-
论文阅读之Discrete Opinion Tree Induction for Aspect-based Sentiment Analysis
论文概要
依赖树与图神经网络被广泛用于基于方面的情感分类。尽管这些方法很有效,但它们依赖于外部依赖性解析器,这对于低资源语言来说是不可用的,或者在低资源领域中性能更差。此外,依赖树也没有针对基于方面的情感分类进行优化。在本文提出了一种面向特定和语言不可知的离散潜在意见树模型,作为显式依赖树的替代结构。
为了简化复杂结构化潜在变量的学习,我们在方面到上下文的注意力得分和句法距离之间建立了联系,从注意力得分中归纳出树。在六个英语基准测试、一个中国数据集和一个韩国数据集上的结果表明,模型可以实现具有竞争力的性能和可解释性。
文章摘要指出,使用依存树虽然效果好,但是存在语料少的情况性能更差,并且依存树的解析本身就存在着不可避免的错误的,因此文章提出了一种离散潜在的意见树模型,用来代替依存树进行方面级情感分析。
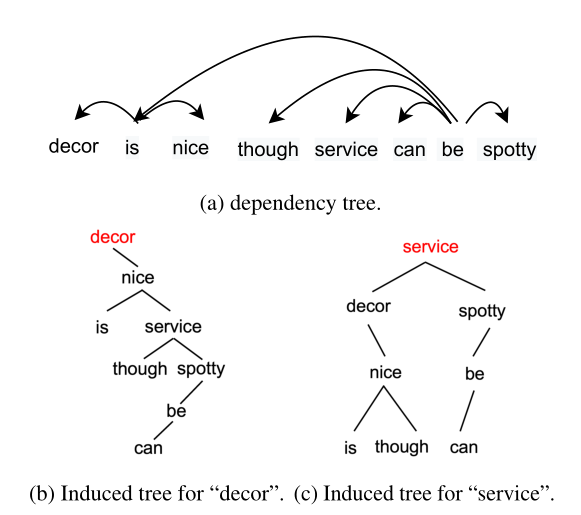
如图,(a)就是依存树,后面的(b)、(c)是文章提出的意见树。其实我们比较直观的看出,意见树其实就是方面词作为根节点的二叉树结构。我们都知道依存树是可以有效的拉近方面词和修饰词的关系,从而帮助推断情感,那么意见树就是进一步操作,理想的情况下,方面词的边上就是修饰词,从而促进情感的判断了。因此一句话里有几组方面词,就会有几课意见树了。因为这是通过训练出来的,因此“潜在”二字也是比较好理解了。模型与公式介绍
我感觉,如果论文里的公式读不懂,那其实文章就是没看明白(虽然我感觉自己其实也并没有看的很明白,但是还是得讲一讲,万一可以抛砖引玉呢)
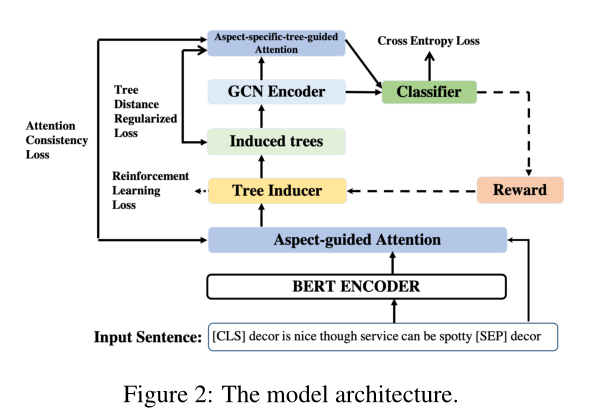
这就是模型图了,大概看看,意思差不多就是,句子用Bert编码,然后通过强化学习训练意见树,然后意见树用GCN编码,获得树的结构特征,然后和句子和方面词的编码进行特征融合,最后进行分类。粗粗说来,确实感觉挺简单的,但是想要了解每一步咋做的,还是需要仔细阅读,花点心思的。
基本变量定义
x 表示一句话,x = w1w2…wn其中w就是表示单个词
a 表示一个方面(方面词或者词组),a = wbwb+1…we其中b到e是连续的正整数,其实就是表示方面词(组)
t 表示一颗意见树
Qϕ(t | x, a) 表示在确定的句子和方面词的情况下的意见树,其中ϕ是一组网络的参数(应该是这个意思吧,因为潜在意见树是针对特定句子和仿方面词的,二者确定了才能确定对应的意见树)
Pθ(y|x, a, t)表示在确定的句子、方面词和意见树的情况下的方面词的情感,其中θ也是一组网络参数。构造意见树
首先我们看看意见树是如何构建的。

其中v表示建立意见树时与方面词的注意力得分,每次取得分最高的进行节点建立。
算法也比较简单,就是以方面词(组)为根节点,分别以左右两边进行二叉树的生长,每次选择v最大的进行生长,意思应该就是说,对方面词情感越大的词,离方面词越近越好。接下来看看v怎么计算
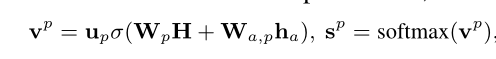
H 表示句子+方面词的Bert向量表示,具体来说就是"[CLS] w1 w2 … wn [SEP] wb…we"喂入Bert输出的 特定方面的句子向量表示。
v 表示建立意见树时与方面词的注意力得分,每次取得分最高的进行节点建立。
σ表示ReLU激活函数
ha表示方面词(组)的Bert向量表示,如果是词组则进行求和池化。ha = Hb+Hb+1+He,其中Hb表示这句话的第b个单词的Bert的向量表示
Qϕ(t | x, a) 表示在确定的句子和方面词的情况下的意见树,其中ϕ是一组网络的参数,up、Wp、Wa,p就是ϕ的一组参数。那么vp 就是一组句中各个词与方面词的注意力得分的,然后以此建立意见树即可。
用GCN编码意见树
首先将意见树转换为图的形式,邻接矩阵如下:
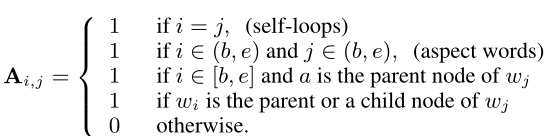
首先是节点自连
其次方面词之间互相连接
再者与方面词连接的子节点和方面词都建立连接
最后剩余的父节点和子节点建立连接GCN节点更新公式如下:
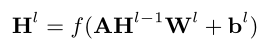
Hl-1 表示图神经网络的前一次特征
Hl 表示图神经网络更新后的特征
Wl 和bl 则代表图神经网络更新特征时需要使用的参数和偏置。
f()表示ReLU激活函数那么GCN编码后,最后得出的特征计算如下:
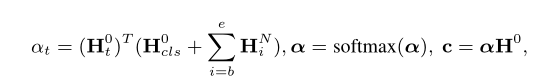
Hcls0 表示GCN中初始CLS向量,也就是经过Bert编码后的CLS的向量
HbN 表示经过GCN编码后方面词中的第1个词的词向量
Ht0 表示句子经过Bert编码后,第t个词的词向量
αt表示第t个词与经过GCN后的方面词的注意力权重
c 是Bert编码+GCN编码意见树后最终的特征GCN意见树编码后的方面词与编码前的词计算注意力权重,就是相当于问了意见树,原句子中哪些词更值得关注,最后就得出c最终特征向量的表示了。
输出层
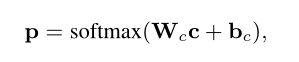
输出层就很简单,全连接变成分类维度即可
Wc和bc则是最后全连接层的参数
p代表最终预测的概率分布至此,前向传播已经完成,但是还有反向传播需要考虑。
损失函数
首先,对于分类的结果p,采用交叉熵损失函数,应该比较好理解,这是我们分类常用的损失函数。
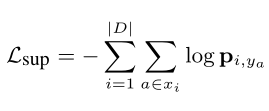
其次,是关于树的距离正则化的损失,因为文章里提到,模型很容易过拟合,因此采用了正则化方式来缓解过拟合,
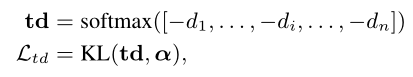
其中给定一个意见树t,使用到根的最短路径的长度计算每个单词i的树距离di,因为距离越短对于的关注度是越大的,因此取负再进行softmax就相当于和注意力机制差不多了。
α就是最终特征的注意力权重组了。因为训练意见树的时候,树的采用是离散的,不可微的,梯度传不过来,就没办法更新,因此这里采用强化学习+蒙特卡洛方法进行训练。
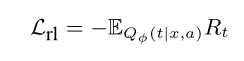
这里使用强化学习训练意见树的损失函数,其中Rt=Pθ(y|x, a, t) 就是说意见树的建立也是为了最后的情感分类服务的。
那么求个梯度: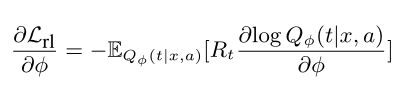
Qϕ(t | x, a) 是生成的样本t的对数似然,可以在每个树构建步骤中将其分解为对数似然之和。根据算法1,build_tree(vij,i,j)的每个调用涉及在给定分数vnm的情况下从跨度[i,j]中选择动作k。动作空间包含j−i+1个动作。该动作的对数似然:
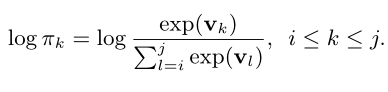
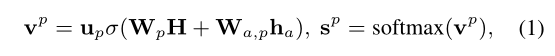
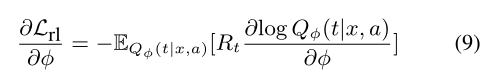
由于等式1中的vp作为得分函数v。枚举所有可能的树来计算等式9中的期望项是困难的,因此使用蒙特卡罗方法(Rubinstein和Kroese,2016),通过获取M个样本来近似训练目标:
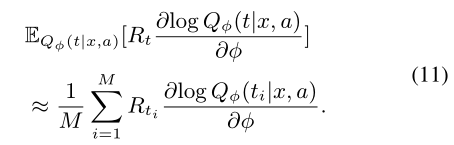
注意力一致性损失:
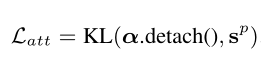
文章还应用注意力一致性损失来直接监督策略网络,而不是仅仅依靠强化梯度来训练策略网络。因为文章里在建树的地方有一个注意力,在最后计算最终特征的时候也有一个注意力,那么也可以根据这两个注意力的一致性来进行进行误差反向传播。那么最终的损失函数如下:
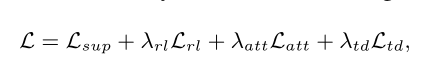
其中,Lsup是监督损失,Lrl是强化学习损失,Latt是一种新的注意力一致性损失,Ltd是通过树约束引导注意力分数分布的损失。λrl、λatt和λtd是超参数。至此,模型的传播和更新应该大概都了解了。
实验结果
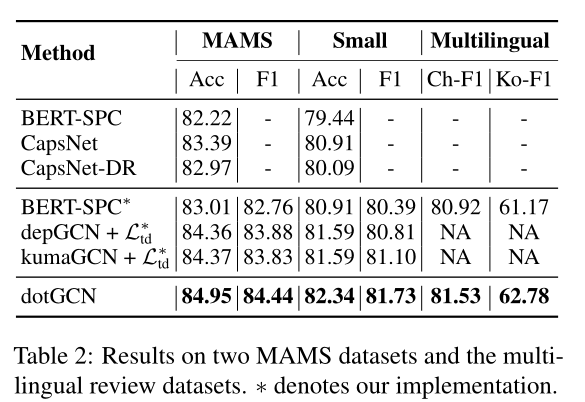
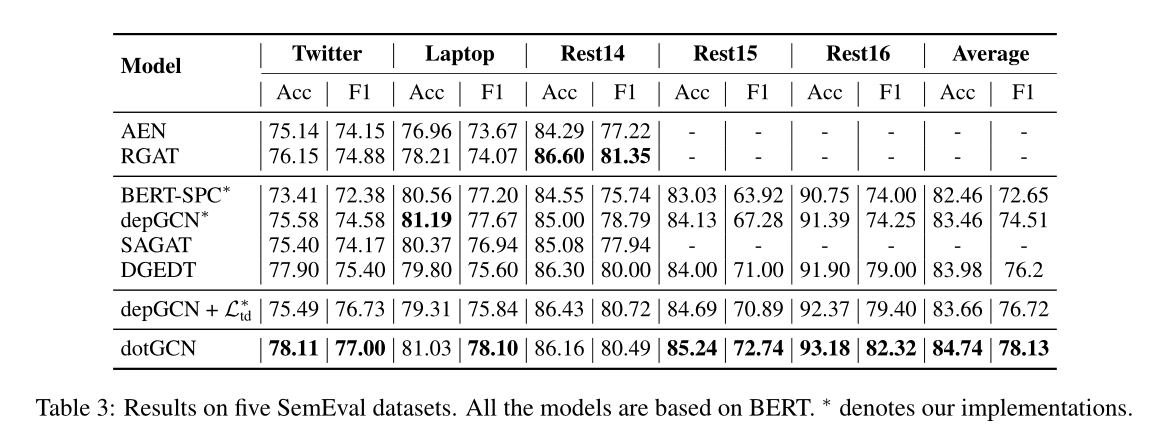
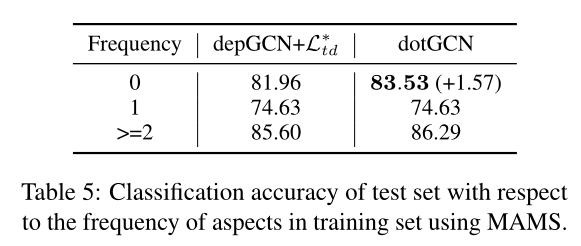
文章提出了一种用于基于方面的情感分析的诱导方面特定离散意见树的方法,通过将方面到上下文的注意力得分视为句法距离来获得树。使用RL和新的基于注意力的正则化来训练注意力得分。模型在不使用解析器(如斯坦福工具等)的情况下,与基于依赖树的模型相比,在经验上实现了竞争性的性能。
总结
后面文章提出的意见树还和依存树进行了对比,效果和依存树差不多,都能拉近方面词和情感词的距离,但是也有区别;并且在低频的方面词有较好的效果,因为不依赖解析器了,可能避免解析器带来的错误,文章还从另一个角度推导了模型,但是看不太懂就没放了。
好的文章需要讲清楚模型结果以及自己添加模块的重要性以及对应的分析,这篇文章就蛮好,就是代码好像还没放出来。参考
Discrete Opinion Tree Induction for Aspect-based Sentiment Analysis
-
相关阅读:
香港科技大学广州|可持续能源与环境学域博士招生宣讲会—广州大学城专场!!!(暨全额奖学金政策)
2024最新 Jenkins + Docker实战教程(七)- Jenkins实现远程传输和自动部署
ipvs之ipvs0网卡
Spark学习(3)-Spark环境搭建-Standalone
【算法作业】实验三:划分集合-贪心 & 可能的IP地址-回溯
Nodejs+vue体育用品商城商品购物推荐系统_t81xg
7 判断给定的二叉树是否是二叉排序树---来源刘H同学
第六讲 主窗体测量代码撰写,实现检测功能
C++零碎记录(二)
Python- 将一个字符串列表连接成一个单独的字符串
- 原文地址:https://blog.csdn.net/qq_52785473/article/details/127809863