-
【C++笔试强训】第二十三天
🎇C++笔试强训
- 博客主页:一起去看日落吗
- 分享博主的C++刷题日常,大家一起学习
博主的能力有限,出现错误希望大家不吝赐教- 分享给大家一句我很喜欢的话:夜色难免微凉,前方必有曙光 🌞。

💦🔥
选择题
💦 第一题
下面程序段的时间复杂度为()
for (int i=0;i<m;i++) for (int j=0;j<n;j++) a[i][j]=i*j;- 1
- 2
- 3

这里一看到循环套循环,这一眼就知道是m*n的,看次数
这道题的答案是C
💦 第二题
下列关于线性链表的叙述中,正确的是( )
A 各数据结点的存储空间可以不连续,但它们的存储顺序与逻辑顺序必须一致
B 各数据结点的存储顺序与逻辑顺序可以不一致,但它们的存储空间必须连续
C 进行插入与删除时,不需要移动表中的元素
D 以上说法均不正确
A 存储空间可以不连续,它存储顺序与逻辑顺序就没有必要一致,逻辑顺序是123,而存储的物理顺序可以是213
B 如果储存空间连续这就不是链表了
C 进行插入与删除时,不需要移动表中的元素,只需要改变指针
这道题的答案是C
💦 第三题
下列描述的不是链表的优点是( )
A 逻辑上相邻的结点物理上不必邻接
B 插进、删除运算操纵方便,不必移动结点
C 所需存储空间比线性表节省
D 无需事先估计存储空间的大小
A逻辑上相邻的结点物理上不必邻接,这是一大特点
B插进、删除运算操纵方便,不必移动结点,这是链表最大的优点
D无需事先估计存储空间的大小,我们都是动态申请的
C 如果存储123,如果是顺序表只需要3个,而链表则需要多申请指针维护数据
这道题的答案是C
💦 第四题
向一个栈顶指针为h的带头结点的链栈中插入指针s所指的结点时,应执行()
A h->next=s;
B s->next=h;
C s->next=h;h->next=s;
D s->next=h->next;h->next=s;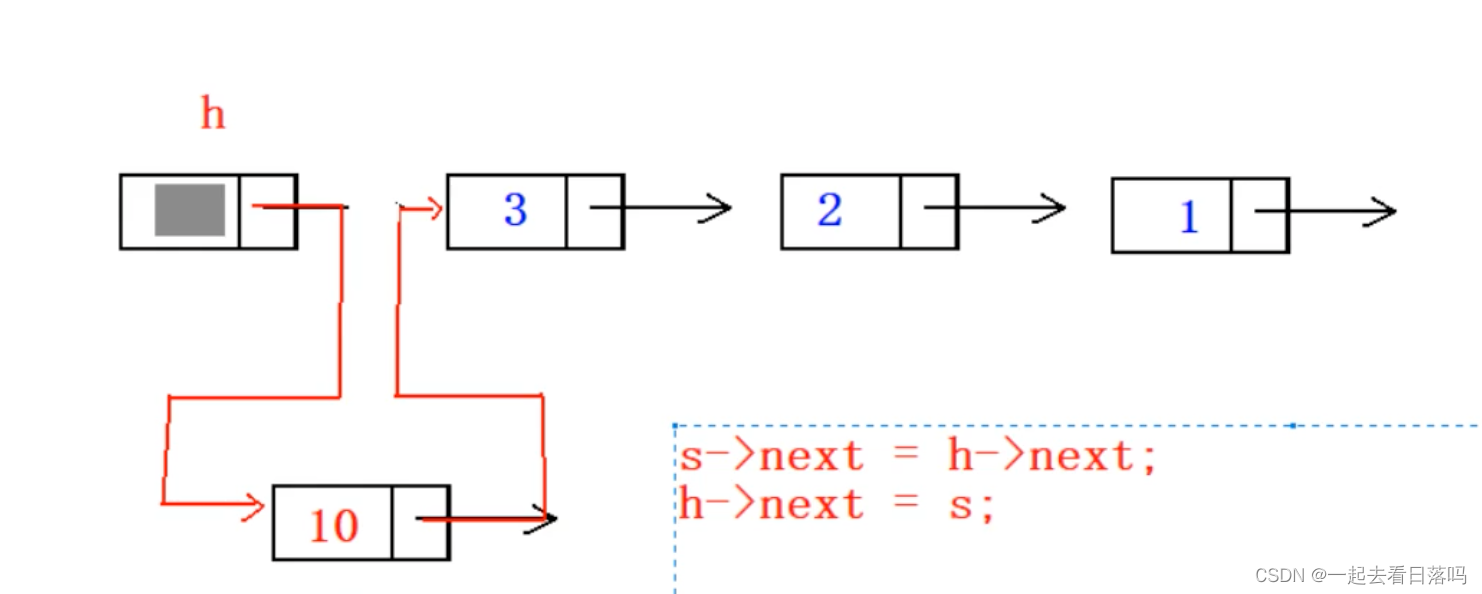
把图画出来答案就清晰明了了
这道题的答案是D
💦 第五题
队列{a,b,c,d,e}依次入队,允许在其两端进行入队操作,但仅允许在一端进行出队操作,则不可能得到的出队序列是()
A b, a, c, d, e
B d, b, a, c, e
C d, b, c, a, e
D e, c, b, a, d注意:允许在其两端进行入队操作,但仅允许在一端进行出队操作
画个图就可以知道结果了,每个结果都尝试一下
这道题的答案是C
💦 第六题
若一棵二叉树具有12个度为2的结点,6个度为1的结点,则度为0的结点个数是()
A 10
B 11
C 13
D 不确定n0 = n2 + 1 ;这是二叉树的一个性质
这道题的答案是C
💦 第七题
下列各树形结构中,哪些是平衡二叉查找树:

平衡二叉树的两个前提,一,他是一棵二叉搜索树,二,平衡因子绝对值不能超过一
A 不是二叉搜索树
B 平衡因子不满足
C 是AVL树
D 不是二叉搜索树
这道题的答案是C
💦 第八题
已知关键字序列5,8,12,19,28,20,15,22是最小堆,插入关键字3,调整后得到的最小堆是()
A 3,8,12,5,20,15,22,28,19
B 3,5,12,19,20,15,22,8,28
C 3,12,5,8,28,20,15,22,19
D 3,5,12,8,28,20,15,22,19


这道题的答案是D
💦 第九题
采用哈希表组织100万条记录,以支持字段A快速查找,则()
A 理论上可以在常数时间内找到特定记录
B 所有记录必须存在内存中
C 拉链式哈希曼最坏查找时间复杂度是O(n)
D 哈希函数的选择跟A无关
A 不一定,用哈希表组织这么多数据,大概率会出现冲突
B 不一定,数据量太大可能在内存放不下,会采用外部存储
C 最坏的情况是所有数据都要查找一次,所以是On
D A如果是整数可以采用其他映射关系,如果是字符串就不能用除留余数法,所以有关系
这道题的答案是C
💦 第十题
假设你只有100Mb的内存,需要对1Gb的数据进行排序,最合适的算法是()
A 归并排序
B 插入排序
C 快速排序
D 冒泡排序
内存无法装载这么大内存
插入,冒泡,快速都是内部排序,利用归并可以把数据分到不同的文件记录内部数据进行排序
这道题的答案是C
编程题
🔥 第一题
链接:微信红包

- 解题思路
本题两种思路,第一种排序思路,如果一个数出现次数超过一半了,排序过后,必然排在中间,则最后遍历整个数组查看是否符合即可。第二种思路可以用map统计每个数字出现的次数,最后判断有没有超过一半的数字。
- 代码演示
class Gift { public: int getValue(vector<int> gifts, int n) { // write code here //方法一:map统计 // map- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
🔥 第二题
链接:计算字符串的编辑距离

- 解题思路
本题需要用动态规划解题 状态: 子状态:word1的前1,2,3,…m个字符转换成word2的前1,2,3,…n个字符需要的编辑距离
F(i,j):word1的前i个字符于word2的前j个字符的编辑距离 状态递推: F(i,j) = min { F(i-1,j)+1, F(i,j-1) +1, F(i-1,j-1) +(w1[i]==w2[j]?0:1) } 上式表示从删除,增加和替换操作中选择一个最小操作数 F(i-1,j): w1[1,…,i-1]于w2[1,…,j]的编辑距离,删除w1[i]的字符—>F(i,j) F(i,j-1): w1[1,…,i]于w2[1,…,j-1]的编辑距离,增加一个字符—>F(i,j) F(i-1,j-1): w1[1,…,i-1]于w2[1,…,j-1]的编辑距离,如果w1[i]与w2[j]相同, 不做任何操作,编辑距离不变,如果w1[i]与w2[j]不同,替换w1[i]的字符为w2[j]—>F(i,j) 初始化: 初始化一定要是确定的值,如果这里不加入空串,初始值无法确定 F(i,0) = i :word与空串的编辑距离,删除操作 F(0,i) = i :空串与word的编辑距离,增加操作 返回结果:F(m,n)
- 代码演示
#include#include #include using namespace std; int minDistance(const string &s1,const string &s2) { if(s1.empty() || s2.empty()) return max(s1.size(),s2.size()); int len1 = s1.size(); int len2 = s2.size(); vector<vector<int >> f(len1+1,vector<int>(len2+1,0)); //初始化距离 for(int i = 0;i <= len1;i++) f[i][0] = i; for(int j = 0;j <= len2;++j) f[0][j] = j; for(int i = 1;i <= len1;++i) { for(int j = 1;j <= len2 ;++j) { if(s2[j-1] == s1[i-1]) { f[i][j] = min(f[i-1][j],f[i][j-1]) + 1; //由于字符相同,距离不发生变化 f[i][j] = min(f[i-1][j-1],f[i][j]); } else { f[i][j] = min(f[i-1][j],f[i][j-1]) + 1; //由于字符不相同,距离+1 f[i][j] = min(f[i-1][j-1]+1,f[i][j]); } } } return f[len1][len2]; } int main() { string s1,s2; while(cin >> s1 >> s2) { cout << minDistance(s1,s2) << endl; } return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
-
相关阅读:
如何从 SD 卡恢复已删除文件?值得尝试的 10 款 SD 卡恢复软件解决方案
PyCharm解决Git冲突
JAVA集合,TreeMap排序
将IEEE制浮点数转换为十进制
BI 数据可视化平台建设(2)—筛选器组件升级实践
Apache Ranger:(一)安装部署
k8s+RabbitMQ单机部署
需求分析步骤
【2022牛客多校-2】G Link with Monotonic Subsequence
单片机选型
- 原文地址:https://blog.csdn.net/m0_60338933/article/details/127820548