-
MicroExpSTCNN and MicroExpFuseNet-基于三维时空卷积神经网络的自发面部微表情识别
3D卷积(w x h x d)=空间卷积(图片w x h)+时间卷积(相邻d帧)
原文链接:https://arxiv.org/pdf/1904.01390v1.pdf解决问题:
传统方法:
传统的基于手工特征的微表情分析方法包括时空局部二值模式(LBP)、LBP-TOP 、定向平均光流特征 等。然而,这些方法的主要缺点是从视频提取的大多是表面信息,缺乏抽象特征表示的信息。从文献综述中,我们可以观察到,手工设计的特征在鲁棒性和准确性方面都有局限性。
深度学习方法:
这些方法通常使用CNN来提取每一帧的空间特征,并馈送给RNN来编码表达视频中各帧之间的时间相关性。因此,这些方法不能同时编码视频特征之间的时空关系。为了克服现有技术的局限性,我们提出了两种三维CNN模型(MicroExpSTCNN和MicroExpFuseNet网络),通过在视频上应用三维卷积操作同时提取时空信息。人们已经努力使用两步深度学习架构对微表情进行分类。在这种典型的两步模型中,第一步使用卷积神经网络(CNNs)在微表情视频的每一帧上提取空间特征。在第二个步骤中,将空间特征以相同的顺序输入一个基于长短期记忆(LSTM)的递归神经网络(RNN),以学习帧之间的时间相关性。这些方法无法更准确地学习时空关系。
如Satya等人,分别使用双流CNN来学习空间和时间特征。将空间和时间特征连接起来,得到最终的单一特征向量,用于SVM分类器的分类。Peng等人使用从每一帧获得的光流序列作为三维CNN架构的输入,对微表情进行分类。三维CNN在微表达识别方面的使用仍然很有限,并且使用了光流等额外的信息。
主要方法:
提出两个
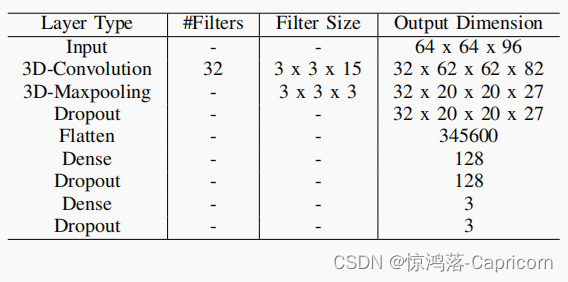
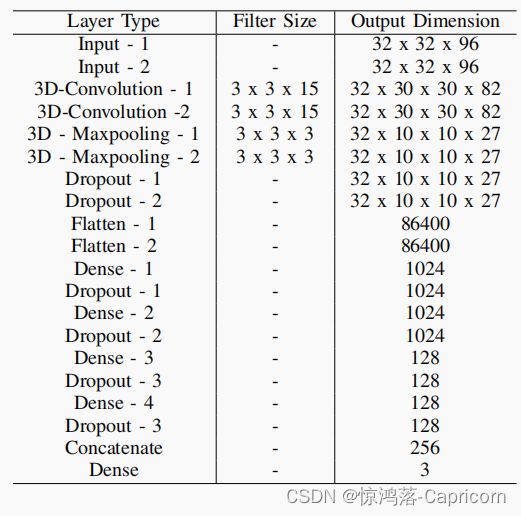
3维时空CNN:利用三维卷积核进行卷积运算,利用三维卷积层提取时空特征。与2D-CNN只在空间方向上使用卷积相比,3D-CNN也在时间方向上使用卷积。三维池化层在保留重要特征的同时,逐步降低了三维卷积层的维度输出,三维池化层在一个小的时空窗口中选择最佳的特征表示。MicroExpSTCNN和MicroExpFuseNet模型的输入尺寸分别为64 x 64 x 96和32 x 32 x 96。①
MicroExpSTCNN模型中的全脸区域来识别微表情,发现嘴区域和其他一些区域,如面颊可以描述识别的关键线索。
MicroExpSTCNN模型的输入维数为w x h x d,其中w和h固定为64,d的值依赖于所使用的数据集。MicroExpSTCNN模型由3D卷积层、3D池化层、全连接层、激活函数和退出层组成。

②
MicroExpFuseNet网模型将眼睛和嘴巴两个区域被用作两个独立的3D时空CNN的输入,最后被融合成一个单一的网络。(DLib人脸检测器裁剪眼睛和嘴巴的区域)基于不同的融合策略(在不同的阶段融合):
中期MicroExpFuseNet和晚期MicroExpFuseNet.
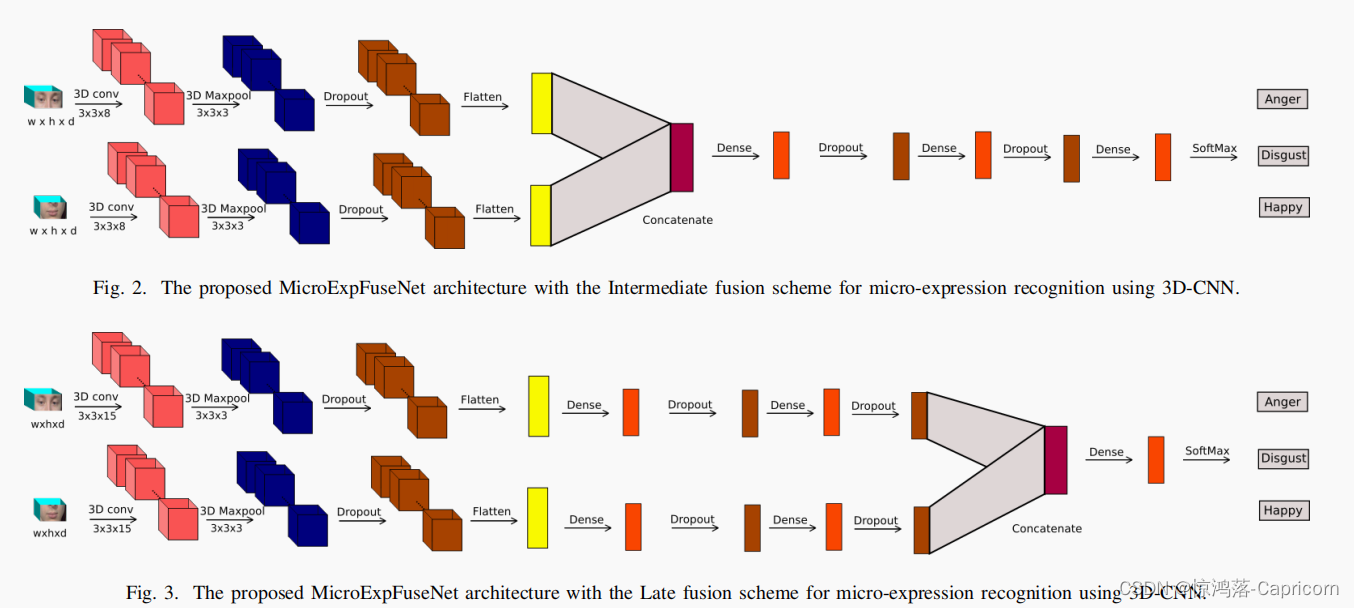
中期MicroExpFuseNet
来自两个网络的扁平特征被连接起来形成一个新的向量,融合的特征在分类得分生成之前,再次用Dense层(全连接层)和Dropout层进行处理。
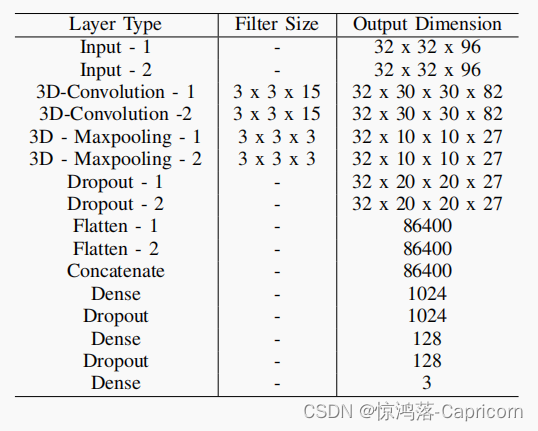
晚期MicroExpFuseNet特征在最后一个Dense全连接层上融合在一起
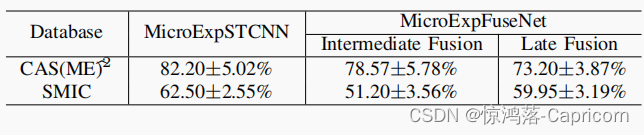
在CAS(ME)b2数据集上,中间融合比晚期融合更适合于中间融合。然而,后期融合更适合于SMIC数据集。创新点:
1>提出了一个能同时
提取视频里的表情 spatial and temporal features来进行分类的MicroExpSTCNN模型。用这个模型达到了最好的表现。
2>提出了一个两分支的MicroExpFuseNet model来提取眼睛和嘴巴区域的特征。
3>在3D-CNNs的基础上,在中间和后期混合了嘴巴和眼睛的特征进行实验
4>用salience maps来进行不同脸部特征的影响分析
5>使用了不同大小的3D卷积核来进行实验效果:
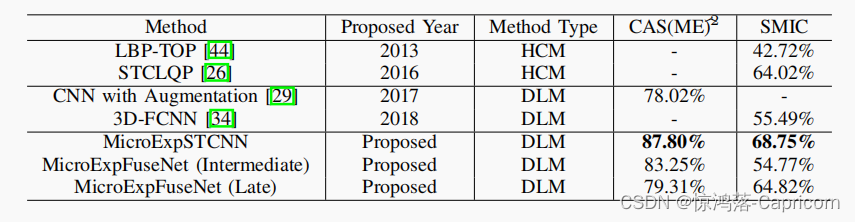
实验在CAS(ME)b2和SMIC微表达数据库上进行。所提出的MicroExpSTCNN模型的性能优于最先进的方法。
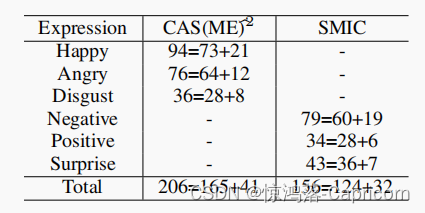
实验数据集:(将几个数据集进行28划分,然后合并,得到一个训练集一个验证集)
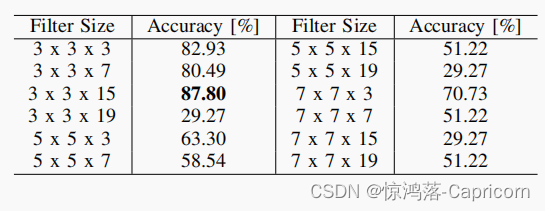
分类交叉熵损失函数和SGD优化,epochs=100,batch_size = 8.3D卷积核大小影响
最优的三维内核大小为3 x 3 x 15。结果表明,
空间范围小(3x3)、时间范围大(15帧)的卷积核更适合。我们还可以看到,更深的内核(15帧)与更小的过滤器(3x3)一起工作得更好。
-
相关阅读:
阴差阳错的帮了博客园一把?
力扣hot100 两数之和 哈希表
Java并发编程—Thread类中的start()方法如何启动一个线程?
MongoDB聚合运算符:$zip
常写的页面(备份)
基于matlab的球形译码的理论原理和仿真结果,对比2norm球形译码,无穷范数球形译码,ML检测
低代码到底是什么?
链表的边界
SSM教室预约管理系统
【CSDN 每日一练 ★☆☆】【数论】用数组写水仙花数
- 原文地址:https://blog.csdn.net/weixin_54338498/article/details/127839685