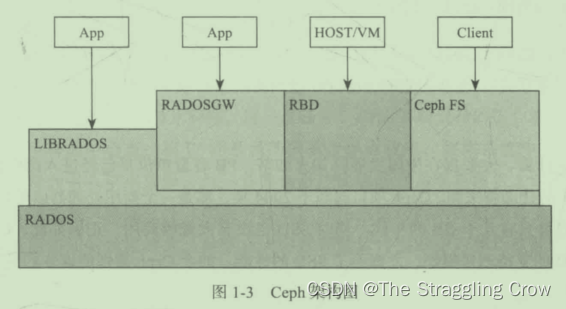
RADOS的灵魂是CRUSH算法
通过librados去操纵RADOS, 上层的RBD、RGW和CephFS都是通过librados访问RADOS的,支持多种语言,不包括go
物理上,LIBRADOS和基于其上开发的应用位于同一台机器,因而也被称为本地API。
RGW app代码直接往这个接口里写数据,以对象的形式,对象是分散地存储,速度最快
RBD从ceph里抽象出一个块,挂到k8s上,我们就可以往这个块里写数据,块是按顺序把数据存储在存储里,对应云主机硬盘
CephFS由于性能差,用得比较少
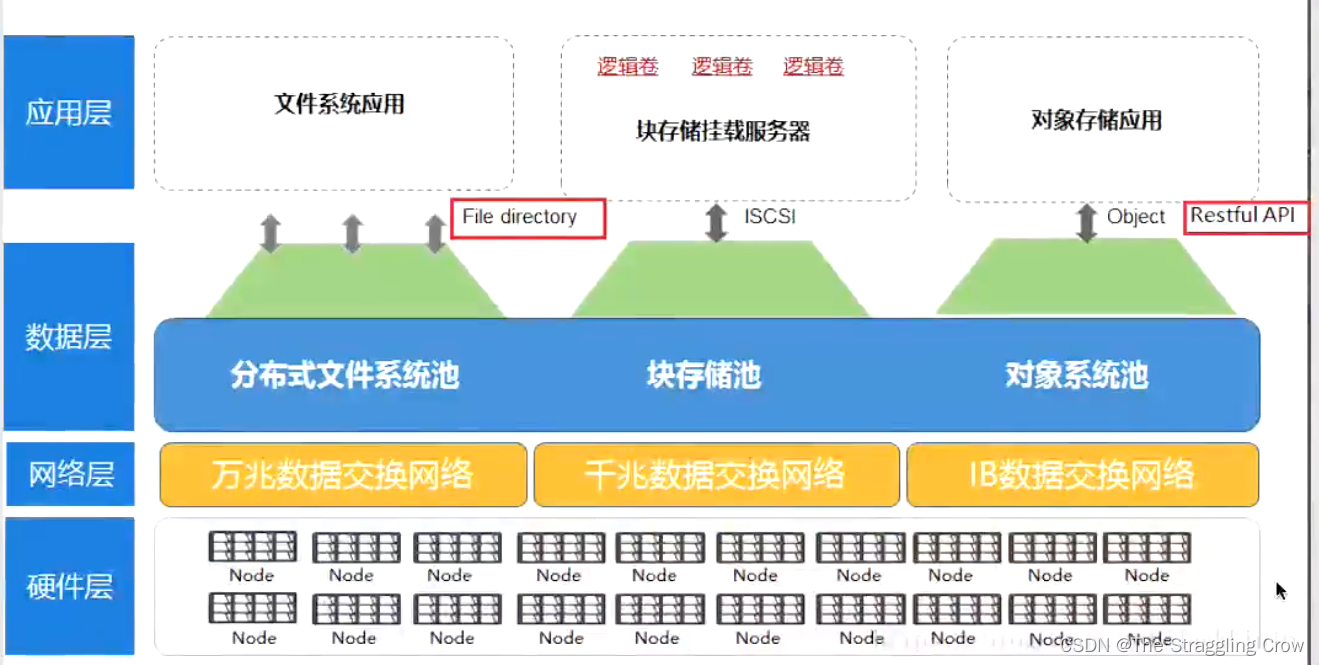
核心概念
元数据是关于数据的数据,它存储的是数据存储在 节点和磁盘阵列的 位置等信息。新数据来,元数据新更新数据会存放的物理位置,然后才是数据存储



存储数据的两种方式:副本和纠删码,我们主要使用副本的方式
纠删码



一个文件分散成10块分布式存放,还有20个块和前面10块一样的,那么一共就是3个副本
pool就是便于ceph管理副本分布用的,三个存储接口(RBD,cephFS,RGW)都有它自己的pool,log也有它自己的pool, 通过pool给区分开,这样就很清楚了


命令行可以创建pool,修改副本数,rename pool;给pool 中的对象拍快照,删除这个对象,从快照恢复对象

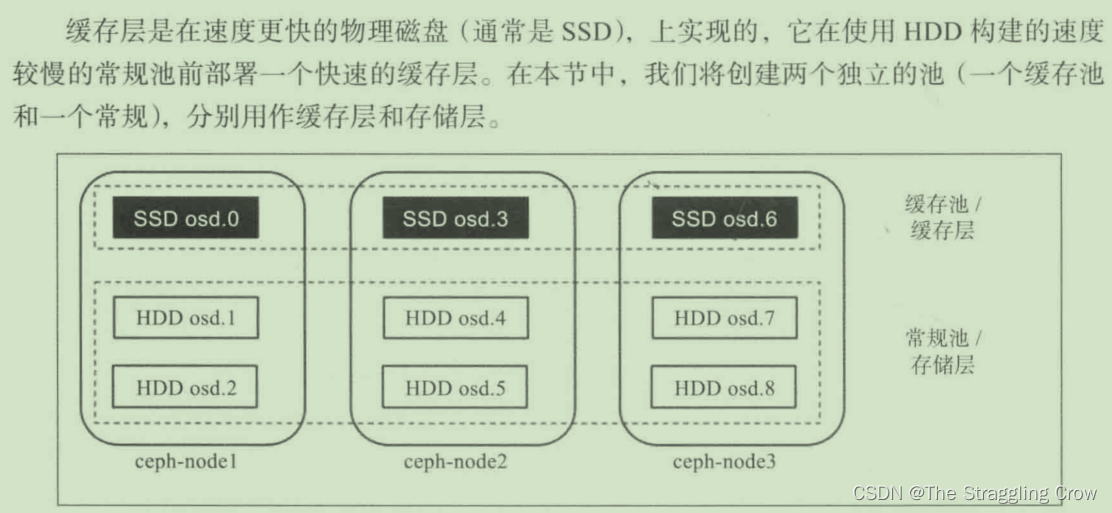
缓存层
客户端写读数据通过缓存池,更快的I/O
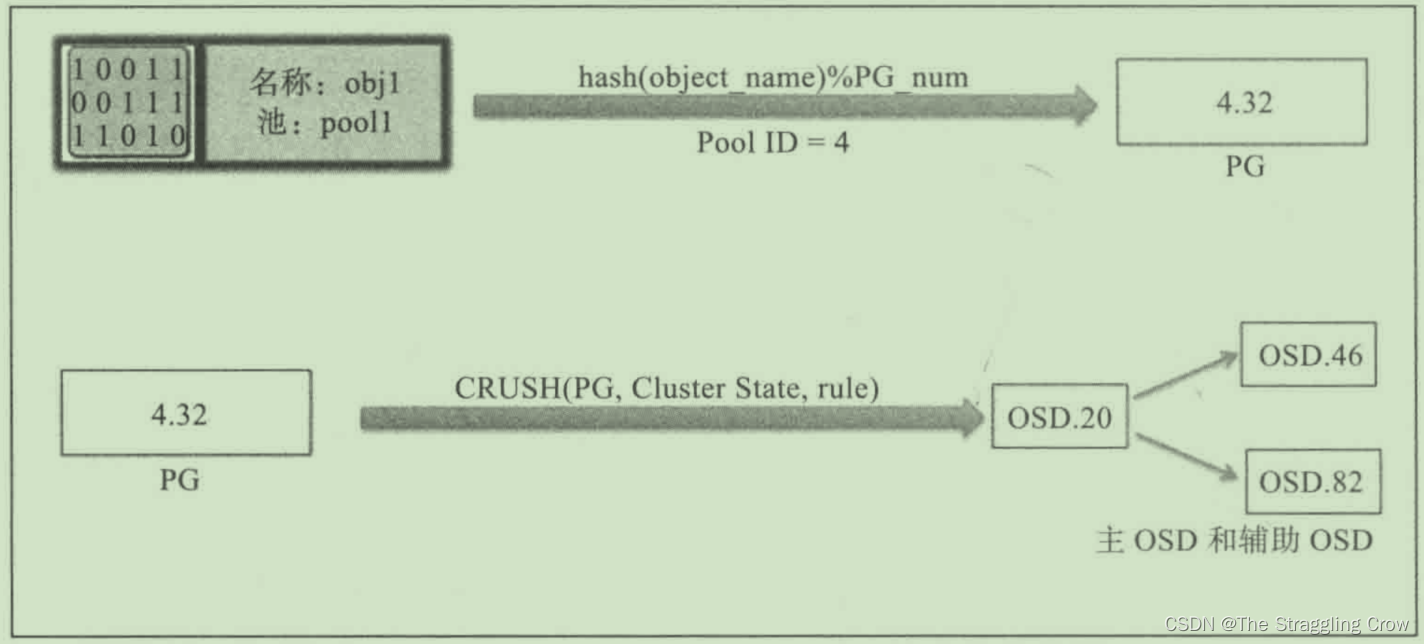
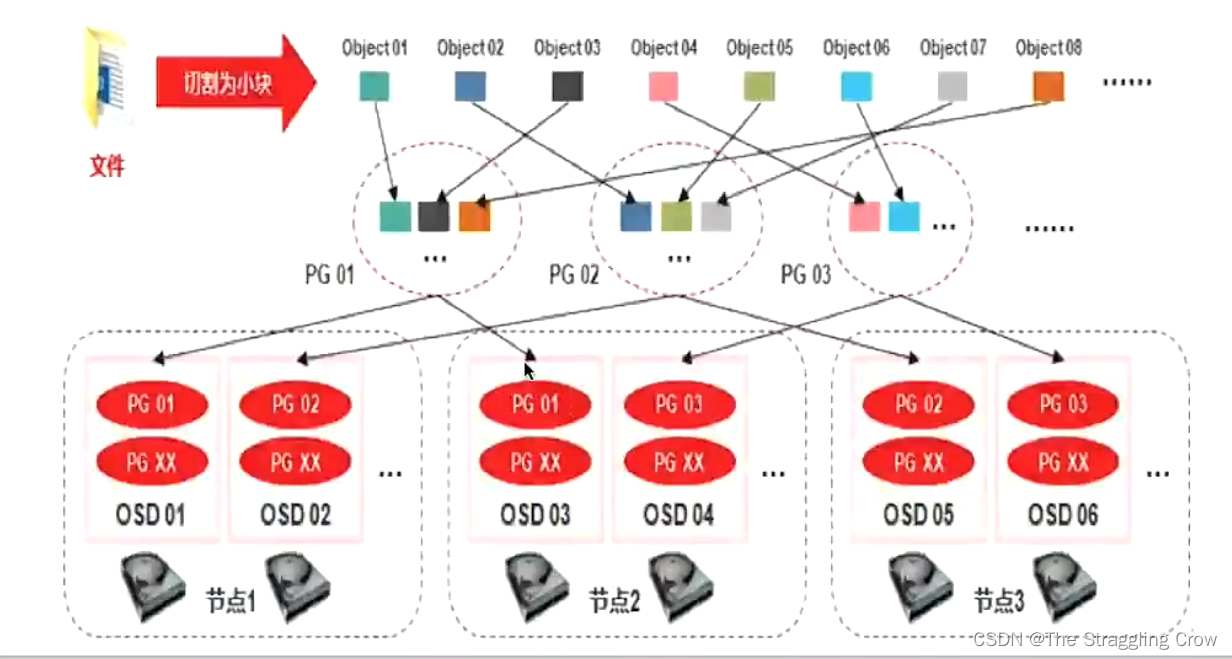
PG是对象的集合,大文件切分成的小块就是对象(4M),相同PG内的对象都会放到相同的硬盘上,一个PG包含多个OSD,加一块盘就是PG里加了空间,
如下图,PG01里包括了OSD01和OSD03,为什么说PG是故障最小单位呢?因为下图是两副本的,OSD01上面的PG01挂了,OSD03上的马上就能顶上来,还能将3上的PG01同步到osd01上,他们也是有主备的
RADOS=OSD (负责存储数据)+ Monitor (负责管理监控)
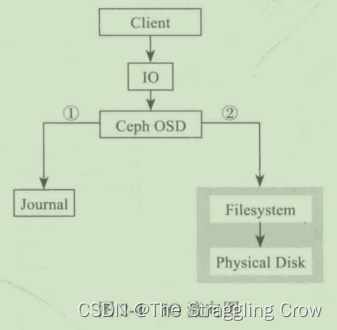
OSD理解为一个硬盘一样,一块裸盘我们会通过ceph的协议,把它格式化成ceph能识别的格式。OSD就是一个进程,管理着这块磁盘
每一个Disk、分区都可以成为一个OSD,将数据提供给Ceph Monitor.【里面包括了pool概念】,数据以副本的形式分散到多台机器上,那么单点故障就不会造成数据丢失
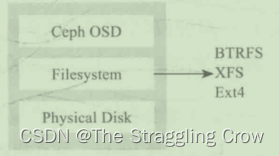
Ceph OSD架构 = 物理磁盘驱动器+在其之上的linux文件系统以及Ceph OSD 服务组成,用xfs,BTRFS和ext4不行
Monitor:相当于ceph集群的大脑,但它并不存储数据,维护整个集群健康状态
# 查看 monitor map ceph mon dump # 查看 osd map ceph osd dump ceph pg dump ceph osd crush dump ceph mds dump- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

MDS: 存放的是文件系统CephFS的元数据,不需要文件系统就不需要它,元数据和数据都是分开的
Mgr: 为外界比如promethus, calamari提供统一的入口,不是核心的东西
RGW:对象存储的接口,他挂了,你没法往里面写对象数据Monitor节点需要更多的cpu,因为它要运算,寻址;osd需要更多的内存,因为osd是进程,内存里需要存放很多信息
三种存储类型/接口的特点
1、RBD有点像我们做的raid, 多块盘组合提升读写和提高容量,主要应用与docker k8s。在容器里用这个块,比如抽象出一个块给mysql使用
2、CephFS 方便文件共享,ftp,nfs
3、对象存储(Object)具备块存储的读写高速和文件存储的共享特性。使用场景,图片存储和视频存储,接口就是简单的GET,PUT,DEL等部署
1、ceph-deploy 推配置文件,变更维护的时候,添加硬盘
虚拟机方式
1、每个虚拟机需要4块硬盘(1个os,3块osd),双网卡,一个dhcp,一个局域网
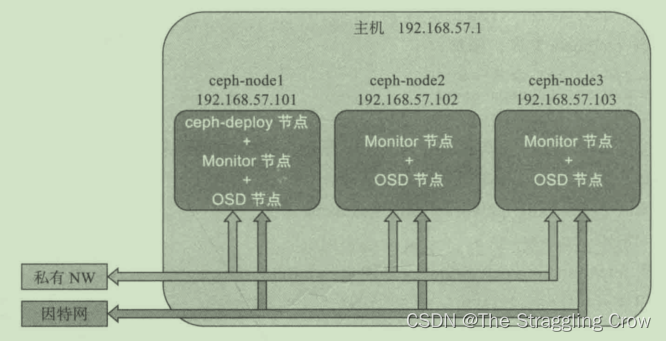
2、
node1 上 install ceph-deploy
利用 ceph-deploy将ceph软件安装到 所有节点
node1 上 创建Monitor, OSD(用掉三块装完系统后挂载裸盘)【osd 会擦除磁盘原有数据,创建新的文件系统,默认是xfs,然后将第一个分区作为数据分区,第二个作为日志分区】
3、ceph需要大于奇数个monitor,例如3或5,以形成仲裁【一个mon挂了,选出个新leader,不是奇数,脑裂】
相同的方法在另外两台机器上部署monitor,OSD



Ceph Dashboard
资源占用,状态等一目了然
Prometheus: 容器监控系统
mgr暴露接口 Prometheus采集 Grafana展示
需要进prome的docker里面修改配置文件,把要监控的ip:port加进去,否则prome的只是在监控它自己
Grafana里面添加prome的数据源,进行图表显示K8s+Ceph
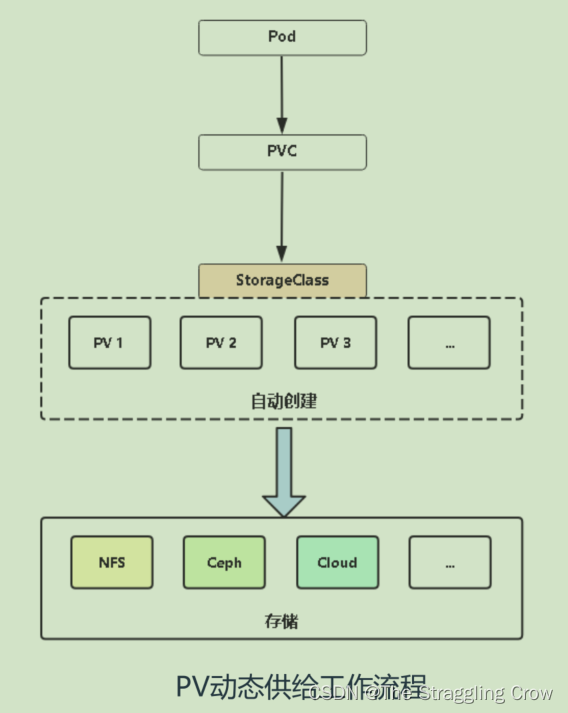
PV持久卷–k8s将外部存储抽象成自己认识的存储,PV分为动态供给和静态供给(提前创建一批PV,维护成本太高)
PVC 持久卷申请— 写yaml时候指定用多少磁盘容量
pod会绑定pv,pv挂载到容器的某个目录下,这个目录就是持久化数据的目录,PVC就会指定StorageClass,StorageClass就是动态供给的资源,他能调用外部存储【NFS,Ceph,Cloud】自动创建pv
ceph-csi 是专门用于为k8s中使用RBD,CephFS提供存储的PV供给程序,k8s和ceph之间做了一个连接
secret.yaml是连接ceph的凭据,yaml文件都要根据自己的情况修改
k8s每个节点都需要装ceph的客户端cephfs就是3个pod共享一个目录
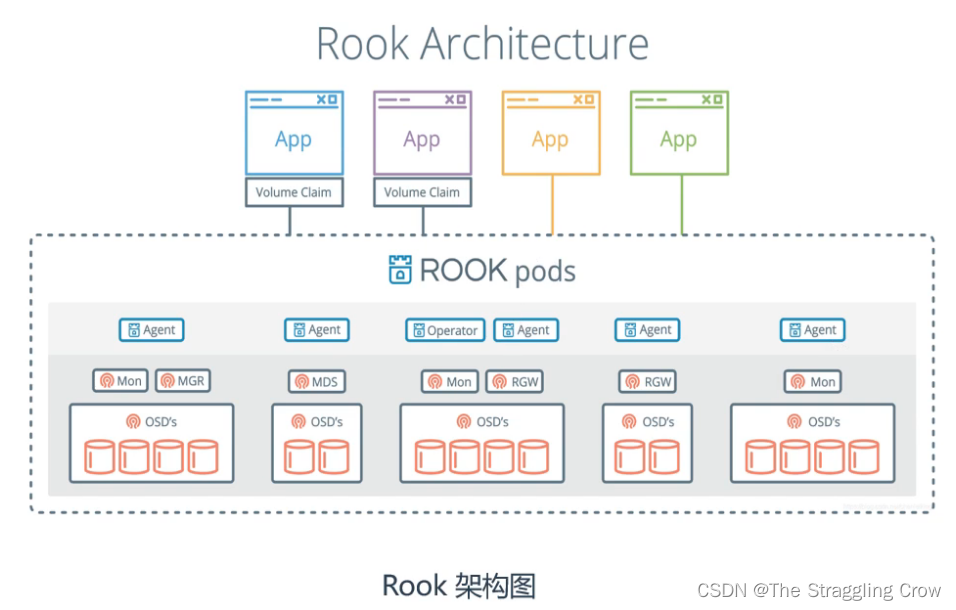
就是pod能挂载ceph的空间,并且能在线扩容Rook(基于k8s活着)
价值: 简化部署维护
rook自动地部署ceph的核心组件,提供agent管理每个节点(挂载,卸载,格式化数据卷等等)
Opterator是rook的核心,维护ceph一些相关的任务

逻辑卷和Raid
传统分区扩展性差,逻辑卷能够很好的解决该问题
RAID- 提高IO能力
磁盘并行读写 - 提高耐用性
磁盘冗余来实现
-
相关阅读:
华为配置WLAN AC和AP之间VPN穿越示例
(二)随机变量的数字特征:探索概率分布的关键指标
医学图像处理——DeepDrr工具CT生成DRR
SpringBoot集成MyBatis-Plus实现增删改查
浅谈UI自动化测试
疫情统计页面 H5 vue3+TypeScript+Echarts
2023-09-26力扣每日一题-水题
AttributeError: Can only use .dt accessor with datetimelike values
在面试了些外包以后,我有了些自己的思考
mysql面试题8:MySQL的日志有哪些?MySQL的bin log、redo log、undo log区别和联系
- 原文地址:https://blog.csdn.net/qq_41834780/article/details/127842601