-
Pytorch中批量定义模型中相同结构的子模型(动态定义子模型变量名)
问题背景
有些时候在定义模型的时候,有一部分的模型结构的是完全相同的,但是模型的数量是一个可以人为控制的变量。比如在多任务学习中,如图所示,输出任务的数量是一个可以人为控制的变量,
Tower层的数量随着任务数量的变化而变化。
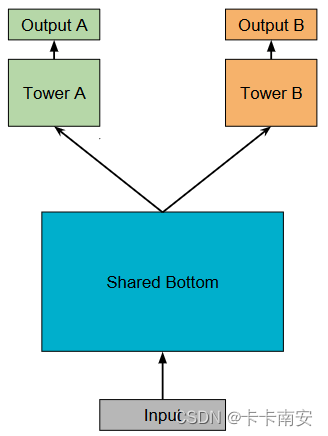
当任务很少时,我们可以简单的定义为:self.TowerA = xxx self.TowerB = xxx ···- 1
- 2
- 3
但是当任务很多的时候,一个一个定义非常麻烦,同时在推理的时候又要重复写多次推理代码,非常不利于代码的通用性和可读性。
接下来我以上图中的模型结构为例,介绍如何重复定义相同结构的模型。
程序实现
class Tower(nn.Module): #Tower模型结构 def __init__(self): super(Tower, self).__init__() p = 0 self.tower = nn.Sequential( nn.Linear(64, 64), nn.ReLU(), nn.Dropout(p), nn.Linear(64, 32), nn.ReLU(), nn.Dropout(p), nn.Linear(32, 1) ) def forward(self, x): out = self.tower(x) return out class SharedBottom(nn.Module): def __init__(self,feature_size,n_task): super(SharedBottom, self).__init__() self.n_task = n_task p = 0 self.sharedlayer = nn.Sequential( nn.Linear(feature_size, 128), nn.ReLU(), nn.Dropout(p), nn.Linear(128, 64), nn.ReLU(), nn.Dropout(p) ) '''下面三种定义方式等价''' #方法1 # self.tower1 = Tower() # self.tower2 = Tower() # ··· '''方法2和方法3为批量定义的写法,将所有tower存入一个列表中,方便推理''' #方法2 # self.towers = [Tower() for i in range(n_task)] # for i in range(n_task): # setattr(self, "tower"+str(i+1), self.towers[i]) #语法:setattr(object, name, value) #方法3 for i in range(n_task): setattr(self, "tower"+str(i+1), Tower()) #语法:setattr(object, name, value) self.towers = [getattr(self,"tower"+str(i+1)) for i in range(n_task)] #语法:getattr(object, name) def forward(self, x): h_shared = self.sharedlayer(x) #如果像方式一那样定义,那么推理时就需要按以下方式,很麻烦 # out1 = self.tower1(h_shared) # out2 = self.tower2(h_shared) # ··· #将所有tower存入列表中,即可用循环来实现推理,len(out)=n_task out = [tower(h_shared) for tower in self.towers] return out Model = SharedBottom(feature_size=32, n_task=2) #feature_size表示输入特征数量,n_task表示任务数量 print(Model)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
当
n=2时,输出为:SharedBottom( (sharedlayer): Sequential( (0): Linear(in_features=32, out_features=128, bias=True) (1): ReLU() (2): Dropout(p=0, inplace=False) (3): Linear(in_features=128, out_features=64, bias=True) (4): ReLU() (5): Dropout(p=0, inplace=False) ) (tower1): Tower( (tower): Sequential( (0): Linear(in_features=64, out_features=64, bias=True) (1): ReLU() (2): Dropout(p=0, inplace=False) (3): Linear(in_features=64, out_features=32, bias=True) (4): ReLU() (5): Dropout(p=0, inplace=False) (6): Linear(in_features=32, out_features=1, bias=True) ) ) (tower2): Tower( (tower): Sequential( (0): Linear(in_features=64, out_features=64, bias=True) (1): ReLU() (2): Dropout(p=0, inplace=False) (3): Linear(in_features=64, out_features=32, bias=True) (4): ReLU() (5): Dropout(p=0, inplace=False) (6): Linear(in_features=32, out_features=1, bias=True) ) ) )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
当
n=3时,输出为:SharedBottom( (sharedlayer): Sequential( (0): Linear(in_features=32, out_features=128, bias=True) (1): ReLU() (2): Dropout(p=0, inplace=False) (3): Linear(in_features=128, out_features=64, bias=True) (4): ReLU() (5): Dropout(p=0, inplace=False) ) (tower1): Tower( (tower): Sequential( (0): Linear(in_features=64, out_features=64, bias=True) (1): ReLU() (2): Dropout(p=0, inplace=False) (3): Linear(in_features=64, out_features=32, bias=True) (4): ReLU() (5): Dropout(p=0, inplace=False) (6): Linear(in_features=32, out_features=1, bias=True) ) ) (tower2): Tower( (tower): Sequential( (0): Linear(in_features=64, out_features=64, bias=True) (1): ReLU() (2): Dropout(p=0, inplace=False) (3): Linear(in_features=64, out_features=32, bias=True) (4): ReLU() (5): Dropout(p=0, inplace=False) (6): Linear(in_features=32, out_features=1, bias=True) ) ) (tower3): Tower( (tower): Sequential( (0): Linear(in_features=64, out_features=64, bias=True) (1): ReLU() (2): Dropout(p=0, inplace=False) (3): Linear(in_features=64, out_features=32, bias=True) (4): ReLU() (5): Dropout(p=0, inplace=False) (6): Linear(in_features=32, out_features=1, bias=True) ) ) )- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
其他
批量定义模型中相同结构的子模型的另一个应用就是基于
MoE的模型,如图所示: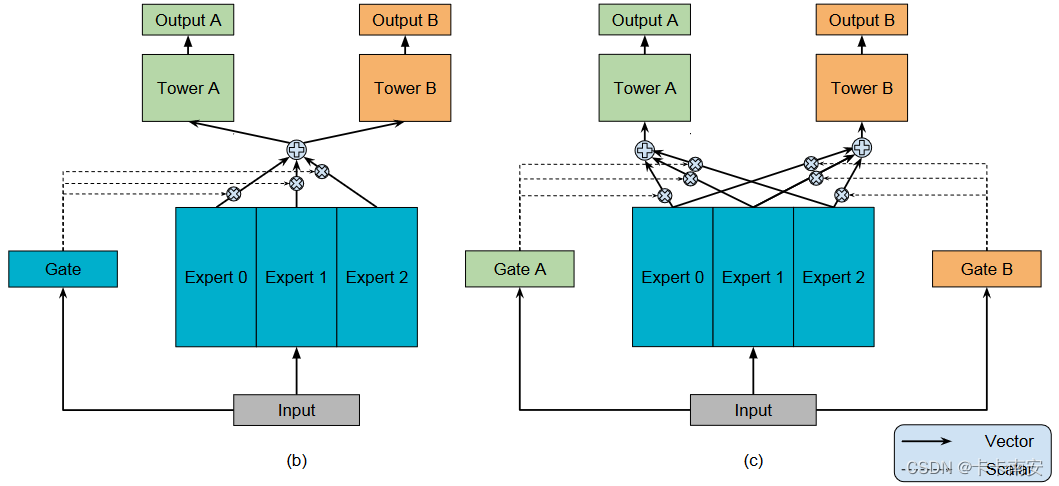
在上图所展示的模型得中,除了Tower是一个变量,Expert也是一个变量,并且不同的Tower和Expert的模型结构往往是相同的,因此批量定义模型中相同结构的子模型在实际应用中非常有用,不仅可以提高编写效率,也可以提高代码的可读性和通用性。关于
MMoE的实现代码请参考:【阅读笔记】多任务学习之MMoE(含代码实现)参考文献:
-
相关阅读:
Java注解学习与实战
【教学类-18-02】20221124《蒙德里安“红黄蓝黑格子画”-A4竖版》(大班)
基于单片机的机械臂运行轨迹在线控制系统设计
微服务架构深入理解 | 技术栈
密码学奇妙之旅、02 混合加密系统、AES、RSA标准、Golang代码
3D抓取算法的网络结构原理及作用
拿走吧你,Fiddler模拟请求发送和修改响应数据
python基础语法14-GUI编程2
卷积神经网络的实际应用,卷积神经网络应用举例
SpringBoot整合MQTT
- 原文地址:https://blog.csdn.net/cyj972628089/article/details/127836983
