-
Elasticsearch学习--script
一、概念


es1.4-5.0,默认脚本语言是Grovvy
es5.0+,默认脚本语言是painless

二、简单使用
将price减一
- # 将id=1的price减一
- POST goods/_update/1
- {
- "script": {
- "source": "ctx._source.price -= 1"
- }
- }
- # 简写
- POST goods/_update/1
- {
- "script": "ctx._source.price -= 1"
- }
其中,ctx是一个上下文对象 ,用在对数据的修改上
三、CRUD
1、数据备份
(数据来源可以查看:CSDN)
- #将goods中的数据备份到goods2中
- POST _reindex
- {
- "source": {
- "index": "goods"
- },
- "dest": {
- "index": "goods2"
- }
- }
2. 新增数组中的值
- # 将id=1的tags新增一个值
- POST goods/_update/1
- {
- "script": "ctx._source.tags.add('无线充电')"
- }
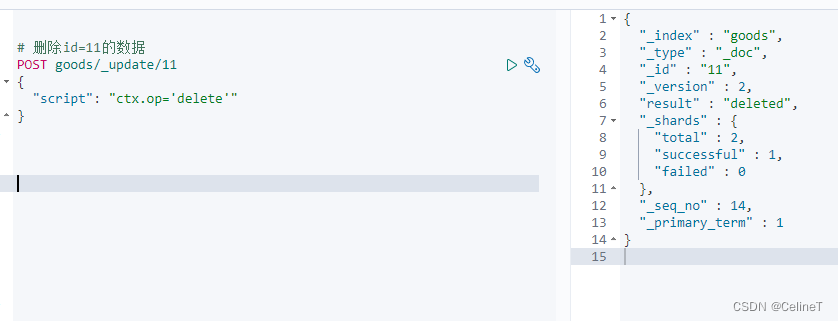
3. 根据id删除
- # 删除id=11的数据
- POST goods/_update/11
- {
- "script": "ctx.op='delete'"
- }
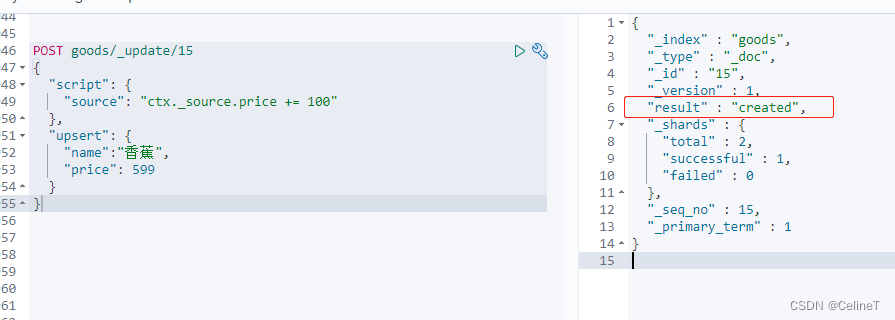
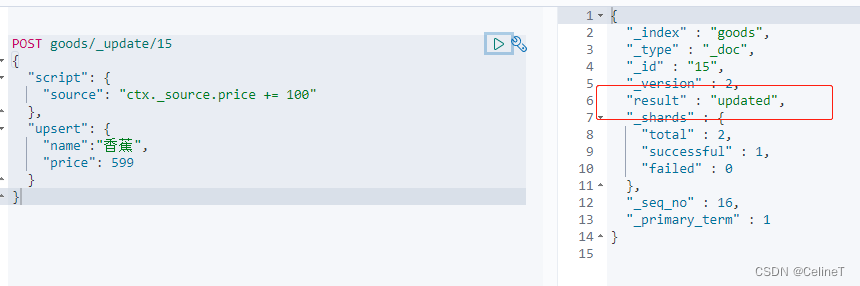
4. upsert
如果数据存在执行script中的updated,如果数据不存在,执行upsert中created
- POST goods/_update/15
- {
- "script": {
- "source": "ctx._source.price += 100"
- },
- "upsert": {
- "name":"香蕉",
- "price": 599
- }
- }
第一次执行结果
第二次执行结果
5. 查询
使用expression和painless两种语言进行查询,查询结果相同
- GET goods/_search
- {
- "script_fields": {
- "new_price": {
- "script": {
- "lang": "expression",
- "source": "doc['price'].value * 0.9"
- }
- }
- }
- }
- GET goods/_search
- {
- "script_fields": {
- "new_price": {
- "script": {
- "lang": "painless",
- "source": "doc['price'] * 0.9"
- }
- }
- }
- }

painless,doc['age'].value和doc['age']都能正确输出,但是doc['age'] * 0.9报错
expression,doc['age'].value和doc['age']都能正确输出,doc['age'] * 0.9和doc['age'].value * 0.9也都不报错但是,painless,如果字段为空,*0.9会报错
expression:只能访问数字、布尔值、日期等,存储的字段不可用
es源数据是map类型的,在取值的时候,要根据doc['x xx']取值
update用ctx,查询的时候用doc
6. 参数化查询
给interest加一个值aaa
- POST indexname/_update/2
- {
- "script": {
- "lang": "painless",
- "source": "ctx._source.interest.add('aaa')"
- }
- }
es在首次执行脚本的时候,会对执行的脚本进行编译,并且把编译的结果放在缓冲区内。es的缓冲区默认只有100M,编译操作很消耗性能,es每分钟支持的编译次数是15次
解决方案是:- POST indexname/_update/2
- {
- "script": {
- "lang": "painless",
- "source": "ctx._source.interest.add(params.inserest_name)",
- "params": {
- "inserest_name":"bbb"
- }
- }
- }
这样,参数是动态传递的,没有硬编码,下次参数内容发生改变,但是脚本没有发生改变,不需要重新编译,节省性能
同理,也可以这样
- GET indexname/_search
- {
- "script_fields": {
- "new_age": {
- "script": {
- "lang": "painless",
- "source":"doc['age'].value * params.num",
- "params": {
- "num": 0.9
- }
- }
- }
- }
- }
如果是expression,就要把params.num改成num
- GET indexname/_search
- {
- "script_fields": {
- "new_age": {
- "script": {
- "lang": "expression",
- "source":"doc['age'].value * num",
- "params": {
- "num": 0.9
- }
- }
- }
- }
- }
结果数组
- GET indexname/_search
- {
- "script_fields": {
- "age": {
- "script": {
- "lang": "painless",
- "source":"doc['age'].value"
- }
- },
- "new_age": {
- "script": {
- "lang": "painless",
- "source":"[doc['age'].value - params.num_1,doc['age'].value - params.num_2,doc['age'].value - params.num_3]",
- "params": {
- "num_1": 1,
- "num_2": 2,
- "num_3": 3
- }
- }
- }
- }
- }
四、stored scripts:scripts模板
1. 操作脚本
因为脚本编译比较消耗性能,可以把脚本保存在集群的缓存中
语法
/_scripts/{script_id}创建脚本
- POST _scripts/age_num
- {
- "script":{
- "lang": "painless",
- "source":"doc['age'].value - params.num"
- }
- }
查看脚本
GET _scripts/age_num使用脚本
- GET indexname/_search
- {
- "script_fields": {
- "age": {
- "script": {
- "lang": "painless",
- "source":"doc['age'].value"
- }
- },
- "new_age": {
- "script": {
- "id": "age_num",
- "params": {
- "num": 0.9
- }
- }
- }
- }
- }
2. scripting的函数式编程
在source中加""",三个双引号
- POST indexname/_update/2
- {
- "script": {
- "lang": "painless",
- "source": """
- ctx._source.interest.add(params.inserest_name);
- ctx._source.age-=1;
- """,
- "params": {
- "inserest_name": "bbb"
- }
- }
- }
如果name中包含aa:name+bb;否则,不操作。==~是匹配的意思
- POST indexname/_update/2
- {
- "script": {
- "lang": "painless",
- "source": """
- if(ctx._source.name ==~ /[\s\S]*aa[\s\S]*/){
- ctx._source.name+="bb"
- }else{
- ctx.op="noop"
- }
- """
- }
- }
for循环取insterst的总数
- GET indexname/_search
- {
- "aggs": {
- "agg_insterst": {
- "sum": {
- "script": {
- "lang": "painless",
- "source": """
- int total=0;
- for(int i=0; i
- total++;
- }
- return total;
- """
- }
- }
- }
- }
- }
doc['filed']:会被加载到内存中,效率更高,更消耗内存,只允许简单类型,object和nested属于复杂类型。推荐
params['_source']['field']:每次都要重新加载,重新解析,可以用于复杂类型
-
相关阅读:
C# .NET6 Log4net输出日志
跨线程池共享的ThreadLocal
Web前端:2022年Web开发者的五大CSS工具
怎样使用SQL SERVER新建立一个数据库
【VUE】vue网站设计-----字节招聘网站设计
Vue3问题:如何实现密码加密登录?前后端!
vector的底层模拟实现
TypeScript基础入门
三分钟了解前端javaScript
maven 常用知识速记
- 原文地址:https://blog.csdn.net/CelineT/article/details/126713188
